Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Abstract: We introduce Lumine, the first open recipe for developing generalist agents capable of completing hours-long complex missions in real time within challenging 3D open-world environments. Lumine adopts a human-like interaction paradigm that unifies perception, reasoning, and action in an end-to-end manner, powered by a vision-LLM. It processes raw pixels at 5 Hz to produce precise 30 Hz keyboard-mouse actions and adaptively invokes reasoning only when necessary. Trained in Genshin Impact, Lumine successfully completes the entire five-hour Mondstadt main storyline on par with human-level efficiency and follows natural language instructions to perform a broad spectrum of tasks in both 3D open-world exploration and 2D GUI manipulation across collection, combat, puzzle-solving, and NPC interaction. In addition to its in-domain performance, Lumine demonstrates strong zero-shot cross-game generalization. Without any fine-tuning, it accomplishes 100-minute missions in Wuthering Waves and the full five-hour first chapter of Honkai: Star Rail. These promising results highlight Lumine's effectiveness across distinct worlds and interaction dynamics, marking a concrete step toward generalist agents in open-ended environments.














Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Lumine, an AI that can play complex 3D open-world games in real time, much like a human. Lumine sees the screen, thinks when needed, and controls the keyboard and mouse to complete long missions that take hours. It was trained mainly in the game Genshin Impact and can also handle new games without extra training.
What were the researchers trying to figure out?
The team wanted to know how to build a “generalist” game-playing agent that:
- Understands what’s happening on the screen.
- Makes plans for long missions.
- Controls the game precisely with keyboard and mouse.
- Works fast enough to keep up with real-time gameplay.
- Remembers what just happened and uses that to make better decisions.
- Transfers what it learned to new games and tasks.
In simple terms: Can we teach an AI to play big, open-world games like a human—seeing, thinking, and acting smoothly—without special insider access to the game?
How did they build and train the agent?
The world they used
The main testbed was Genshin Impact, a huge open-world game with:
- Free movement (running, climbing, gliding, swimming).
- Long missions (often hours).
- Many activities (exploration, puzzles, combat, talking to NPCs).
- Lots of on-screen text, menus, and special mechanics.
It’s challenging because there’s no secret API to read game states. Lumine has to work like a player: it just sees the screen and uses the mouse and keyboard.
Seeing, thinking, and acting (like a person playing)
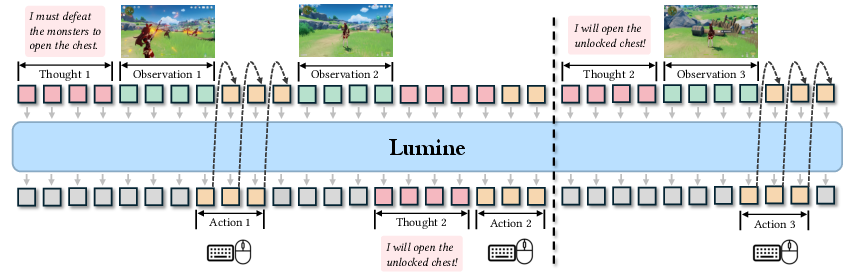
- Lumine is powered by a vision-LLM (VLM). Think of it as a neural network that can understand both images and text.
- It “sees” raw pixels from the screen 5 times per second (5 Hz).
- It “acts” by creating detailed keyboard and mouse actions 30 times per second (30 Hz). That’s fast enough for smooth camera movement, running, fighting, and clicking.
- It uses “hybrid thinking”: sometimes it pauses to write down a short inner thought (a plan or reflection), and sometimes it skips the thinking and acts directly to save time. This keeps it quick but still smart.
A helpful analogy:
- Perception = watching the game.
- Reasoning = inner monologue (thinking to yourself about what to do next).
- Action = pressing keys and moving the mouse, chunked into tiny, precise pieces, like breaking a move into frames in animation.
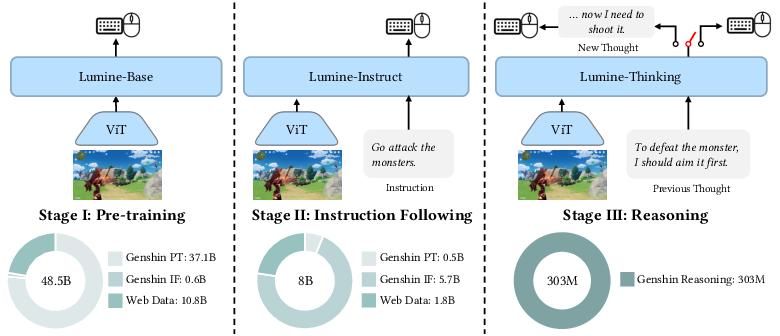
Training recipe (three stages)
They trained Lumine in a curriculum, like going from basics to advanced:
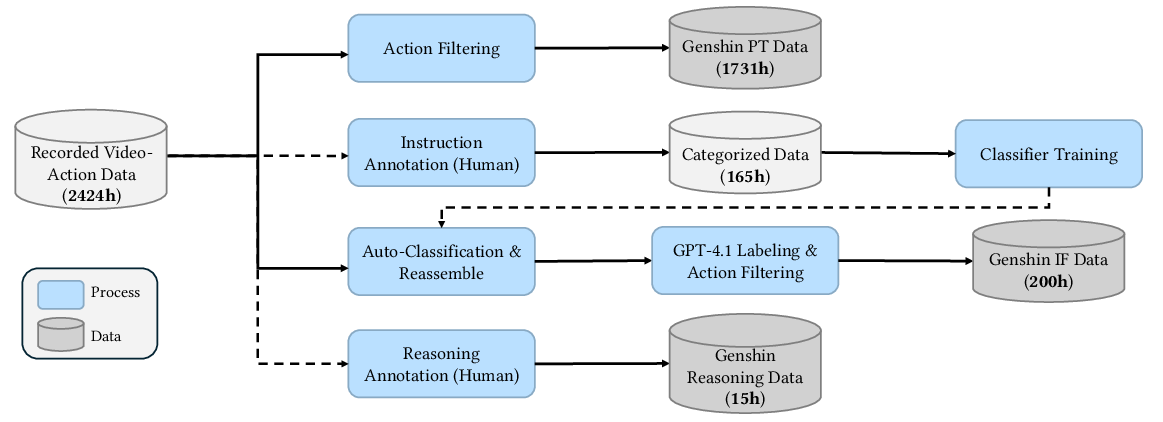
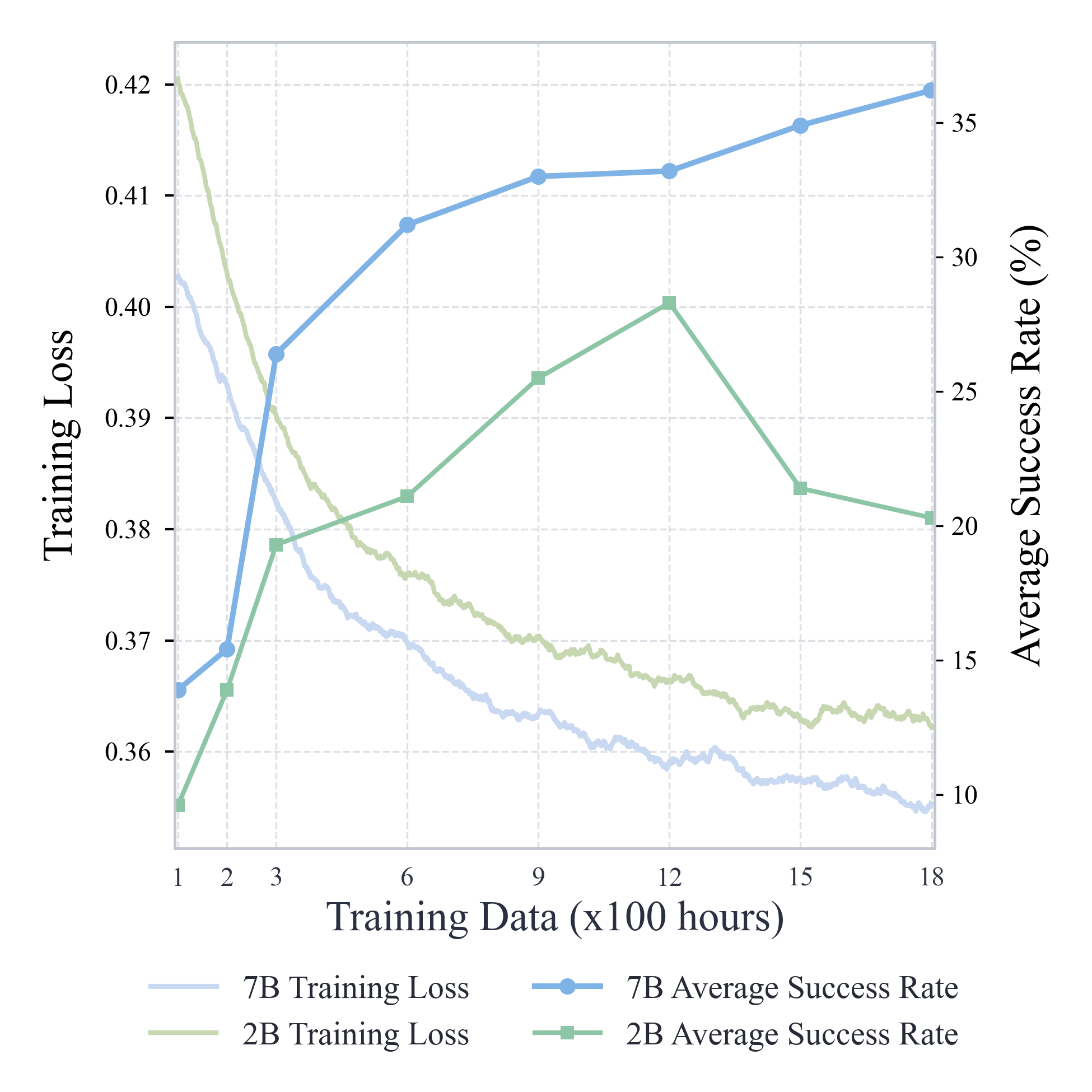
- Pre-training (1731 hours of gameplay): Learn the “feel” of the game—movement, interactions, camera control, basic combat, and GUI (menus). This was done by imitating human keyboard/mouse behavior paired with the video.
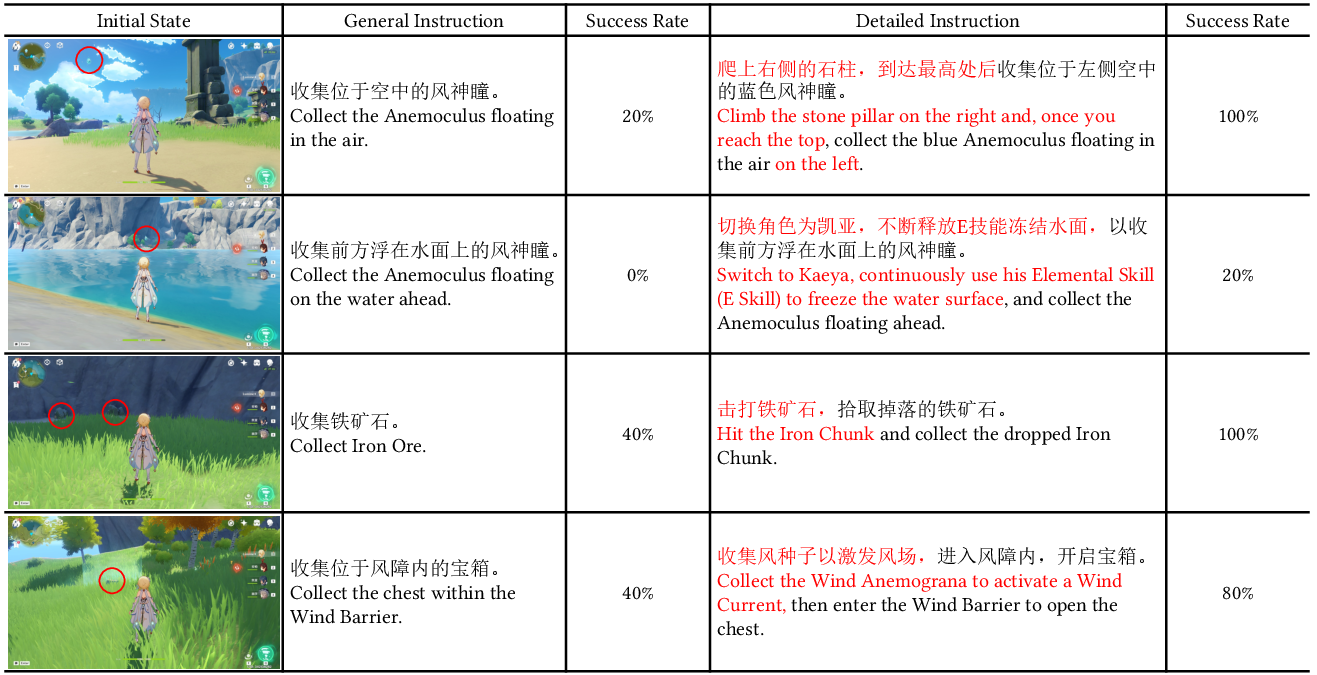
- Instruction following (200 hours): Teach Lumine to follow natural language instructions (e.g., “open the chest,” “go to the waypoint”). This helps it break habits and switch goals when needed.
- Reasoning (15 hours): Teach Lumine when and how to think out loud (its inner monologue), so it can plan and adjust strategies during long missions.
They started with 2424 hours of raw game recordings and carefully filtered and labeled them. For labeling activities, they used a small model to classify clip types, then had GPT-4.1 help write clear, context-aware instructions.
Making it fast enough for real-time play
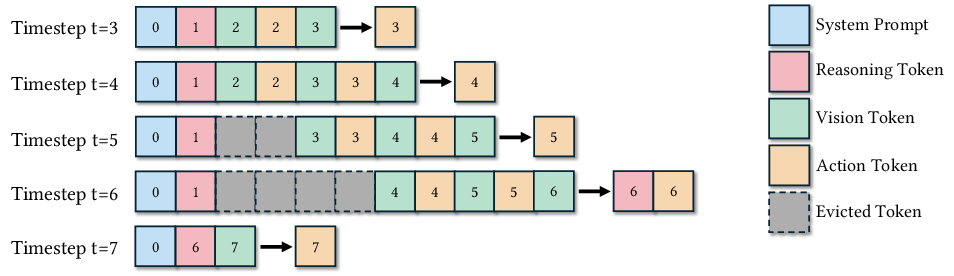
- Lumine keeps a short-term memory of about the last 20 steps and stores its past reasoning as long-term memory.
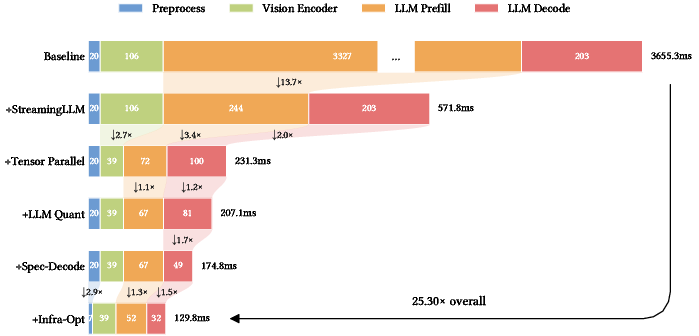
- The team optimized everything end-to-end so the model runs quickly, achieving a 25.3× reduction in latency. That’s what lets it act smoothly at 30 Hz.
What did they find?
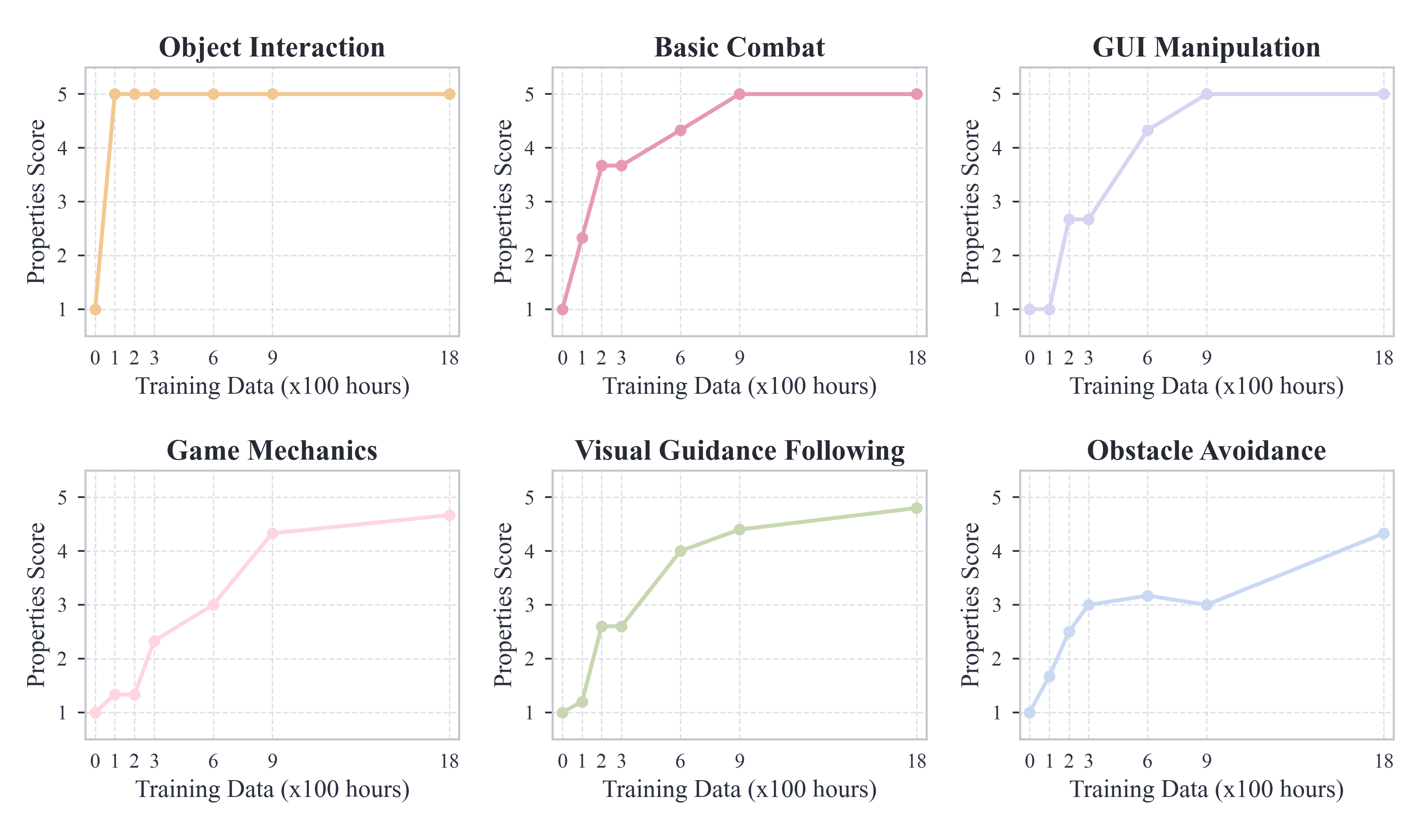
- Emergent skills from pre-training: Lumine naturally learned to interact with objects, fight basic battles, handle on-screen interfaces, and navigate 3D spaces—just by imitating large amounts of human play.
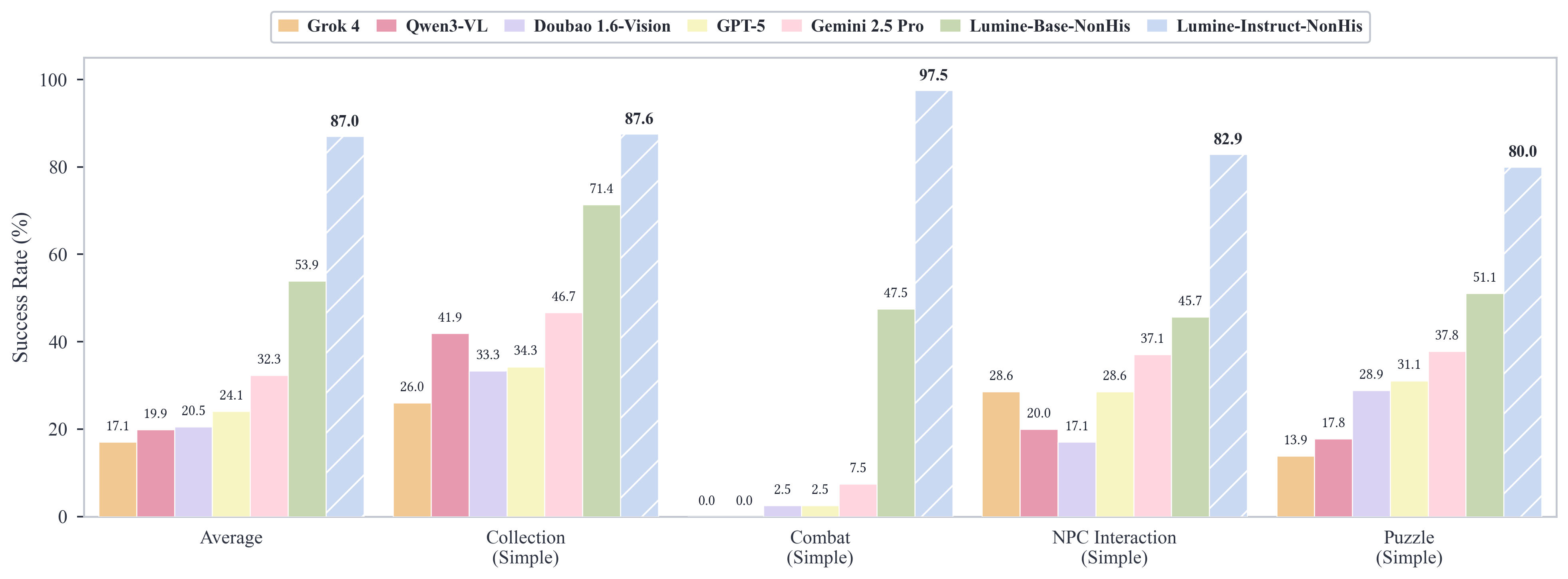
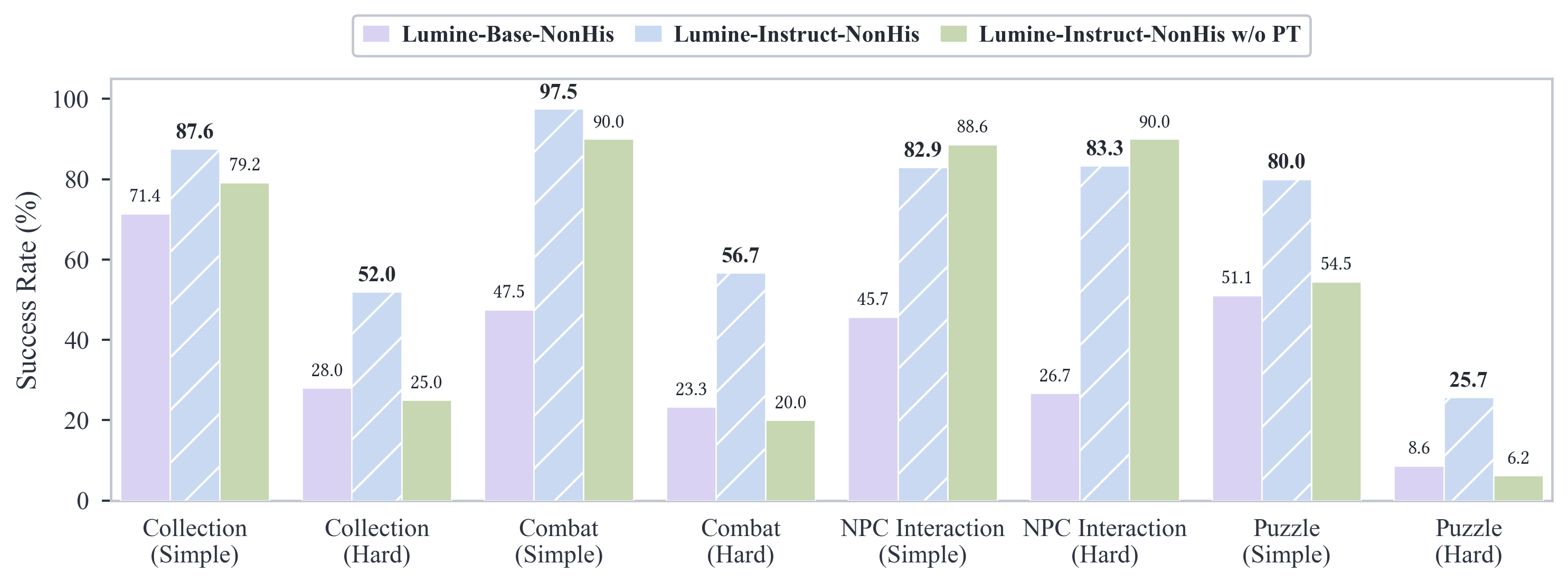
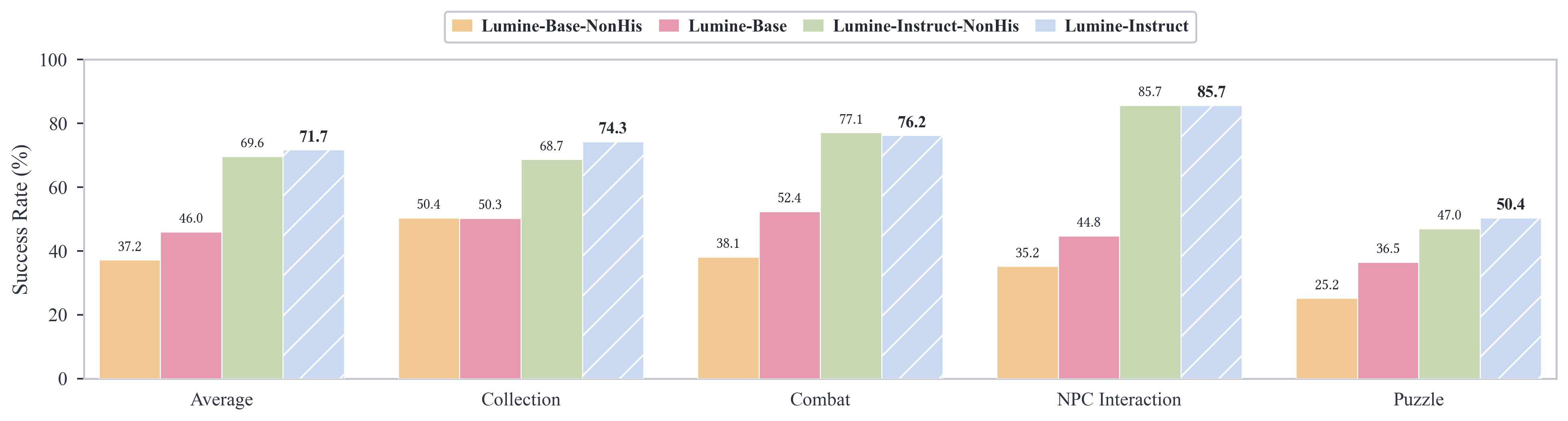
- Strong instruction following: When given short tasks (from 10 seconds to a few minutes), Lumine succeeded over 80% of the time, even on new objectives.
- Long missions at human-level efficiency:
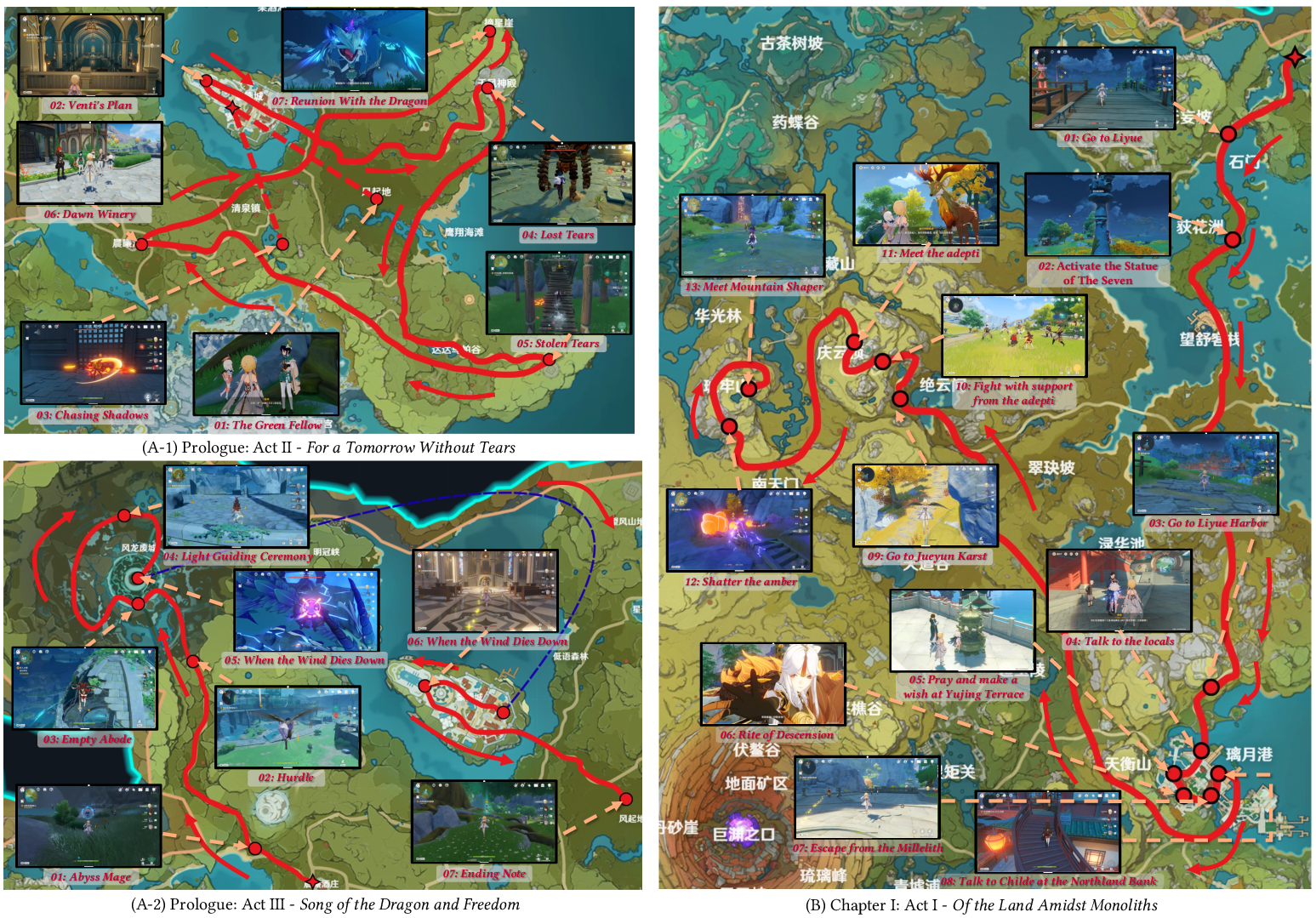
- It completed the full five-hour Mondstadt main storyline in Genshin Impact, performing on par with a human player.
- It kept up in Acts II and III (about four more hours) even though those parts weren’t in the reasoning dataset.
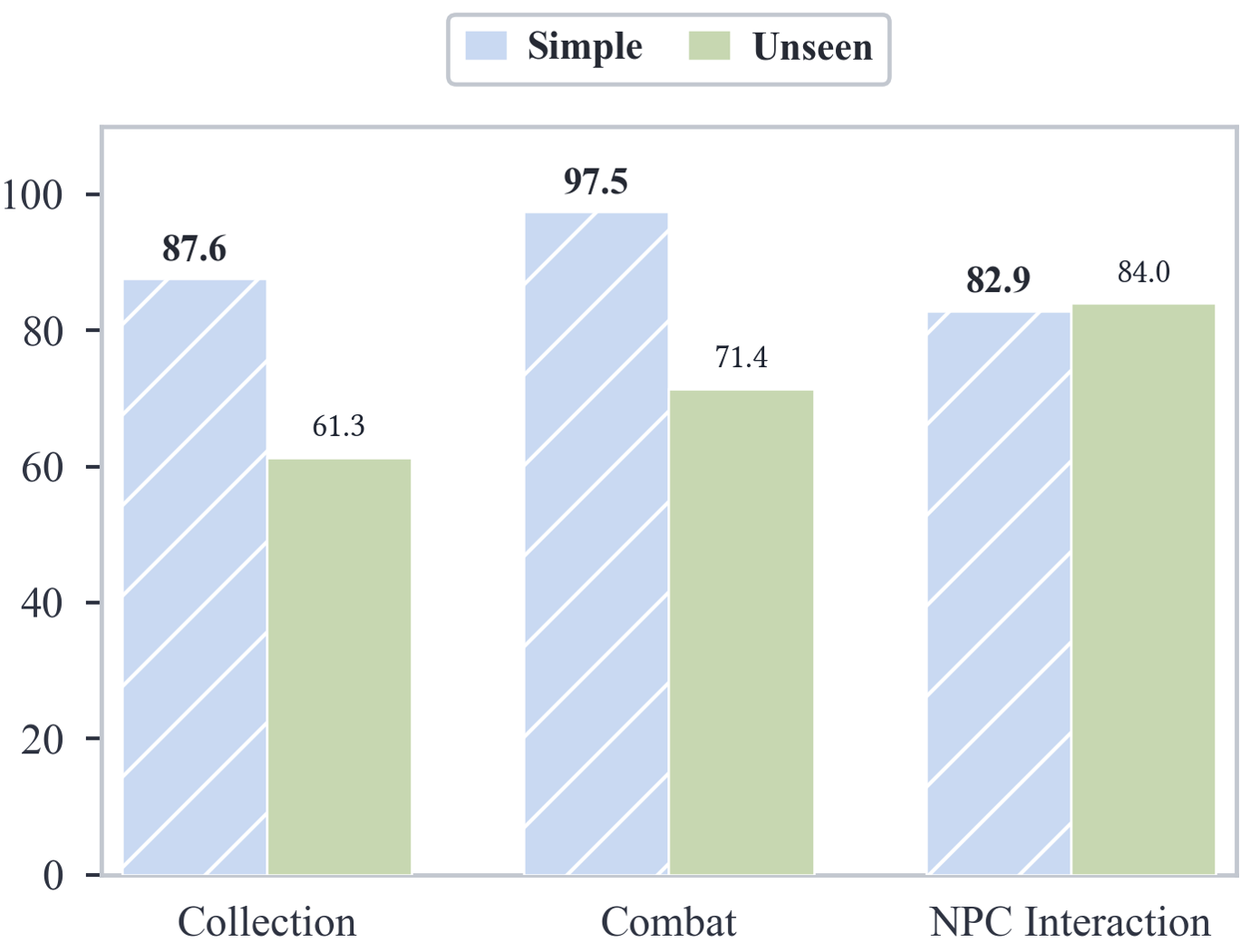
- It navigated to a new in-game nation (Liyue) and finished an initial one-hour mission there without being trained on that content.
- Zero-shot cross-game generalization (no fine-tuning):
- Wuthering Waves: completed 100-minute missions.
- Honkai: Star Rail: finished the five-hour first chapter.
In other words: Lumine didn’t just memorize one game. It transferred its skills to new games and different interaction styles.
Why is this important?
This work shows a practical path to general-purpose game agents:
- It unifies seeing, thinking, and acting in real time through one model.
- It uses a human-like interface (screen, keyboard, mouse), which makes it broadly applicable—not just to specific games with special access.
- It demonstrates that large-scale imitation of human play can lead to robust, general skills without expensive labels for every action.
- It balances speed and smarts by reasoning only when necessary, making it suitable for fast, dynamic environments.
Potential impact:
- Smarter assistants for games, testing, or accessibility (helping people navigate complex interfaces).
- Techniques that could transfer to robots and software agents (GUI control), since they also need to see, plan, and act quickly.
- A step toward agents that can handle open-ended, long-term tasks across different worlds—not just one narrowly defined challenge.
Overall, Lumine marks real progress toward building AI that can operate like a skilled, adaptable player in rich, complex environments.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps that future work could address.
- Reproducibility of environment interaction: The paper does not specify the full interaction stack (OS, windowing mode, capture/injection method, anti-cheat constraints, game versioning), making the setup difficult to replicate in commercial games.
- Data availability and licensing: It is unclear whether the 1731h pretraining, 200h instruction-following, and 15h reasoning datasets can be released (and under what license) given commercial game content; without access, the claimed “open recipe” is hard to verify.
- Evaluation metrics and baselines: Claims of “human-level efficiency” and long-horizon success lack standardized metrics (e.g., time-to-completion, deaths, retries, path optimality, action efficiency) and controlled comparisons to strong baselines on identical missions.
- Human baseline definition: The paper does not define human benchmarks (novice vs expert, prior knowledge, number of participants, variance), leaving “human-level” comparisons ambiguous.
- Ablation studies: No quantitative ablations are provided for key design choices (hybrid thinking vs always reasoning, action chunk size/number, observation rate, context window length, resolution), limiting insight into what actually drives performance.
- Scaling laws: There is no analysis of performance as a function of model size, pretraining hours, instruction labels, or reasoning hours; it is unclear whether additional data or larger models yield predictable gains or diminishing returns.
- Robustness to environment changes: The agent’s behavior under game patches, UI skin changes, different resolutions (e.g., 1080p/1440p), framerates, windowed/fullscreen modes, and network latency is not evaluated.
- Breadth of cross-domain generalization: All demonstrations are in similar action-RPGs; generalization to different genres (FPS, platformers, racing, strategy), gamepad-only titles, and non-game GUIs remains untested.
- Modality limitations: The agent ignores audio; it is unknown whether adding sound improves reaction to cues (timers, enemy telegraphs) and puzzle feedback.
- Controller support: The action representation is limited to keyboard/mouse; extension to gamepads, touch, and mobile input (and the necessary tokenization) is unexplored.
- Action discretization constraints: The chosen mouse displacement bounds and 200 ms smoothing, plus 33 ms key chunks, may cap peak responsiveness (parry windows, micro-aim). The precision/latency trade-offs are not quantified.
- Memory design and limits: “Context-as-memory” (up to 20 recent steps) and reasoning traces as long-term memory lack formal analysis; how memory scales to missions spanning hours, how summarization/retrieval is handled, and failure modes when context overflows remain open.
- Reasoning gating mechanism: The criterion for emitting <|thought_start|> is not clearly supervised or analyzed; frequency, latency trade-offs, and failure cases (e.g., unnecessary reasoning, reasoning hallucinations) are not quantified.
- Faithfulness of reasoning traces: The paper does not evaluate whether inner-monologue reasoning is causally linked to subsequent actions or suffers from post-hoc rationalization; metrics for reasoning fidelity are missing.
- Inference optimization breakdown: The reported 25.3× latency reduction is not decomposed (hardware specs, batching, caching, quantization, speculative decoding, I/O pipelines), limiting reproducibility and generalization to other setups.
- OCR and text understanding: At 720p, small fonts and multilingual text may be hard to read; the paper lacks measurements of in-game text recognition accuracy and sensitivity to language/locale changes.
- Dataset biases: Contractors used system-provided characters and targeted specific progression; coverage of high-level combat mechanics, team synergies, rare puzzles, and late-game content is unclear, risking overfitting to early-game distributions.
- Labeling quality and noise: Rule-based filtering and auto-labeling via a 2B classifier (plus GPT-4.1 captions) may introduce label noise; classifier accuracy, error rates, and the impact of mislabeled sequences are not reported.
- Reward-free training limitations: The recipe relies purely on imitation; whether offline RL or RL fine-tuning improves long-horizon efficiency, recovery behaviors, or robustness is left unexplored.
- Recovery and reset strategies: The agent’s behavior after deaths, quest-state inconsistencies, soft-locks, or getting stuck is not described; systematic evaluation of recovery competence is missing.
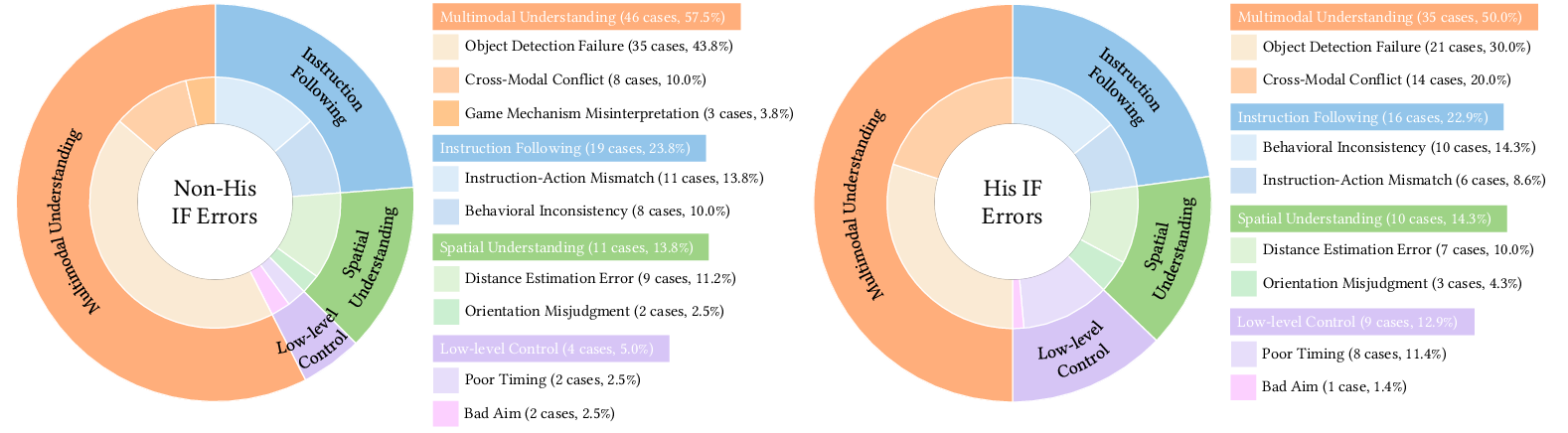
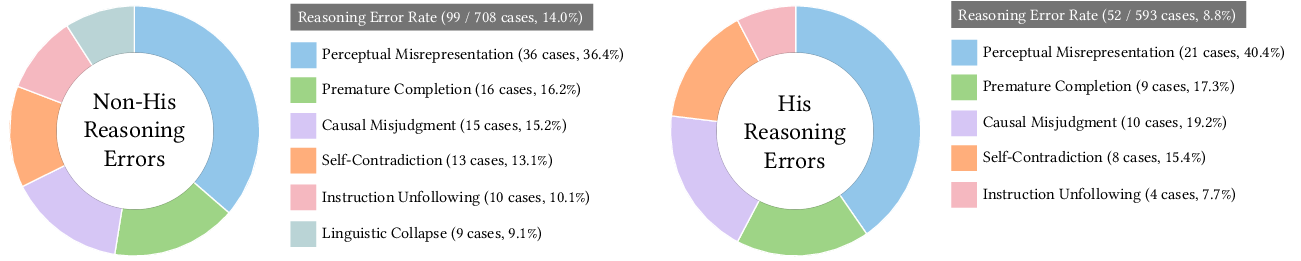
- Failure mode taxonomy: No detailed error analysis (e.g., navigation loops, camera drift, misclicks, UI misinterpretation, combat strategy errors) with frequencies and root causes is provided to guide targeted improvements.
- Adversarial and safety testing: The agent is potentially vulnerable to on-screen prompt injection (misleading UI text) and visual adversarial patterns; no robustness or red-team evaluations are reported.
- Ethical and ToS compliance: Operating automated agents in online games raises ToS, anti-cheat, and economic impact concerns; the paper does not discuss detection, mitigation, or compliance strategies.
- Generalization rationale: It is unclear which components (action language, perception, memory) underpin cross-game transfer; a formal factorization and sensitivity analysis of game-agnostic vs game-specific elements is missing.
- Training objective details: Loss weighting between reasoning and action tokens, curriculum scheduling, and sequence formatting choices (e.g., interleaving thought/action/history) are insufficiently specified for reproducibility.
- Benchmark standardization: There is no public, standardized long-horizon benchmark (mission suites with seeds, telemetry, scoring scripts); without this, broader comparison and progress tracking are difficult.
- Compute and energy footprint: Training/inference costs (GPU hours, memory, energy) are not reported; practical deployment and scaling implications remain unclear.
Practical Applications
Overview
Below are actionable, real-world applications derived from the Lumine paper’s findings, methods, and innovations. Each item is linked to relevant sectors, proposed tools/products/workflows, and assumptions or dependencies that impact feasibility. Applications are grouped into Immediate and Long-Term based on deployability.
Immediate Applications
The following uses can be deployed now with modest engineering effort, given Lumine’s demonstrated real-time control, hybrid reasoning, and cross-game generalization via a human-like pixel/keyboard/mouse interface.
- Autonomous playtesting and QA in commercial games
- Sector: gaming, software QA
- What: Use Lumine to execute hours-long missions and diverse activities (combat, puzzle-solving, GUI flows) to surface regressions and usability issues across patches and builds.
- Tools/Products/Workflows: “Autonomous Playtest Runner” that:
- Ingests test scenarios as natural-language goals
- Captures telemetry and reasoning logs for reproducibility
- Flags anomalies (soft locks, UI misalignment, quest progression failures)
- Assumptions/Dependencies: Compliance with game ToS; robust screen capture/input injection; resilience to frequent UI and content changes; controlled test environments to avoid bans.
- Regression and content verification across updates
- Sector: gaming studios, live ops
- What: Automated quest and event validation using zero-shot generalization (e.g., new regions, mission chapters) to ensure continuity after content updates.
- Tools/Products/Workflows: “Quest Completion Bot” integrated into CI/CD; scheduled runs on nightly builds with diff reports.
- Assumptions/Dependencies: Access to internal builds; stabilizing prompts/goals for consistency; version-aware instruction grounding.
- Customer support assistance via reproducible in-game investigations
- Sector: gaming support operations
- What: Reproduce player-reported issues by replaying multi-hour mission contexts and logging interactions.
- Tools/Products/Workflows: “Support Investigator Agent” workflow—attach ticket metadata → natural-language reconstruction → automated run → export trace with thought/action logs.
- Assumptions/Dependencies: Controlled accounts and sandbox servers; audit trails; privacy and compliance; human review.
- Accessibility assistants for players with motor limitations
- Sector: healthcare (assistive tech), gaming accessibility
- What: Voice- or text-driven agent that executes precise keyboard/mouse actions to complete missions on behalf of users.
- Tools/Products/Workflows: “Voice-to-Play Assistant” combining ASR + Lumine to follow high-level instructions; safe handoff to user at critical choices.
- Assumptions/Dependencies: Developer approval; real-time latency budgets; transparent labeling; configurable difficulty/scope.
- GUI automation for desktop/RPA without APIs
- Sector: enterprise software, RPA, IT ops
- What: Automate complex multi-step GUI workflows in legacy or proprietary applications using pixel-level perception and precise key/mouse control.
- Tools/Products/Workflows: “Operator-lite” agent that:
- Learns tasks from demonstrations (video+action)
- Executes long sequences reliably with hybrid reasoning only when needed
- Assumptions/Dependencies: Domain-specific fine-tuning; UI stability or robust vision; strict security policies, access control, and audit logging; privacy-safe screen capture.
- Realistic user simulation for desktop application QA
- Sector: software QA
- What: Generate realistic input traces (e.g., drag-and-drop, multi-key combos, timing-sensitive actions) for stress and usability testing.
- Tools/Products/Workflows: “Realistic Input Simulator” with scenario scripting; action chunking at 30 Hz; replay harness for reproducibility.
- Assumptions/Dependencies: Cross-platform input hooks; hardware variability; deterministic replays.
- Synthetic dataset generation for CV/GUI agent training
- Sector: AI/ML tooling, academia
- What: Curate large-scale pixel-action-reasoning traces to train and evaluate VLA/GUI models on long-horizon tasks.
- Tools/Products/Workflows: “Dataset Generator” exporting synchronized video+action+thought logs; labeling via instruction-following prompts; curriculum slices by task type.
- Assumptions/Dependencies: Dataset licensing; diversity beyond a single game/app; annotation quality control.
- Research replication toolkit for embodied agents
- Sector: academia
- What: Adopt the open recipe (data curation, three-stage curriculum, action modeling, hybrid thinking) to build agents in new environments.
- Tools/Products/Workflows: “Lumine Toolkit” starter packs—key/mouse token mappings, thought/action format, latency optimization modules, evaluation missions.
- Assumptions/Dependencies: Compute budget; access to diverse demonstration data; reproducible environment setups.
- Strategy exploration and training analytics in games
- Sector: e-sports analytics, game design
- What: Use thought logs to analyze decision paths and efficiency versus human baselines; identify optimal routes and tactics.
- Tools/Products/Workflows: “Strategy Explorer” dashboard visualizing plans, deviations, and timing; side-by-side human vs. agent runs.
- Assumptions/Dependencies: Representative benchmarks; alignment with player skill levels; interpretability of reasoning traces.
Long-Term Applications
The following uses require further research, scaling, or domain adaptation (e.g., safety, hardware integration, policy governance) before broad deployment.
- Generalist desktop agent for complex professional software
- Sector: software, enterprise productivity
- What: Autonomously operate high-stakes tools (CAD, video editing, medical imaging) through pixel+keyboard/mouse, completing long workflows via hybrid reasoning.
- Tools/Products/Workflows: “Pixel-to-Action Operator” with domain knowledge modules; structured macros; human-in-the-loop validation for critical steps.
- Assumptions/Dependencies: Strong domain grounding; reliable task decomposition; error recovery; compliance and change management; rigorous auditing.
- Robotics VLAs with real-time hybrid reasoning
- Sector: robotics, manufacturing, logistics, home automation
- What: Transfer Lumine’s action chunking, hybrid thinking, and memory context to embodied robots for long-horizon tasks.
- Tools/Products/Workflows: “Household Generalist VLA” integrating perception-action pipelines; safety supervisors; sim-to-real curricula using synthetic traces.
- Assumptions/Dependencies: Contact-rich control, safety and reliability certification; multimodal sensor fusion; extensive real-world data and hardware constraints.
- Autonomous digital workers (RPA 2.0) across heterogeneous enterprise stacks
- Sector: enterprise IT, operations
- What: Cross-app task automation (ERP, CRM, legacy desktop) without APIs, scaling from minutes to hours with robust failure handling.
- Tools/Products/Workflows: “Generalist Desktop Agent” with governance (policy guardrails, role-based access, observability); playbook orchestration; rollback mechanisms.
- Assumptions/Dependencies: High reliability targets; organizational buy-in; robust privacy and security architecture; standardized logging of thought/action.
- Dynamic NPCs and systemic AI in open-world games
- Sector: gaming
- What: Replace script-based NPCs with generalist agents capable of emergent exploration, puzzle-solving, and adaptive dialogue-driven behavior.
- Tools/Products/Workflows: “Emergent NPC Agent” sandboxed per zone; resource budgets to avoid latency spikes; authoring tools for designer constraints.
- Assumptions/Dependencies: Cost-effective inference; anti-cheat and fairness considerations; content moderation; designer control over agency.
- Simulation-based training for emergency response and industrial operations
- Sector: education, public safety, industrial training
- What: Use open-world-like sims with agents to create adaptive scenarios, evaluate procedures, and generate synthetic edge cases.
- Tools/Products/Workflows: “Scenario Trainer” with controllable difficulty; multi-agent coordination; post-run analytics leveraging thought logs.
- Assumptions/Dependencies: Domain-specific sim fidelity; transferability to real-world protocols; accreditation requirements.
- GUI red-teaming and security testing
- Sector: cybersecurity
- What: Automated agents probing complex GUIs for misuse paths, privilege escalation, and unsafe defaults by replicating realistic human behaviors.
- Tools/Products/Workflows: “Pen-Test GUI Agent” in sandboxed VMs; coverage metrics; risk scoring; replayable traces with reasoning explanations.
- Assumptions/Dependencies: Strict isolation; ethics and legal compliance; false positive mitigation; collaboration with app vendors.
- Finance/trading GUI automation under governance
- Sector: finance
- What: Agent-driven execution and monitoring on broker platforms with natural-language strategy inputs and long-horizon workflows.
- Tools/Products/Workflows: “Trade Execution Agent” with risk controls, latency monitors, kill-switches, and audit trails of thought/actions.
- Assumptions/Dependencies: Regulatory compliance (KYC, best execution); extreme reliability; low-latency networking; transparent accountability.
- Educational agents in open worlds for problem-solving curricula
- Sector: education
- What: Use Lumine-like agents to scaffold problem-solving and planning skills through quest-based learning; expose reasoning for teachable moments.
- Tools/Products/Workflows: “Quest-based Tutor” aligning tasks with learning objectives; adaptive hints; reflection prompts from thought logs.
- Assumptions/Dependencies: Age-appropriate content; pedagogy alignment; content licensing; moderation and safety filters.
- Standardization and policy frameworks for embodied AI interfaces
- Sector: policy, standards bodies
- What: Develop interface and logging standards (e.g., keyboard/mouse token schemas, hybrid-thinking markers) to support auditability and safety evaluations.
- Tools/Products/Workflows: “Hybrid Thinking Logging Standard” proposals for reproducible traces; benchmarks for real-time inference and long-horizon competence.
- Assumptions/Dependencies: Multi-stakeholder adoption; alignment with privacy and AI governance norms; compatibility across OS/platforms.
Notes on Assumptions and Dependencies
Across applications, feasibility depends on:
- Legal/ethical compliance: Respect for ToS, bot policies, data privacy, and auditing for high-stakes domains.
- Robustness to UI changes: Vision models must adapt to evolving layouts, themes, and resolutions; domain-specific fine-tuning may be required.
- Reliability and latency: Meeting real-time constraints (e.g., 5 Hz observation, 30 Hz action) under varied hardware/OS conditions.
- Safety and oversight: Human-in-the-loop gates for critical operations; interpretable logging of “thought” and “action” for post-hoc analysis.
- Data availability: High-quality demonstration data and task curricula; synthetic augmentation for rare events; cross-domain generalization limits.
- Infrastructure: Secure screen capture and input injection; sandboxed environments; observability and replay systems for reproducibility.
Glossary
- AAA games: High-budget, large-scale commercial video games with high production values that provide rich, realistic challenges for AI agents. "Commercial games, especially AAA games, however, often feature more realistic physics engines, richer content, and more diverse gameplay, making them especially valuable yet challenging testbeds for general-purpose agents."
- action chunking: A technique that predicts short sequences (chunks) of actions per step to achieve high-frequency, efficient control. "Lumine adopts a hybrid thinking strategy, allowing it to adaptively enter a thinking mode to produce inner-monologue reasoning before generating executable actions when necessary, thereby avoiding redundant computation and latency without compromising decision quality... and autoregressively generates textual keyboard and mouse actions at 30 Hz using action chunking \citep{zhao2023learning}."
- action heads: Separate output layers specialized for action prediction, distinct from language outputs. "While prior works often introduce additional action heads~\citep{black2024pi0, intelligence2025pi} or redefine the vocabulary~\cite{zitkovich2023rt, li2025jarvis} to represent actions, they fail to exploit the inherent semantics of keyboard and mouse operations, which are well captured by LLMs."
- action primitives: Basic low-level operations (e.g., key presses, mouse movements) that compose more complex behaviors. "i) 1731 hours of human gameplay for pre-training to master action primitives;"
- action tokenization: Discretizing actions into tokens so they can be generated with language-model-style decoding. "In robotics, VLAs employ techniques such as action chunking~\citep{zhao2023learning}, flow matching~\citep{black2024pi0}, and action tokenization~\citep{pertsch2025fast} to accelerate policy learning and action generation."
- asynchronous interactions: Interaction where environment changes continue while the agent is computing, requiring timely, non-blocking responses. "The ability to operate under strict latency constraints, balancing computational deliberation with timely responses and managing asynchronous interactions to avoid missing critical opportunities~\citep{kober2013reinforcement, black2025real}."
- autoregressive: A modeling approach that generates outputs token-by-token conditioned on previous tokens; used here to emit action sequences. "Lumine provides a practical solution by combining these techniques with traditional LLL inference optimization strategies and efficient action modeling, enabling autoregressive models to achieve real-time inference in gaming environments."
- brittle intelligence: High performance in narrow settings that fails to generalize or adapt to new contexts. "This specialization yields mastery but brittle intelligence with limited abstraction, weak transfer, and poor adaptability to the ambiguity and diversity inherent in open-world scenarios."
- compositional dynamics: Environment dynamics composed of reusable parts that agents must combine to act and generalize. "providing compositional dynamics that challenge agents to interact, learn, and generalize, while remaining standardized, scalable, and reproducible~\citep{bellemare2013arcade,brockman2016openai,beattie2016deepmind,tan2024cradle, raad2024scaling}."
- cross-game generalization: Transferring skills across different games without retraining. "In addition to its in-domain performance, Lumine demonstrates strong zero-shot cross-game generalization."
- end-to-end optimization: Jointly optimizing the full system from inputs to outputs rather than modular components separately. "Finally, an end-to-end optimization yields a 25.3Ã overall latency reduction, enabling real-time inference and smooth task execution."
- flow matching: A generative modeling method that aligns probability flows for efficient training or sampling; adapted here for action generation. "In robotics, VLAs employ techniques such as action chunking~\citep{zhao2023learning}, flow matching~\citep{black2024pi0}, and action tokenization~\citep{pertsch2025fast} to accelerate policy learning and action generation."
- foundation model: A large, broadly pre-trained model that serves as a base for many downstream tasks and domains. "The recent success of large language foundation models~\cite{achiam2023gpt,team2023gemini,hurst2024gpt,guo2025deepseek} reinforces this view through their superior common-sense understanding and reasoning."
- hierarchical architecture: A multi-level control design where high-level reasoning guides a lower-level controller. "Some robotics VLAs adopt a hierarchical architecture, where one model performs high-level reasoning at a low frequency, and another model generates low-level actions based on that reasoning~\citep{shi2025hi, bjorck2025gr00t, figure2025helix}."
- hybrid thinking: A mechanism where the agent adaptively decides when to think (reason) explicitly and when to act directly. "Lumine adopts a hybrid thinking strategy, allowing it to adaptively enter a thinking mode to produce inner-monologue reasoning before generating executable actions when necessary"
- inner-monologue reasoning: Private textual reasoning produced by the model to plan or reflect before acting. "adaptively enter a thinking mode to produce inner-monologue reasoning before generating executable actions when necessary"
- instruction following: Aligning actions to natural-language goals so the agent can execute user-specified tasks. "Building upon these foundational abilities, instruction-following fine-tuning enables Lumine to demonstrate robust short-horizon control"
- latent structure: Hidden representations that organize information and guide subsequent predictions or actions. "This factorization reflects the model's perceive-reason-action paradigm, where intermediate reasoning provides an explicit latent structure that guides the subsequent action generation."
- long-horizon: Spanning many steps or long durations, requiring sustained planning and memory. "The ability to generate self-motivated, long-horizon plans that adapt as environmental dynamics evolve"
- non-stationarity: Changing data or dynamics over time, which complicates stable joint optimization. "Although this structure provides temporal abstraction, it is challenging to optimize both stages jointly and stably due to non-stationarity~\cite{hutsebaut2022hierarchical}."
- open-world: Broad, unscripted environments with diverse objectives and free-form exploration. "the first open recipe for developing generalist agents capable of completing hours-long complex missions in real time within challenging 3D open-world environments."
- partial observability: The agent cannot observe the full state, making memory and history crucial. "it inherently suffers from partial observability, limiting temporal coherence and hindering performance on long-horizon tasks."
- perceive-reason-action paradigm: A loop where the agent perceives inputs, optionally reasons, then outputs actions. "This factorization reflects the model's perceive-reason-action paradigm, where intermediate reasoning provides an explicit latent structure that guides the subsequent action generation."
- prompt-based agents: Systems that leverage prompting of LLMs/VLMs to perform tasks without extensive additional training. "Even without additional training, prompt-based agents built upon LLMs and VLMs have shown that such models can serve as powerful foundation models for general-purpose agents"
- ReAct paradigm: A method where the agent alternates explicit reasoning with action at every step. "other approaches~\citep{xu2024aguvis,qin2025ui,hershey2025claude, zhang2025gemini,intelligence2025pi} follow the ReAct paradigm~\citep{yao2023react}, where the agent performs explicit reasoning and outputs an action at every step."
- real-time inference: Producing outputs quickly enough to meet live interaction deadlines. "Real-time inference poses a great challenge for VLM-based agents, especially in fast-paced video games requiring high-frequency interactions."
- System 1 (style): Fast, heuristic, reactive decision-making, by analogy to Kahneman’s dual-process theory. "optimize policy networks from scratch via supervised learning or reinforcement learning in a system 1 style~\citep{kahneman2011thinking}."
- temporal abstraction: Operating at multiple time scales, where high-level plans guide lower-level actions over extended intervals. "Although this structure provides temporal abstraction, it is challenging to optimize both stages jointly and stably due to non-stationarity~\cite{hutsebaut2022hierarchical}."
- temporal coherence: Maintaining consistent behavior over time despite partial observability or delays. "This 'context as memory' design allows us to study how an extended context window influences temporal coherence and action consistency without introducing specialized memory modules."
- VLA (Vision-Language-Action model): A model that integrates vision and language inputs to produce actions. "Continue training with large-scale robotic data, VLMs can be converted into VLA models~\citep{zitkovich2023rt, kim2024openvla, black2024pi0, shukor2025smolvla, intelligence2025pi}, which are capable of following instructions and performing a wide range of robotic tasks"
- VLM (Vision-LLM): A model that processes and relates visual and textual information. "The recent rise of LLMs and visionâLLMs (VLMs)~\citep{achiam2023gpt, anthropic2025claude3.7, google2025gemini2.5} has demonstrated strong capabilities in language understanding and commonsense reasoning."
- visuomotor competence: The ability to map visual perception to motor control effectively. "These emergent behaviors indicate that structured visuomotor competence can naturally arise from large-scale imitation of human gameplay"
- zero-shot generalization: Performing well on unseen tasks or environments without additional training. "Beyond the training domain, Lumine exhibits strong zero-shot generalization."
Collections
Sign up for free to add this paper to one or more collections.

