Real-to-Sim Robot Policy Evaluation with Gaussian Splatting Simulation of Soft-Body Interactions
Abstract: Robotic manipulation policies are advancing rapidly, but their direct evaluation in the real world remains costly, time-consuming, and difficult to reproduce, particularly for tasks involving deformable objects. Simulation provides a scalable and systematic alternative, yet existing simulators often fail to capture the coupled visual and physical complexity of soft-body interactions. We present a real-to-sim policy evaluation framework that constructs soft-body digital twins from real-world videos and renders robots, objects, and environments with photorealistic fidelity using 3D Gaussian Splatting. We validate our approach on representative deformable manipulation tasks, including plush toy packing, rope routing, and T-block pushing, demonstrating that simulated rollouts correlate strongly with real-world execution performance and reveal key behavioral patterns of learned policies. Our results suggest that combining physics-informed reconstruction with high-quality rendering enables reproducible, scalable, and accurate evaluation of robotic manipulation policies. Website: https://real2sim-eval.github.io/





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about a faster, cheaper, and more reliable way to test how well robot control programs (called “policies”) work, especially when the robot handles squishy or bendy things like plush toys and ropes. Instead of doing lots of real-world trials—which are slow and hard to repeat exactly—they build a super-realistic simulation that looks and behaves like the real world. Then they check if a policy that succeeds in the simulator also succeeds in real life.
What questions did the researchers ask?
- Can a realistic simulator predict how well a robot policy will do in the real world?
- What makes a simulator trustworthy for evaluation: how things look (appearance) or how things move and interact (dynamics)—or both?
- If we improve the simulator’s visuals and physics, does it better match real-world results?
- Can this approach help teams choose good policy versions without running tons of real robot tests?
How did they do it?
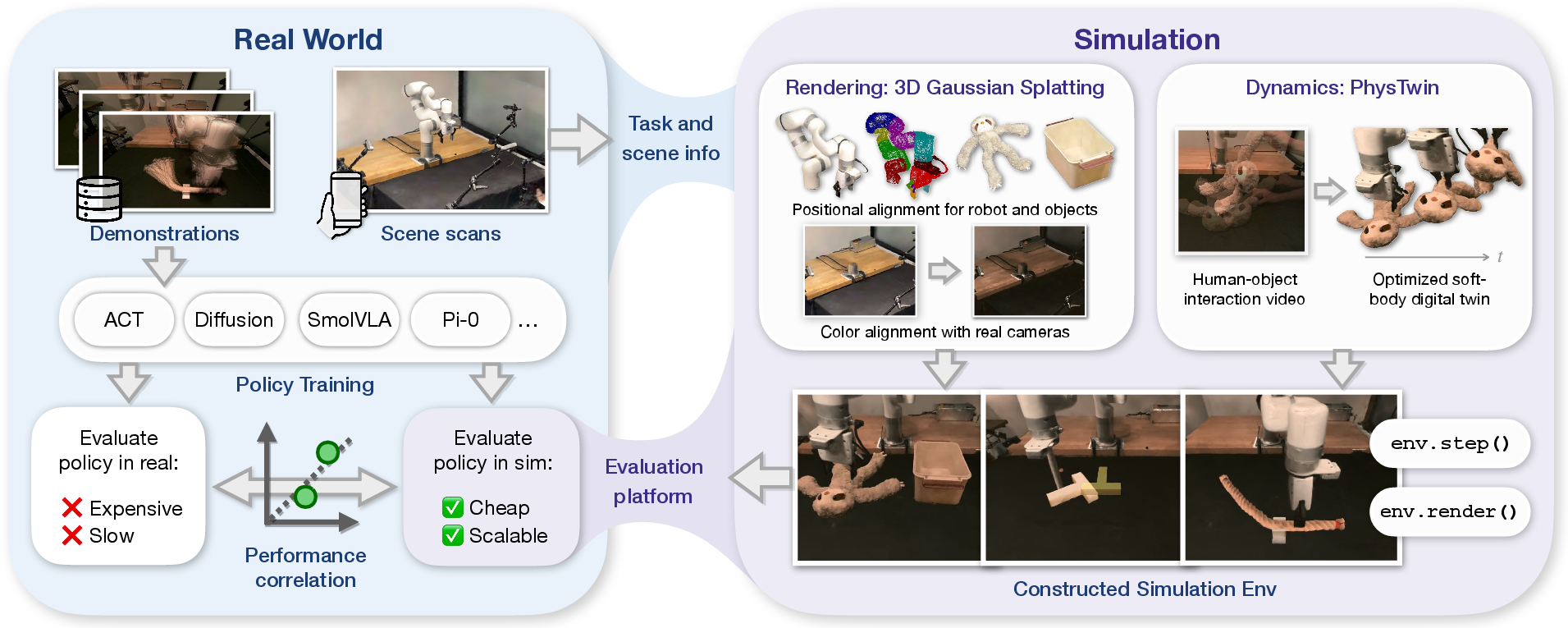
The team combined two key ideas—making the simulated world look real and making objects move like real objects—into one system the policies can be tested in.
Making the simulated world look real (Gaussian Splatting)
Think of “Gaussian Splatting” as painting the 3D world with thousands of tiny glowing dots that capture color and shape from phone videos. This lets you render lifelike scenes from any camera angle, including the robot’s wrist camera.
They:
- Scanned the robot’s workspace and objects with a phone app to build 3D “dot” models.
- Split the scan into parts: robot, objects, and background.
- Lined up these parts precisely with the robot’s known geometry so motions match up.
- Fixed color differences so the simulated images look like the robot’s real camera images. This is like applying a smart color filter so the simulator’s colors don’t confuse the policy.
Making objects move like in real life (PhysTwin)
“PhysTwin” makes a “digital twin” of an object—a virtual copy that moves like the real thing—by watching video of a human interacting with it. It treats the object as lots of tiny masses connected by springs, like a mesh of rubber bands. By tuning the spring stiffness and friction so the simulated motion matches the video, the digital twin behaves realistically when the robot pushes, grasps, or drops it.
Key points:
- Deformable objects (plush toys, ropes) are tricky because they have many ways they can bend and wobble.
- PhysTwin automatically learns how bendy or stiff the object is from real videos.
- The simulator uses realistic contacts: instead of “gluing” the object to the gripper, it uses friction so grasps look natural.
Putting it all together and testing policies
They built a complete simulator that:
- Renders photorealistic scenes with Gaussian Splatting.
- Simulates object dynamics with the PhysTwin physics engine.
- Updates the “dots” as the robot or objects move or deform, so the images the policy sees look consistent across time.
- Provides a standard “Gym-style” interface, so common robot learning policies plug in easily.
They trained several popular policies only on real-world data (no simulation training) and then evaluated them both in the simulator and in the real world. They used fixed starting positions to make fair comparisons and measured the success rate (how often the task was completed).
They tested three tasks:
- Plush toy packing: pick up a sloth plush and fit it into a small box without anything sticking out.
- Rope routing: thread a cotton rope through a clip.
- T-block pushing: push a T-shaped block to a target position and orientation.
What did they find?
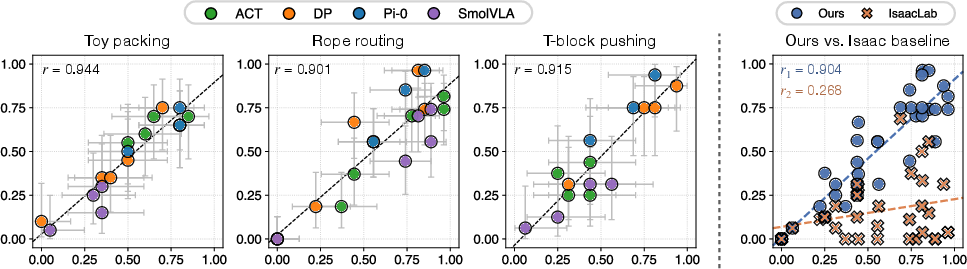
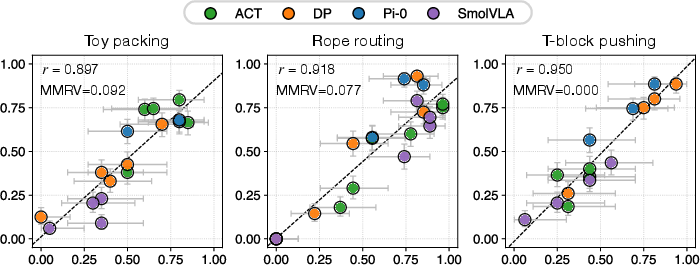
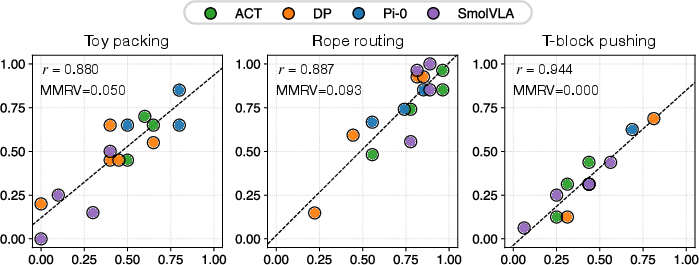
- Strong correlation between simulation and real-world performance. In simple terms: when a policy did well in the simulator, it also did well in real life. Quantitatively, the correlation coefficient was high ( across tasks and policies).
- Better than a standard baseline. Compared to a common simulator (IsaacLab), theirs matched real-world outcomes much more closely, especially for deformable tasks like rope routing (baseline correlation was low, e.g., for rope vs. about $0.9$ for their simulator).
- Both looks and physics matter. Removing color alignment (so images don’t match the real camera’s color space) or removing physics optimization (so objects move unrealistically) reduced correlation. This shows that realistic visuals and realistic motion are both crucial.
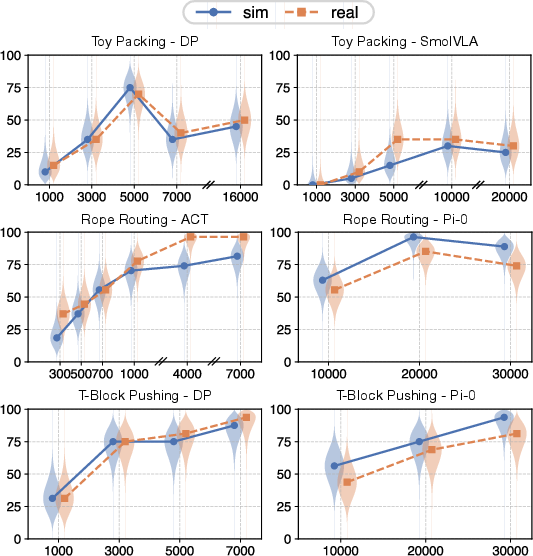
- Useful for tracking learning. As policies trained over time, improvements in the simulator matched improvements in the real world. This means teams can use the simulator to choose the best checkpoints to try on the real robot.
- Faster and more reproducible. Simulation runs faster than setting up and resetting the real robot each time, and you can re-run the exact same initial conditions reliably.
Why does this matter?
- Saves time and money: Real robot testing is slow and costly. A trustworthy simulator lets teams try more ideas quickly.
- More reliable evaluations: Strong sim-to-real correlation means you can trust the simulator for performance comparisons and benchmarking.
- Helps scale robotics research: As the field moves toward large “foundation” models for robots, we need fast, repeatable evaluations across many tasks. This approach supports that.
- Encourages better simulator design: The study shows that closing both the visual gap (how things look) and the dynamics gap (how things move) is key to reliable policy evaluation.
- Future impact: With more tasks and objects, this method could become a standard way to evaluate robot policies, especially for handling soft or deformable items that traditional simulators struggle with.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what the paper leaves unresolved and where further work is needed to strengthen, generalize, and systematize the proposed real-to-sim evaluation framework.
- Limited task diversity: only three tabletop tasks (one rigid, two deformable); evaluate on more diverse soft-body scenarios (cloth, bags, foam, cables with connectors, elastic bands), contact-rich assembly, and non-tabletop/mobile manipulation.
- Single robot embodiment: results are on a UFactory xArm 7; test across different arms, grippers (suction, soft hands), compliance levels, and robot controllers to assess generality.
- Sensor homogeneity: policies use two Intel RealSense RGB cameras; quantify correlation under different sensors (RGB-only, depth-only, fisheye, event cameras), varying intrinsics/extrinsics, and auto-exposure/white-balance changes.
- Binary success metric only: incorporate continuous metrics (pose error, contact time, path length, energy, safety violations, grasp stability) to detect subtle sim-real deviations beyond binary outcomes.
- Statistical power and episode count: provide a principled analysis of how many episodes per checkpoint are needed to bound correlation estimation error; include power analysis and confidence intervals for Pearson/Spearman at task level.
- Correlation robustness to unseen states: current evaluation grids are “comparable to training distribution”; quantify sim-real correlation on out-of-distribution initial states and harder corner cases.
- Residual visual gap quantification: beyond qualitative ablations, measure pixel/feature-domain discrepancies (e.g., FID, CLIPScore, feature distance from policy encoders) and their contribution to performance variance.
- Color alignment generalization: the polynomial RGB transform is fit with paired images from the specific cameras; assess robustness across lighting changes, time-of-day variations, camera replacements, and dynamic auto-exposure.
- Wrist-camera alignment: clarify whether color alignment is learned for wrist views (dynamic viewpoints) and test whether transform learned from fixed cameras transfers to wrist-mounted cameras.
- View-dependent effects in 3DGS: evaluate how specularities, metallic surfaces, motion blur, and view-dependent appearance (non-Lambertian) impact policy performance and whether neural reflectance models help.
- GS dynamic rendering limits: LBS on splats may not preserve volume/topology in large deformations; quantify visual artifacts (ghosting, tearing) and their effect on policies; compare to mesh-based or neural volumetric deformations.
- Physics parameter identifiability: the PhysTwin spring-mass parameters are estimated from human-interaction videos; analyze identifiability and sensitivity to multi-view calibration, occlusion, and depth noise; report parameter uncertainty.
- Friction/contact calibration: friction coefficients and contact models (including gripper force-threshold stopping) are not fully identified from data; add data-driven system ID for friction, damping, restitution, stick-slip transitions.
- Robot dynamics modeling: control latency, motor saturation, compliance, and servo tracking errors are simplified; quantify their impact and incorporate identified robot dynamics to improve correlation for faster motions.
- Self-contact and rope dynamics: provide quantitative validation (trajectory error, contact timing) of rope self-collision handling and stiffness/damping accuracy against real-world rope motion, not just task success.
- Plush-toy deformation fidelity: evaluate volumetric shape preservation, limb articulation constraints, and contact stress realism; compare to ground-truth motion capture or tactile measurements.
- Positional alignment automation: parts of GS–URDF alignment are manual (coarse alignment, bounding box segmentation); reduce human-in-the-loop steps and quantify time/cost and alignment error’s effect on downstream correlation.
- Scaling pipeline cost: report end-to-end time for scanning, segmentation, alignment, PhysTwin training, and environment setup; study trade-offs between pipeline effort and correlation gains.
- Rendering–dynamics coupling: study how mismatches between photorealistic rendering and imperfect physics (and vice versa) affect learned policy behavior; isolate causal pathways (perception vs. dynamics).
- Alternative color alignment methods: benchmark histogram matching, learned color-space mappings (e.g., MLPs), and domain-adversarial feature alignment against polynomial transforms.
- Depth and multimodal inputs: policies were evaluated with RGB; assess whether using simulated depth (from GS or fused geometry) improves correlation or exposes new gaps (e.g., depth noise realism).
- IsaacLab baseline fairness: the plush toy was excluded due to instability; compare against other strong baselines (Splatsim, Real-is-sim, GaussGym, Habitat-based renderers) under matched rendering/physics assumptions.
- Generalization across learning paradigms: results focus on imitation learning; evaluate RL, model-based control, classical visual servoing, and multimodal VLA methods to test framework breadth.
- Policy selection efficacy: quantify whether simulation-based checkpoint selection improves real-world performance versus naive selection, including selection error rates and expected gains.
- Spearman rank and significance: complement Pearson r and MMRV with Spearman rank correlations and hypothesis testing (p-values, bootstrapping) to ensure robustness to nonlinearity and outliers.
- Initial-state reproduction accuracy: the real-world replication of simulated initial states uses overlay tools; measure placement error and its contribution to evaluation variance.
- Dynamic environments: GS scenes are static; evaluate robustness under moving backgrounds, changing illumination, and human presence; explore dynamic scene reconstruction or relighting.
- High-speed motions and motion blur: GS renderings may not capture motion blur; test performance for faster robot actions and consider motion-blur-aware rendering.
- Real-time constraints: 5–30 FPS may not meet control-loop requirements; profile end-to-end latency with policies in the loop and assess impact on closed-loop behavior.
- Occlusion handling: quantify how well GS+robot rendering handles severe occlusions (e.g., object hidden by end-effector) and whether occlusion artifacts bias policies.
- Topology changes: soft-object topology changes (e.g., rope knots, cloth folding layers) are challenging; assess simulator’s capacity to handle topology changes without visual/physical artifacts.
- Safety and failure characterization: beyond success rates, measure collision forces, near-miss events, and unsafe behaviors in sim vs. real to validate safety fidelity.
- Domain adaptation potential: the framework is used for evaluation only; investigate whether small sim-driven adaptations (e.g., visual finetuning with GS renders) improve real performance without overfitting to sim artifacts.
- Transfer across workspaces: test in different labs with varied tables, backgrounds, and clutter; measure how color alignment and GS reconstruction scale to non-curated scenes.
- Open-source reproducibility: the paper commits to releasing the implementation; specify release scope (assets, scripts, datasets), required hardware/software, and reproducibility checklists to enable independent validation.
- Policy sensitivity analysis: characterize which visual features or physical parameters most influence policy decisions by perturbation experiments in sim; use this to prioritize simulator fidelity improvements.
Practical Applications
Practical Applications Derived from the Paper
The paper presents a real-to-sim evaluation framework that combines 3D Gaussian Splatting (3DGS) for photorealistic rendering with physics-informed soft-body digital twins (PhysTwin) reconstructed from videos. It demonstrates strong sim-to-real correlation (Pearson r > 0.9) across several visuomotor policies and deformable/rigid tasks. Below are actionable applications grouped by deployment timeframe, mapped to sectors, and annotated with potential tools/workflows and key assumptions.
Immediate Applications
These applications can be deployed now with the described pipeline and tooling.
- Robotics R&D CI/CD for policy pre-screening and checkpoint selection (software, robotics)
- Use the simulator’s Gym-style API to automatically evaluate policy checkpoints (ACT, DP, SmolVLA, Pi-0) against fixed initial-condition grids before on-robot testing.
- Integrate a “Policy Correlation Dashboard” tracking Pearson r/MMRV over time to gate deployments.
- Assumptions/dependencies: Access to URDFs, GPU (5–30 FPS), camera calibration/pose alignment, policies trained on real data, initial-state reproduction.
- Cost-effective A/B testing of perception-driven manipulation strategies (robotics, manufacturing, logistics)
- Evaluate the effect of visual encoders, action parameterizations, and control strategies on soft-body tasks (packing, cable/rope routing, part reorientation) with reproducible initial states.
- Tools/workflows: “SimEval Suite” to batch trials; “Color-Domain Calibrator” to match 3DGS colors to RealSense-like camera domains via quadratic IRLS.
- Assumptions: Quality of GS scans (e.g., Scaniverse) and segmentation (SuperSplat), stable friction/contact modeling.
- Soft-body digital twin creation from handheld videos for task analysis (robotics, academia)
- Build deformable object models (rope, plush, textiles) from human-object interaction videos to study task policies and contact dynamics.
- Tools: “PhysTwin Builder” to auto-tune spring-mass parameters from videos; LBS deformation handlers integrated with Warp.
- Assumptions: Multi-view RGB-D capture improves parameter estimation; single-video setups work but may limit generalization.
- Scalable, reproducible benchmarking for vision-based policies (academia, community benchmarks)
- Standardize evaluation tasks and initial configurations to reduce variance, enable cross-lab comparisons, and study robustness trends during training.
- Workflows: Publish tasks/assets via Gym-style environments; provide camera-aligned GS scenes and evaluation grids; compute CIs (Clopper–Pearson) in reports.
- Assumptions: Community adoption; shared asset repositories; consistent camera settings (exposure/white balance).
- Failure analysis and behavior profiling for contact-rich manipulation (robotics QA)
- Replay and inspect simulated rollouts to identify perception errors (color-space mismatch), dynamics mis-specification (stiffness/friction), and grasping stability (force thresholds).
- Tools: “Behavior Pattern Analyzer” to map failure modes to rendering/dynamics ablations; automated friction force limits for gripper closure.
- Assumptions: Accurate mapping from kernels to robot links; correct gripper segmentation and contact modeling.
- Rapid environment capture for new tasks with consumer devices (startups, labs)
- Use smartphone scans for quick GS reconstruction of workspaces, robots, and objects; perform position/color alignment to approximate the real camera domain.
- Tools: “GS Workspace Capture Kit” (workflow + guides for Scaniverse + SuperSplat + ICP/RANSAC alignment).
- Assumptions: Good lighting; clean segmentation; ICP/RANSAC robustly aligns GS and URDF point clouds.
- Curriculum and hands-on coursework for deformable-object robotics (education)
- Offer lab exercises that demonstrate how appearance/dynamics fidelity affect sim-to-real correlations; students reproduce tasks across imaging conditions and stiffness/friction settings.
- Tools: Pre-built tasks (rope routing, toy packing, push-T), parameterized physics ablations, color alignment exercises.
- Assumptions: Access to basic robots or simulated robot assets; open-source environment release.
- Procurement and vendor evaluation using reproducible simulation (policy, industry standards)
- Institutions can pre-evaluate third-party policy models under standardized simulated tasks prior to physical trials, reducing risk and cost.
- Workflows: Submission APIs for policy rollouts; standardized reporting of r/MMRV and CIs.
- Assumptions: Trust in evaluation assets; clear acceptance thresholds; disclosure of training domains to avoid domain shift surprises.
Long-Term Applications
These require further research, scaling, or integration with broader ecosystems.
- Certification frameworks for robot policy safety and reliability (policy, standards)
- Establish certifiable test suites where strong sim-to-real correlation is a prerequisite for approvals in contact-rich tasks (e.g., packaging, assembly with flexible components).
- Products: “Robotics Policy Certification Suite” with audited GS/PhysTwin assets, statistical correlation requirements, and stress-testing protocols.
- Dependencies: Regulatory buy-in; broader task coverage; safety cases for high-stakes domains; standardized camera/domain calibration procedures.
- Sim-first training with soft-body digital twins (robotics, software)
- Transition from evaluation-only to training-in-sim pipelines where deformable-object twins are sufficiently realistic to train policies that generalize without extensive real data.
- Tools: Hybrid data generation (3DGS + PhysTwin + domain randomization), sim-to-real adaptation modules leveraging color-space alignment and physics parameter identification.
- Dependencies: Further reduction of residual dynamics gaps (complex friction/contact, higher-speed interactions), larger benchmarks, multi-embodiment validation.
- Foundation model development pipelines augmented by high-fidelity sim evaluation (software, robotics)
- Use simulation as a scalable feedback loop to triage and refine large visuomotor models (e.g., Pi-0-like systems), selecting promising checkpoints for scarce on-robot trials.
- Products: “FM Policy Triage Service” with cloud batch evaluation, multi-GPU scaling, automated correlation metrics, and deployment gating.
- Dependencies: Support for diverse robot platforms and sensors; robust color/dynamics alignment across many camera types and materials.
- Industrial process engineering for handling deformables (manufacturing, textiles, electronics harness assembly)
- Virtually prototype grippers and motion strategies for tasks involving cables, cloth, foam, and soft packaging; predict throughput, success rates, and ergonomic constraints.
- Tools: “Soft-Handling Design Studio” with parametric gripper models, rope/wire harness libraries, and physics-calibrated digital twins from factory videos.
- Dependencies: Accurate parameter identification for varied materials; multi-contact, multi-speed regimes; integration with CAD/PLM workflows.
- Healthcare and surgical robotics simulation with improved soft-tissue modeling (healthcare, medical devices)
- Extend digital twins to biological tissues for training/evaluating perception-driven maneuvering and manipulation under controlled scenarios.
- Tools: Domain-specific tissue parameter libraries, validated contact/friction models, augmented sensing (depth/force).
- Dependencies: Biomechanical fidelity, safety and compliance, high-resolution sensing alignment; rigorous clinical validation.
- Fleet-scale remote evaluation and policy marketplaces (robotics platforms, cloud services)
- Cloud services where manufacturers/operators upload policy artifacts to be benchmarked across standardized GS/PhysTwin task suites; results drive procurement and deployment decisions.
- Products: “Policy Marketplace & Benchmark Cloud” with reproducible assets, correlation scores, and task difficulty tiers.
- Dependencies: Interoperability standards (URDF/SRDF variants), IP/data governance, cross-device calibration, fair-use policies.
- Consumer-level home robot customization via scanning (daily life, consumer robotics)
- Let users scan household environments/objects to generate digital twins, enabling robots to evaluate task feasibility (e.g., packing/tidying, cable management) before acting.
- Tools: Mobile apps that guide GS capture, perform color alignment to the robot’s camera domain, and propose policy settings with predicted success likelihood.
- Dependencies: Reliable smartphone scanning in varied lighting, user-friendly segmentation/alignment, robust domain matching to consumer robot sensors.
- Sustainability and resource optimization via simulation-driven testing (policy, ESG)
- Use sim evaluation to reduce physical trial energy usage, material waste (damaged components/consumables), and downtime in factories and labs.
- Workflows: ESG reporting modules quantify avoided trials and resource footprints; simulation-first decision gates for changes to policies or processes.
- Dependencies: Organizational adoption; credible accounting frameworks; broad acceptance of simulation as a proxy.
- Cross-robot generalization and multi-embodiment validation (robotics research)
- Extend the pipeline to varied robot arms/grippers and mobile manipulators to establish generalization bounds and task transferability.
- Tools: Embodiment abstraction layers that map GS kernels to diverse URDFs; automatic link segmentation; generalized color calibration profiles.
- Dependencies: Diverse hardware availability, robust ICP/RANSAC alignment across morphology, task-specific physics nuances (e.g., underactuated hands).
Each application’s feasibility hinges on assumptions such as accurate GS reconstruction and segmentation, robust position/color alignment to the robot’s camera domain, reliable PhysTwin parameter identification from limited video, task-specific friction/contact fidelity, and the availability of standardized assets and evaluation protocols. Continued scaling of task diversity, materials, robots, and camera types will strengthen the generality of these applications and support broader industry and policy adoption.
Glossary
- ACT: An imitation-learning architecture (Action Chunking Transformer) for visuomotor control. "ACT~\cite{zhao2023learning}"
- Ablation studies: Controlled experiments that remove or alter components to assess their impact on system performance. "and performing ablation studies"
- Beta prior: A Bayesian prior over probabilities (e.g., success rates) modeled with the Beta distribution. "under a uniform Beta prior"
- Clopper–Pearson confidence interval (CI): An exact confidence interval for a binomial proportion, used to quantify uncertainty in success rates. "ClopperâPearson confidence interval (CI)"
- Dense spring-mass system: A physics model representing deformable objects as masses connected by many springs to simulate realistic deformation. "using a dense spring-mass system"
- Diffusion Policy (DP): An imitation-learning approach that uses diffusion models to generate robot actions from observations. "Diffusion Policy (DP)~\cite{chi2023diffusionpolicy}"
- End-effector: The tool or gripper at the tip of a robot arm that interacts with objects. "end-effector state"
- Gaussian kernel: In Gaussian Splatting, an anisotropic 3D Gaussian primitive used to represent and render scene content. "Gaussian kernel colors and opacities"
- Gaussian Splatting (3DGS): A scene representation technique that renders photorealistic views by projecting 3D Gaussian primitives; enables real-time, view-consistent rendering. "3D Gaussian Splatting (3DGS)~\cite{kerbl3Dgaussians}"
- GELLO: A teleoperation system for streaming high-frequency control commands to robots during data collection. "GELLO~\cite{wu2023gello}"
- Gym environment API: A standardized interface for reinforcement learning environments used to package simulation tasks for policy evaluation. "Gym environment API~\cite{brockman2016openaigym}"
- ICP (Iterative Closest Point): A geometric registration algorithm that aligns two point clouds by iteratively minimizing distances between closest points. "Iterative Closest Point (ICP)~\cite{4767965}"
- IRLS (Iteratively Reweighted Least Squares): A robust regression method that reduces the influence of outliers by iteratively reweighting residuals. "Iteratively Reweighted Least Squares (IRLS)~\cite{green1984iteratively}"
- IsaacLab: NVIDIA’s robotics simulation environment built on PhysX, used as a baseline in this work. "NVIDIA IsaacLab~\cite{nvidia2024isaac}"
- Kinematic control points: Prescribed-motion points used to drive a simulation, often attached to an object to match observed trajectories. "as kinematic control points"
- LBS (Linear Blend Skinning): A deformation technique that blends transformations to smoothly skin meshes or primitives to underlying motion. "Linear Blend Skinning (LBS)~\cite{10.1145/1276377.1276478}"
- MMRV (Mean Maximum Rank Variation): A metric that quantifies how often the relative ranking of policies differs between simulation and real-world evaluations. "Mean Maximum Rank Variation (MMRV)"
- NVIDIA Warp: A GPU-accelerated framework used to implement custom physics simulation kernels. "NVIDIA Warp~\cite{warp2022}"
- PhysTwin: A video-based digital-twin framework that reconstructs deformable object dynamics with a spring-mass model. "PhysTwin~\cite{jiang2025phystwin}"
- PhysX: NVIDIA’s physics engine for simulating rigid and articulated bodies, used by IsaacLab. "PhysX physics engine"
- Pi-0: A vision-language-action policy from robotics foundation models evaluated in the study. "Pi-0~\cite{black2024pi0}"
- Privileged simulation states: Internal simulator states not available to the policy but used for automatic success evaluation. "privileged simulation states"
- Quaternion: A four-parameter representation of 3D rotation used in robot state/action vectors. "quaternion,"
- RANSAC: A robust estimation algorithm that fits models while rejecting outliers through random sampling. "RANSAC~\cite{10.1145/358669.358692}"
- Real-to-sim: A pipeline or framework that reconstructs and transfers real-world scenes and dynamics into simulation for evaluation. "Real-to-sim Robot Policy Evaluation"
- Scaniverse: An iPhone app that captures videos and produces Gaussian Splatting reconstructions of scenes. "Scaniverse~\cite{scaniverse}"
- Sim-to-real gap: The discrepancy between performance in simulation and the real world that hinders reliable policy evaluation. "sim-to-real gap"
- SmolVLA: A compact vision-language-action policy architecture tested in the experiments. "SmolVLA~\cite{shukor2025smolvla}"
- SuperSplat: An interactive tool for visualizing and segmenting Gaussian Splatting reconstructions. "SuperSplat~\cite{supersplat2025}"
- Tukey bi-weight: A robust weighting function used within IRLS to downweight large residuals. "Robust IRLS with Tukey bi-weight"
- URDF (Unified Robot Description Format): A robot model specification describing links and joints used for kinematic and rendering alignment. "URDF"
- Violin plots: Distribution visualizations that show the posterior of success rates, including spread and density. "with violin plots"
- Wrist-mounted cameras: Cameras attached to the robot’s wrist providing close-up, egocentric visual feedback. "wrist-mounted cameras"
Collections
Sign up for free to add this paper to one or more collections.