Generating an Image From 1,000 Words: Enhancing Text-to-Image With Structured Captions
Abstract: Text-to-image models have rapidly evolved from casual creative tools to professional-grade systems, achieving unprecedented levels of image quality and realism. Yet, most models are trained to map short prompts into detailed images, creating a gap between sparse textual input and rich visual outputs. This mismatch reduces controllability, as models often fill in missing details arbitrarily, biasing toward average user preferences and limiting precision for professional use. We address this limitation by training the first open-source text-to-image model on long structured captions, where every training sample is annotated with the same set of fine-grained attributes. This design maximizes expressive coverage and enables disentangled control over visual factors. To process long captions efficiently, we propose DimFusion, a fusion mechanism that integrates intermediate tokens from a lightweight LLM without increasing token length. We also introduce the Text-as-a-Bottleneck Reconstruction (TaBR) evaluation protocol. By assessing how well real images can be reconstructed through a captioning-generation loop, TaBR directly measures controllability and expressiveness, even for very long captions where existing evaluation methods fail. Finally, we demonstrate our contributions by training the large-scale model FIBO, achieving state-of-the-art prompt alignment among open-source models. Model weights are publicly available at https://huggingface.co/briaai/FIBO
























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making text-to-image AI (the kind of models that turn words into pictures) much better at following detailed instructions. Instead of training models on short, vague prompts like “a cat on a couch,” the authors train on long, organized captions (often over 1,000 words) that describe every important part of a scene. They also introduce a new way to combine text and image information efficiently and a new test to measure how well the model understands and follows very detailed prompts. Their model, called FIBO, is open-source and shows strong control and accuracy.
What questions did the researchers ask?
They focused on three simple questions:
- Can we make text-to-image models more precise by feeding them long, structured captions that include all the details people care about (objects, positions, lighting, camera settings, and more)?
- Can we fuse (mix) text information from a LLM into the image model efficiently, even when the captions are very long?
- How do we fairly test whether a model truly understands and follows long, detailed captions, not just short ones?
How did they do it?
Long structured captions: turning a prompt into a blueprint
Instead of a short sentence, they use a “blueprint” for each image: a structured caption in a consistent format (like a carefully filled-out form or a well-organized checklist). It covers:
- What’s in the scene (objects, people) and where each thing is (position, size).
- How things look (colors, textures, expressions).
- Global settings (background, lighting, camera angles, depth of field, composition). These captions are stored as JSON (think of it like a neat, computer-friendly form). A vision–LLM (VLM) helps expand short user prompts into this detailed JSON and can refine it based on editing instructions.
DimFusion: packing more information into each word
Long captions can be expensive to process. Their new method, DimFusion, mixes text and image information without adding more “tokens” (tokens are small pieces of text the model reads). DimFusion works like packing more info into each word instead of adding more words:
- It takes useful signals from different layers of a LLM and merges them into the features of each token.
- This keeps the sequence length the same (faster and cheaper) while still giving the image model rich, layered text meaning.
TaBR (Text-as-a-Bottleneck Reconstruction): a fair test for long prompts
Evaluating long captions is hard—humans get tired, and common automatic tests don’t handle 1,000-word prompts well. TaBR is a simple, image-grounded test:
- Start with a real image.
- Use a captioner to write a detailed structured caption of that image.
- Use the text-to-image model to rebuild the image from that caption.
- Compare the new image to the original. If the reconstruction is close, the model understood and followed the caption well. This directly measures controllability (can you get exactly what you asked for?) and expressiveness (can the caption capture all the needed details?).
FIBO: the model they built and released
They trained a large text-to-image model named FIBO on this structured-caption data and connected it with their VLM workflow:
- Generate: expand a short user prompt into a detailed structured caption.
- Refine: change specific parts (e.g., “make the background evening light,” “set camera from above”).
- Inspire: caption an input image into JSON and edit from there.
They also fine-tuned an efficient open-source VLM so the whole system can be used by the community.
What did they find?
- Better control: FIBO can change one thing without messing up others (this is called “disentanglement”). For example, you can adjust “depth of field” (how blurry the background is) or set different facial expressions for multiple people in the same image without unexpected changes elsewhere.
- Better alignment to prompts: It follows unusual or tricky instructions (like “a bear doing a handstand in the park” or “a professional boxer does a split”) more faithfully, instead of defaulting to common scenes.
- Faster and higher quality training: Models trained on long, structured captions converge faster and produce better-looking images than models trained on short captions. In their tests, they got a much lower FID score (a standard “lower is better” image-quality metric), showing clear improvements.
- Efficient text–image fusion: DimFusion lets the model use rich language-model features without slowing down by increasing the token count.
Why does it matter?
- For creators and professionals: You get reliable control over the final image—composition, lighting, camera settings, object attributes, and more—without trial-and-error or the model “guessing” your intent.
- For the AI community: FIBO and its weights are open-source, so others can build on this approach. The structured-caption idea and the TaBR evaluation give a practical path to train and measure future models for real-world, detailed use.
- For everyday users: Even if you don’t want to write a 1,000-word prompt, the system can turn your short prompt into a detailed plan, and you can tweak it with simple instructions like “make it evening” or “change the sign to red.”
In short, this paper shows that if you treat text like a detailed blueprint and pack language understanding efficiently into image generation, you get a model that follows instructions better, gives you precise control, and creates images that match your ideas much more faithfully.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and unresolved questions that future researchers could address:
- Training data transparency and reproducibility: The paper does not disclose the sources, size, licensing, domain composition, or demographic distribution of the images paired with structured captions; releasing the dataset or a generator to reproduce the captions would enable replication and bias audits.
- Accuracy and reliability of structured JSON captions: There is no quantitative validation of VLM-generated attribute correctness (e.g., object positions, lighting, camera parameters, ethnicity, expressions); measuring error rates against human-verified ground truth and analyzing failure modes is needed.
- Schema design ablation: The effects of schema choices (which fields exist, required vs optional fields, granularity of attributes, handling of relations/contradictions) on controllability and alignment are unstudied; identify minimal and sufficient field sets and test hierarchical vs flat schemas.
- Handling noisy, incomplete, or contradictory captions: The model’s robustness when fields are missing, inconsistent, or adversarially specified is not evaluated; stress tests should quantify degradation and propose validation/auto-correction mechanisms.
- Generalization to free-form short prompts: While a VLM bridge is proposed, there is no direct evaluation of FIBO’s performance on standard short natural language prompts without structured conversion; measure degradation and add mitigation strategies.
- DimFusion efficiency claims: Compute savings, memory footprint, and throughput vs baselines (e.g., concatenating intermediate layers along the sequence dimension, dual-stream decoder setups) are not benchmarked; provide wall-clock, FLOPs, and GPU memory comparisons across caption lengths.
- DimFusion design choices: The impact of concatenating intermediate layers along the embedding dimension, the D/2 projection ratio, layer selection strategy, gating/weighting, and fusion frequency across blocks is not ablated; systematic studies could optimize architecture.
- LLM size trade-offs for text encoding: The claim that a “relatively small LLM suffices” lacks quantitative comparisons vs larger LLMs; characterize alignment/controllability vs compute across LLM scales and tokenizer settings.
- Long-context handling: With 1,000–1,800 tokens per caption, there is no analysis of attention degradation, recency effects, or truncation strategies; evaluate sensitivity to token position, context length, and memory-efficient attention variants.
- Disentanglement quantification: Disentanglement is demonstrated qualitatively but not measured; develop intervention-based metrics (e.g., attribute change impact scores, mutual information, causal tests) across factors and seeds to quantify isolation of edits.
- TaBR protocol rigor: The captioner choice, error compounding (image→caption→image), leakage risks, and sensitivity to different captioners are not analyzed; standardize captioners, report inter-rater reliability for human judgments, and compare perceptual metrics (e.g., LPIPS, DINO features).
- Human evaluation methodology: Details on participant numbers, instructions, inter-rater agreement, and statistical significance for TaBR human assessments are missing; formalize protocols and release evaluation scripts.
- Benchmark coverage and quantitative comparisons: Aside from FID at 256×256 and limited visual examples (ContraBench, Whoops), comprehensive quantitative alignment on compositional benchmarks (e.g., T2I-CompBench, ARO, GenEval) is absent; report cross-model comparisons and standardized metrics.
- Aesthetic predictors usage: It is unclear whether aesthetic scores are used as conditioning, loss weighting, or only for metadata; ablate their functional role and impact on output quality and style controllability.
- End-to-end usability and latency: The practical overhead of the VLM “Generate/Refine/Inspire” loop is not measured; report latency, cost, caching strategies, and failure rates of JSON parsing/validation in real workflows.
- Safety, ethics, and fairness: The paper does not assess bias or harm risks, especially with sensitive attributes (e.g., ethnicity, body features, gender presentation); conduct fairness audits, implement safety filters for structured fields, and evaluate misuse scenarios.
- Cross-lingual support: While the VLM is multilingual, it is unclear whether the image model handles non-English structured prompts or multilingual text content in images; evaluate cross-lingual performance and schema portability.
- Out-of-schema generalization: The model may overfit to the structured schema; test robustness to alternative or partial schemas and to free-form text without JSON.
- Real-image editing capability: The work focuses on generation from structured prompts with fixed seeds; explore conditioning on input images (e.g., image editing, inpainting) and quantify disentangled edits on real images.
- Scaling and resolution: Beyond a 256×256 ablation, details on FIBO’s high-resolution performance, scaling laws with caption length, and resolution-aware behavior are missing; report results at production resolutions and study diminishing returns.
- Diversity vs controllability trade-off: Training with exhaustive captions may bias toward precision at the expense of creative diversity; quantify diversity (e.g., Fréchet Inception Distance variants, mode coverage) under varying caption detail.
- Data governance and privacy: The provenance and licensing of training images, privacy considerations, and filtering for personally identifiable information are not discussed; document data governance and consent mechanisms.
- Implementation details for reproducibility: Full training hyperparameters, optimizer schedules, augmentation, curriculum, and compute budgets are not provided; release configs and training logs to enable replication.
- Failure case taxonomy: Systematic characterization of where FIBO fails (e.g., complex occlusions, rare relations, extreme lighting/camera parameters, crowded scenes) is missing; build a taxonomy and targeted test suites.
- Integration with existing toolchains: The paper does not discuss interoperability with widely used T2I ecosystems (ControlNet, LoRA, IP-Adapter) or how structured captions complement or replace them; evaluate combined setups.
- Legal and licensing of released weights: The licensing terms and usage restrictions for FIBO weights are not specified; clarify permissible use to support open research and commercial adoption.
Practical Applications
Immediate Applications
Below is a concise set of practical use cases that can be deployed today by leveraging FIBO (open-source model), DimFusion (efficient fusion mechanism), structured JSON captions, and the TaBR evaluation protocol. Each item includes sector alignment and key assumptions or dependencies.
- Precision creative production and art direction (media & entertainment, advertising, design)
- Use case: Generate shots with explicit control over composition, lighting, depth of field, lens specifications, and multi-subject expressions, reducing iteration cycles between creative teams and clients.
- Tools/workflows: “Prompt-to-JSON” expander (VLM), JSON-based shot editor, FIBO generation API, brand-safe preset libraries.
- Assumptions/dependencies: Access to FIBO weights and GPU resources; a UI that abstracts JSON editing; content safety filters and internal usage policies.
- E-commerce product imagery at scale (retail, marketplaces)
- Use case: Produce consistent, on-brand product images with controlled backgrounds, camera parameters, and lighting; run A/B tests for conversion with structured variants.
- Tools/workflows: PIM-to-FIBO connector that maps product metadata to structured JSON; batch generation pipelines; brand compliance validators.
- Assumptions/dependencies: High-quality product metadata; clear IP/licensing and disclosure policies; human QA for edge cases.
- Multisubject portrait control and expression targeting (marketing, HR communications, events)
- Use case: Precisely specify facial expressions and poses for multiple subjects in one scene (e.g., marketing heroes, team photos).
- Tools/workflows: Studio-in-a-box interface for expression parameters; iterative JSON refinement via VLM.
- Assumptions/dependencies: Fairness and representational balance; appropriate consent workflows when referencing specific identities; robust safety checks.
- Film/TV previsualization and shot listing (media production)
- Use case: Convert shot lists into photorealistic frames with controlled lens specs, depth-of-field, composition, and lighting to plan scenes and communicate intent.
- Tools/workflows: Shot-list-to-JSON plugin; FIBO generation in previs tools; iterative “Refine” loop with VLM.
- Assumptions/dependencies: Mapping of cinematography terms to the structured schema; team training for JSON-based workflows.
- Photography education and training (education)
- Use case: Interactive learning of photographic principles (DOF, lighting, composition) by specifying camera settings and immediately visualizing outcomes.
- Tools/workflows: “Virtual Camera Lab” built on FIBO; guided exercises with structured captions for lesson plans.
- Assumptions/dependencies: Simple UI that abstracts JSON; commodity GPUs or cloud access.
- Accessibility and alt‑text generation (software, public sector)
- Use case: Produce machine‑readable, detailed structured descriptions from existing images to improve alt‑text and accessibility compliance (WCAG).
- Tools/workflows: Structured captioner (VLM) pipeline; CMS plugin to attach JSON alt‑text; optional human review.
- Assumptions/dependencies: Captioner accuracy on diverse content; privacy and data handling for sensitive images; language coverage.
- Model controllability benchmarking with TaBR (academia, AI labs, compliance)
- Use case: Evaluate prompt alignment and expressive power by reconstructing images from captions and comparing similarity to originals.
- Tools/workflows: TaBR toolkit integrating captioner + FIBO + human/perceptual similarity scoring; experiment dashboard.
- Assumptions/dependencies: Availability of human raters for higher reliability; consistent captioner; agreed‑upon perceptual metrics.
- Structured content moderation and governance (enterprise software, policy)
- Use case: Use machine‑readable captions to validate constraints pre‑generation (e.g., no disallowed content, protected attributes) and document decisions for audits.
- Tools/workflows: JSON schema validators; rule engines; logging for audit trails.
- Assumptions/dependencies: Clear internal policies and taxonomies; robust detectors; alignment with regional regulations.
- Multilingual creative pipelines (global marketing, localization)
- Use case: Expand short prompts in any language into a unified structured schema for consistent outputs across locales.
- Tools/workflows: Multilingual VLM expander; locale‑specific style presets; batch generation orchestrator.
- Assumptions/dependencies: VLM multilingual capability and fine‑tuning; localized brand guidelines.
- Synthetic data for visual reasoning tasks (computer vision, robotics R&D)
- Use case: Generate datasets with controlled contextual relations (e.g., “contextual contradictions”) for training and evaluating reasoning‑aware CV models.
- Tools/workflows: Dataset generator that enumerates structured caption variations; labeling via the same schema; automated splits.
- Assumptions/dependencies: Domain gap considerations when training real‑world models; need for downstream labels beyond captions for certain tasks; ethical review for content types.
Long‑Term Applications
The following applications require further research, scaling, standardization, or integration to reach production maturity.
- Industry‑wide structured prompt standardization (software, media, advertising)
- Use case: Adopt a shared JSON schema for text‑to‑image across tools and vendors to enable interoperability and auditability.
- Tools/workflows: Standards consortium; reference implementations; conformance tests.
- Assumptions/dependencies: Stakeholder buy‑in; governance processes; evolving schema versions for domain‑specific needs.
- Fully automated product imagery from PIM at global scale (retail, marketplaces)
- Use case: Generate millions of SKU images directly from product metadata with minimal human intervention.
- Tools/workflows: High‑throughput orchestration; automated QA; exception handling; continuous TaBR‑style monitoring.
- Assumptions/dependencies: Throughput and cost constraints; strong QA pipelines; regulatory acceptance and disclosure practices.
- 3D/physics‑aware generation via scene graphs (robotics, simulation, VFX)
- Use case: Extend structured captions to 3D scene graphs and physical constraints for simulation‑ready assets and planning.
- Tools/workflows: Scene‑graph generators; differentiable renderers; physics engines; text‑to‑3D bridges.
- Assumptions/dependencies: Advances in 2D‑to‑3D grounding; physically accurate rendering; standard 3D schemas.
- Video generation from structured shot specs (media production, education)
- Use case: Generate sequenced shots with camera motion, continuity, and temporal lighting control from a structured storyboard.
- Tools/workflows: “Storyboard‑to‑video” pipelines; temporal consistency modules; editing tools.
- Assumptions/dependencies: Stable, controllable text‑to‑video models; temporal TaBR‑style evaluation; compute scaling.
- Domain‑specialized synthetic imaging (healthcare, scientific R&D)
- Use case: Produce domain‑accurate synthetic images (e.g., medical, microscopy) with explicit control over anatomy or instrument parameters for training and QA.
- Tools/workflows: Clinical schema extensions; domain‑validated captioners; expert‑in‑the‑loop verification.
- Assumptions/dependencies: Regulatory approval; domain generalization; bias and safety assessments; rigorous validation.
- Accessibility co‑creation for blind/low‑vision creators (public sector, education)
- Use case: Author or edit structured captions via voice or tactile interfaces to generate images aligned with intent; enable iterative co‑creation loops.
- Tools/workflows: Voice‑first JSON editors; auditory feedback; guided refinement using VLM; provenance tracking.
- Assumptions/dependencies: Inclusive UX; reliable prompt‑to‑image alignment; safeguards against unintended content.
- Formal compliance auditing using TaBR‑like standards (policy, governance)
- Use case: Regulators and auditors adopt controllability and reconstruction‑based benchmarks to certify generative systems.
- Tools/workflows: Auditor suite; standardized datasets; reporting templates; provenance and watermarking integrations.
- Assumptions/dependencies: Broad acceptance of evaluation protocols; harmonized metrics; integration with compliance frameworks.
- Edge/mobile deployment via DimFusion‑optimized encoders (consumer apps)
- Use case: Bring controllable generation to mobile devices by keeping token lengths fixed and optimizing computation, enabling on‑device creative assistants.
- Tools/workflows: Quantized runtimes; hardware‑aware kernels; memory‑efficient captioners.
- Assumptions/dependencies: Further efficiency gains; hardware capabilities; privacy and safety on device.
- Multi‑agent creative assistants (software)
- Use case: Orchestrate captioner, generator, and critic in a TaBR loop to automatically refine outputs toward user‑defined constraints (composition, lighting, emotion).
- Tools/workflows: Agent frameworks; constraint solvers; feedback policies; versioned artifacts.
- Assumptions/dependencies: Low‑latency coordination; reliability under non‑determinism; human‑in‑the‑loop guardrails.
- Cross‑modal education and assessment (education)
- Use case: Teach visual reasoning by mapping structured language to images and back (image→caption→image), evaluating fidelity to intent.
- Tools/workflows: Curriculum platforms; classroom dashboards; formative assessment using TaBR.
- Assumptions/dependencies: Age‑appropriate content; educator training; alignment with learning standards.
Glossary
- Aesthetic predictors: Models that score the aesthetic quality of images to quantify visual appeal. "two dedicated aesthetic predictors~\cite{kirstain2023pick,laion2022_aesthetics_v1}"
- Bidirectional textâimage mixing: Joint attention between text and image tokens that allows mutual influence during generation. "adopts DiT-style architectures with bidirectional textâimage mixing"
- Captioningâgeneration loop: An evaluation pipeline that captions a real image and regenerates it from the caption to test controllability. "captioningâgeneration loop"
- Cross-attention: An attention mechanism that injects text features into image generation by attending across modalities. "via cross-attention"
- Cycle consistency: The principle that translating data to another domain and back should approximately reconstruct the original. "Cycle consistency is the principle that translating an input from one domain to another and back should approximately reconstruct the original (e.g., imagetextimage)."
- Cycle-consistency-based evaluation: An assessment method leveraging cycle consistency to measure alignment and reconstruction quality. "Cycle-consistency-based evaluation."
- Depth of field: The range of distances in a scene that appears acceptably sharp, controllable by camera settings. "Shallow depth of field"
- DiT-style architectures: Diffusion Transformer designs for image generation that use transformer backbones. "adopts DiT-style architectures with bidirectional textâimage mixing"
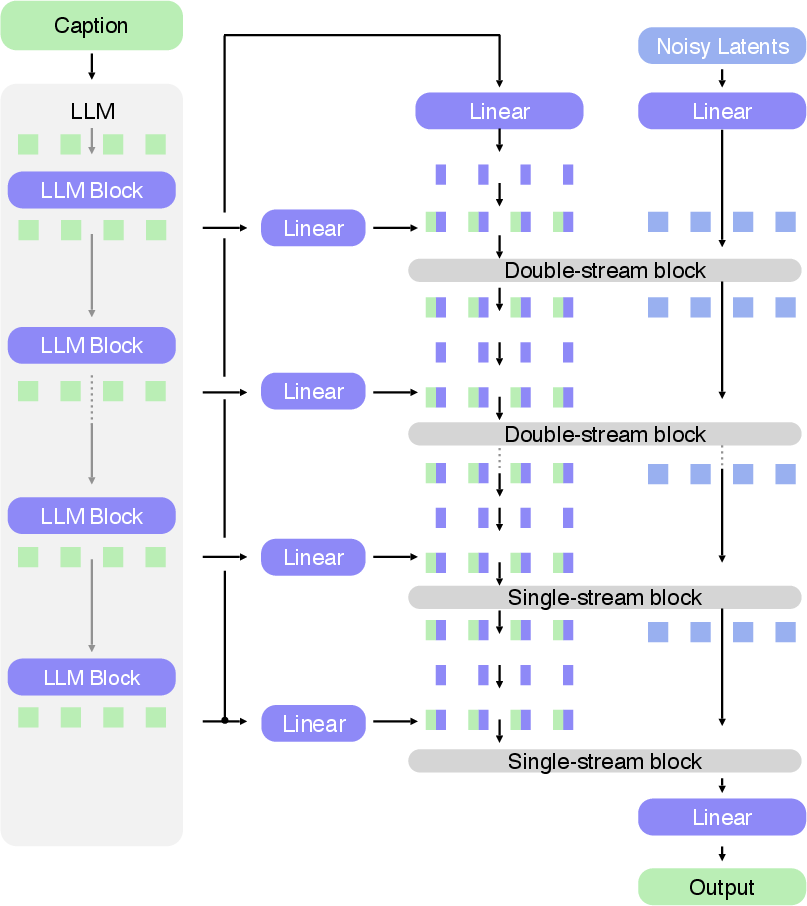
- DimFusion: A fusion mechanism that integrates intermediate LLM representations with image tokens without increasing token length. "We present DimFusion, an efficient mechanism for fusing intermediate LLM representations into a text-to-image model."
- Disentanglement: The property that individual factors of variation (e.g., color, lighting) can be controlled independently. "Structured captions encourage disentanglement."
- Dual-stream blocks: Transformer blocks that process text and image streams jointly before transitioning to single-stream processing. "dual-stream blocks followed by single-stream blocks"
- FIBO: A large-scale open-source text-to-image model trained on long structured captions for controllable generation. "Finally, we introduce FIBO, a large-scale text-to-image model capable of generating an image from structured long captions."
- FID (Fréchet Inception Distance): A metric for comparing distributions of generated and real images; lower is better. "long captions yield lower (better) FID."
- Flow-matching objectives: Training objectives that align model dynamics with optimal transport flows for generative modeling. "A newer wave pivots to transformer backbones and flow-matching objectives:"
- Latent diffusion: A technique performing diffusion in a compressed latent space to make large-scale training practical. "Latent diffusion~\cite{rombach2022high} made large-scale training practical,"
- Prompt adherence: The degree to which generated images faithfully follow the provided text instructions. "achieving state-of-the-art prompt adherence even for captions exceeding 1,000 words."
- TaBR (Text-as-a-Bottleneck Reconstruction): An evaluation protocol that measures expressive power via captionâgenerationâreconstruction. "We also introduce the Text-as-a-Bottleneck Reconstruction (TaBR) evaluation protocol."
- UNet-based scaling: Scaling strategies for diffusion models that use UNet architectures to improve performance. "SDXL~\cite{podell2023sdxl} pushed UNet-based scaling."
- VisionâLLM (VLM): A multimodal model that processes both images and text for tasks like structured captioning and refinement. "we employ a visionâLLM (VLM) to bridge natural human intent and structured prompts"
Collections
Sign up for free to add this paper to one or more collections.