- The paper presents ReCalX, a method that adaptively calibrates model predictions under perturbations to enhance explanation reliability.
- It leverages adaptive temperature scaling by partitioning perturbation intensities to minimize KL divergence and preserve mutual information.
- Empirical analysis shows error reductions of 80%-97% and improved feature ranking robustness across tabular and vision tasks.
Uncertainty Calibration as a Foundational Prerequisite for Reliable Perturbation-based Explanations
Introduction
Perturbation-based explanation methods are extensively employed for post-hoc interpretability in machine learning, particularly due to their model-agnostic nature and intuitive approach of modifying input features and observing output changes. However, the reliability of such techniques remains confounded by the discrepancy between the model's training distribution and the perturbed inputs used during explanation. This paper rigorously analyzes how uncertainty calibration—defined as the alignment between model confidence and empirical accuracy—is essential for producing trustworthy feature attributions under perturbations. The authors introduce ReCalX, a recalibration method that specifically adjusts model outputs for perturbed instances, resulting in significant improvements in explanation robustness, fidelity, and identification of relevant features.
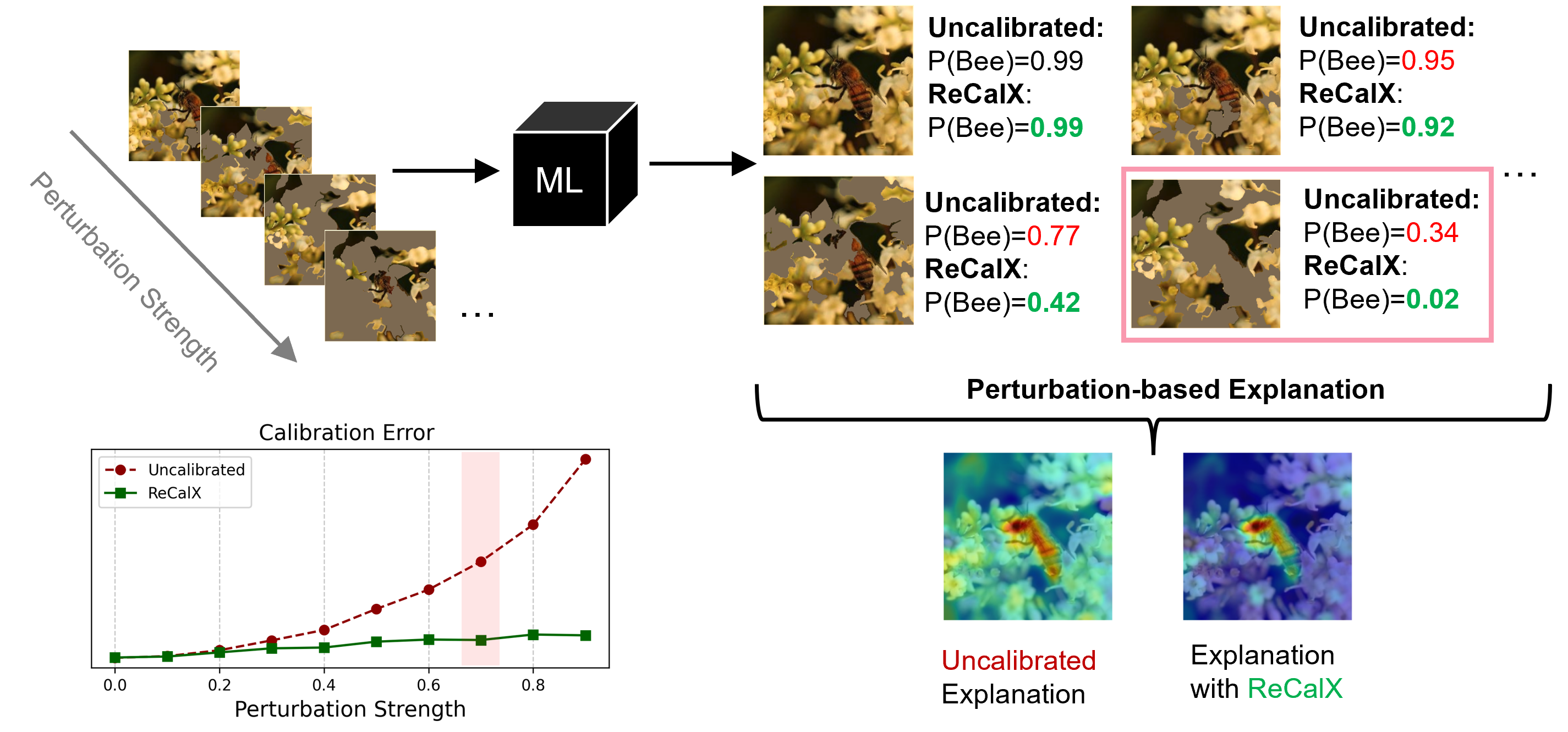
Figure 1: Perturbation-based explanation methods rely on model outputs from modified inputs, but miscalibrated predictions obscure true feature importance; ReCalX mitigates this by recalibrating for reliable outputs under perturbation.
Theoretical Foundations: Calibration and Explanation Quality
The formal analysis begins by connecting calibration errors under perturbation to fundamental limitations in global and local explanations. For global feature importance—quantified via predictive power decomposed in terms of cross-entropy loss, Kullback-Leibler divergence, mutual information, and calibration error—the paper demonstrates that the KL-based calibration error under subset perturbations directly subtracts from interpretable mutual information between the model's restricted representation and the true target. Consequently:
- Perfect calibration under all perturbations ensures that global importance is strictly equivalent to the mutual information captured by the model's predictions conditioned on the selected features.
- For local explanations, the deviation from ideal attribution is theoretically upper-bounded by the maximum calibration error over all perturbation subsets, establishing that poor calibration can distort both quantitative and qualitative feature importances.
These findings formally motivate the need for recalibration algorithms that target the specific, high-miscalibration regime induced by explainability-oriented perturbations, rather than solely optimizing calibration for in-distribution samples.
The ReCalX Algorithm: Perturbation-level Adaptive Recalibration
To address explanation-specific miscalibration, ReCalX generalizes temperature scaling by introducing temperature parameters dependent on the perturbation level—the fraction of perturbed features. During post-hoc calibration, ReCalX partitions perturbation intensities into bins and optimizes separate temperature parameters for each, effectively minimizing the KL calibration error for all relevant perturbation levels. This approach satisfies both information preservation (componentwise monotonicity ensuring mutual information and ranking consistency) and effective reduction of miscalibration.
Implementation details include:
- Adaptive temperature selection: For each perturbed sample, infer its bin according to λ(S) and apply the corresponding temperature Tb during prediction for explanation purposes.
- Scalability: Empirical evidence demonstrates monotonic improvements as the number of perturbation bins increases, with diminishing returns beyond B=10.
- Efficiency: The only inference-time computational overhead is the selection and application of the precomputed temperature parameter.
ReCalX is also extensible to regression via monotonic post-processing techniques suitable for continuous predictive distributions.
Empirical Analysis: Calibration Error and Explanation Reliability
Calibration Error Across Tasks
Uncalibrated models exhibit substantial miscalibration under explainability-specific perturbations, with KL-based errors ranging up to 0.863 for tabular and 0.418 for image models. Standard temperature scaling, applied naively on unperturbed data, frequently fails and sometimes exacerbates calibration error on perturbed samples. In contrast, ReCalX achieves relative error reductions of 80%−97% across all evaluated settings, outperforming both baseline and conventional temperature scaling.
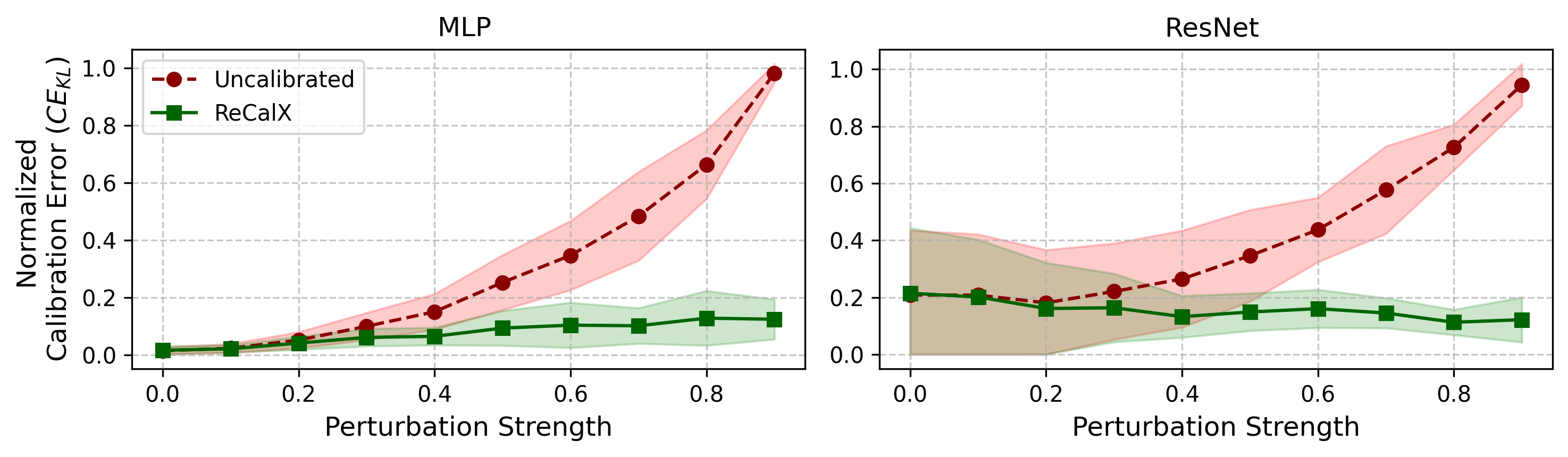
Figure 2: Calibration errors for MLP and ResNet systematically increase with greater perturbation levels across 10 tabular datasets.
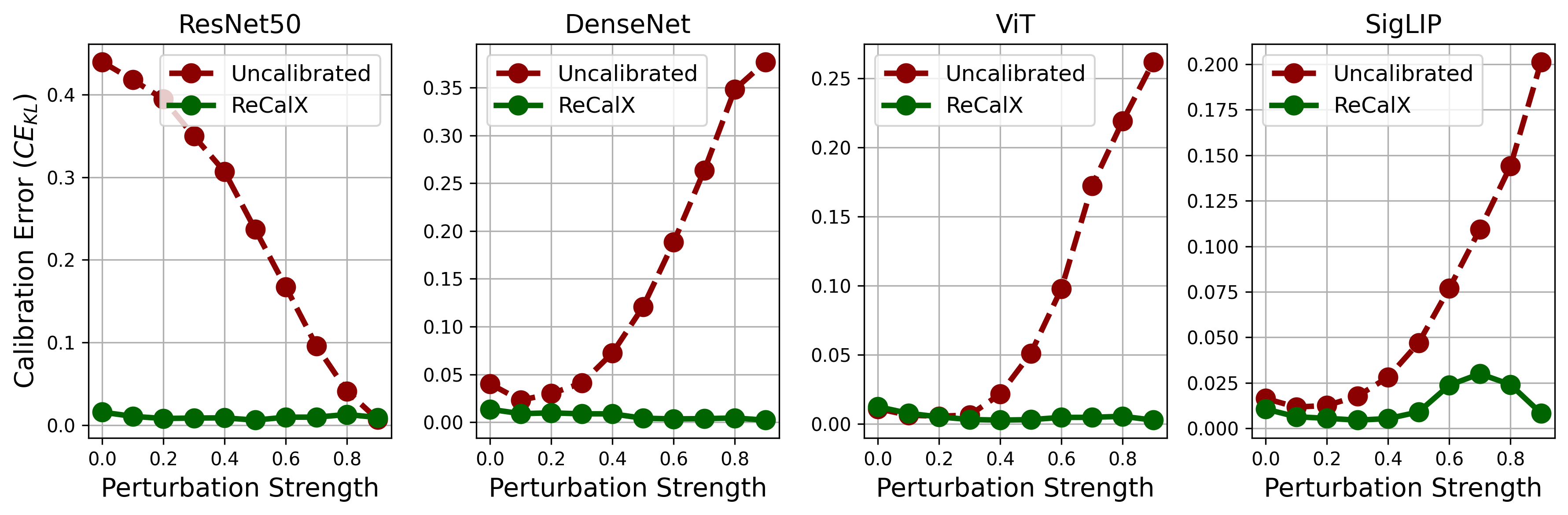
Figure 3: Calibration errors for popular image classifiers on ImageNet under zero-baseline perturbation illustrate variability across severity and underscore the need for adaptive recalibration as afforded by ReCalX.
Fidelity and Robustness of Explanations
The improvement in calibration translates directly to enhanced explanation quality:
- Global fidelity: Remove-and-retrain experiments show that, when features ranked by ReCalX-calibrated importance are removed, the resulting models suffer significantly greater performance degradation compared to removal based on uncalibrated rankings, corroborating the assertion that ReCalX accurately identifies truly informative features.
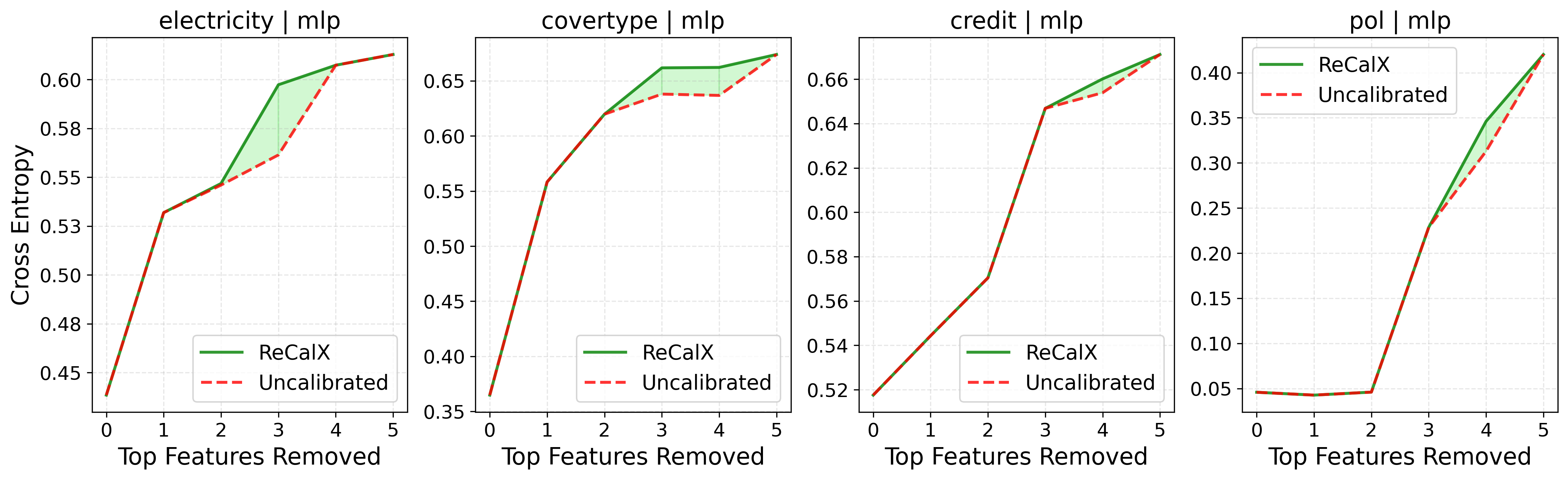
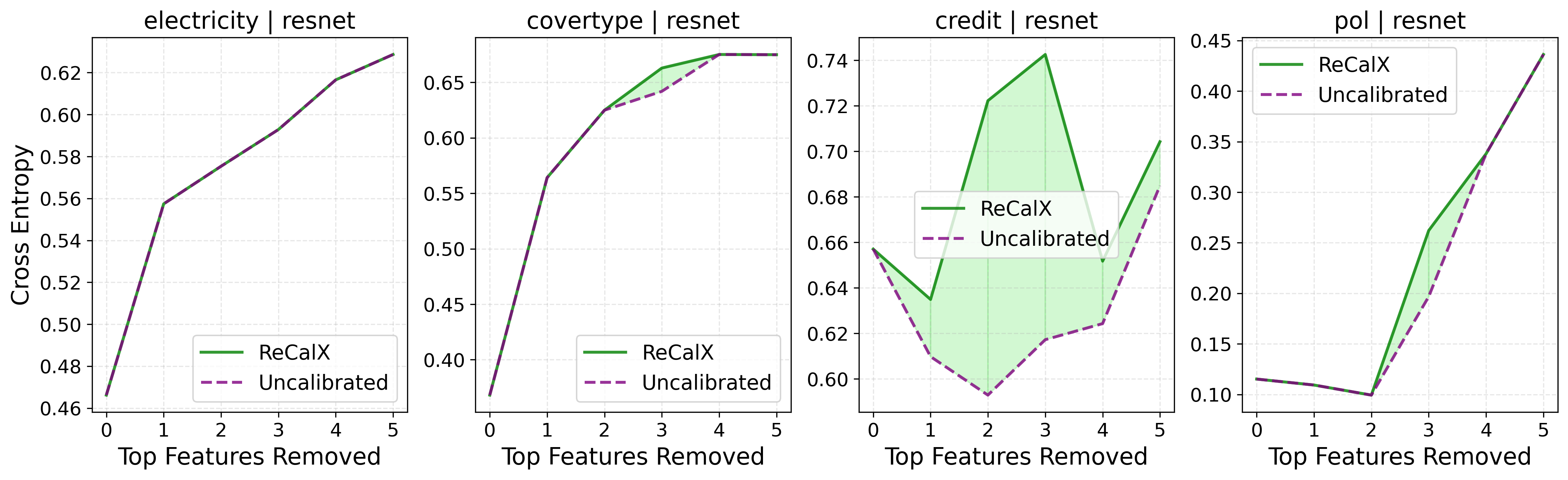
Figure 4: Removing features ranked highest by ReCalX-explanations (green area) causes greater loss increases, confirming superior detection of crucial features over uncalibrated methods.
- Robustness: Sensitivity analysis demonstrates that explanations computed after ReCalX recalibration display lower variance under small input perturbations, confirming that miscalibration correction also resolves instabilities and susceptibility to adversarial manipulation previously reported for perturbation-based XAI.
- Qualitative improvement: Visual explanations for image models become more concentrated on semantically meaningful object regions, with reduced noise and spurious attributions after applying ReCalX.
Practical Implications and Theoretical Relevance
This work fundamentally reframes explanation reliability in machine learning as not merely a property of the explanation method or perturbation strategy, but as dependent on the model's calibrated response under out-of-distribution conditions induced by explanation mechanisms. It bridges uncertainty estimation with post-hoc interpretability and sets a requirement for explanation-aware calibration as a preprocessing step for all perturbation-based XAI methods.
Practitioners must recognize that standard confidence calibration may be inadequate and can even degrade the reliability of explanations. Instead, explicit recalibration, such as ReCalX, which accounts for the specific statistics of perturbed inputs, should be considered mandatory when deploying models in settings requiring trustworthy attributions. The computational requirements for ReCalX are negligible compared to the interpretability gains, especially given the prevalence of automated monitoring and model debugging workflows depending on dependable explanations.
From a theoretical perspective, the mutual information-centric decomposition and the tight connection to proper scoring rules extend the scope of information-theoretic analyses in XAI, and open avenues for further investigation in other explanation paradigms (gradient-based, counterfactual, etc.) where similar calibration phenomena may occur.
Prospects and Future Directions
- Generalization across domains: ReCalX's principles can be tailored for time series, text, and multimodal applications, provided an analogous perturbation-level quantification.
- Integration with robust training: Preemptively training models to maintain calibration under diverse perturbations could further strengthen explanation reliability.
- Extension beyond removal-based methods: The calibration linkage may induce new evaluation metrics and recalibration strategies for saliency and counterfactual explainers subject to distribution shifts.
- Automated explanation monitoring: ReCalX can be integrated into model monitoring pipelines, enabling automatic recalibration as feature distributions shift over time.
Conclusion
Uncertainty calibration under perturbations is an essential, often neglected, prerequisite for the reliability of perturbation-based explanations. ReCalX provides a principled and practical solution by adaptively recalibrating model outputs for perturbed samples, yielding consistent improvements in explanation fidelity, robustness, and information attribution across tabular and vision tasks. Future research should investigate broader calibration-aware evaluation and extend recalibration techniques to additional explanation families and modalities.