AHA! Animating Human Avatars in Diverse Scenes with Gaussian Splatting
Abstract: We present a novel framework for animating humans in 3D scenes using 3D Gaussian Splatting (3DGS), a neural scene representation that has recently achieved state-of-the-art photorealistic results for novel-view synthesis but remains under-explored for human-scene animation and interaction. Unlike existing animation pipelines that use meshes or point clouds as the underlying 3D representation, our approach introduces the use of 3DGS as the 3D representation to the problem of animating humans in scenes. By representing humans and scenes as Gaussians, our approach allows for geometry-consistent free-viewpoint rendering of humans interacting with 3D scenes. Our key insight is that the rendering can be decoupled from the motion synthesis and each sub-problem can be addressed independently, without the need for paired human-scene data. Central to our method is a Gaussian-aligned motion module that synthesizes motion without explicit scene geometry, using opacity-based cues and projected Gaussian structures to guide human placement and pose alignment. To ensure natural interactions, we further propose a human-scene Gaussian refinement optimization that enforces realistic contact and navigation. We evaluate our approach on scenes from Scannet++ and the SuperSplat library, and on avatars reconstructed from sparse and dense multi-view human capture. Finally, we demonstrate that our framework allows for novel applications such as geometry-consistent free-viewpoint rendering of edited monocular RGB videos with new animated humans, showcasing the unique advantage of 3DGS for monocular video-based human animation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
AHA! Animating Human Avatars in Diverse Scenes with Gaussian Splatting — Explained Simply
What is this paper about?
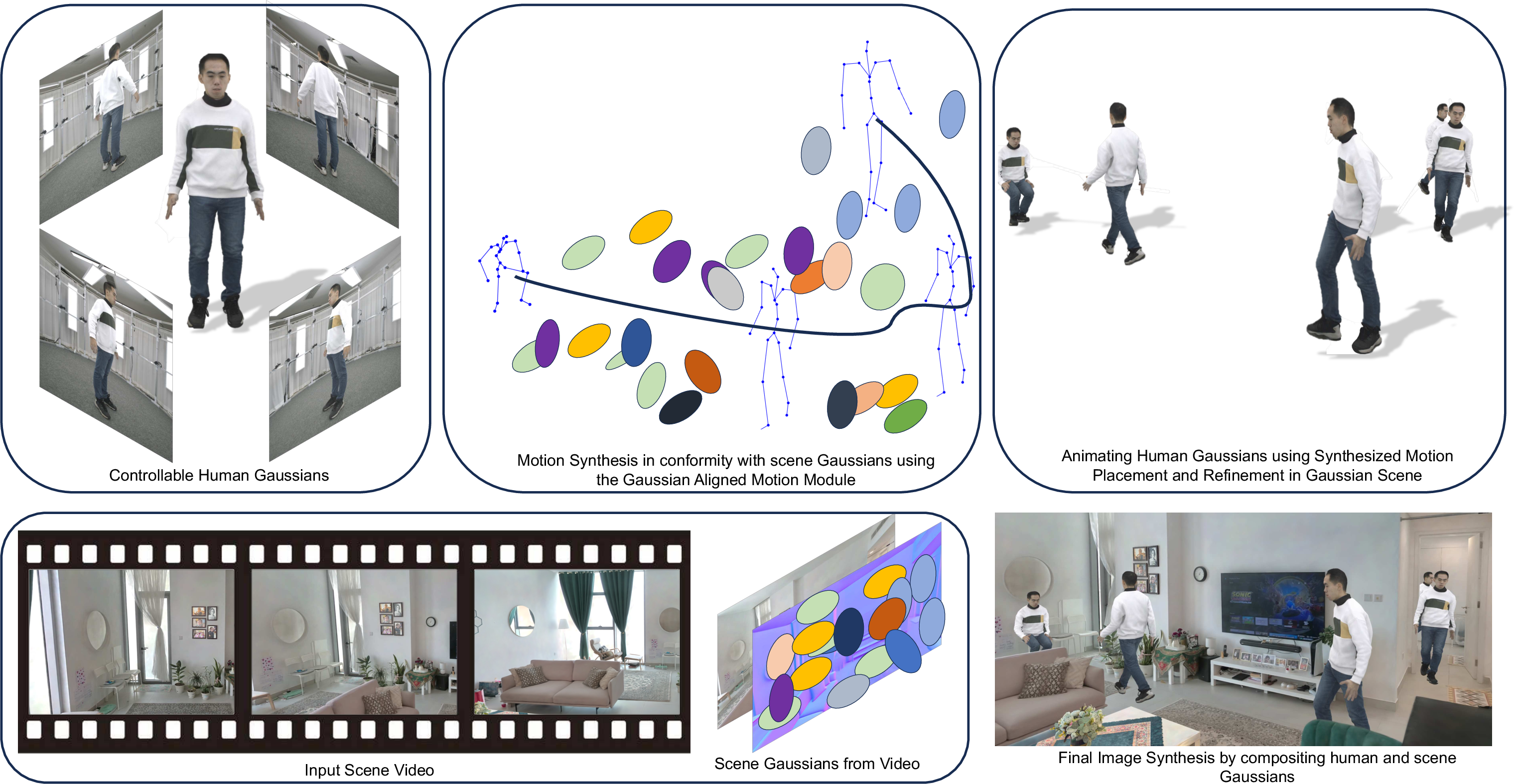
This paper shows a new way to put realistic-looking 3D people (avatars) into 3D scenes and make them move naturally. It uses a technique called 3D Gaussian Splatting, which is great at making images look photorealistic. The big idea is to use the same “language” (Gaussians) to represent both the person and the environment so they fit together well and look real from any camera angle.
Think of it like a movie set:
- The scene is the stage.
- The human is the actor.
- “Gaussian splats” are tiny, soft, colored blobs of paint in 3D that, when rendered, look like real objects and people.
What were the authors trying to do?
In simple terms, the paper tries to answer: Can we use these tiny blobs (Gaussians) not just to show scenes, but also to animate people inside those scenes in a realistic way?
Specifically, they wanted to:
- Make human avatars and 3D scenes with the same representation (Gaussians) so they blend well.
- Create natural human motion that respects the room’s layout (don’t walk through walls, place feet on the floor, sit on chairs).
- Do all this without needing special “paired” training data of humans moving in those exact scenes.
- Let people edit regular videos (even from a phone) by inserting animated humans and view the result from any angle.
How did they do it?
The approach has three main steps. You can imagine these as: build the actor, build the stage, plan the performance, then film it.
- Build the scene and the human as Gaussians
- Scene: From a video of a room, they reconstruct the environment as lots of tiny, soft 3D blobs (Gaussians). When you “splat” these blobs into the camera view, they look like a realistic photo.
- Human: From multi-view photos or videos of a person, they build a “controllable” human made of Gaussians that can be posed like a puppet. Under the hood, they use a common body model (called SMPL) to make the avatar bend its joints correctly.
- Plan the motion so it fits the scene
- Challenge: Gaussians don’t have a clean, solid surface like a mesh. So how do you avoid walls and step on floors?
- Their trick: Use what Gaussians already give you—how opaque (solid) they are and where they project in a top-down view. This is like making a simple floor plan from the blobs to see where you can walk.
- They combine two motion tools:
- A learned walking “policy” (like a smart game AI) that moves the avatar toward waypoints while avoiding obstacles detected from the Gaussian scene.
- A precise “optimizer” that fine-tunes short actions (like stopping, sitting, or reaching) right near the target. Think of it as switching from general walking to careful placing of feet and hands when you’re close to the chair or object.
- Refine contact so it looks right
- Even with good motion, feet might sink slightly into the floor or hover a bit.
- Their “refinement” step makes small adjustments to parts of the human’s Gaussians (for example, feet or hips) so contacts look natural—feet touch the floor, a body sits on a seat—without passing through surfaces.
- This works directly in Gaussian space, meaning it doesn’t need a solid mesh to check contact.
What did they find?
Here is what their experiments show and why it matters:
- More realistic renderings: When people watched videos side-by-side, the method using Gaussians was preferred over strong mesh-based baselines most of the time. That means the results looked more like real life.
- Works with regular videos: They can reconstruct scenes from a normal phone video and then insert animated humans. You can even move the camera to new angles after the fact—called free-viewpoint rendering.
- Consistent human–scene interaction: The feet, hips, and hands are better aligned with floors, seats, and objects thanks to their contact refinement, so the animation looks less “floaty” or glitchy.
In short, their method makes it easier to create photorealistic animations of people moving inside real-looking 3D places.
Why is this important?
Here are some simple reasons this matters:
- Better visuals: 3D Gaussian Splatting can look more like real photos than many classic 3D meshes, especially for lighting and texture.
- Easier to use with phone videos: You don’t need fancy scanners. A regular video can become a 3D scene where you can add people.
- New creative tools: This could help in making games, films, AR/VR content, or social media edits where you insert a person into any captured place and view it from new angles.
What are the limitations and what’s next?
The authors mention a few caveats in simple terms:
- Lighting can still be tricky, especially if it changes quickly.
- Physics isn’t fully enforced, so some movements can look real but still break physical rules slightly.
- They focus on common actions (walking, sitting, simple interactions). Very complex hand-object interactions or long, multi-step tasks are still hard.
- The best avatars currently need multi-view recordings of the person, which can be harder to capture than a single video.
They suggest future work on better lighting, more physics-aware motion, more complex interactions, and learning avatars from simpler inputs like one camera.
Takeaway
This paper shows a new path: represent both humans and scenes with the same photorealistic “blobs” (Gaussians), plan motion using smart scene cues from those blobs, and polish the contacts so everything looks right. The result: realistic people moving naturally inside realistic 3D places you can capture with a phone—then watch from any viewpoint.
Knowledge Gaps
Below is a consolidated list of concrete gaps, limitations, and open questions that remain unresolved and could guide follow-up research.
- Lack of automatic metric-scale alignment between monocular 3DGS scenes and human avatars; no principled method is provided to infer absolute scale, floor height, and root calibration from monocular reconstructions.
- Static-scene assumption: no handling of dynamic or deformable scene elements, moving obstacles, or objects that the human pushes/relocates.
- Reliance on user-provided “action points” (e.g., sit/grab locations); no automatic affordance detection or semantics-driven action selection directly from 3DGS.
- Navigation relies on 2D top-down projection of Gaussians; no 3D navigation mesh or multi-level reasoning (stairs, balconies, overhangs), risking failures in vertically complex spaces.
- Heuristic opacity thresholds and PCA alignment for occupancy estimation are not analyzed for sensitivity or failure modes (e.g., floaters, glass, reflective or translucent surfaces).
- Sim-to-3DGS gap: locomotion policy is trained in mesh environments and deployed in 3DGS without systematic evaluation of domain shift, robustness, or adaptation strategies (e.g., fine-tuning on 3DGS cues).
- The differentiable signed-distance proxy to 3DGS is not formalized or validated; uncertainty remains about its accuracy near thin structures, anisotropic splats, and non-watertight geometry.
- Contact refinement only applies small translations to a subset of human Gaussians; orientation, joint torques/rotations, and shape adjustments are not optimized, leaving foot orientation and footskate unaddressed.
- No physics-based constraints (forces, friction cones, momentum, stability) or differentiable physics are enforced; interactions can look plausible yet violate physical laws.
- Illumination is baked into Gaussians; no integrated inverse rendering or relighting for cross-scene lighting consistency between avatar and environment, especially under time-varying or complex illumination.
- Avatars require multi-view human capture; there is no monocular avatar reconstruction pipeline with guarantees for out-of-distribution poses, loose clothing, hair, or accessories.
- No analysis of runtime, memory footprint, and scalability (number of Gaussians, scene size) for training/inference; real-time rendering and motion synthesis feasibility remains unclear.
- Multi-person interactions are not supported; inter-person collisions, mutual occlusion, and joint planning are unaddressed.
- Fine-grained contact and collision with thin structures (chair legs, cables, plants) are not validated; Gaussian resolution limits and distance-proxy biases could lead to unnoticed penetrations.
- Dexterous hand-object manipulation is not modeled; grasp planning, multi-contact stability, and object state changes (rigid/deformable) in 3DGS remain open problems.
- Objective evaluation is limited: no quantitative metrics for contact accuracy, penetration depth, foot sliding, center-of-mass stability, or path efficiency; reliance on human/VLM preference introduces subjectivity.
- Baseline B is not within-scene matched and omits comparisons with other neural scene representations (e.g., NeRF- or surfel-based animation), limiting the strength of conclusions about 3DGS superiority.
- Robustness to outdoor scenes, strong specularities, and rapidly changing lighting is not demonstrated; flicker and temporal instability are unquantified.
- Monocular video editing with inserted humans lacks a complete occlusion/compositing pipeline for existing moving actors and dynamic objects (matting, depth ordering, shadow integration).
- Semantic understanding in 3DGS (e.g., category labels, instance segmentation) is not leveraged; learning-to-afford behaviors from 3DGS semantics is an open direction.
- Switching logic between RL locomotion and latent optimization (when/how to hand off control) is heuristic; no general policy optimization for multi-step tasks or sequences of actions is provided.
- Failure recovery and long-horizon planning are not addressed (e.g., re-planning after local minima, loop closure, drift correction).
- The impact of 3DGS artifacts (floaters, misregistration, view-dependent color leaking) on motion planning and contact optimization is not quantified; no automatic artifact suppression is proposed.
- Occlusion ordering and depth compositing between separately reconstructed human and scene Gaussians can be inconsistent; no guarantees for temporally coherent z-ordering or alpha blending are provided.
- Ethical, privacy, and consent considerations for avatar capture, as well as biases in the mocap data used for the motion prior, are not discussed.
- Reproducibility details (code, model weights, hyperparameters for RL/latent optimization, datasets for human studies) are not specified, limiting independent verification and benchmarking.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s framework and components (3DGS scene reconstruction, animatable Gaussian avatars, Gaussian-aligned motion module, and contact refinement). Each item includes likely sectors, potential tools/workflows, and assumptions or dependencies that affect feasibility.
- Photoreal free-viewpoint video editing with inserted humans
- Sectors: media/entertainment, social apps, advertising
- Tools/workflows: mobile capture of a monocular scene video → 3DGS reconstruction → select/reconstruct an animatable Gaussian avatar → specify waypoints/actions (walk, sit, grab) → render multi-view outputs; “AHA Studio” or a plugin for existing 3DGS editors
- Assumptions/dependencies: scenes are mostly static; access to GPU for 3DGS; avatars require multi-view capture or existing 3DGS avatars; lighting remains stable for good photorealism
- Previsualization for film/CGI and creative blocking
- Sectors: film/TV/VFX, virtual production
- Tools/workflows: quickly block and iterate on actor movement in captured sets using Gaussian-aligned RL locomotion and latent transition optimization; export shot plans from free-viewpoint renders
- Assumptions/dependencies: actor avatars reconstructed from multi-view; limited relighting and physics fidelity compared to full simulation; scene scan permissions
- Architectural visualization and interior walkthrough evaluation
- Sectors: architecture, real estate, facilities planning
- Tools/workflows: capture building or room with a phone; use opacity-thresholded Gaussian projections to generate walkability maps and simulate occupant paths; render photoreal walkthroughs with avatars for ergonomics or access checks
- Assumptions/dependencies: static environments; pathfinding via projected occupancy is approximate; contact refinement improves plausibility but not strict physics
- Game prototyping with real-world captured levels
- Sectors: gaming, XR
- Tools/workflows: turn a mobile video of a location into a 3DGS “level”; drop in animated NPC avatars using RL locomotion in Gaussian space; prototype missions and interactions without building meshes; potential Unreal/Unity viewer integration for Gaussian assets
- Assumptions/dependencies: 3DGS runtime/viewer integration; mesh-centric engines may need bridge tooling; limited dynamic lighting and physics
- Retail and showroom visualization with scale references
- Sectors: retail/e-commerce, interior design
- Tools/workflows: place avatars to demonstrate human scale and product use in a captured environment (e.g., sitting on a chair location); rely on latent optimization for sit/stop transitions; export photoreal renders for marketing
- Assumptions/dependencies: target action points provided; accurate furniture placement not guaranteed without extra constraints; stable lighting preferred
- Synthetic data generation for computer vision
- Sectors: software/AI, robotics research
- Tools/workflows: generate labeled, photoreal images/sequences of human-scene interactions from diverse captured scenes; control motion via text cues and waypoints; augment datasets for pose estimation or affordance learning
- Assumptions/dependencies: labels for ground truth must be defined (e.g., projected joints, contact indices); physics realism is limited; domain diversity tied to scene capture quality
- Training and safety demos in facilities
- Sectors: industrial training, operations, public safety
- Tools/workflows: produce photoreal training videos where avatars navigate real facilities (e.g., evacuation routes), using the Gaussian scene to derive obstacle maps and safe paths; use free-viewpoint renders for different vantage points
- Assumptions/dependencies: no full physics; motion plausibility guided by kinematics and simple proximity; static scene scans required
- Education and communication of human movement in environments
- Sectors: education, sports/biomechanics communication
- Tools/workflows: show how movement and contact occur in a classroom, lab, or gym captured from phone video; leverage contact refinement to reduce penetrations and improve visual clarity; export annotated sequences
- Assumptions/dependencies: educational use tolerates limited physics; avatar identity requires multi-view capture or library avatars
- Real estate marketing and virtual tours with occupants
- Sectors: real estate, marketing
- Tools/workflows: insert avatars into 3DGS tours to showcase room usage (e.g., cooking, sitting), render paths and interactions from any viewpoint; streamline content creation for listings
- Assumptions/dependencies: static property scans; motion templates cover common activities; permissions for capturing interiors
- Rapid research prototyping on human–scene interaction with photoreal rendering
- Sectors: academia (vision/graphics), HCI
- Tools/workflows: use the pipeline to test motion synthesis and placement hypotheses in Gaussian scenes; avoid mesh conversion; run user studies on photoreal stimuli
- Assumptions/dependencies: availability of animatable Gaussian avatars; compute resources; current interaction repertoire (walk, sit, reach) is limited
Long-Term Applications
These opportunities require further research and engineering (e.g., robust relighting, physics integration, real-time operation, richer interactions, single-view avatar reconstruction).
- Real-time AR insertion of animated avatars into live monocular video
- Sectors: AR/VR, social apps, live events
- Tools/products: “3DGS Lens” for phones/glasses that reconstructs scenes on-the-fly and inserts controllable avatars in real time
- Dependencies: fast 3DGS reconstruction and rendering; low-latency motion synthesis; dynamic illumination handling; sensor fusion
- Physics-consistent interaction and manipulation
- Sectors: robotics simulation, VFX/CG, training
- Tools/products: physics-augmented Gaussian refinement with differentiable or learned physics; grasping/manipulation libraries over Gaussian scenes
- Dependencies: robust contact dynamics, stability, momentum conservation; scene semantics (object types, friction) and material models
- Multi-person, long-horizon, multi-contact behaviors
- Sectors: crowd simulation, venue planning, entertainment
- Tools/products: multi-agent motion synthesis on Gaussian maps; scheduling and social spacing constraints; event previsualization
- Dependencies: scalable controllers; collision avoidance; identity-agnostic coordination; richer action sets
- Robotics navigation policy training from phone-scanned environments
- Sectors: robotics, autonomous systems
- Tools/products: pipeline to convert Gaussian scenes to occupancy and cost maps; policy transfer frameworks that bridge 3DGS-derived cues to real sensors
- Dependencies: sim-to-real gap mitigation; dynamic obstacles; sensor-specific noise modeling; standardized export formats
- Telepresence with personalized animatable Gaussian avatars
- Sectors: communication, enterprise collaboration
- Tools/products: avatar capture from minimal inputs; insertion into remote 3DGS spaces; free-viewpoint telepresence sessions
- Dependencies: monocular-to-animatable Gaussian avatar reconstruction; real-time networking and rendering; privacy and consent mechanisms
- At-home rehabilitation and ergonomic coaching
- Sectors: healthcare, occupational safety
- Tools/products: guided exercises visualized with photoreal avatars inside the patient’s own home scan; posture feedback against scene fixtures
- Dependencies: medically validated motion libraries; reliable single-view avatar reconstruction; accurate contact and load modeling
- Smart home and facility planning using realistic occupant flow
- Sectors: smart buildings, operations
- Tools/products: planners that simulate occupant behavior over 3DGS scans; evaluate bottlenecks and accessibility
- Dependencies: behavior models; long-term scheduling; semantic segmentation of Gaussian scenes; energy-aware simulation
- Standardization and tooling around a Gaussian Scene Format (GSF)
- Sectors: software, content pipelines
- Tools/products: interchange standards, viewers, converters (GSF↔meshes/point clouds); SDKs for motion insertion and refinement
- Dependencies: community adoption; compatibility with existing engines; authoring tools and asset libraries
- Interactive commerce and personalized product try-on in the home
- Sectors: retail/e-commerce
- Tools/products: avatars demonstrating product use (e.g., furniture, fitness gear) within user-captured spaces; dynamic relighting for realism
- Dependencies: advanced relighting and material estimation; accurate size calibration; legal compliance for in-home scans
- Cultural heritage and museum experiences with guided virtual visitors
- Sectors: culture, education
- Tools/products: 3DGS reconstructions of sites with avatar-guided tours; multi-view narrative experiences
- Dependencies: high-fidelity capture; crowd behaviors; accessibility adaptations; curatorial policies
- Policy and governance frameworks for scanned environments and avatars
- Sectors: policy/regulation
- Tools/products: privacy-preserving pipelines (on-device reconstruction, consent tracking), watermarking of synthetic content, provenance metadata for renders
- Dependencies: standards for disclosure and labeling; secure storage and access controls; legal clarity on scanning private spaces
- High-fidelity relighting and appearance transfer for realistic compositing
- Sectors: VFX, advertising
- Tools/products: inverse rendering for 3DGS; material/BRDF estimation; environment light capture and transfer
- Dependencies: robust inverse methods; calibration hardware/software; integration with DCC tools
Cross-cutting assumptions and dependencies
- Static scenes and modest lighting changes are preferred; dynamic illumination and moving objects currently pose challenges.
- Animatable Gaussian avatars typically require multi-view human capture; generalizing to single-view capture and out-of-distribution poses is ongoing work.
- Contact refinement improves plausibility but does not enforce full physical correctness.
- Deployment requires GPU acceleration and 3DGS tooling (viewer, renderer, reconstruction).
- Scene privacy, consent, and content provenance must be addressed for consumer and enterprise use.
Glossary
- 3D Gaussian Splatting (3DGS): A neural scene representation that models scenes as collections of 3D Gaussian primitives and renders them by splatting onto the image plane for photorealistic novel-view synthesis. "We present a novel framework for animating humans in 3D scenes using 3D Gaussian Splatting (3DGS)"
- A* Pathfinding: A graph search algorithm that finds shortest paths using heuristics; used here on projected 3DGS obstacles to plan navigation routes. "render a binary map of obstacles and run A* for pathfinding"
- Alpha compositing: A rendering technique that combines semi-transparent layers front-to-back using opacity to produce the final image. "The rendered image is obtained via front-to-back alpha compositing,"
- AMASS: A large motion capture dataset aggregating many mocap sources, used to train motion priors. "We adopt a latent motion prior, following prior work \cite{Zhao:DartControl:2025} trained on AMASS \cite{BABEL:CVPR:2021, mahmood19amass}."
- Anisotropic 3D Gaussians: Gaussian primitives with direction-dependent covariance used to represent scene geometry in 3D. "we model the environment as a set of anisotropic 3D Gaussians"
- Canonical Gaussian parameterization: Defining human Gaussians in a pose-independent, canonical space (e.g., on a template) before skinning to posed space. "Step 1: Canonical Gaussian parameterization on SMPL."
- DDIM sampler: A deterministic diffusion sampling method that enables controlled generation without stochastic step noise. "we adopt a deterministic DDIM sampler (no step-skipping)"
- Diffusion prior: A probability model over latent codes learned via diffusion processes to generate plausible motion sequences. "and places a diffusion prior in this latent space."
- Egocentric occupancy grid: A local, agent-centered binary map indicating free and occupied cells for navigation. "The policy consumes an egocentric occupancy grid/walkability map centered on the agent."
- Gaussian-aligned motion module: A motion synthesis controller that uses cues derived from 3DGS (opacity/projections) to align human motion with scene structure. "Central to our approach is a novel Gaussian-aligned motion module (Sec. \ref{sec:motion-gaussian})"
- Gaussian rasterizer: The renderer that composites 3D Gaussian splats into images using the 3DGS pipeline. "rendered with the standard 3DGS rasterizer"
- Latent motion backbone: The core learned model that encodes/decodes human motion into a compact latent space for controllable synthesis. "Latent motion backbone."
- Latent-space optimizer: A deterministic optimization over diffusion latent variables to precisely achieve task goals (e.g., sit, grasp) under constraints. "a deterministic latent-space optimizer that executes short, fine-grained actions near targets"
- Linear blend skinning (LBS): A standard character animation technique that deforms canonical geometry using weighted bone transformations. "We obtain posed Gaussians by applying linear blend skinning (LBS) to canonical Gaussians"
- MDP (Markov Decision Process): A formal model for sequential decision-making used to frame locomotion control in latent action space. "We cast navigation as an MDP whose action space is the latent space of the motion model."
- Monocular video: Single-camera video input, used here to reconstruct 3DGS scenes enabling free-viewpoint rendering. "3DGS allows for reconstructing scenes with only a monocular video"
- Navigation mesh: A walkable surface representation used for pathfinding; here approximated from 3DGS via projection. "approximate navigation meshes via orthographic projection"
- NeRF: Neural Radiance Fields, a volumetric neural rendering approach for novel-view synthesis. "neural scene representations have emerged, beginning with NeRF \cite{mildenhall2020nerf}"
- Novel-view synthesis (NVS): Rendering of scenes from viewpoints not present in the input data. "and NVS from sparse cameras"
- Opacity field: Spatial distribution of transparency in 3DGS used as a cue for placement and collision avoidance. "its opacity fields and projected Gaussian structures offer sufficient cues"
- Orthographic projection: A projection method without perspective used for atlas construction and scene flattening for navigation. "via orthographic projections of the SMPL mesh."
- PCA (Principal Component Analysis): A dimensionality reduction technique used to form a pose subspace for fast inference. "compute the top PCA components of training pose maps"
- Photometric loss: A reconstruction objective comparing rendered and observed pixel colors to optimize 3DGS parameters. "optimized with the standard 3DGS photometric loss across frames."
- Pose map: A rasterized representation of pose-conditioned features on a UV atlas serving as input to the avatar network. "rasterize pose-conditioned features into a pose map "
- Reinforcement learning (RL): A learning paradigm for training policies via rewards; here used for locomotion in Gaussian space. "we deploy reinforcement learning (RL) in Gaussian space"
- Signed-distance proxy: A differentiable approximation to the distance to scene surfaces, used for collision and contact modeling. "ϕ(·) is a differentiable signed-distance proxy to 3DGS Gaussians ."
- SMPL: A parametric human body model with shape and pose parameters used to anchor and skin human Gaussians. "animated with different SMPL poses"
- SMPL-X: An extended SMPL model including hands and face articulation; used for motion parameter generation. "use \cite{zhao2023dimos} to generate SMPL-X parameters."
- Splatting algorithm: The rendering technique that projects Gaussian primitives into 2D and composites them into images. "3DGS rasterizes Gaussian primitives into images using a splatting algorithm \cite{westover1991phdsplatting}."
- StyleUNet: A UNet-based neural network with style conditioning that predicts canonical human Gaussians from pose maps. "A per-identity StyleUNet predicts a set of canonical human Gaussians"
- UV atlas: A mapping of a 3D surface to 2D coordinates used to place Gaussians on the SMPL surface. "constructing an approximate front--back UV atlas via orthographic projections of the SMPL mesh."
- View-dependent color: Appearance modeled as a function of view direction for greater photorealism in 3DGS. "and possibly view-dependent color ."
- Vision–LLM (VLM): Models that jointly process images and text; used for automated photorealism judgments. "We use two strong visionâLLM (VLM): GPT-5 \cite{openai2025gpt5} and Gemini2.5 \cite{comanici2025gemini25pushingfrontier} as paired comparators between still renderings."
- Watertight surfaces: Surface meshes with no holes; 3DGS lacks explicit watertight topology, complicating contact modeling. "even though 3DGS does not provide watertight surfaces"
Collections
Sign up for free to add this paper to one or more collections.