MIDI-LLM: Adapting Large Language Models for Text-to-MIDI Music Generation
Abstract: We present MIDI-LLM, an LLM for generating multitrack MIDI music from free-form text prompts. Our approach expands a text LLM's vocabulary to include MIDI tokens, and uses a two-stage training recipe to endow text-to-MIDI abilities. By preserving the original LLM's parameter structure, we can directly leverage the vLLM library for accelerated inference. Experiments show that MIDI-LLM achieves higher quality, better text control, and faster inference compared to the recent Text2midi model. Live demo at https://midi-LLM-demo.vercel.app.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Midi-LLM, a computer model that can create multitrack music (in MIDI format) from everyday text prompts like “happy pop song with piano and drums.” It adapts a LLM—the kind used for chatbots—so it understands both words and music, and can quickly turn a description into editable music.
Key Questions
The authors set out to answer simple, practical questions:
- Can we teach a LLM to “speak” music, not just text?
- Can it make music that matches a user’s description (genre, mood, instruments, tempo)?
- Can it be fast enough to use in real creative workflows?
- Is it better than existing text-to-MIDI systems?
How They Did It (Methods)
To make this clear, here are the main ideas explained in everyday terms.
What is MIDI?
- MIDI is like a “digital sheet music” file. It describes notes, instruments, and timing, but doesn’t contain recorded sound.
- MIDI is powerful because you can easily edit it: change notes, instruments, tempo, and more.
Turning music into tokens
- Computers like to work with tokens, which are “tiny building blocks” of information—similar to words in a sentence.
- The authors used a method where each note is turned into three tokens:
- When the note starts (its time),
- How long it lasts (its duration),
- Which instrument and pitch it is (e.g., piano, middle C).
Think of each note as a LEGO built from three bricks. This makes music easy for a LLM to “read” and “write.”
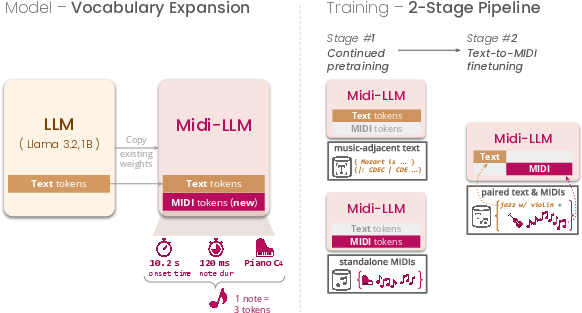
Expanding an LLM’s vocabulary
- A LLM has a vocabulary: all the “words” it knows. Midi-LLM adds new “music words” (MIDI tokens) to a regular text LLM’s vocabulary.
- It’s like teaching a fluent reader a new set of symbols so it can read and write music as naturally as it writes sentences.
Two-stage training
The model learns in two steps, similar to how you’d learn music:
- Continued pretraining (getting familiar with music)
- The model reads lots of music-related text (articles, music facts) and lots of unpaired MIDI files.
- This teaches the model music structure and timing, so it understands how notes and instruments come together.
- Supervised finetuning (learning to follow instructions)
- The model studies pairs of text descriptions and matching MIDI songs.
- It practices turning descriptions like “slow jazz, minor key, saxophone and piano” into the right notes and instruments.
- They also add “infilling” examples: the model fills in missing parts of a song using the surrounding context, with extra captions for variety.
Making it fast
- The authors kept the LLM’s original structure, which means they could use popular speed-up tools (like vLLM and quantization) without heavy engineering work.
- They used sampling tricks to balance variety and coherence (nucleus sampling with a high “top p”), and special math settings to make generation faster without hurting quality too much.
What They Found
Here are the main results, explained simply:
- Better music quality: Midi-LLM’s music sounds more realistic and matches the text prompts better than a recent system called Text2midi.
- They measured this using:
- FAD (Frechet Audio Distance): lower is better; it means the music is closer to real, high-quality music.
- CLAP: higher is better; it means the music matches the text description well.
- Much faster generation:
- Midi-LLM produced music roughly 5–10 times faster in their tests, depending on settings.
- That makes it more practical for real use, especially when generating multiple songs or working interactively.
- Works with multitrack MIDI:
- It can generate separate instrument parts, which is useful for composers and producers who want to edit or rearrange pieces.
- Negative findings (honest limitations they observed):
- When filling in missing parts of a song, the text prompt didn’t have much influence; the surrounding notes mattered more.
- Pretraining on music-specific text didn’t clearly beat pretraining on general text, which raises questions about what kind of text helps most.
Why It Matters
- Editable music: Unlike “audio-only” music generation, MIDI lets you tweak notes, instruments, and structure afterward. That’s big for creative control.
- Better human-AI collaboration: Because the output is symbolic (like sheet music), musicians can easily build on the AI’s ideas, change parts, and experiment.
- Speed and usability: Fast generation and standard LLM tooling mean it’s easier to use in real workflows and apps.
Limitations and Future Directions
- Dynamics and expression: The paper notes differences in how loudness and expression are handled compared to some other systems.
- Stronger text control during editing: They want to make text-guided editing more powerful, so prompts could reshape specific parts of a song.
- Learning from users: They plan to use feedback (from the live demo) to tune the model to user preferences and improve creative results.
- Working with musicians: Interviews and co-creation sessions could help decide what controls and features matter most in practice.
Takeaway
Midi-LLM teaches a LLM to “speak” music as easily as text. By adding MIDI tokens to its vocabulary and training it on lots of music and descriptions, it can turn everyday prompts into multitrack MIDI that’s high-quality, well-matched to the text, and fast to generate. This makes AI music creation more editable, collaborative, and practical for musicians and creators.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete points future researchers can act on.
- Expressive performance modeling is absent: the AMT tokenization used here does not encode velocity (dynamics), articulations, pedal, tempo changes, time signature changes, or controller events. How to extend the vocabulary and training to cover expressive MIDI performance and global meta-events without exploding sequence length or harming speed?
- Limited generation length and structural form: training and inference use 2048 tokens (≈30 seconds), constraining long-form composition (e.g., verse–chorus–bridge development). What hierarchical or memory-augmented strategies (segment-level generation, cached KV states, recurrence, retrieval) enable coherent multi-minute pieces?
- Weak text influence in infilling: despite training on text-paired infilling, the model ignores text at inference for infill tasks. Which conditioning mechanisms (explicit cross-attention, gating to text tokens, prefix-tuning, control tokens, contrastive losses) restore strong textual control during infilling?
- Necessity and composition of continued pretraining data are unclear: replacing MusicPile with FineWeb-Edu produced no noticeable change. Systematic ablations controlling corpus size, curation quality, music density, and multilinguality are needed to determine whether domain-adjacent text helps and under what conditions.
- No ablation on design choices: the paper lacks controlled studies quantifying contributions from (a) vocabulary expansion vs. textual serialization of MIDI events, (b) two-stage training vs. direct SFT, (c) tokenization choice (AMT vs. REMI/ABC) and instrument–pitch joint token design. Which choices most impact controllability, quality, and speed?
- Audio-based metrics may be confounded by synthesis: FAD and CLAP are computed after rendering with a single Fluidsynth soundfont, which can mask symbolic quality and arrangement accuracy. Evaluate robustness across multiple soundfonts and add symbolic metrics (key/tonality detection accuracy, chord progression compliance, instrumentation correctness, phrase/section structure, repetition/variation statistics) and human listening studies.
- Text controllability is not directly measured: CLAP is a coarse proxy. Introduce attribute-level accuracy metrics (e.g., prescribed tempo, key, chord progression, instrumentation presence/absence, genre/mood classification) to quantify how well generated MIDI matches specific textual constraints.
- Pairing quality for captions is under-specified: the finetuning pairs MidiCaps text with LMD MIDI, and additional captions are auto-generated by Qwen2.5-Omni for infilling. Assess caption–MIDI alignment quality (human verification, automatic consistency checks) and analyze sensitivity to noisy captions; explore better captioners or joint training with caption refinement.
- Impact on original language competence is unknown: expanding embeddings and training on MIDI may degrade general text tasks. Measure retention on standard LLM benchmarks (e.g., MMLU, reading comprehension) and explore techniques (modality adapters, LoRA adapters, selective freezing) that preserve general language ability.
- Token initialization strategy is simplistic: new AMT embeddings are randomly initialized. Investigate informed initialization (e.g., pretrain a small AMT-only model, map similar concepts, use semantic anchors) to speed convergence and reduce interference with the text vocabulary.
- Tempo and meter control through text are not operationalized: although prompts include tempo and tonality, the tokenization does not expose explicit tempo/meter events. Add meta-event tokens and evaluate whether the model can set and vary tempo/meter according to text.
- Multilingual and out-of-distribution prompt robustness is untested: evaluate performance on non-English prompts, mixed technical/music-theory prompts, and creative narratives; consider multilingual continued pretraining and prompt normalization strategies.
- Arrangement quality and instrument mapping are not evaluated: joint instrument–pitch tokens assume GM instruments; measure instrument assignment accuracy, timbral diversity, and track balance; test alternative instrument schemas (Program + channel + articulation) and multi-instrument blending.
- Speed and scalability profiling is narrow: inference speed is reported for 2K tokens on one GPU with nucleus sampling and vLLM. Provide comprehensive throughput/latency profiles across hardware (consumer GPUs, H100, CPU), batch sizes, sequence lengths, quantization settings, and streaming/interactive scenarios.
- Quantization impact on musicality is only lightly assessed: FP8 improves speed with modest metric changes, but nuanced musical artifacts may not be captured by FAD/CLAP. Study quantization-aware training and mixed-precision layouts specialized for symbolic music to balance speed and fidelity.
- Microtiming and groove representation may be limited by 10 ms quantization and arrival-time encoding: analyze whether swing, humanized timing, and rubato are captured; explore variable-resolution timing tokens or relative timing schemes that preserve groove with fewer tokens.
- Long-range harmonic planning and thematic development are not measured: introduce evaluations for tonal stability, modulation control, motif recurrence, and section-level coherence; consider planning modules (e.g., chord/section plans) fed as conditions or scaffolds.
- Fairness and comparability of baselines need strengthening: the baseline differs in architecture, tokenization, precision, and supports dynamics; ensure matched evaluation settings (e.g., controlled soundfonts, same prompt subsets, equal output durations) and include more symbolic baselines (REMI-based, ABC-based, MuPT, NotaGen) for comprehensive comparison.
- Data quality, duplication, and legal considerations are not addressed: LMD/GigaMIDI may contain duplicates and licensing ambiguities. Implement deduplication, contamination checks against test splits, and plagiarism/copy-detection analyses (e.g., n-gram and sequence alignment) to quantify memorization risk.
- Editing capabilities are proposed but not demonstrated: design and evaluate text-guided symbolic editing (e.g., “raise bass by a fifth,” “replace chorus with strings,” “transpose bridge to G minor”) with appropriate UI, task formulations, and metrics for edit fidelity and minimality.
- Integration with DAWs and downstream workflows remains unexplored: measure end-to-end usability (round-trip editing, re-quantization, track separation), export/import of controller data, and user latency requirements; build benchmarks tied to common production tasks.
- Safety and bias in musical style generation are unexamined: assess style imitation risks, culturally sensitive content, and potential over-representation of certain genres; develop style-coverage diagnostics and opt-out mechanisms.
- Generalization to other symbolic formats (MusicXML, LilyPond) is not studied: evaluate whether the approach transfers to richer notations with articulations and dynamics; compare tokenization trade-offs and mixed-modality training (MIDI + MusicXML).
- Training efficiency vs. model size trade-offs are unknown: explore scaling laws (1B vs. 3B–7B), parameter-efficient tuning (LoRA, adapters), and curriculum schedules for joint text/MIDI learning to balance inference speed and controllability.
- Lack of transparent details for AMT-based infilling conditions in training: specify and ablate how anticipated tokens are presented, how masks/conditions are constructed, and how loss weighting affects infilling behavior and text conditioning.
Practical Applications
Applications of Midi-LLM
The paper introduces Midi-LLM, a LLM adapted for multitrack text-to-MIDI generation via vocabulary expansion and a two-stage training recipe. Because it preserves the LLM parameter structure, it can leverage vLLM for fast, cost-efficient inference, and it demonstrably outperforms prior text-to-MIDI systems on quality, controllability, and speed. Below are practical applications derived from the paper’s findings, methods, and innovations, grouped by deployment horizon and linked to relevant sectors. Each item includes assumptions or dependencies that may affect feasibility.
Immediate Applications
The following applications can be deployed now with the released code, weights, and demo, relying on standard tooling (HuggingFace Transformers, vLLM, fluidsynth) and existing music production ecosystems.
- Software / Creative Tools — Text-to-MIDI Copilot for DAWs
- Use case: Generate multitrack MIDI from prompts (genre, mood, instrumentation, tempo, tonality) and import directly into DAWs (e.g., Ableton Live, Logic Pro, Reaper) for editing, arrangement, and mixing.
- Tools/products/workflows: A lightweight script or plugin that calls a local vLLM server and returns MIDI clips; prompt templates; batch generation with top-p sampling; optional quantization (FP8) for cheaper inference.
- Assumptions/dependencies: Access to GPU/CPU with sufficient memory; fluidsynth or virtual instruments (VSTs) for rendering; current model lacks note dynamics (velocity) and certain controllers, so expressive performance may require manual editing or downstream tools.
- Media / Advertising / Stock Music — Prompt-to-Loop/Track Generator
- Use case: Rapidly generate royalty-manageable MIDI loops and stems for ads, corporate videos, podcasts, and stock libraries, with human curation and polishing.
- Tools/products/workflows: Batch prompt pipelines; style libraries (e.g., “uplifting corporate,” “dark cinematic,” “lofi hip-hop”); human-in-the-loop selection; MIDI-to-audio rendering via VSTs.
- Assumptions/dependencies: Legal review of dataset provenance and licensing for downstream commercialization; quality control; model bias toward Western instrumentation due to LMD/GigaMIDI data.
- Games / XR — Real-time Adaptive Background Music
- Use case: Generate or refresh background music segments based on game state (e.g., tension, exploration, boss fight) or player behavior, swapping MIDI clips on the fly to avoid repetition.
- Tools/products/workflows: Runtime service that sends state tags to Midi-LLM and renders MIDI via embedded soft synth; RTF > 11 suggests generation faster than playback for short segments.
- Assumptions/dependencies: Integration with game engines (Unity/Unreal), real-time audio pipeline, and latency management; conservative length (e.g., 10–30 seconds) to avoid sequence limits during gameplay; careful memory management on consoles/mobile.
- Education — Music Theory Exercise Generator
- Use case: Automatically produce MIDI examples for chord progressions, tonalities, instrumentations, and rhythms; generate practice material for sight-reading and arranging.
- Tools/products/workflows: Teacher interface for prompt-based generation; export to class DAW or notation software; worksheet generation with paired text prompts and MIDI.
- Assumptions/dependencies: Pedagogical validation; may need post-processing for notation (e.g., quantization and phrasing) since AMT tokens are not score-native.
- Accessibility / Hobbyist Creativity — Mood-to-Melody Web App
- Use case: Enable novices to create multi-instrument music from natural language without formal training; assist users with limited mobility via text-based composition.
- Tools/products/workflows: Browser UI calling hosted vLLM; library of prompt presets; export to MIDI and audio; simple editing tools.
- Assumptions/dependencies: Hosted inference costs and rate limits; basic moderation (e.g., prompt filtering, safety) if deployed publicly.
- Research (Music AI) — Dataset Augmentation and Benchmarking
- Use case: Augment symbolic music datasets with synthetic MIDI conditioned on diverse text prompts; benchmark text-to-symbolic generation using standardized pipelines (FAD/CLAP via MIDI-to-audio synthesis).
- Tools/products/workflows: Use the released weights to generate paired text-MIDI examples; evaluate with fluidsynth-rendered audio; analyze text controllability.
- Assumptions/dependencies: FAD/CLAP depend on audio render quality and feature extractors; generated samples must be clearly labeled to avoid contamination in downstream training.
- Software Engineering / ML Systems — Embedding Expansion Pattern Reuse
- Use case: Adopt the paper’s vocabulary expansion technique (adding domain tokens to LLM embeddings) for other tokenized, non-text sequences (e.g., event logs, time-series symbol streams).
- Tools/products/workflows: Initialize new embeddings randomly; continued pretraining on standalone domain tokens; supervised finetuning with paired domain-text; leverage vLLM for inference.
- Assumptions/dependencies: Requires robust tokenization for the target domain; data availability for both standalone and paired stages.
Long-Term Applications
These applications require further research, scaling, or development—particularly around expressive MIDI, text-guided editing, personalization, and policy frameworks.
- Software / Creative Tools — Natural-Language Editing of MIDI
- Use case: Edit existing compositions via text (e.g., “double the string ostinato,” “transpose the bridge to E minor,” “thin out the arrangement after bar 16”).
- Tools/products/workflows: Iterative dialogue with a DAW-integrated copilot; alignment between text instructions and structural edits (bars, sections, instruments).
- Assumptions/dependencies: The paper’s negative finding (limited text influence in infilling) indicates more research needed for strong text-conditioned edits; likely requires additional training paradigms and alignment methods.
- Performance / Expressivity — Velocity, Articulation, and Controllers
- Use case: Generate expressive performance parameters (velocity, pedaling, modulation, tempo curves, CC automation) for realistic playback and nuanced musicality.
- Tools/products/workflows: Extended MIDI tokenization and model retraining; joint generation of notes and performance metadata; post-processing with performance models.
- Assumptions/dependencies: Current AMT tokenization omits dynamics; requires new tokens, data, and evaluation metrics; potential increases in sequence length and compute.
- Personalization — RLHF/DPO for User-Specific Taste and Style
- Use case: Tailor generative behavior to a user’s preferred genres, motifs, instrumentation, and complexity through interactive feedback.
- Tools/products/workflows: Collect demo feedback at scale; preference modeling; style tokens; user profiles; fine-tuning pipelines.
- Assumptions/dependencies: Sufficient high-quality feedback and careful prompt safety; on-device or private fine-tuning for privacy-sensitive users.
- Cross-Domain Symbolic Generation — Generalizing the Embedding Expansion Method
- Sectors: Robotics (control sequences), CAD (parametric design steps), Animation (keyframe/event streams), Education (symbolic exercises).
- Use case: Apply the LLM vocabulary expansion + two-stage training to other structured event/token domains for text-conditioned generation and editing.
- Tools/products/workflows: Domain-specific tokenizers; continued pretraining on standalone tokens; paired text-domain finetuning; vLLM-backed serving.
- Assumptions/dependencies: High-quality tokenizers and datasets; safety and reliability expectations differ per domain (e.g., robotics requires strict constraints).
- Games / XR — Fully Procedural, Player-Adapted Score
- Use case: Long-form, coherent, dynamic scores with structure-aware transitions, motif reuse, and adaptive orchestration synchronized to narrative beats and player context.
- Tools/products/workflows: Hierarchical generation (sections, phrases, motifs); text + state-conditioned editing; multi-scene music director.
- Assumptions/dependencies: Robust long-sequence modeling (>2K tokens); formalized structure tokens; strong text conditioning.
- Education — Curriculum Integration and Controlled Studies
- Use case: Systematically integrate text-to-MIDI tools into music pedagogy; study learning outcomes for harmony, orchestration, and composition.
- Tools/products/workflows: Classroom platforms; exercise banks; assessment rubrics; longitudinal studies.
- Assumptions/dependencies: Institutional approval; standardized evaluation of educational efficacy; inclusive datasets covering diverse musical traditions.
- Health / Therapy — Personalized Music for Wellness
- Use case: Generate personalized, mood-aligned music for relaxation, focus, or therapy sessions; adapt over time with user feedback.
- Tools/products/workflows: Clinical validation; preference tuning; safe prompt design; integration with therapeutic protocols.
- Assumptions/dependencies: Regulatory approval for clinical settings; stringent privacy controls for user data.
- Policy / Governance — Standards for AI Music Provenance, Licensing, and Transparency
- Use case: Establish guidelines for dataset provenance, watermarking of AI-generated MIDI, attribution metadata, and labeling in consumer products.
- Tools/products/workflows: Standardized metadata schemas (prompt, model version, generation settings); watermarking; rights management workflows; audit trails.
- Assumptions/dependencies: Cross-industry consensus; potential updates to copyright law; clear policies on training data and commercial usage.
- Mobile / Edge — On-Device, Low-Latency Music Copilots
- Use case: Offline, privacy-preserving text-to-MIDI generation on laptops/tablets/phones; creative apps with real-time feedback.
- Tools/products/workflows: Distillation and quantization strategies; memory-optimized inference; edge-friendly tokenization.
- Assumptions/dependencies: Model compression without quality loss; hardware acceleration; UX design for constrained devices.
- Multi-Modal Production — MIDI-to-Audio and Audio-MIDI Round-Trip
- Use case: Integrated pipelines where text drives MIDI, MIDI controls high-fidelity audio synthesis, and audio-to-MIDI tools support iterative refinement.
- Tools/products/workflows: Coupling Midi-LLM with state-of-the-art audio generative models; round-trip alignment tools; consistent timbral control via instrument profiles.
- Assumptions/dependencies: Robust cross-modal alignment; licensing of audio models and sound libraries; computational costs for high-quality audio synthesis.
In summary, Midi-LLM enables immediate, scalable text-to-MIDI generation with strong practical value in creative industries, education, and research, while opening long-term avenues for expressive control, personalization, cross-domain generalization, and policy development. The principal dependencies include GPU/serving infrastructure (vLLM), MIDI rendering tools, expanded tokenization for expressive parameters, and governance around datasets and licensing.
Glossary
- ABC-derived notations: Text-based musical notation formats derived from ABC, used to represent music symbolically for language modeling. "text-based ABC-derived notations~\citep{yuan2024chatmusician,qu2024mupt,wang2025notagen}"
- ABC notation: A plain-text music notation system for encoding melodies and rhythms. "QAs -- music in ABC notation"
- AdamW: An optimizer that decouples weight decay from the gradient update to improve training stability. "AdamW~\citep{loshchilov2017decoupled} optimizer"
- Anticipatory Music Transformer (AMT): A symbolic music transformer that models notes via arrival-time tokenization and uses anticipated tokens for infilling. "Anticipatory Music Transformer (AMT)~\citep{thickstun2024anticipatory}"
- Arrival (onset) time: The start time of a note, used as a token in AMT’s representation. "Arrival (onset) time: The note's start time"
- BF16 precision: A bfloat16 floating-point format that accelerates training while preserving range for gradients. "BF16 precision."
- CLAP: Contrastive Language-Audio Pretraining; a metric/model that aligns text and audio embeddings to assess prompt relevance. "CLAP~\citep{wu2023large}: is meant to capture each output's relevance to text prompt"
- Contrastively trained text encoder: A text encoder trained to align with audio features via contrastive learning. "contrastively trained text encoder (receiving the prompt)"
- Continued pre-training: Further pretraining of an LLM on domain-specific data to specialize its capabilities. "continued pre-training stage"
- Cosine decay: A learning-rate schedule that decays following a cosine curve. "learning rate to with cosine decay."
- DPO: Direct Preference Optimization; a technique for aligning models to human preferences without explicit reward modeling. "DPO~\citep{rafailov2023direct}"
- Encoder-decoder setup: An architecture with separate encoder and decoder components for conditioning and generation. "it uses an encoder-decoder setup"
- FAD: Fréchet Audio Distance; a measure of audio generation quality based on feature distribution similarity. "FAD~\citep{kilgour2019fr}: measures roughly the outputs' quality or realisticness"
- FlashAttention-2: An optimized attention algorithm that improves speed and memory efficiency for transformers. "FlashAttention-2~\citep{dao2024flashattention}"
- fluidsynth: A software synthesizer that renders MIDI into audio using soundfonts. "fluidsynth package."
- FP8 quantization: 8-bit floating-point quantization to speed inference and reduce memory usage with modest quality impact. "Using FP8 quantization yields additional speedup (20\%)"
- Instrument-pitch: A joint token encoding both the instrument identity and the pitch of a note. "Instrument-pitch: A joint token for the instrument and its pitch"
- Lakh MIDI (LMD): A large-scale dataset of MIDI files widely used for symbolic music research. "Lakh MIDI~(LMD)~\citep{raffel2016lmd}"
- LlamaForCausalLM: A HuggingFace class implementing causal Llama models for generation tasks. "instantiate Midi-LLM from LlamaForCausalLM"
- MidiCaps: A dataset providing MIDI pieces paired with descriptive text captions. "MidiCaps~\citep{melechovsky2024midicaps}"
- Music infilling: Generating or completing missing musical segments conditioned on surrounding context. "music infilling tasks"
- Nucleus sampling: A sampling method that draws from the smallest set of tokens whose cumulative probability exceeds p. "nucleus sampling~\citep{holtzman2020curious} with top "
- Real-time factor (RTF): The ratio of generated audio duration to the wall-clock time required to produce it. "RTF real-time factor: generated music duration / wall-clock time."
- REMI: Revamped MIDI tokenization aligned to beats, used for structured symbolic music modeling. "metered Revamped MIDI tokens (REMI)~\citep{huang2020pop,hsiao2021compound,wu2023compose}"
- Supervised finetuning: Training on paired inputs and targets (e.g., text-to-MIDI) to learn a specific mapping. "Supervised finetuning."
- Token embedding weights: The learned matrix mapping tokens to their vector embeddings for transformer input. "expand the LLM's token embedding weights"
- vLLM: A high-performance LLM inference engine that provides efficient memory management and acceleration. "vLLM~\citep{kwon2023efficient,shaw2024llm} for accelerated inference."
- VGGish: An audio feature extractor based on VGG-like CNN architecture used for evaluation. "We employ VGGish~\citep{hershey2017cnn} as the feature extractor."
Collections
Sign up for free to add this paper to one or more collections.