Out-of-Distribution Generalization with a SPARC: Racing 100 Unseen Vehicles with a Single Policy
Abstract: Generalization to unseen environments is a significant challenge in the field of robotics and control. In this work, we focus on contextual reinforcement learning, where agents act within environments with varying contexts, such as self-driving cars or quadrupedal robots that need to operate in different terrains or weather conditions than they were trained for. We tackle the critical task of generalizing to out-of-distribution (OOD) settings, without access to explicit context information at test time. Recent work has addressed this problem by training a context encoder and a history adaptation module in separate stages. While promising, this two-phase approach is cumbersome to implement and train. We simplify the methodology and introduce SPARC: single-phase adaptation for robust control. We test SPARC on varying contexts within the high-fidelity racing simulator Gran Turismo 7 and wind-perturbed MuJoCo environments, and find that it achieves reliable and robust OOD generalization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots and AI agents to handle new, surprising situations they weren’t specifically trained for. The authors focus on a racing game called Gran Turismo 7 and some robot simulations. They introduce a simpler training method, called SPARC, that helps an AI driver adapt to different cars and changing conditions, even when it doesn’t get told what is different during a race.
What problem are they trying to solve?
In the real world, things change: a car’s grip can vary with weather, a robot can face strong winds, or a vehicle might have very different weight or power. AI agents trained in one set of conditions often fail when they meet new ones. The big question is: how can we make AI agents that learn to adjust on the fly to “out-of-distribution” situations—new contexts they didn’t train on—without being told exactly what changed?
To make that clearer:
- “Context” means hidden factors like wind, road surface, car weight, engine power, or tire grip.
- “Out-of-distribution (OOD)” means situations that differ a lot from the training examples.
- The agent must figure out what’s going on from experience and recent actions, not from a label that says, “Your car is heavier today” or “There’s more wind.”
How does their method work?
Think of a skilled driver jumping into a new car without any specs. They press the gas, steer, brake, and quickly “feel” how the car responds, then adjust their driving. SPARC does something similar with AI:
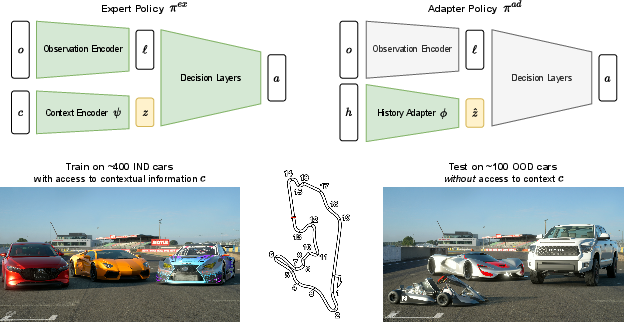
- It trains two parts at the same time:
- An “expert” policy that knows the true context during training (like having the car’s secret specs) and learns how best to drive in each situation.
- An “adapter” policy that does not get the true context, but instead looks at a short history of observations and actions—what it sensed and did recently—to infer what the context probably is. This is like the driver feeling the car’s behavior to guess its characteristics.
- The adapter learns to produce a “context-like” internal signal from history that matches what the expert’s context encoder produces from the true context. In everyday terms: the adapter becomes good at guessing the hidden situation just by watching how the car responds.
- Unlike older methods (like RMA) that train in two separate stages, SPARC trains everything in one go. That makes it simpler to implement and easier to continue training over time.
A few technical ideas explained simply:
- “Reinforcement Learning (RL)” is learning by trial and error: the agent tries actions, gets rewards (like faster lap times), and improves.
- “History” is a short memory of recent observations and actions. It helps the agent detect patterns, like “my steering feels sluggish—maybe the car is heavier.”
- “Single-phase” means both the expert and adapter are trained together, not one after the other. This avoids the hassle of stopping, picking the “best checkpoint,” and restarting a second phase.
What did they test?
They tested SPARC in two kinds of environments:
- Gran Turismo 7: The agent races many different cars on several tracks. It must adapt to car models it never trained on, and to changes like different engine power and mass. They also tested what happens when the game’s physics get updated.
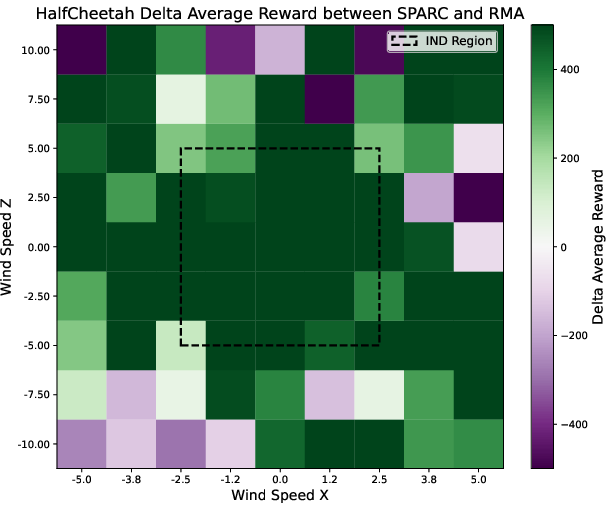
- MuJoCo (robot simulation): Tasks like running and hopping with random wind forces pushing the robot, including wind settings the agent never saw during training.
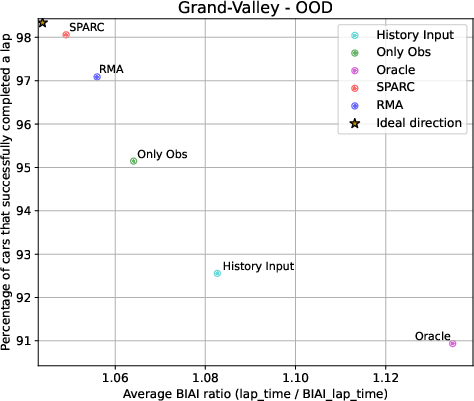
To measure performance in Gran Turismo:
- They compared lap times to the game’s built-in AI (BIAI). A lower “BIAI ratio” means faster laps relative to that baseline.
- They also counted how often the agent could complete a lap at all, since very difficult cars can cause crashes or failures.
What did they find, and why is it important?
Here are the main results:
- In Gran Turismo 7, SPARC generally beat methods that don’t use context at test time and often beat the two-stage RMA method too. It completed laps more reliably and achieved faster normalized lap times with many unseen cars.
- In the car power/mass experiments, SPARC was the most robust—almost always completing laps—and had the best average lap times among methods that don’t get context at test time.
- In MuJoCo, SPARC performed best in 2 out of 3 tasks when facing new wind conditions.
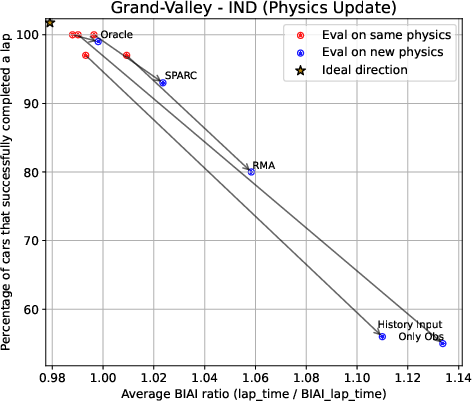
- When Gran Turismo’s physics changed (like a game update), SPARC handled the shift better than other methods, showing strong “transfer” to updated dynamics.
Why this matters:
- Real robots and autonomous systems often can’t get perfect context labels (nobody hands them a note saying “it’s windy and your tires are cold”). They must infer the context from experience.
- SPARC’s single-phase design makes training simpler and supports continual learning, which is useful for devices that update themselves over time, possibly even on-device.
- More robust generalization means safer, more reliable performance in real-world conditions.
What does this mean for the future?
If an AI can quickly adapt to new contexts without being told what changed, it’s closer to handling the messy, unpredictable real world. This could help:
- Self-driving cars adjust to new roads or weather without manual retuning.
- Robots operate safely across changing terrains or loads.
- Simulation-trained agents transfer better to the real world.
The authors suggest future steps like testing on physical robots and making training even more efficient. Overall, SPARC is a promising step toward AI that can “feel and adapt” like a skilled human, rather than breaking when things aren’t exactly like training.
Knowledge Gaps
Below is a single, concrete list of the key knowledge gaps, limitations, and open questions left unresolved by the paper. Each point is phrased to enable actionable follow-up work.
- No validation on physical robots or hardware-in-the-loop; sim-to-real transferability of SPARC remains untested.
- Adaptation speed is not measured: how many steps of history are needed for the adapter to reliably infer and react to a new context?
- Context is treated as stationary within an episode; robustness to abrupt, within-episode context shifts (e.g., sudden weather/terrain changes) is unknown.
- Theoretical understanding is missing: no convergence or stability analysis for learning with a non-stationary context-encoding target (moving teacher).
- The schedule/frequency for copying weights between expert and adapter (and its stability/learning impact) is unspecified and not ablated in the main text.
- Critic networks use privileged context during training; the effect of removing or corrupting this privilege (train–test mismatch risk) is not studied.
- Claims about continual/on-device learning are not empirically demonstrated; no experiments on online adaptation, learning under non-stationarity, or catastrophic forgetting.
- Comparison set omits strong meta-RL and recurrent baselines (e.g., RL2, PEARL, R2D2/IMPALA/DrQ-v2 with LSTM/TCN); it remains unclear how SPARC fares against these.
- Oracle baseline lacks history input, likely handicapping it; an “Oracle + history” control is needed for a fairer comparison.
- Sample complexity and wall-clock training cost are not reported; relative efficiency vs RMA (and vs pure history baselines) is unknown.
- Failure modes are not analyzed: which context dimensions (e.g., drivetrain, tire model, power-to-weight extremes) cause breakdowns, and why?
- Learned latent representations (z and z-hat) are uninterpreted; which physical factors they encode and how they evolve during training is unknown.
- No uncertainty calibration or OOD detection for inferred context; the agent cannot recognize when it is outside its competency region.
- Evaluation focuses on telemetry/state observations; robustness with high-dimensional vision inputs and visual domain shifts is untested.
- Generalization to unseen tracks/layouts is not evaluated; results are limited to three seen tracks and do not probe track-level OOD.
- OOD car selection via isolation forest is not validated against dynamic difficulty; the relationship between anomaly score, physical differences, and control difficulty remains unclear.
- The BIAI-ratio metric caps failures at 2.0; no sensitivity analysis shows how results change under different failure penalties or metrics capturing safety (offs, collisions).
- Safety considerations (collision rates, off-track durations, near misses) are not reported; finishing a lap may mask risky policies.
- Context types are limited (wind, power/mass, car models); key real-world shifts (tire friction changes, road surface wetness, actuator delay, sensor noise/latency, partial sensor failures) are not tested.
- Robustness to sensing artifacts (delays, dropouts, asynchronous sensors) is not assessed.
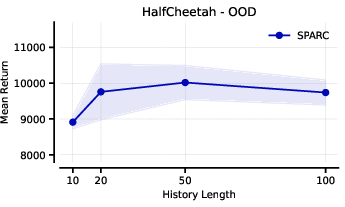
- Adaptation-history design is underexplored: how to choose history length H, buffer composition, and memory/compute trade-offs across tasks is unclear.
- Checkpoint/model selection uses only IND evaluations; strategies for OOD-aware selection (e.g., proxies, coverage metrics) are not investigated.
- Physics-update transfer is demonstrated but not quantified in terms of what changed; the repeatability and severity of the shift are unknown to the community.
- Reproducibility barrier: GT7 is proprietary; it is unclear how much of the setup (assets, physics versions, evaluation harness) others can replicate.
- Applicability beyond QR-SAC is unverified; whether SPARC’s single-phase approach carries over to other off-policy/on-policy algorithms is unknown.
- Alternative adapter-training objectives are unexplored (e.g., contrastive/InfoNCE, BYOL-style targets, variational/auxiliary dynamics prediction), which might stabilize the moving-target issue.
- The effect of domain randomization itself is not isolated; ablating or varying randomization strength could clarify its contribution vs SPARC’s.
- Stress tests at more extreme OOD scales (farther beyond 2× ranges) are missing; limits of extrapolation remain unknown.
- Multi-agent interactions (overtaking, blocking, drafting) are not studied; SPARC’s behavior under opponent-induced non-stationarity is an open question.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with minimal additional research, leveraging SPARC’s single-phase context adaptation, history-based inference, and demonstrated robustness to out-of-distribution (OOD) dynamics.
- Sector: Gaming and Simulation (Racing)
- Application: Adaptive AI drivers that generalize to hundreds of unseen cars, tracks, and physics patches without re-training.
- Tools/Products/Workflows: Integrate SPARC policy into game AI stack; maintain a short rolling history buffer at inference; QA/playtesting automation suite that stress-tests across newly released vehicles and physics updates.
- Assumptions/Dependencies: Access to simulator telemetry for training with privileged context; safe driving constraints (e.g., penalties for collisions); compute budget for asynchronous/distributed off-policy training; inference runs adapter-only (no privileged context).
- Sector: Gaming QA/DevOps
- Application: Regression testing harness that flags performance regressions across physics updates using OOD-generalizing agents.
- Tools/Products/Workflows: CI pipeline that runs SPARC agents on nightly builds; dashboards tracking BIAI-normalized lap times and success rates per asset patch.
- Assumptions/Dependencies: Stable reward metrics; reproducible seeds; access to pre/post-patch binaries.
- Sector: Automotive OEMs and Tier-1s (Simulation)
- Application: Controller prototyping that transfers across trims/SKUs (mass, power, tire friction) with minimal re-tuning.
- Tools/Products/Workflows: Vehicle-in-the-loop simulation; SPARC training with varied vehicle parameters as privileged context; deployment of adapter-only inference for black-box test sessions.
- Assumptions/Dependencies: High-fidelity sim and coverage of likely parameter ranges; safety envelopes and fallback controllers; telemetry logging for post-hoc analysis.
- Sector: Robotics—Legged Locomotion in Labs and Controlled Facilities
- Application: Robust locomotion controllers across terrains and payload changes without needing explicit context labels at deployment.
- Tools/Products/Workflows: On-device adapter with small history window; lab training with privileged terrain/payload labels; continual learning capability on-device for facility-specific adaptation.
- Assumptions/Dependencies: Safety monitors (e.g., velocity/torque limits); representative training contexts; reliable proprioceptive history capture.
- Sector: Robotics—Mobile Platforms in Warehouses
- Application: AGVs/AMRs that adapt to floor friction, payload shifts, and wind from HVAC without environment retuning.
- Tools/Products/Workflows: SPARC-based speed/steering controllers; domain randomization of friction/payload; telemetry-based A/B test harness on test tracks before rollout.
- Assumptions/Dependencies: Known operational envelope; fallback MPC; compliance with facility safety protocols.
- Sector: Drones/UAV (Test Fields, Non-critical)
- Application: Gust-robust flight control using history-inferred latent context for wind without onboard wind sensors.
- Tools/Products/Workflows: Simulation with wind fields as privileged training context; adapter-only inference on embedded hardware; rapid re-validation after firmware updates.
- Assumptions/Dependencies: Flight safety geofencing; certification not required for mission-critical operations; compute-fit models on edge SoCs.
- Sector: Industrial Automation (Pilot lines)
- Application: Process controllers that adapt to drift (e.g., viscosity, temperature) based on interaction history, reducing retuning cycles.
- Tools/Products/Workflows: Historian-integrated SPARC controller; guardrails for setpoint deviations; shadow-mode deployment before switching to active control.
- Assumptions/Dependencies: Reliable surrogate reward; drift stays within trained envelope; easy rollback to PID/MPC.
- Sector: MLOps/Platforms
- Application: Simplified RL adaptation pipelines—no two-phase checkpoint selection; continuous training and rollout with asynchronous workers.
- Tools/Products/Workflows: SPARC training template; model registry with adapter-only deployment artifact; evaluation via Pareto-front across IND metrics; automated rollback on OOD drift.
- Assumptions/Dependencies: Off-policy infrastructure (e.g., QR-SAC or SAC); data versioning; monitoring for non-stationary targets during training.
- Sector: Education/Academia
- Application: Teaching labs and benchmarks for contextual RL without test-time context—SPARC reduces implementation friction versus RMA.
- Tools/Products/Workflows: Course modules using the open-source SPARC repo; MuJoCo wind benchmarks; ablation studies on history length and rollout policy choice.
- Assumptions/Dependencies: Access to MuJoCo/GT-like simulators; GPUs for off-policy training.
- Sector: Consumer Robotics (Prototyping)
- Application: Floor-care robots (vacuums/mops) adapting to surface changes (carpet/tile/wet patches) via history instead of explicit sensors or labels.
- Tools/Products/Workflows: Synthetic training with privileged labels (surface type) and domain randomization; adapter-only on-device inference.
- Assumptions/Dependencies: Safety constraints for motors; battery/compute budgets; representative training diversity.
Long-Term Applications
These opportunities require further research, scaling, safety validation, or regulatory clearance before wide deployment.
- Sector: Autonomous Driving (On-road)
- Application: Vehicle control layers that adapt across weather, tires, load, and minor hardware variations without relying on explicit context at runtime.
- Tools/Products/Workflows: Multimodal history buffer; integration with safety cages and planners; continuous learning under privacy constraints (federated or on-device).
- Assumptions/Dependencies: Safety certification for adaptive RL; rigorous failover to rule-based controllers; extensive OOD coverage and interpretability of latent context.
- Sector: Healthcare and Assistive Robotics
- Application: Exoskeletons/prosthetics adapting to patient-specific gait and changing conditions (fatigue, footwear) from short interaction history.
- Tools/Products/Workflows: Clinical digital twin for training with privileged context; compliance with medical device regulations; clinician-in-the-loop tuning.
- Assumptions/Dependencies: Patient safety and comfort constraints; generalization across populations; transparent adaptation logs.
- Sector: Energy and Grid Operations
- Application: Controllers that adapt to variable renewable inputs (wind/solar intermittency) and equipment aging using history-inferred latent states.
- Tools/Products/Workflows: Simulator-in-the-loop training with privileged context (true wind/load traces); adapter-only deployment in supervisory roles.
- Assumptions/Dependencies: Strict safety envelopes; operator override; certified testing on digital twins before real grid integration.
- Sector: Logistics and Manipulation
- Application: Robotic pick-and-place adapting to varying payloads, grips, and object friction without per-SKU retuning.
- Tools/Products/Workflows: Synthetic training with privileged object parameters; on-device adapter with short memory; automatic SKU onboarding workflow.
- Assumptions/Dependencies: Robust perception-to-control interface; collision-safe motion planning; coverage of edge-case objects in training.
- Sector: Agriculture Robotics
- Application: Field robots adapting to soil conditions, crop density, and implement wear using history rather than explicit sensors.
- Tools/Products/Workflows: Farm digital-twin training; continuous on-device learning bounded by safety rules; seasonal OOD testing.
- Assumptions/Dependencies: Weather/terrain variability beyond training; minimal operator intervention; maintainability in harsh environments.
- Sector: Smart Buildings/HVAC
- Application: Controllers adapting to occupancy, weather, and structural changes (e.g., retrofits) without explicit labels, improving comfort/efficiency.
- Tools/Products/Workflows: Simulation-based training with privileged context (ground-truth occupancy/weather); adapter-only rollout; safe exploration limits.
- Assumptions/Dependencies: Strong comfort and energy-use constraints; explainability; integration with BMS and occupant privacy protections.
- Sector: Finance (Experimental)
- Application: Strategy controllers that infer market regime shifts from short history windows and adapt without explicit regime labels.
- Tools/Products/Workflows: Backtesting with regime-labeled privileged context for training; adapter-only live inference; risk controls and kill switches.
- Assumptions/Dependencies: High non-stationarity; regulatory compliance; difficulty defining rewards aligned with risk-adjusted returns.
- Sector: Policy and Standards
- Application: Benchmarks and certification frameworks for OOD generalization in RL (standardized CMDPs, history-based inference tests).
- Tools/Products/Workflows: Public OOD suites (e.g., wind-perturbed control, asset-variant driving); reporting standards (success rate plus normalized performance); audit trails for online adaptation.
- Assumptions/Dependencies: Cross-industry buy-in; shared simulators/datasets; guidelines for online adaptation logging and rollback.
- Sector: Cross-Simulator and Sim-to-Real Transfer
- Application: Policies robust to simulator physics updates and sim-to-real gaps by relying on history rather than explicit, incomplete context.
- Tools/Products/Workflows: Multi-sim training (engine ensembles), domain randomization; adapter-only deployment on real systems with safety cages.
- Assumptions/Dependencies: Sufficient training diversity; real-world validation harness; well-defined operational envelope.
- Sector: Developer Tooling
- Application: SDKs for history-adaptive controllers with plug-and-play context encoders and adapters; templates for asynchronous off-policy SPARC training.
- Tools/Products/Workflows: Libraries for history buffer management, adapter distillation, and continual learning; automated Pareto-front model selection.
- Assumptions/Dependencies: Standardized APIs across environments; developer familiarity with off-policy RL; resource availability for distributed training.
Glossary
- Ablation studies: Controlled experiments removing or altering components to assess their impact on performance. "We perform and analyze several ablation studies, examining key design choices such as history length and the selection of rollout policy during training."
- Adapter policy: A policy that infers context from interaction history to act without privileged context at test time. "SPARC trains an expert policy π{ex} and an adapter policy π{ad} simultaneously in a single phase."
- Asynchronous distributed computation: Parallel training setup where multiple workers collect data or compute updates without strict synchronization. "SPARC is straightforward to implement and naturally integrates with off-policy training as well as asynchronous distributed computation on cloud-based rollout workers."
- Built-in AI (BIAI) ratio: A normalized lap-time metric defined as RL lap time divided by the simulator’s built-in AI lap time. "Results show the mean built-in AI (BIAI) ratio across cars (ratio = the RL agent's lap time divided by the BIAI lap time, lower is better)."
- Context encoder: A network that maps privileged context variables to a latent representation used by the policy. "In the first phase, a context encoder is trained using privileged information about the environment."
- Contextual Markov decision process (CMDP): An MDP where dynamics, rewards, or observations are conditioned on a context variable. "We consider a contextual Markov decision process (CMDP) ... defined ... as a tuple"
- Contextual reinforcement learning: RL that leverages or adapts to varying environment contexts. "we focus on contextual reinforcement learning, where agents act within environments with varying contexts, such as self-driving cars or quadrupedal robots"
- Domain randomization: Training technique that randomizes environment parameters to improve robustness and sim-to-real transfer. "We employ domain randomization by default in our experiments."
- Expert policy: A policy trained with privileged context that serves as a teacher or reference for adaptation. "SPARC trains an expert policy π{ex} and an adapter policy π{ad} simultaneously in a single phase."
- History adapter: A module that encodes recent observation–action history into a latent context estimate. "In the adapter policy, a history adapter φθ processes a sequence of recent observation-action pairs h_t to produce a latent representation"
- History-based policies: Policies that condition actions on a sequence of recent observations and actions to infer hidden context. "History-based policies have emerged as a powerful approach in reinforcement learning for inferring hidden environmental context from past interactions."
- Hypernetworks: Networks that generate parameters of another network, enabling rapid task-specific adaptation. "emerging methods using hypernetworks generate task-specific policy parameters on the fly"
- In-distribution (IND): Contexts or environments that lie within the training distribution. "which are in-distribution (IND), short for within the training distribution."
- Isolation forest: Anomaly detection algorithm used to identify outliers by random partitioning. "we sort all ∼500 vehicles by their anomaly score through an isolation forest on the car's contextual features such as mass, length, width, weight distribution, power source type, drive train type, wheel radius, etc."
- Latent context: An unobserved representation capturing environment-specific factors inferred from data. "enabling the agent to infer latent context solely from past state-action trajectories."
- Meta-reinforcement learning: Methods that learn to adapt quickly to new tasks or contexts from prior experience. "Meta-reinforcement learning offers an alternative paradigm for learning adaptable policies"
- MuJoCo: A physics engine and benchmark suite for continuous control tasks in RL. "a set of MuJoCo environments featuring strongly varying environment dynamics through the use of wind perturbations"
- Off-policy training: Learning from data generated by a behavior policy different from the one being optimized. "naturally integrates with off-policy training"
- On-device continual learning: Continual policy improvement directly on the deployment device, without round-trips to the cloud. "SPARC is naturally compatible with on-device continual learning"
- On-policy setting: Learning where the data is collected by the same policy that is being updated. "brings the learning dynamics of π{ad} closer to an on-policy setting"
- Oracle: A baseline policy with access to ground-truth context at test time. "Oracle: A policy that has access to the ground-truth unencoded contextual features, even at test time."
- Out-of-distribution (OOD): Contexts or environments significantly different from those seen during training. "We tackle the critical task of generalizing to out-of-distribution (OOD) settings"
- Pareto-front: The set of non-dominated models balancing multiple objectives; improving one worsens another. "These training evaluations form a Pareto-front, from which we select the best model checkpoint for each run."
- Pareto-optimal: A solution for which no objective can be improved without degrading another. "SPARC achieves state-of-the-art generalization performance and consistently produces Pareto-optimal policies when evaluated across multiple desiderata."
- Partial observability: When the agent cannot fully observe the environment state, necessitating inference from history. "knowledge of some history may be useful to mitigate the partial observability in our contextual MDP"
- Privileged contextual information: Context variables available during training but not at deployment. "while only having access to privileged contextual information c ∈ C_IND during training."
- Procedurally generated environments: Environments algorithmically varied to expose agents to diverse conditions. "Domain randomization and procedurally generated environments introduce diversity during training, thereby encouraging robust policy behavior."
- Proprioceptive data: Internal sensory signals (e.g., joint angles/velocities) used for control and adaptation. "leveraging an extended history of proprioceptive data via a temporal convolutional network (TCN) enables robust control in diverse settings."
- QR-SAC: Quantile Regression Soft Actor-Critic; a distributional RL variant improving sample efficiency. "we employ the more sample-efficient QR-SAC, proven to work well in Gran Turismo"
- Rapid Motor Adaptation (RMA): A two-phase approach that learns context encoding with privileged info and then adapts from history. "Rapid Motor Adaptation (RMA) is a notable framework in this direction, introducing a two-phase learning procedure."
- Rollout workers: Parallel actors that collect interaction data from environments for training. "asynchronous distributed computation on cloud-based rollout workers."
- System identification: Estimating environment/robot dynamics parameters to improve control performance. "System identification methods—whether performed explicitly or through implicit online adaptation, as in SPARC and RMA—also contribute to improved performance under varying conditions."
- Temporal convolutional network (TCN): A convolutional architecture over time sequences for modeling history. "leveraging an extended history of proprioceptive data via a temporal convolutional network (TCN) enables robust control in diverse settings."
- Two-phase approach: Training paradigm with separate stages (e.g., pretrain encoder, then adapt), often adding complexity. "While promising, this two-phase approach is cumbersome to implement and train."
- World models: Learned models of environment dynamics used to inform or plan policy behavior. "or employ world models to capture environment dynamics"
- Zero-shot: Evaluating on new conditions without any additional training or adaptation. "these algorithms have only been trained on old physics settings, and are tested zero-shot on the new physics after a game update of Gran Turismo."
Collections
Sign up for free to add this paper to one or more collections.