- The paper presents a novel hybrid algorithm (APP) that integrates structured pruning and path patching for efficient neural circuit discovery.
- It leverages causal mediation and activation-based heuristics to prune task-irrelevant attention heads, substantially reducing computational cost.
- Empirical results on GPT-2 demonstrate up to 14x GFLOP reductions while retaining high fidelity in causal circuit recovery across key tasks.
Accelerated Path Patching with Task-Specific Pruning: Methodology and Implications
Introduction
Mechanistic interpretability aims to dissect the internal computation of Transformer-based LLMs by identifying minimal circuits—compact subgraphs comprising key components such as attention heads—responsible for model behavior on specific tasks. Existing circuit discovery techniques, notably Path Patching, exhaustively probe the impact of model components via activation interventions but suffer from prohibitive computational cost as model scale increases. This paper introduces Accelerated Path Patching (APP), an efficient hybrid algorithm that combines structured pruning (via FLAP and Contrastive-FLAP) with traditional Path Patching to drastically reduce search space while preserving analysis fidelity. The approach leverages causal mediation and activation-based heuristics to prune task-irrelevant heads, yielding substantial computational savings without compromising on circuit quality.
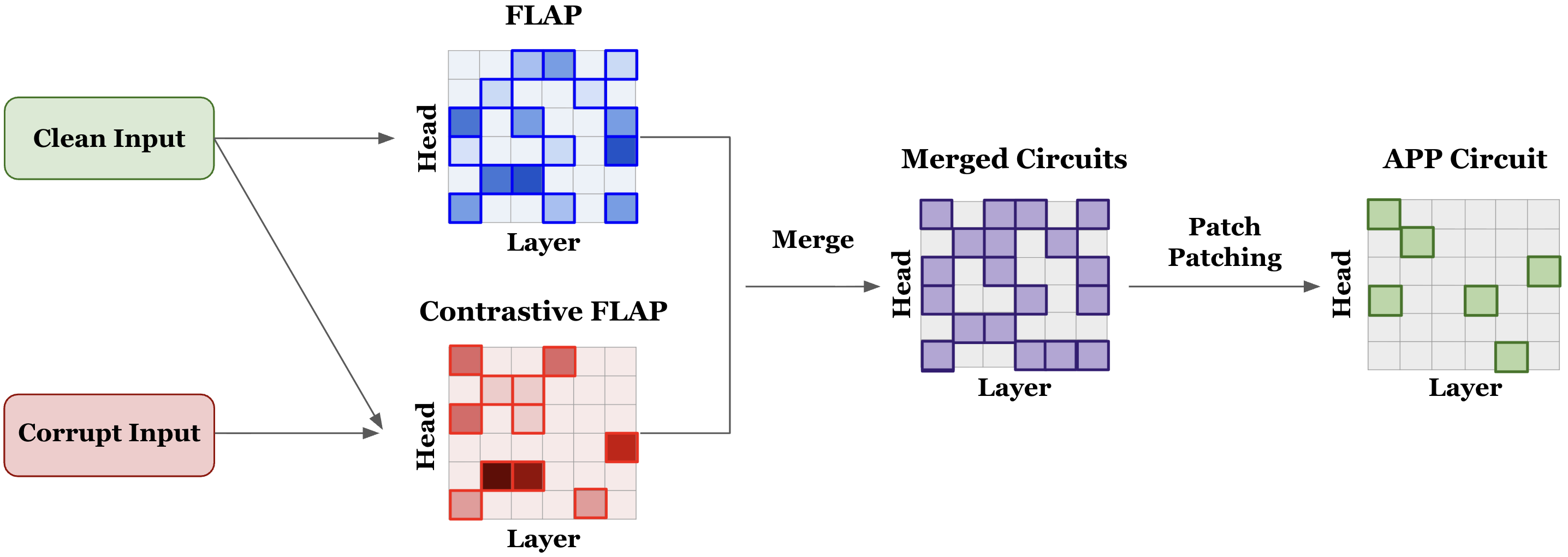
Figure 1: The Accelerated Path Patching (APP) algorithm leverages pruning to shrink the search space before applying Path Patching, increasing circuit discovery efficiency.
Background: Circuit Discovery and Head-Level Pruning
Transformer circuits are defined as subnetworks of attention heads and MLPs that can reproduce the full model’s performance on well-characterized tasks such as Indirect Object Identification (IOI), mathematical inference (Greater Than), and coreference resolution. Path Patching [wang2022interpretabilitywildcircuitindirect] isolates circuit components by contrasting activation flows between clean and corrupted input pairs, but it requires multiple passes and scales poorly with model size.
Pruning algorithms, such as FLAP [FLAP2024], compute attention head importance based on activation statistics and weight magnitudes, enabling efficient removal of non-contributing components in a retraining-free and hardware-friendly manner. However, the analysis in this work shows that head-level pruning fails to recover strictly minimal circuits due to the omission of functional dependencies and context sensitivity.
Contrastive FLAP further incorporates causal mediation analysis by quantifying head importance using the activation difference between clean and corrupted inputs, isolating heads with context-sensitive behavior.
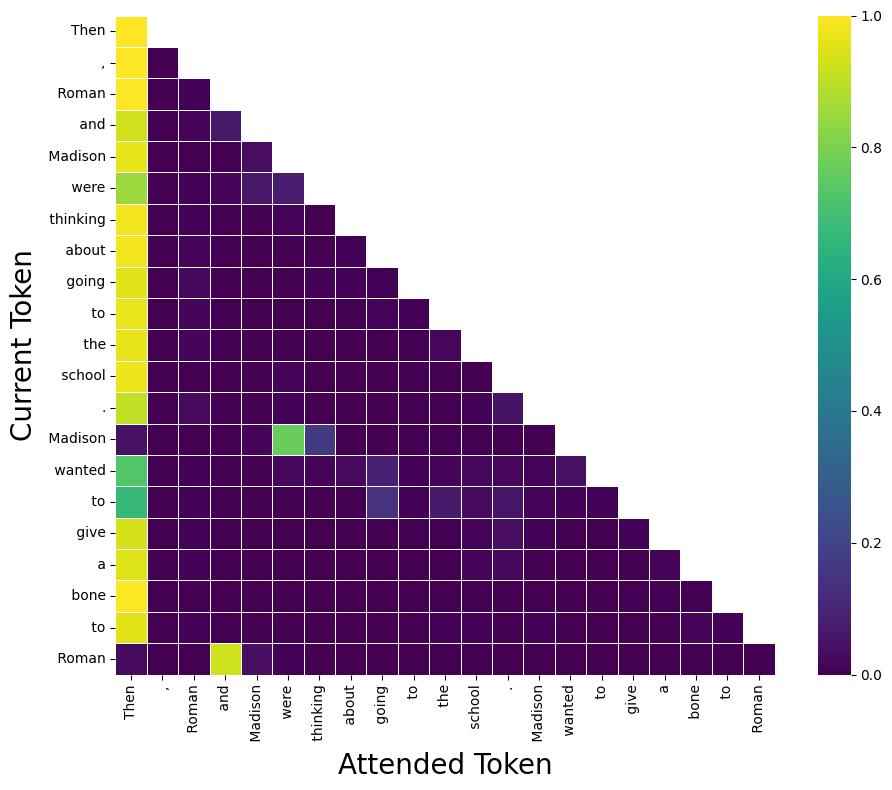
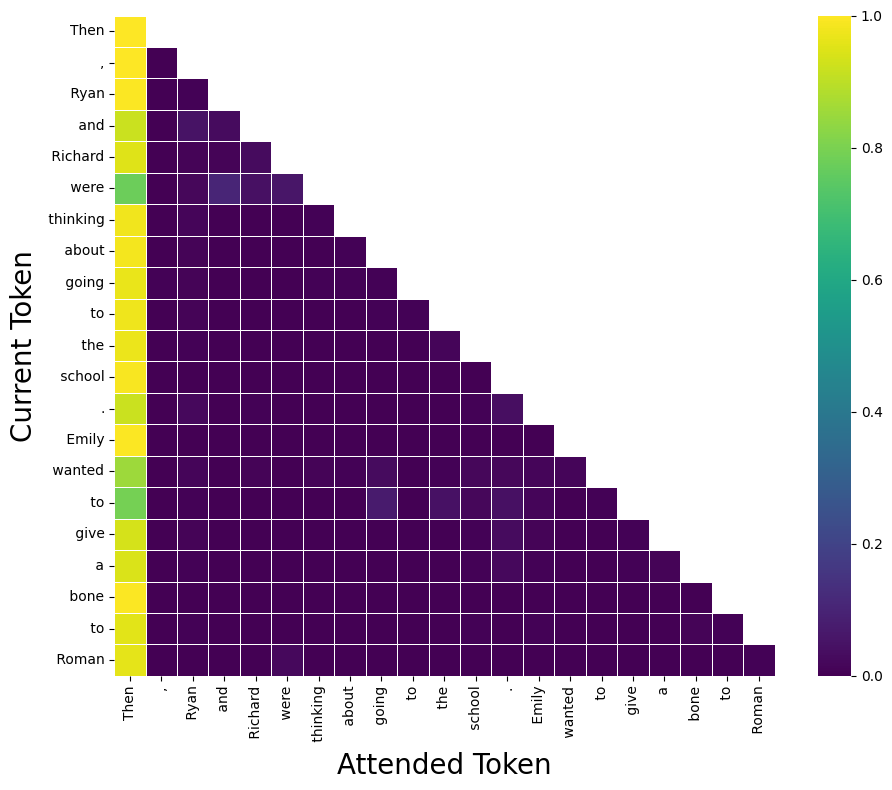
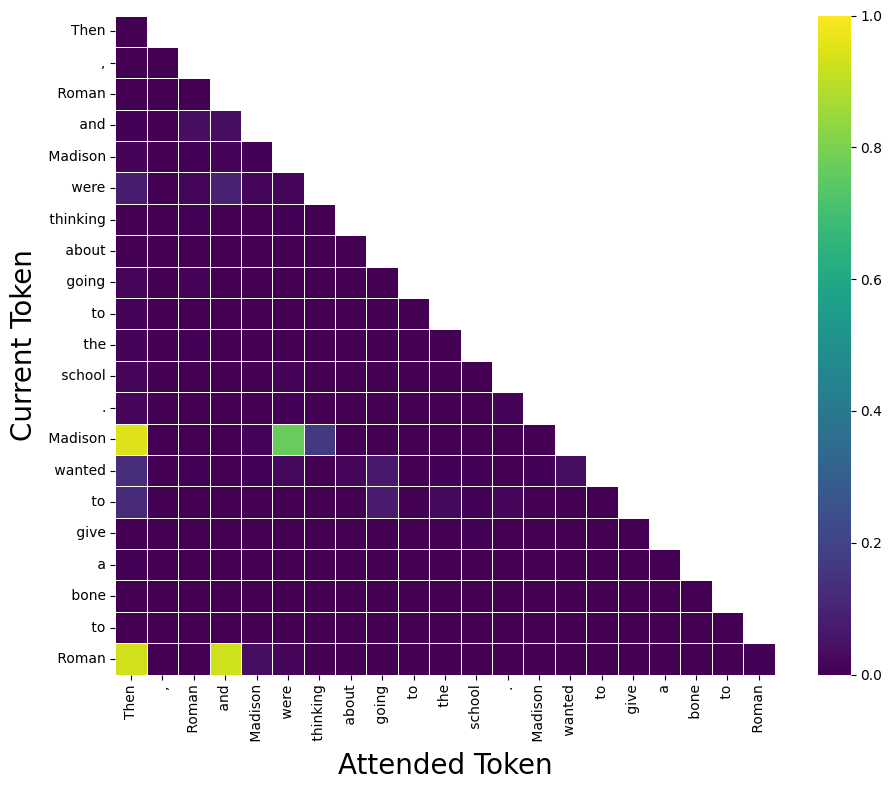
Figure 2: Example of a context-insensitive "Previous Token Head" showing stable activation patterns across clean input.
Detailed Algorithmic Framework
APP operates in four stages:
- Vanilla FLAP computes head importance scores over clean activations and selects critical heads via cliff-point thresholding.
- Contrastive FLAP computes head importance from the difference in clean vs. corrupted activations, preserving context-sensitive, task-critical heads.
- Circuit Merging takes the union of heads identified by both methods, forming a reduced search space for subsequent analysis.
- Automated Path Patching is applied to this merged set to discover causal circuits.
The contrastive scoring for head i is formalized as:
S~i=∣Wi∣⋅∥Xclean−Xcorr∥2
where Wi denotes the head's weight matrix, and Xclean,Xcorr are the respective batch activations.
Cliff points, specified as abrupt drops in reconstruction performance against sparsity, are used to select aggressive yet safe pruning levels that avoid catastrophic removal of task-essential heads.
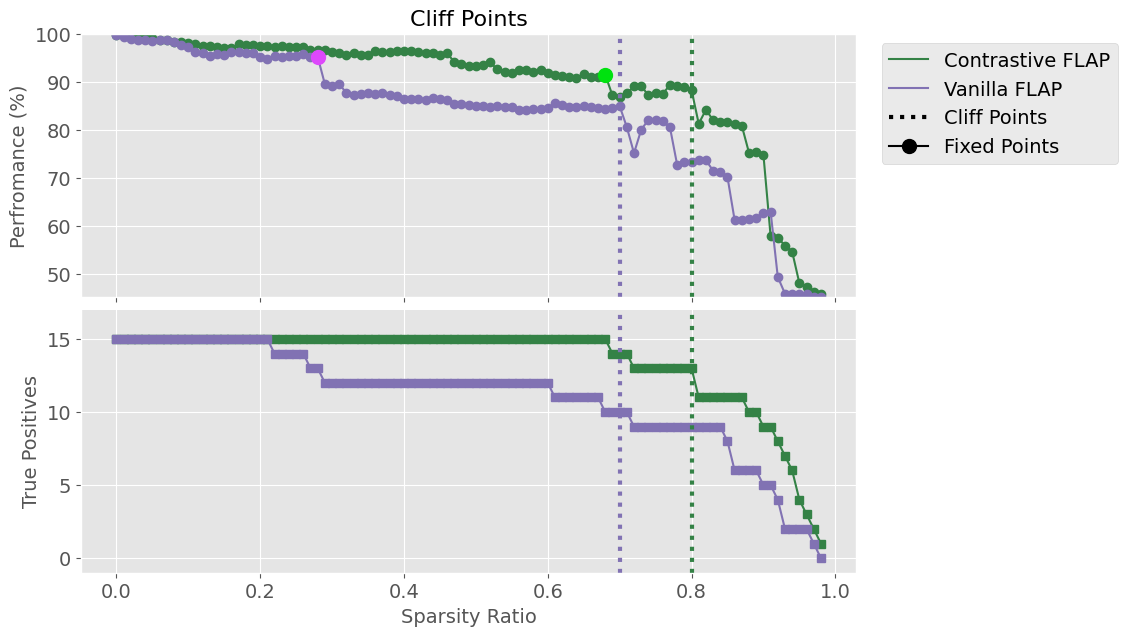
Figure 3: Performance and true positive rate (TPR) for vanilla and contrastive FLAP, showing cliff points in TPR as sparsity increases.
On GPT-2 small, APP achieves a search space reduction of ∼56%, yielding a 4x–14x reduction in GFLOPs over naive Path Patching for larger models. Precision and recall metrics demonstrate that merged pruning circuits recover most ground-truth Path Patching heads, with Contrastive-FLAP circuits presenting higher sparsity and substantially better retention of context-sensitive heads.
Despite these gains, both vanilla and contrastive FLAP produce circuits larger than those discovered by direct Path Patching, failing the strict minimality constraint. Table-based analyses show that pruning achieves comparable—but not equivalent—task performance and head overlap. Circuit inclusion based on activation-based importance does not fully account for composite and interaction effects discovered via direct causal interventions.
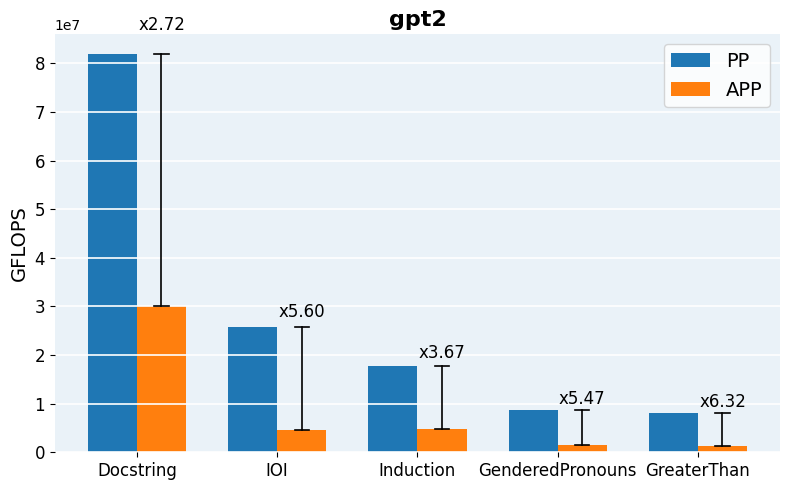
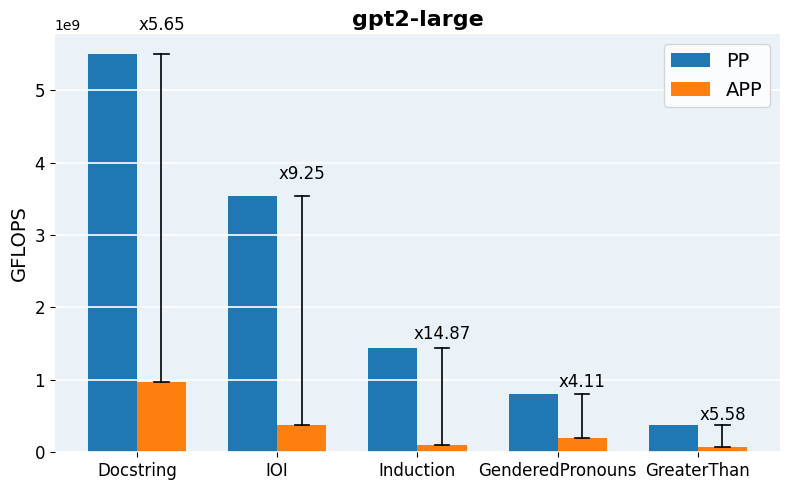
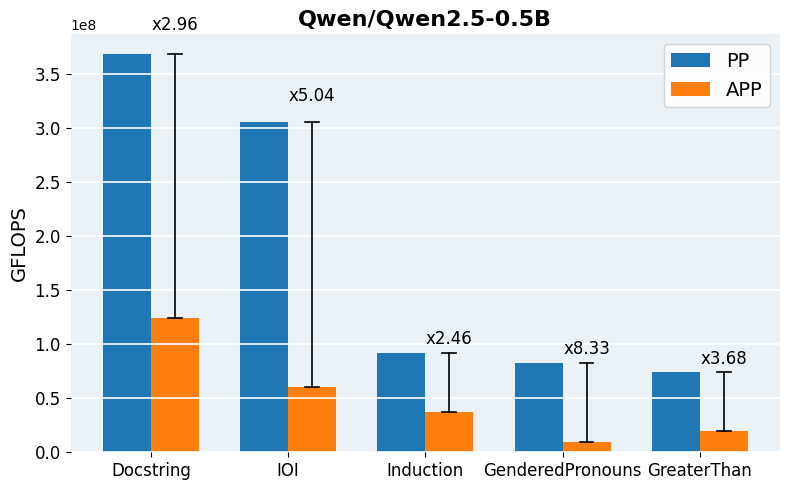
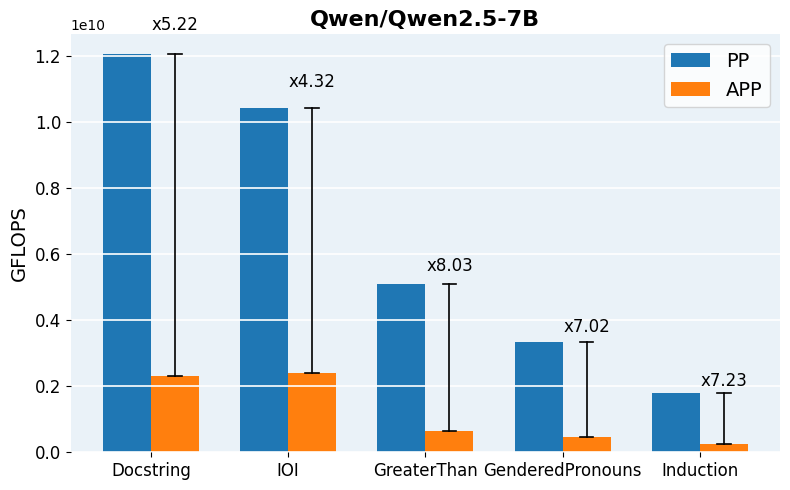
Figure 4: Required GFLOPs for APP vs. vanilla Path Patching across architectures and tasks, demonstrating robust acceleration in computation.
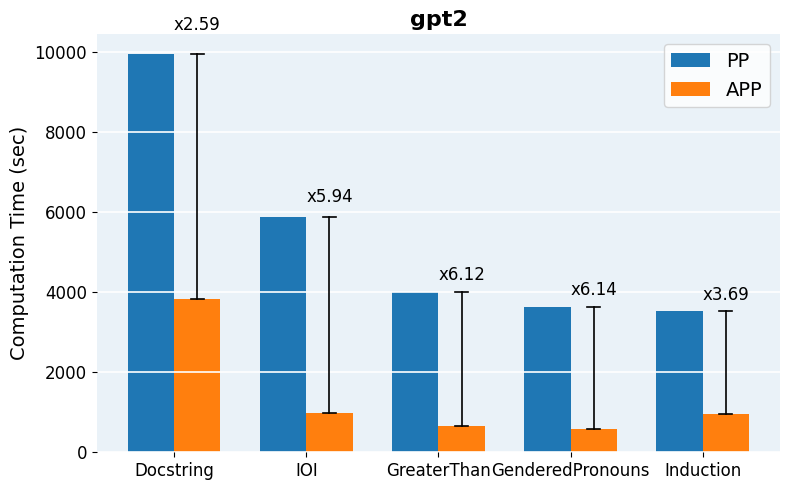
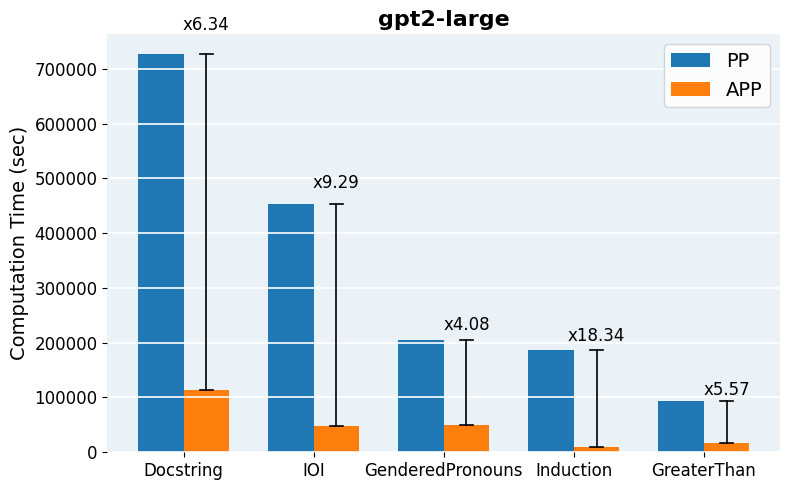
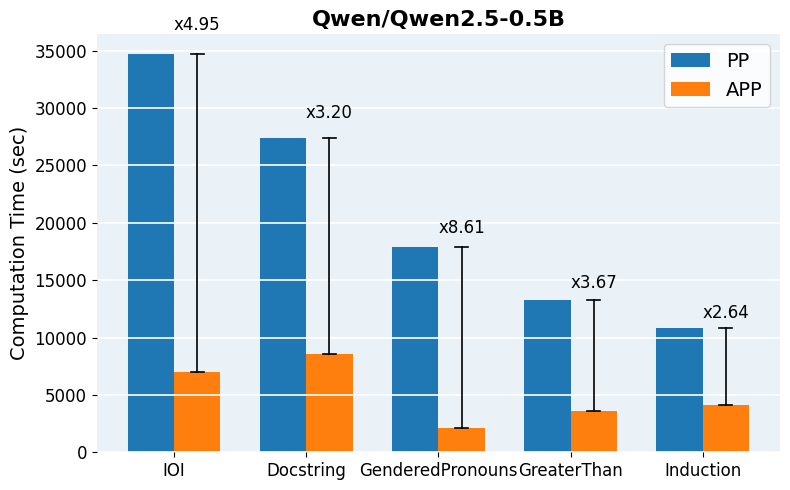
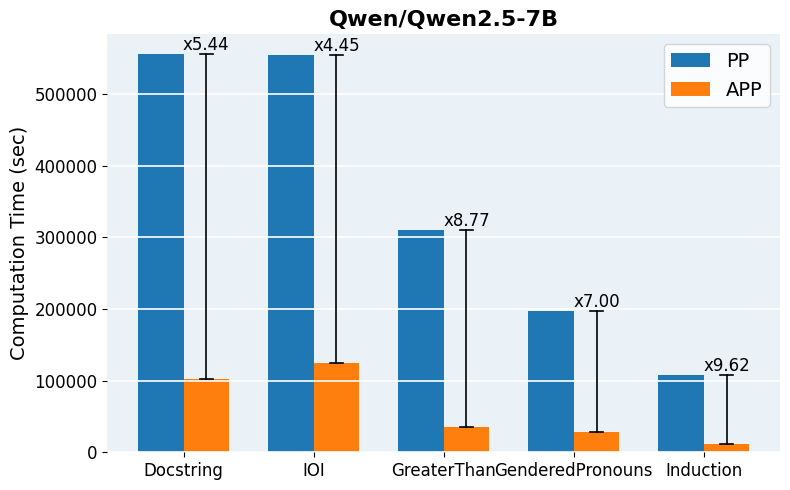
Figure 5: Computation time comparison across models and tasks, quantifying practical runtime savings delivered by APP.
Tagging heads via contrastive activation scoring mitigates the tendency of vanilla FLAP to prune context-sensitive, task-critical heads (such as induction heads required by IOI and coreference tasks). For example, on Gendered Pronouns, contrastive FLAP preserves 100% of Path Patching heads but in a less compact circuit.
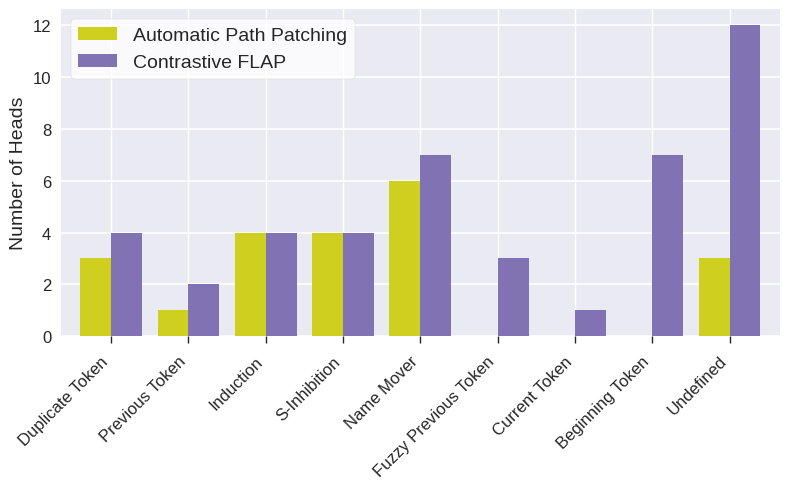
Figure 6: Comparison of attention head types identified by Contrastive FLAP and Automatic Path Patching for the IOI task.
Practical Implementation and Scaling Considerations
APP is readily implemented using head-wise activation logging for both clean and corrupted input batches, followed by parallelized scoring and iterative thresholding. The final patched evaluation can leverage standard libraries for efficient batch-propagation and intervention. For scaling to mid-sized and large models (Qwen2.5-0.5B, GPT-2 Large, Qwen2.5-7B), pruning reduces per-task runtime from hours to minutes and enables tractable hyperparameter search over inclusion thresholds.
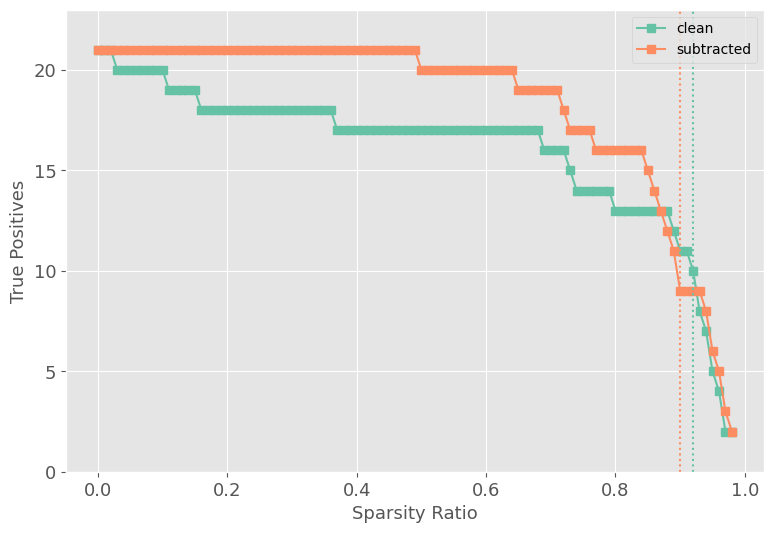
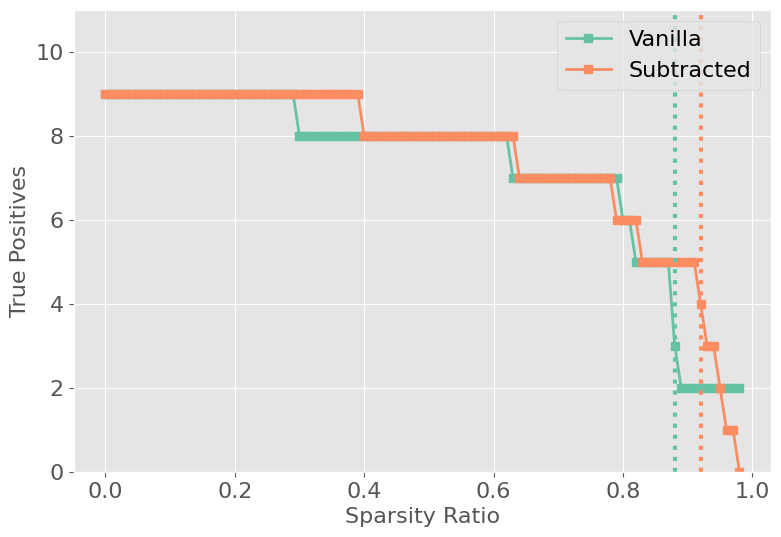
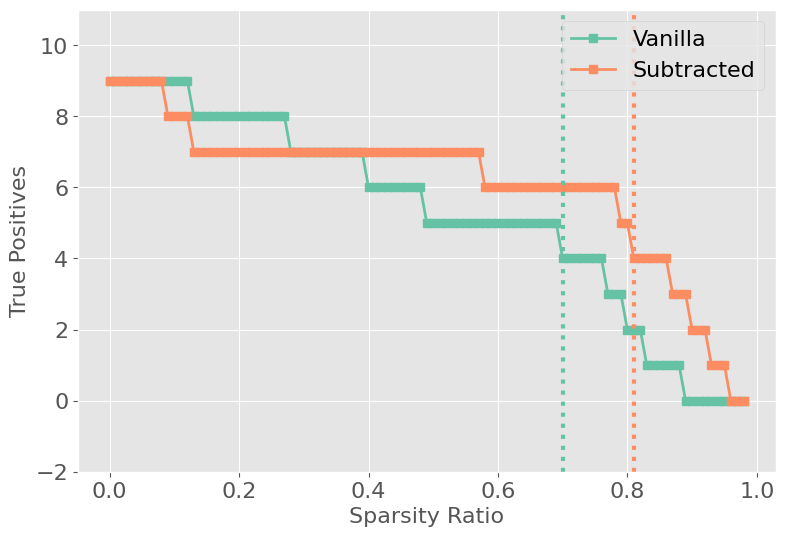
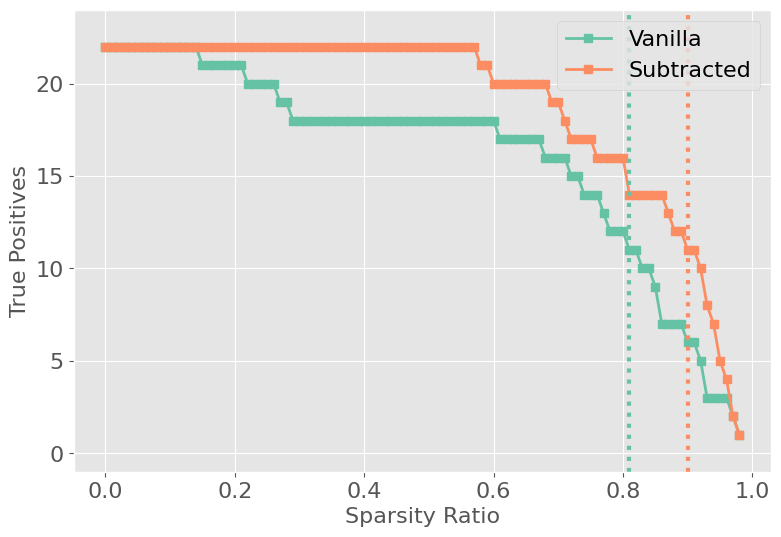
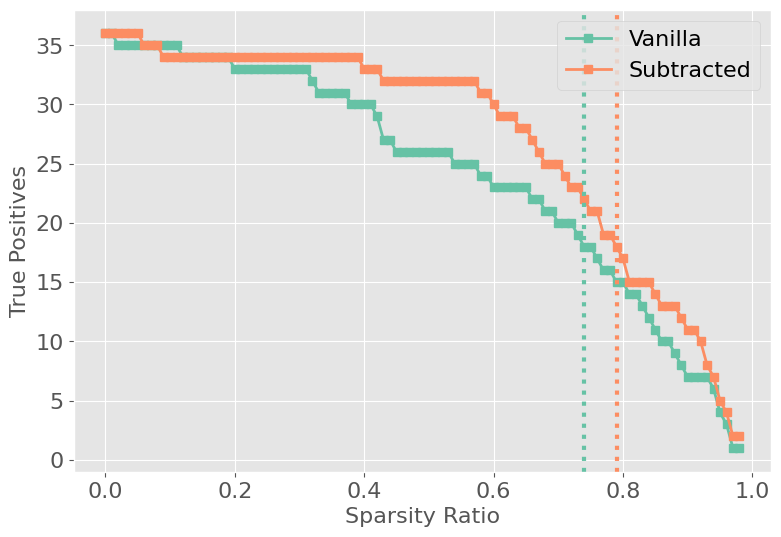
Figure 7: IOI Task example circuit and activation analysis.
Hyperparameters for both Patch Patching and APP (importance and maximum value thresholds) are tuned via Pareto-front analysis to balance circuit size and reconstruction accuracy per-task.
Theoretical and Practical Implications
APP establishes that task-aware structured pruning functions as an effective preprocessing step for mechanistic circuit discovery, rather than a direct substitute. By shrinking the hypothesis space, researchers can deploy causal analysis pipelines to more ambitious architectures and tasks previously barred by computational cost. Nevertheless, full circuit minimality and causal mechanism isolation remain contingent on direct functional interventions, highlighting that statistical importance is not strictly equivalent to causal necessity.
These findings suggest that scalable mechanistic interpretability depends on hybrid approaches integrating structured pruning with causal analysis. Pruning strategies emphasizing context-sensitive activation differences are crucial for task-specific subnetwork recovery but should be complemented by downstream causal testing.
Future Directions
Future work may extend APP by integrating layer- and edge-level pruning [EdgePruning2024], adapting circuit analysis to MLPs, and combining with automated decomposition methods such as ACDC [acdc2023]. Investigation into the transferability of discovered circuits across model scales and architectures remains an open challenge. Additionally, further exploration of hyperparameter landscapes and multi-objective optimization (minimality vs. performance) may yield more compact and faithful circuit representations.
Conclusion
Accelerated Path Patching (APP) is an efficient and generalizable approach that leverages task-specific pruning as preprocessing for causal circuit discovery. APP enables practical scaling of mechanistic interpretability pipelines while preserving near-equivalent circuit fidelity. However, pruning alone remains insufficient for minimal causal analysis, reinforcing the continued relevance of activation-based causal interventions in the mechanistic study of neural LLMs.

