LLM Output Drift: Cross-Provider Validation & Mitigation for Financial Workflows
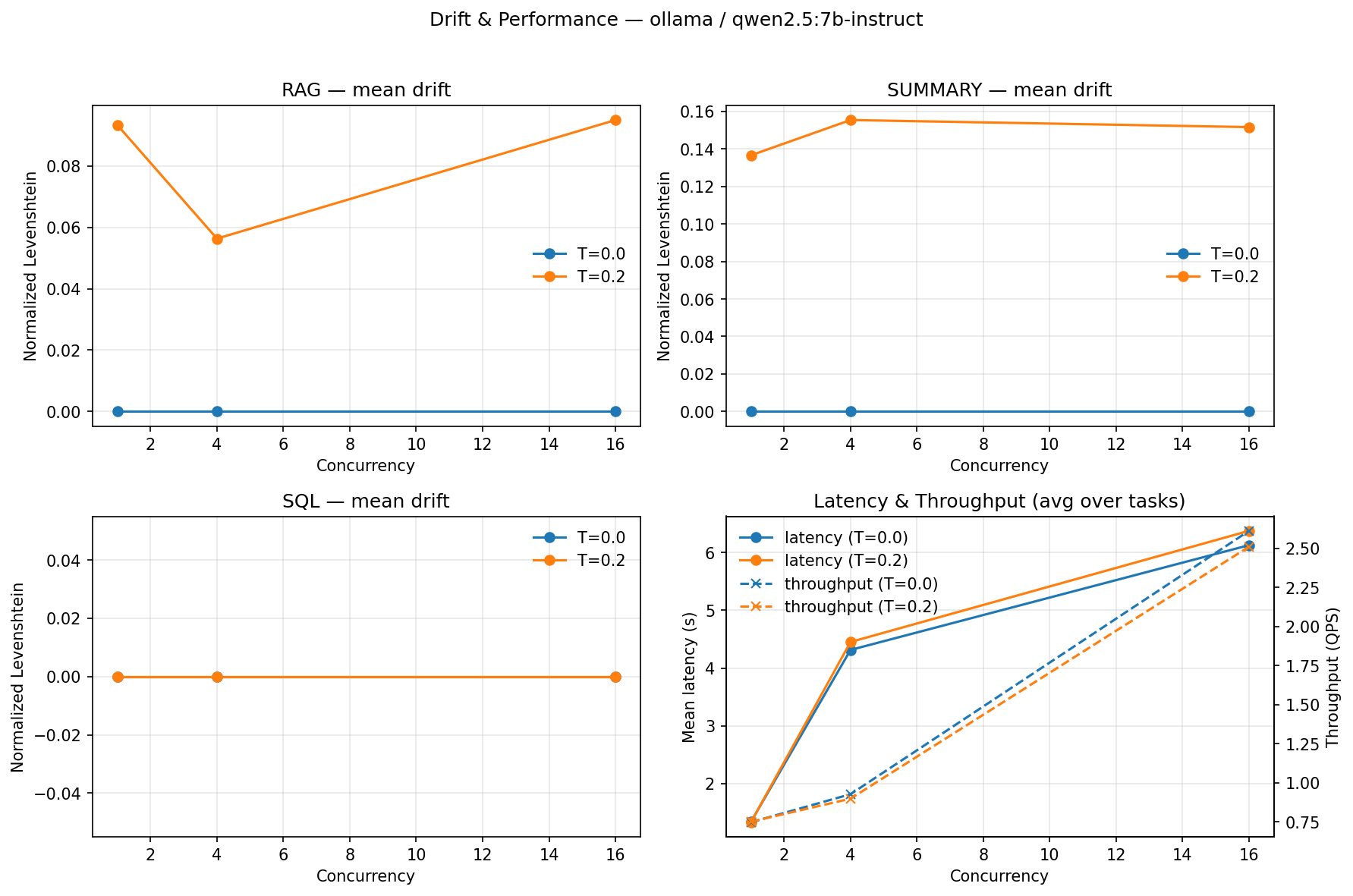
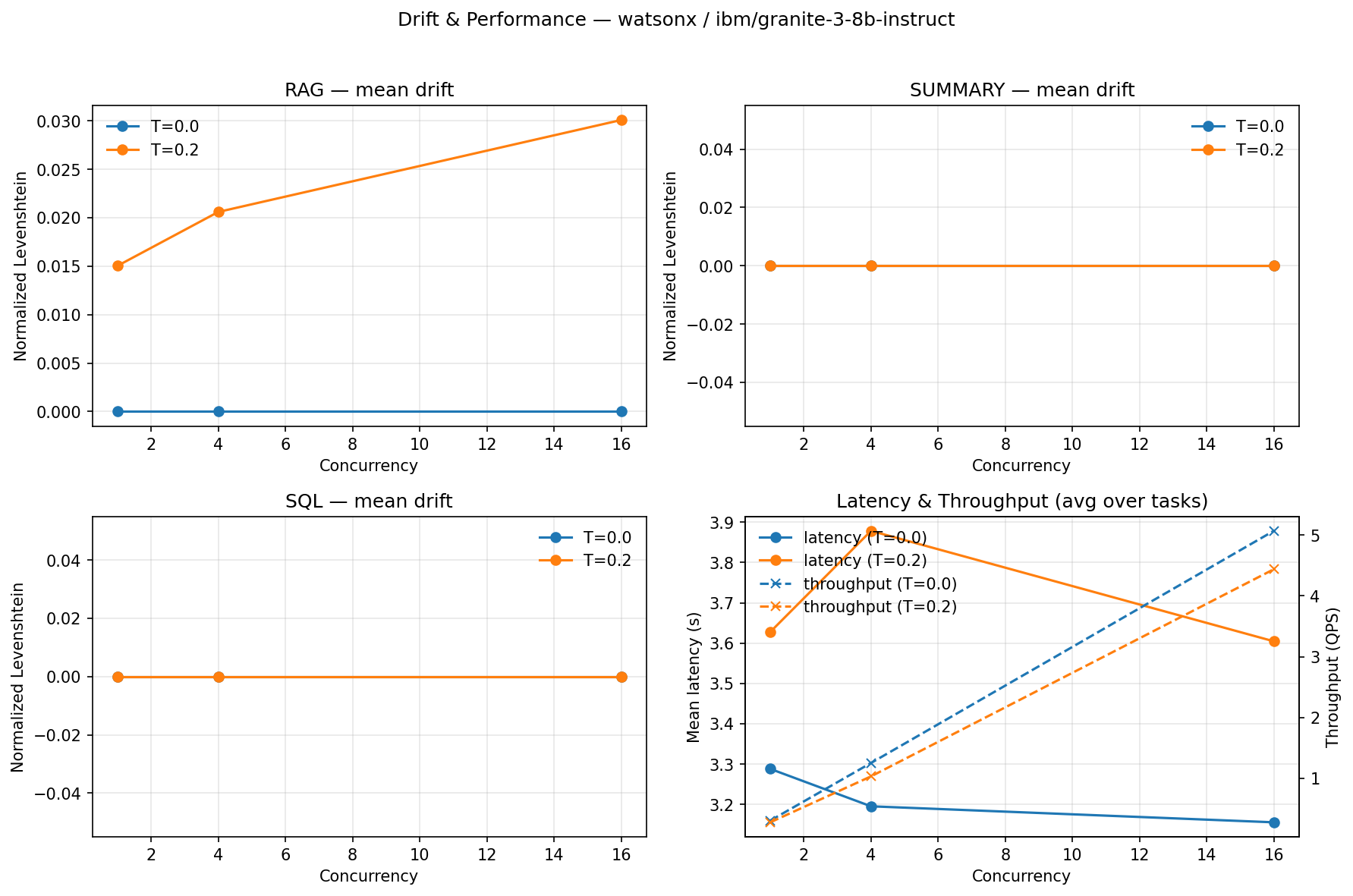
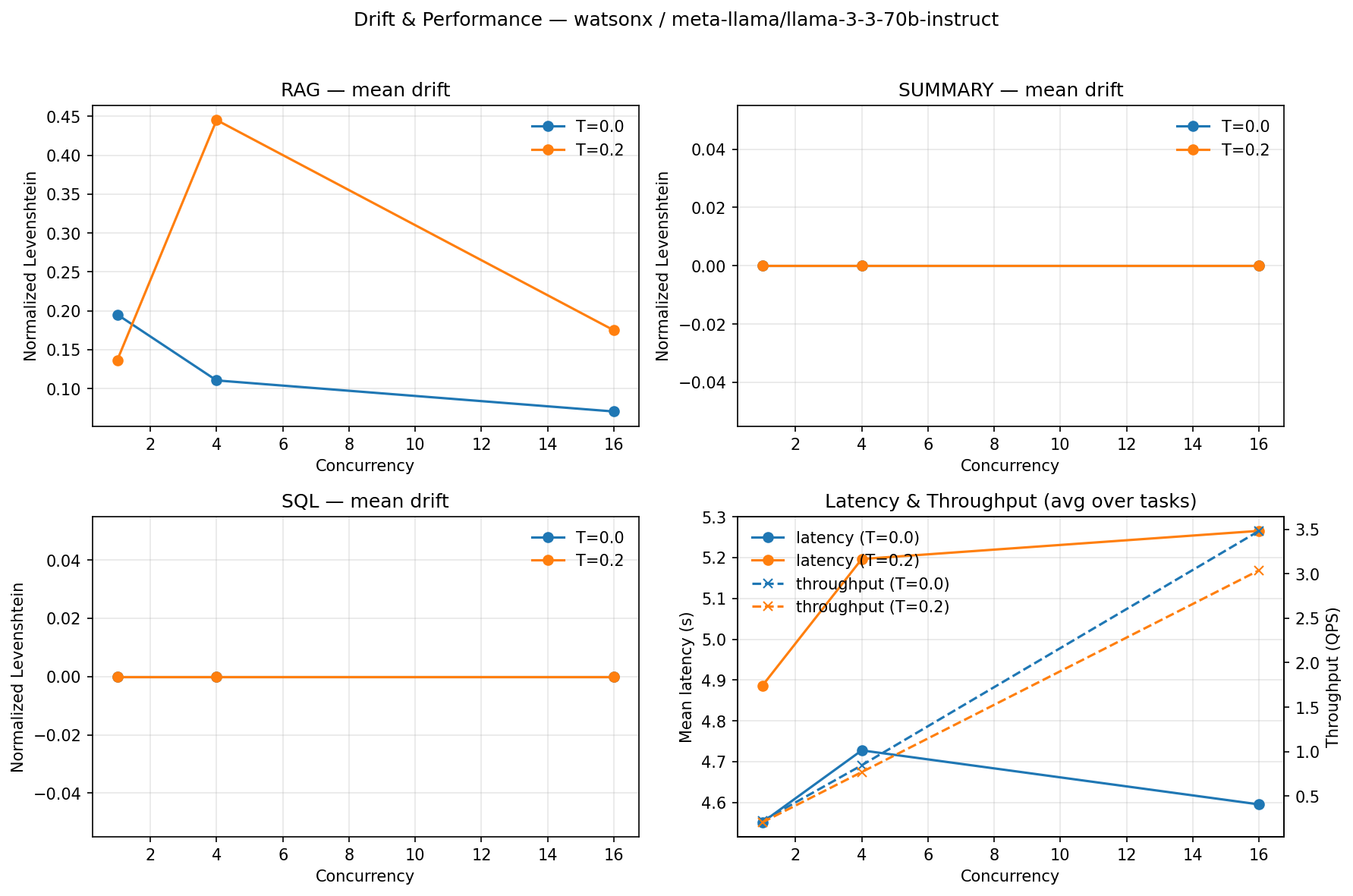
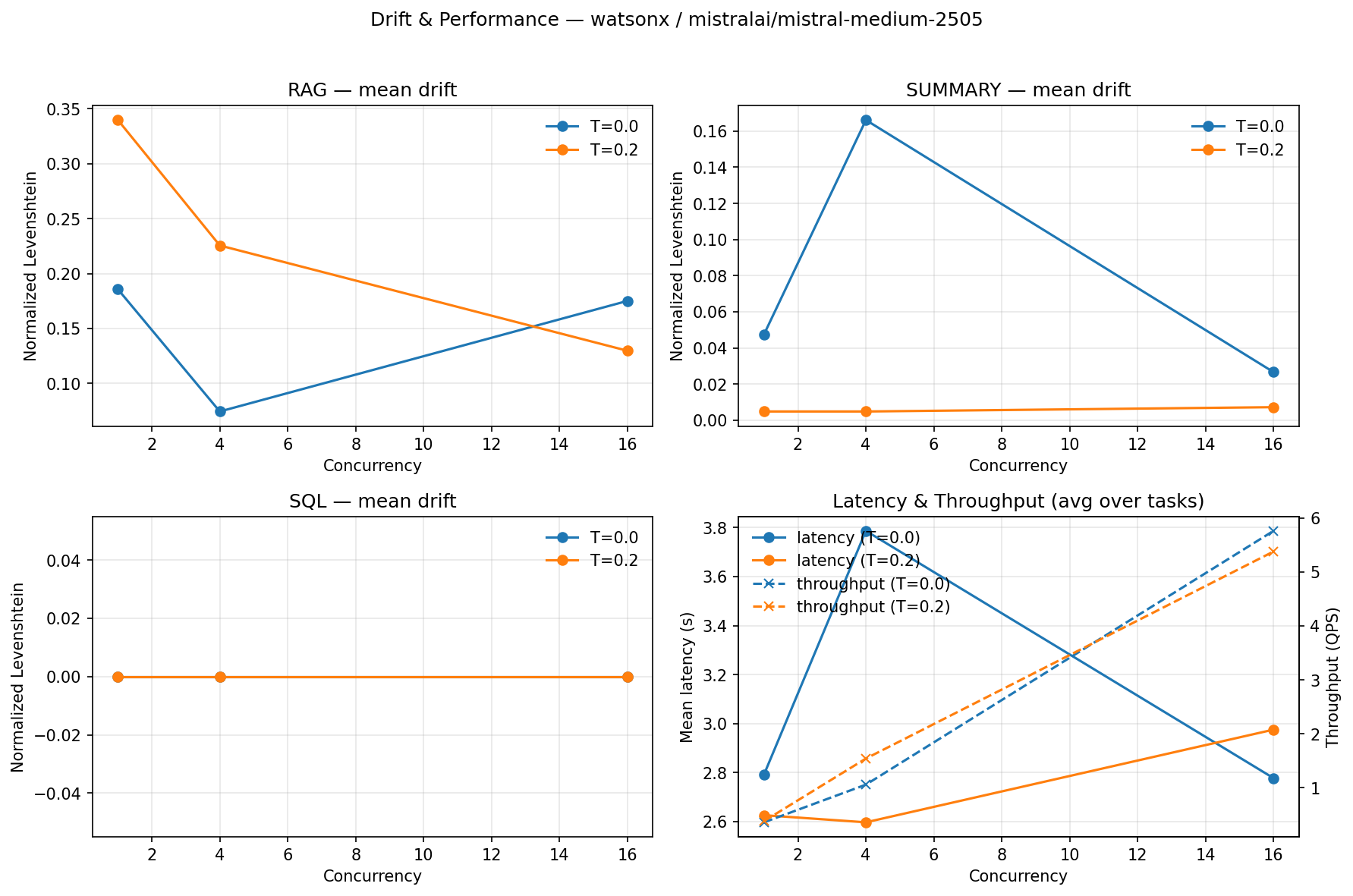
Abstract: Financial institutions deploy LLMs for reconciliations, regulatory reporting, and client communications, but nondeterministic outputs (output drift) undermine auditability and trust. We quantify drift across five model architectures (7B-120B parameters) on regulated financial tasks, revealing a stark inverse relationship: smaller models (Granite-3-8B, Qwen2.5-7B) achieve 100% output consistency at T=0.0, while GPT-OSS-120B exhibits only 12.5% consistency (95% CI: 3.5-36.0%) regardless of configuration (p<0.0001, Fisher's exact test). This finding challenges conventional assumptions that larger models are universally superior for production deployment. Our contributions include: (i) a finance-calibrated deterministic test harness combining greedy decoding (T=0.0), fixed seeds, and SEC 10-K structure-aware retrieval ordering; (ii) task-specific invariant checking for RAG, JSON, and SQL outputs using finance-calibrated materiality thresholds (plus or minus 5%) and SEC citation validation; (iii) a three-tier model classification system enabling risk-appropriate deployment decisions; and (iv) an audit-ready attestation system with dual-provider validation. We evaluated five models (Qwen2.5-7B via Ollama, Granite-3-8B via IBM watsonx.ai, Llama-3.3-70B, Mistral-Medium-2505, and GPT-OSS-120B) across three regulated financial tasks. Across 480 runs (n=16 per condition), structured tasks (SQL) remain stable even at T=0.2, while RAG tasks show drift (25-75%), revealing task-dependent sensitivity. Cross-provider validation confirms deterministic behavior transfers between local and cloud deployments. We map our framework to Financial Stability Board (FSB), Bank for International Settlements (BIS), and Commodity Futures Trading Commission (CFTC) requirements, demonstrating practical pathways for compliance-ready AI deployments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper studies a problem called “output drift” in AI chat systems, especially when banks and financial companies use them. Output drift means the AI gives different answers even when you ask it the exact same question the exact same way. That’s a big problem for finance, because laws and audits require answers to be consistent and repeatable.
The authors test different AI models, figure out why answers change, and show simple ways to make the outputs stable so banks can trust and audit them.
What questions the paper tries to answer
- Can we make AI models give the same answer every time for important financial tasks?
- Do bigger AI models behave more consistently than smaller ones—or is it the other way around?
- Which kinds of tasks are more likely to drift?
- What practical steps can banks use today to reduce drift and meet regulatory rules?
How they did the study (everyday explanation)
They tested five different AI models from different providers (some small, some very large) on three types of common finance tasks, and they ran each many times to see if the answers changed.
They compared:
- Local setups (running the model on your own machine) and cloud setups (running the model on a provider’s platform).
- A “creativity” setting called temperature. Think of it like a creativity dial: temperature 0.0 means “always pick the most likely next word” (very steady), while higher temperature (like 0.2) allows small randomness.
They focused on three task types:
- Retrieval-augmented Q&A (RAG): like an open-book quiz where the AI must read real company reports (SEC 10-Ks) and answer questions with exact citations.
- Policy-bounded JSON summaries: write short client-friendly summaries in a fixed, structured format with a required legal disclaimer.
- Text-to-SQL: turn a plain-English question into a database query, then check the result is within a realistic ±5% range (like a calculator answer with a tolerance banks consider “not materially different”).
To measure drift, they checked if the answers were exactly identical (letter-for-letter) across repeated runs. If even a small change showed up, they considered that “drift,” because auditors care about exact repeats.
They also added engineering steps to reduce drift:
- Always use the same “reading order” for documents (like sorting chapters the same way every time), so the AI sees the same facts first.
- Fix the random seed and decoding settings so the AI’s choice process is locked down.
- Enforce rules on the outputs (e.g., correct JSON shape, matching citations, and ±5% number tolerance), so small wiggles get caught.
Finally, they logged everything (prompts, answers, times, versions) to create an audit trail—proof that the same inputs lead to the same outputs later.
What they found and why it matters
Here are the main results at a glance:
- Smaller models were the most consistent. The 7–8 billion parameter models gave the exact same answer every time at temperature 0.0.
- The very large model (120B parameters) was the least consistent. It only gave the same answer about 1 out of 8 times (12.5%), even at temperature 0.0.
- Mid-sized models (40–70B) landed in the middle—sometimes consistent, sometimes not.
- The type of task matters. SQL tasks stayed stable even with a bit of randomness (temperature 0.2). RAG tasks (reading long reports) drifted much more at 0.2. Summaries were mostly stable.
Why this matters:
- In finance, laws and audits require you to reproduce results months or years later. If an AI changes its mind randomly, you can’t pass audits.
- The common belief that “bigger is always better” is not true for compliance. For high-stakes, regulated work, smaller, well-engineered models can be safer and more reliable.
- These findings help banks choose models and settings that reduce the time humans spend re-checking AI work.
What this could mean for the future
- Smarter model choices: Banks may prefer smaller, well-tuned models for regulated tasks to get stable, auditable outputs.
- Practical controls now: The paper shows simple, deploy-today steps—like fixed decoding settings, consistent document ordering, strict output checks, and cross-provider validation—that cut drift and support audits.
- Better compliance: The framework maps to what regulators want (consistent, traceable decisions with full documentation). That means AI systems can be designed from the start to pass audits.
- Lower verification costs: If outputs don’t drift, teams spend less time double-checking AI—and more time using it productively.
In short
To make AI dependable for finance, don’t just chase the biggest model. Use models and settings that keep answers the same every time, add checks that catch tiny changes, and keep clear logs. That’s how you build AI systems that auditors can trust.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to enable actionable follow-up by future researchers.
- Generalizability beyond the evaluated models: Results are based on five models (7B–120B) and do not include widely used proprietary frontier models (e.g., GPT‑4.x, Claude Opus, Gemini) or other SLM families; it remains unknown whether the observed size–determinism relationship holds across broader architectures and providers.
- Limited temperature and decoding coverage: Only and greedy decoding are tested; the impact of diverse decoding strategies (top‑k, nucleus/top‑p, beam search, contrastive/DoLa, guided decoding with JSON/SQL grammars) on determinism is left unexplored.
- Hardware and serving stack variability not systematically assessed: Determinism sensitivity to GPU type, driver/cuDNN versions, BLAS/MatMul kernels, quantization schemes (FP32, BF16, FP8, INT8), and server configurations (micro‑batching, scheduling, streaming) is not characterized.
- Batch‑invariant kernels untested in deployment: While cited, batch‑invariant kernel implementations are not integrated or benchmarked; their real‑world effectiveness, performance overhead, and portability across vLLM, TensorRT‑LLM, and HF TGI remain open.
- Limited concurrency scale: Concurrency is capped at 16; real financial systems can exceed hundreds/thousands of concurrent requests. The relationship between large-scale batching/micro‑batching and output drift is unquantified.
- Cross‑provider breadth: Validation is restricted to local (Ollama) and a single cloud (IBM watsonx.ai). Consistency across other major clouds (Azure OpenAI, Amazon Bedrock, Google Vertex AI) and on‑prem inference stacks is unverified.
- Time‑based drift and model updates: The bi‑temporal audit concept is proposed, but longitudinal tests across model revisions, tokenizer updates, and serving library upgrades (weeks–months) are not performed; durability of attestations over time is uncertain.
- Tokenizer drift impact unmeasured: Despite discussion, the paper does not quantify how tokenizer/version changes affect determinism, token counts, costs, or vulnerability to injection in the tested workflows.
- RAG retrieval generalization: The DeterministicRetriever encodes SEC 10‑K precedence; applicability to other corpora (prospectuses, research reports, multi‑document portfolios) and retrieval pipelines (vector DBs, hybrid sparse‑dense, rerankers) is not evaluated.
- Adversarial robustness and security controls: Claims reference Shadow Escape and prompt injection risks, but no experiments evaluate whether the proposed controls (retrieval ordering, invariant checks) withstand adversarial documents, tool hijacking, or malicious citations.
- Accuracy vs determinism trade‑offs: The paper prioritizes determinism but does not quantify whether smaller Tier‑1 models match large models in accuracy, calibration, and reasoning for the tested financial tasks; compliance‑viable accuracy thresholds remain unestablished.
- Statistical power and multiple comparisons: With n=16 per condition, analyses may be underpowered for moderate differences; correction for multiple model–task–temperature comparisons (e.g., Holm–Bonferroni) is not applied.
- Identity metric strictness and audit acceptability: Exact string equality () is used for identity; regulators’ tolerance for harmless surface variations (whitespace, punctuation, tokenization) is unclear. Sensitivity of conclusions to different canonicalization policies is not explored.
- Factual drift threshold rationale: A fixed ±5% tolerance is adopted as “finance‑calibrated,” but alignment with GAAP/IFRS materiality across varied contexts (e.g., risk disclosures vs. transaction sums) and auditor acceptance is not validated.
- JSON/SQL constraint mechanisms: The paper relies on post‑hoc invariant checks; proactive constrained decoding (grammar‑guided, structured prompting, toolformer patterns) and their effect on determinism and throughput are not tested.
- Streaming and function/tool calling: The impact of streaming responses, multi‑tool orchestration, function‑calling APIs, and tool latency variance on determinism is not measured, despite their prevalence in production financial assistants.
- Multi‑turn dialogues and agents: Determinism in agent loops, memory use, plan‑act‑reflect cycles, and conversation state management—core to financial advisory and operations—is not evaluated.
- Multilingual and cross‑jurisdiction behavior: The framework’s consistency is untested for multilingual outputs (e.g., EU jurisdictions, APAC markets), locale‑specific formats (dates, currency), and translation tasks crucial to cross‑border compliance.
- Real‑world SQL schemas: The SQL task uses a synthetic toy database; generalization to complex, evolving production schemas (ETL variance, late‑arriving data, partitioning) and the stability of query generation under schema drift are open.
- Throughput–determinism–cost trade‑offs: The paper states no correlation at fixed , but comprehensive cost/latency analysis under realistic load, caching, and rate limiting—and impact on determinism—is not provided.
- Root‑cause analysis for large‑model nondeterminism: The observed 12.5% consistency in GPT‑OSS‑120B is reported, but the specific culprits (kernel non‑invariance, scheduler, sampler differences, tokenizer) are not isolated or instrumented.
- Audit log immutability and provenance: “Immutable JSONL traces” are claimed without specifying tamper‑evident mechanisms (e.g., hash‑chaining, Merkle trees, WORM storage, signed manifests) or retention/compliance assurances (SOX, SEC Reg SCI).
- Regulatory validation: While mappings to FSB/BIS/CFTC are argued, there is no independent validation with regulators or external auditors confirming that the attestation framework satisfies audit standards in practice.
- Sensitivity to prompt/template changes: Determinism under minor prompt edits, template versioning, and policy disclaimer updates is untested; operational resilience to drift in prompt libraries is unknown.
- Provider policy and rate‑limit effects: The influence of API policies (retries, fallback models, dynamic batching), rate‑limit backoff, and traffic shaping on determinism is not measured.
- Reproducibility package completeness: A repository commit/tag is referenced without a URL; the absence of a publicly accessible artifact (code, manifests, data slices, seeds) hinders third‑party verification.
- Data privacy and compliance constraints: Deterministic pipelines’ interaction with privacy controls (PII redaction, data residency, encryption) and whether these controls introduce nondeterminism are not examined.
- Robustness to long contexts: Determinism with very long inputs (multi‑document, 100k+ tokens) and chunking strategies (overlap, summarization, hierarchical RAG) remains untested.
- Governance escalation and fail‑safe design: The paper does not specify operational responses when drift is detected (e.g., automated rollback, human‑in‑the‑loop thresholds, circuit breakers) or quantify their effectiveness.
Practical Applications
Overview
This paper proposes and validates a practical framework to mitigate LLM output drift in regulated financial workflows. Key contributions include a deterministic test harness (temperature 0.0, fixed seeds, structure-aware retrieval ordering), domain-calibrated invariant checks (e.g., SEC citation validation, ±5% materiality thresholds), a three-tier model classification for risk-appropriate deployment, and an audit-ready attestation system with dual-provider validation. Empirical results show small models (7–8B) can achieve 100% output consistency across providers, while a 120B model exhibits severe nondeterminism—even at temperature 0.0. Below, we outline practical applications that can be deployed immediately and those that require further development.
Immediate Applications
The following applications can be implemented with current tools and processes, leveraging the paper’s methods (deterministic decoding, retrieval-order normalization, invariant checks, and attestation).
- Compliance-ready LLM middleware for financial workflows (finance, software)
- What: Wrap existing LLM services with the proposed deterministic harness (T=0.0, fixed seeds, deterministic retriever, schema/invariant checks) to ensure reproducible outputs.
- Use cases: Reconciliations, regulatory reporting, client communications, audit responses.
- Tools/workflows: vLLM/Ollama/IBM watsonx.ai; deterministic retriever; JSON/SQL validators; Levenshtein-based identity checks; Wilson CIs; Fisher tests; JSONL trace logging.
- Assumptions/dependencies: Control over decoding parameters and retrieval pipeline; stable tokenization; acceptance of ±5% materiality thresholds; model/version pinning.
- Model tiering–based procurement and deployment policy (finance, healthcare, government)
- What: Adopt the paper’s three-tier classification (Tier 1 = 7–8B models for all regulated tasks; Tier 2 = 40–70B for structured tasks; Tier 3 = avoid for regulated use).
- Use cases: Vendor selection, internal model governance, risk gating in ML Ops.
- Tools/workflows: Consistency tests in evaluation pipelines; policy manifests capturing seeds/decoders.
- Assumptions/dependencies: Organizational agreement to prioritize determinism over brute capability in regulated contexts.
- Dual-provider validation and bi-temporal audit attestation (finance, policy)
- What: Validate outputs across local and cloud providers with identical manifests; store audit-ready JSONL traces for replay months later.
- Use cases: Regulator exams (FSB, BIS, CFTC), internal audit, cross-border compliance.
- Tools/workflows: Trace vault with corpus versioning, citation provenance, decision flip rate metrics.
- Assumptions/dependencies: Access to at least two providers; strict version control for prompts and corpora.
- Deterministic SEC RAG for disclosure-driven tasks (finance)
- What: Implement the SEC 10-K structure-aware retrieval ordering (score↓, section_priority↑, snippet_id↑, chunk_idx↑) and exact citation preservation.
- Use cases: Investor relations Q&A, regulatory inquiries, due diligence.
- Tools/workflows: SEC ID mapping; chunking and retrieval normalization; citation validators.
- Assumptions/dependencies: Stable SEC corpus snapshots; consistent chunking/tokenization; domain ontology for section precedence.
- JSON template enforcement for regulated communications (finance, insurance, healthcare)
- What: Enforce schema and disclaimer invariants in client communications to eliminate drift in required fields and legal language.
- Use cases: KYC updates, compliance notices, claims correspondence, adverse action letters.
- Tools/workflows: JSON schema validators, deterministic prompts, fixed disclaimers.
- Assumptions/dependencies: Approved legal templates; integration with CRM/email systems.
- Text-to-SQL with invariant checks for reporting accuracy (finance, energy, education)
- What: Constrain generated queries and verify aggregates against ground truth within ±5% to prevent numerical drift.
- Use cases: Financial dashboards, audit reconciliations, KPI reporting, budget tracking.
- Tools/workflows: Post-execution validators; schema-aware prompting; BI integration.
- Assumptions/dependencies: Known totals or authoritative reference tables; stable schemas.
- LLM observability and drift monitoring integration (software, operations)
- What: Track normalized edit distance, factual drift (citations, numbers), and schema violations; alert on variance.
- Use cases: Production monitoring, incident detection, SRE runbooks.
- Tools/workflows: Integration with LLM observability platforms; feature flags to force deterministic mode.
- Assumptions/dependencies: Logging/telemetry budgets; governance acceptance of automated gating.
- Incident response runbook for output drift (enterprise IT)
- What: Operational procedures to contain drift: revert to Tier 1 models, enforce T=0.0, freeze tokenizers, disable batch-variant kernels, pin versions.
- Use cases: Outages, misconfiguration events, suspect model updates.
- Tools/workflows: CI/CD rollback, deterministic kernel configuration, tokenizer version pinning.
- Assumptions/dependencies: Access to serving stack configuration; change management discipline.
- Non-finance deterministic outputs for daily tasks (daily life, education, software)
- What: Fixed-seed, template-driven tools for consistent resumes, lesson plans, rubrics, code snippets with guardrails.
- Use cases: Educator grading rubrics, legal/HR disclaimers, reproducible code generation in CI.
- Tools/workflows: Seeded prompts; schema validators; deterministic decoding.
- Assumptions/dependencies: Willingness to trade creativity for reproducibility in critical outputs.
- Regulatory documentation mapping and acceleration (policy, finance)
- What: Generate regulator-ready documentation aligned to NIST AI RMF (GAI profile), GAO, OCC, BIS/FSB expectations using the audit traces.
- Use cases: Model risk management submissions, supervisory exams, AI program governance.
- Tools/workflows: Documentation templates; trace-to-requirement mapping.
- Assumptions/dependencies: Internal risk teams; clear linkage between trace metrics and regulatory controls.
Long-Term Applications
These applications will benefit from additional research, standardization, vendor support, and scaling (e.g., deterministic kernels, tokenizer governance, sector-wide adoption).
- Certification standard for deterministic LLMs (policy, industry-wide)
- What: A recognized accreditation that includes determinism metrics (e.g., TAR, identity rate, CI reporting), tier labels, and audit practices.
- Impact: Procurement clarity; regulatory acceptance of “determinism-ready” models.
- Dependencies: Regulator and standards body collaboration (NIST, BIS/FSB); third-party auditors.
- Batch-invariant and deterministic kernel adoption across serving stacks (software, AI infrastructure)
- What: Mainstream support in vLLM, PyTorch, and cloud inference for batch-invariant operations to eliminate infra-induced nondeterminism.
- Impact: Reliability under concurrency; reduced drift in production.
- Dependencies: Vendor engineering; hardware-specific optimizations; community benchmarks.
- Tokenizer governance and security (software, cybersecurity, policy)
- What: Standardize tokenization to prevent drift and injection risks; mandate version pinning and attestations.
- Impact: Predictable costs and behavior; reduced surface for context protocol attacks.
- Dependencies: Model/provider cooperation; security reviews; industry guidelines.
- Compliance-grade RAG products for other regulated domains (healthcare, legal, public sector)
- What: Domain-aware retrieval precedence rules (e.g., HIPAA documentation, case law hierarchies) and citation invariants.
- Impact: Auditable RAG for clinical documentation, legal discovery, public records.
- Dependencies: Sector ontologies; corpus normalization pipelines; legal acceptance.
- Multi-model consensus validation services (finance, healthcare)
- What: Cross-check outputs with two or more Tier 1 SLMs; escalate on disagreement; log consensus audits.
- Impact: Reduced single-model risk; stronger attestations.
- Dependencies: Cost/latency budgets; orchestration middleware; model diversity.
- Risk-aware inference policies with dynamic determinism (software, enterprise governance)
- What: Policy engines that switch between deterministic (T=0.0) and non-deterministic modes based on task criticality, logging, and materiality rules.
- Impact: Balanced creativity and compliance; automated governance.
- Dependencies: Fine-grained task classification; policy authoring; observability integration.
- Reproducibility-aware benchmarks and leaderboards (academia, industry)
- What: Extend FinBen/SEC-QA/DocFinQA with reproducibility metrics alongside accuracy; public leaderboards reporting consistency CIs.
- Impact: Model selection that values auditability; research incentives.
- Dependencies: Dataset maintainers; community adoption; standardized metrics and protocols.
- Audit-ready AI trace vault products (software, data governance)
- What: Bi-temporal storage, replay tools, and regulator report generators built into MLOps platforms.
- Impact: Faster audit responses; durable compliance posture.
- Dependencies: Long-term storage strategies; privacy and retention policies; integration with governance tools.
- Deterministic small-model agents for finance (finance, robotics/process automation)
- What: SLM-based agent frameworks tuned for deterministic decision steps in credit, trade surveillance, reconciliations.
- Impact: Reliable automation in high-stakes workflows; reduced verification overhead.
- Dependencies: Agent tooling; domain-specific guardrails; ongoing evaluation.
- Cross-jurisdiction consistency tooling (policy, multi-cloud operations)
- What: Systems that demonstrate consistent behavior across regions/providers for MiFID II, Basel III, and local supervisory regimes.
- Impact: Easier global approvals; resilience to regional outages.
- Dependencies: Multi-cloud orchestration; harmonized corpora; legal frameworks for data residency.
- Automated attestation generators and CI/CD gates (software, compliance engineering)
- What: Pipelines that compile manifests, metrics, and statistical reports into regulator-ready attestations; block non-deterministic outputs in protected flows.
- Impact: Continuous compliance; reduced manual effort.
- Dependencies: DevOps integration; policy mappings; artifact signing.
- Deterministic decision engines for credit and risk (finance)
- What: End-to-end systems where deterministic LLM components feed rule-based or statistical models for audit-ready outcomes.
- Impact: Reduced rework; defensible decisions under supervision.
- Dependencies: Integration with risk systems; acceptance of hybrid (LLM + rules) architecture.
- Sector expansions (energy, education, environmental reporting)
- What: Apply SQL invariants and retrieval normalization to grid operations reports, grading systems, ESG disclosures.
- Impact: Trustworthy automated reporting across sectors.
- Dependencies: Domain schemas; regulated documentation standards; stakeholder buy-in.
Each long-term application assumes broader ecosystem changes (standards, vendor support, policy adoption) and may require performance engineering to maintain throughput while enforcing determinism.
Glossary
- Agentic inference: Inference style where models perform goal-directed, autonomous actions or reasoning steps. "advocating smaller models for efficient, deterministic agentic inference."
- Attestation system: A mechanism to formally prove and record that system outputs meet compliance criteria. "an audit-ready attestation system with dual-provider validation."
- Basel III: Global banking regulatory framework setting risk and capital standards, including expectations for explainability. "Basel III, Dodd-Frank, MiFID II mandate explainable and consistent decision-making for credit, trading, and risk management."
- Batch-invariant kernels: Specialized inference kernels engineered to produce identical results regardless of batch composition. "Their batch-invariant kernels achieve exact reproducibility by ensuring operations yield identical results regardless of batch composition."
- Bi-Temporal Regulatory Audit System: An audit logging design that captures both event time and record versioning to support long-term regulatory audits. "Bi-Temporal Regulatory Audit System: All experimental runs generate immutable audit logs"
- Bi-temporal audit trails: Audit records that track decisions across time and document versions, enabling reproducible regulatory review. "bi-temporal audit trails mapped to FSB/CFTC requirements—innovations requiring financial regulatory expertise beyond general ML reproducibility techniques"
- CFTC 24-17: A U.S. Commodity Futures Trading Commission staff letter setting documentation expectations for AI outcomes. "CFTC 24-17 'document all AI outcomes'"
- Citation validation (SEC citation validation): Ensuring generated outputs preserve exact source references required for regulatory compliance. "SEC citation validation—RAG outputs must preserve exact citation references (e.g., [citi_2024_10k])"
- Cross-provider validation: Verifying that model behavior remains consistent across different deployment environments or vendors. "Cross-provider validation confirms deterministic behavior transfers between local and cloud deployments."
- Decision flip rate: Metric capturing how often binary or categorical decisions change across repeated runs. "decision-level compliance metrics (citation_accuracy, schema_violation, decision_flip)"
- Deterministic kernels: Inference implementations designed to eliminate numerical or scheduling randomness for repeatable outputs. "The vLLM serving infrastructure with PagedAttention provides efficient batching that can be extended with deterministic kernels."
- DeterministicRetriever: A retrieval component enforcing a fixed, rule-based ordering of documents/snippets to prevent nondeterministic context assembly. "DeterministicRetriever implementing multi-key ordering (score↓, section_priority↑, snippet_id↑, chunk_idx↑)"
- Dual-provider validation: A control where outputs are checked across two independent providers to ensure jurisdictional and infrastructure consistency. "dual-provider validation reduces the likelihood of outputs varying across cloud (IBM watsonx.ai) and local (Ollama) deployments"
- EDGAR: The SEC’s Electronic Data Gathering, Analysis, and Retrieval system for public company filings. "SEC EDGAR database"
- Factual drift: Changes in facts (numbers, citations) across runs that breach compliance or audit requirements. "Factual drift counts differ if (a) the set of citation IDs differs or (b) any extracted numeric value differs"
- Fisher's exact test: A statistical test for significance on small samples or categorical data, used to compare model consistency rates. "p<0.0001, Fisher's exact test"
- Finance-calibrated tolerance thresholds: Domain-specific numeric tolerances (e.g., ±5%) reflecting materiality limits in financial auditing. "finance-calibrated tolerance thresholds (±5%) as acceptance gates"
- Financial Stability Board (FSB): International body setting financial stability policy, including expectations for AI consistency and traceability. "The Financial Stability Board requires 'consistent and traceable decision-making'"
- GAAP materiality threshold: Accounting practice defining the size of a discrepancy that is significant enough to affect financial reporting. "reflecting GAAP materiality thresholds"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step, often used with temperature zero for determinism. "greedy decoding ($T{={0.0})"</li> <li><strong>Invariant checking</strong>: Validation that outputs satisfy fixed properties or constraints, regardless of minor variations. "task-specific invariant checking for RAG, JSON, and SQL outputs"</li> <li><strong>Levenshtein edit distance</strong>: A string metric counting the minimum number of insertions, deletions, or substitutions to transform one text into another. "where $ED$ is the Levenshtein edit distance"
- MiFID II: EU directive governing financial markets, with requirements for consistency and accountability in decision-making. "Basel III, Dodd-Frank, MiFID II mandate explainable and consistent decision-making for credit, trading, and risk management."
- Model tier classification: A structured categorization of models by consistency and compliance suitability. "a three-tier model classification system enabling risk-appropriate deployment decisions"
- Normalized edit distance: Edit distance scaled by the length of the longer string, used to assess output identity for audits. "The normalized edit distance is defined as:"
- PagedAttention: An attention mechanism in vLLM that enables efficient memory management and batching for large models. "The vLLM serving infrastructure \cite{kwon2023} with PagedAttention provides efficient batching"
- Retrieval-augmented generation (RAG): A technique where external documents are retrieved and fed into the model to ground responses. "RAG tasks show drift (25–75%)"
- Retrieval-order normalization: Standardizing the order of retrieved contexts to avoid randomness in prompt construction. "seeded decoding, retrieval-order normalization, and schema-constrained outputs—reduce drift"
- Schema-constrained outputs: Forcing generated content to match a predefined structure (e.g., JSON, SQL schema) to improve consistency. "seeded decoding, retrieval-order normalization, and schema-constrained outputs—reduce drift"
- Schema violation: An output error where generated content does not conform to the required structure. "decision-level compliance metrics (citation_accuracy, schema_violation, decision_flip)"
- SEC 10-K: Annual report filed to the U.S. Securities and Exchange Commission, used as a regulated data source. "SEC 10-K structure-aware retrieval ordering"
- Seeded decoding: Running generation with fixed random seeds to minimize stochastic variation. "seeded decoding, retrieval-order normalization, and schema-constrained outputs—reduce drift"
- Text-to-SQL: Converting natural language queries into executable SQL statements, often with post-execution validation. "Text-to-SQL with Invariants"
- Tokenizer drift: Variability in tokenization over time or versions that alters token counts and can introduce vulnerabilities. "Tokenizer drift—where text normalization changes inflate token counts by up to 112% and enable command injection vulnerabilities"
- Total Agreement Rate (TAR): A metric capturing the proportion of runs that produce identical outputs. "They introduced the Total Agreement Rate (TAR) metric"
- vLLM: An LLM serving system focused on high-throughput inference with advanced attention and batching strategies. "The vLLM serving infrastructure with PagedAttention provides efficient batching"
- Wilson confidence interval: A method for confidence intervals on proportions that performs well with small samples. "We report identity rate with Wilson 95% CIs"
Collections
Sign up for free to add this paper to one or more collections.

