PercHead: Perceptual Head Model for Single-Image 3D Head Reconstruction & Editing
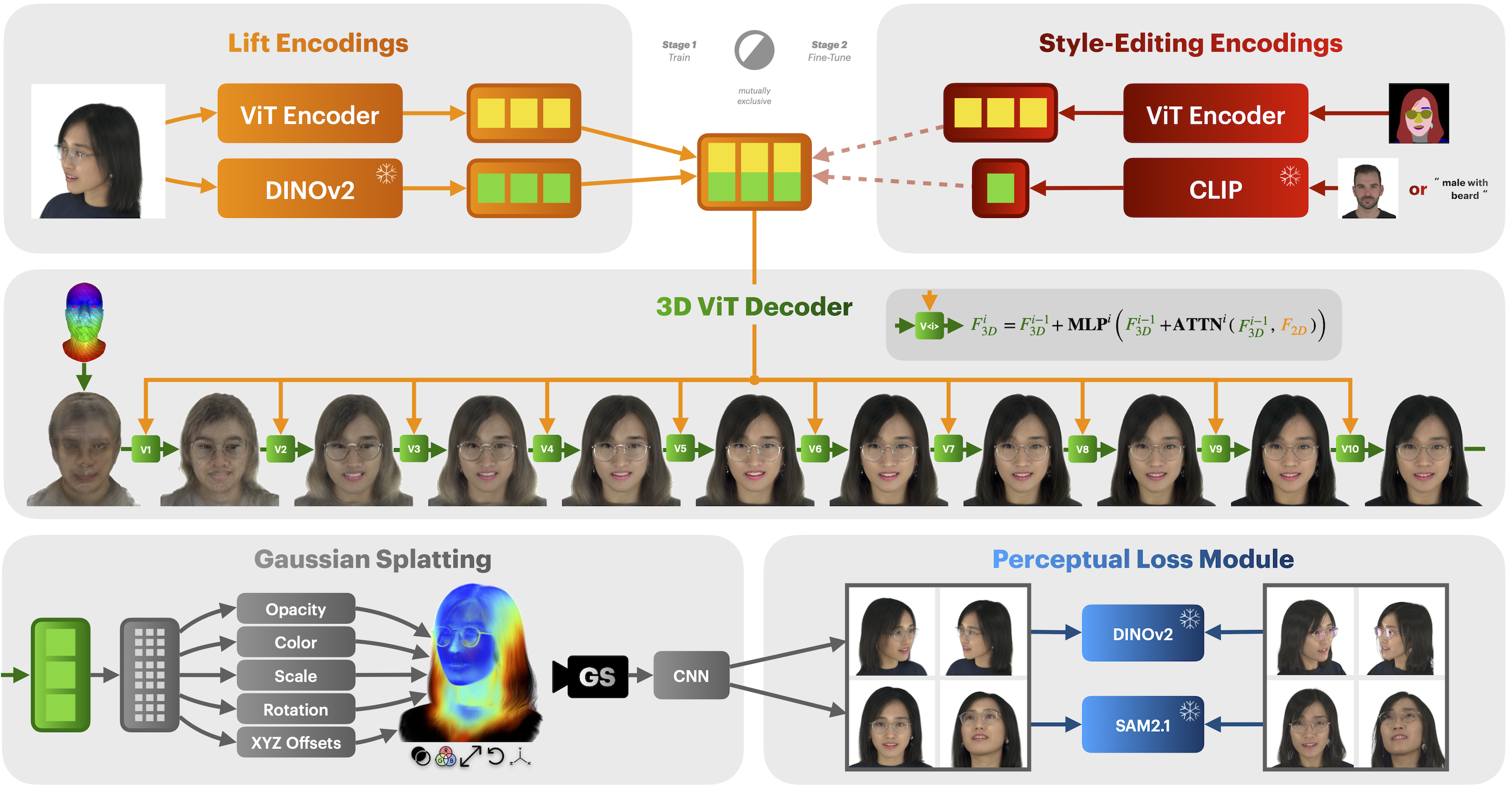
Abstract: We present PercHead, a method for single-image 3D head reconstruction and semantic 3D editing - two tasks that are inherently challenging due to severe view occlusions, weak perceptual supervision, and the ambiguity of editing in 3D space. We develop a unified base model for reconstructing view-consistent 3D heads from a single input image. The model employs a dual-branch encoder followed by a ViT-based decoder that lifts 2D features into 3D space through iterative cross-attention. Rendering is performed using Gaussian Splatting. At the heart of our approach is a novel perceptual supervision strategy based on DINOv2 and SAM2.1, which provides rich, generalized signals for both geometric and appearance fidelity. Our model achieves state-of-the-art performance in novel-view synthesis and, furthermore, exhibits exceptional robustness to extreme viewing angles compared to established baselines. Furthermore, this base model can be seamlessly extended for semantic 3D editing by swapping the encoder and finetuning the network. In this variant, we disentangle geometry and style through two distinct input modalities: a segmentation map to control geometry and either a text prompt or a reference image to specify appearance. We highlight the intuitive and powerful 3D editing capabilities of our model through a lightweight, interactive GUI, where users can effortlessly sculpt geometry by drawing segmentation maps and stylize appearance via natural language or image prompts. Project Page: https://antoniooroz.github.io/PercHead Video: https://www.youtube.com/watch?v=4hFybgTk4kE





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces PercHead, a computer program that can turn a single face photo into a realistic 3D head you can view from any angle. It also lets you “edit” that 3D head by changing the shape (like the jawline or hairstyle outline) separately from the look (like hair color or skin texture) using simple inputs such as a sketch-like map, a reference image, or even a text prompt.
What are the main goals?
In simple terms, the paper aims to:
- Rebuild a believable 3D head from just one photo, even when you turn it to angles the photo never showed.
- Keep the person’s identity clear and consistent from different viewpoints.
- Make editing easy and powerful: control the head’s shape and style independently, so changing one doesn’t mess up the other.
How does it work? (Easy explanation)
Think of it like turning a single selfie into a detailed 3D sculpture and then “painting” it. The system has two big parts: a reconstruction model and an editing model. They both share the same 3D “builder,” but take different kinds of input.
Here’s the approach, explained with everyday ideas:
- Dual-branch “eyes” for the photo:
- The program first looks at the 2D image using two kinds of smart “eyes”:
- DINOv2: a powerful vision model that sees general patterns and meaning in images (like “this is hair,” “this is skin,” “these are edges”).
- A small Vision Transformer (ViT): a task-focused helper that picks up extra details specific to 3D head building.
- These two feature sets are aligned and combined, so the system has both broad understanding and fine detail.
- Lifting 2D features into 3D:
- The 3D “builder” is a transformer decoder that starts from a basic 3D face template (like a plain bust with many tiny points).
- It repeatedly “asks” the 2D features where to place and adjust parts in 3D. You can imagine a sculptor checking the photo and refining the sculpture layer by layer.
- Painting with tiny blobs: Gaussian Splatting
- Instead of triangles or blocks, the head is rendered using lots of tiny, soft 3D spots (Gaussians). Picture making a 3D object from thousands of little translucent dots that you can color, resize, and rotate to match the photo’s look. This is fast and photorealistic.
- Better training with smart guidance:
- Instead of using standard pixel-by-pixel comparisons (which often miss what humans care about), the system learns using feature signals from DINOv2 and SAM 2.1 (SAM is great at understanding image regions).
- Think of these models as expert coaches who tell the system, “This looks like real hair texture,” or “This outline matches a face,” giving strong, general feedback that improves realism and consistency.
- Editing model: separate shape and style
- For editing, the input changes:
- Geometry control: a segmentation map (like a color-by-number outline showing where hair, eyes, mouth, etc. are). This tells the system the head’s structure.
- Style control: a single “style token” from CLIP (another vision-LLM). You can give it a reference image or just text like “old man with gray curly hair” or “teen with short black hair,” and it adjusts colors and textures accordingly.
- Because the shape and style come from different sources, you can change one without messing up the other.
What did they find, and why does it matter?
The authors tested PercHead on multiple datasets and compared it with well-known methods. Key outcomes:
- Stronger realism and identity consistency:
- PercHead beat competing systems on most measures of quality and identity preservation, especially when the view is very different from the original photo (like side or top views).
- Robust to extreme angles:
- Other methods often break down when you look from unusual angles. PercHead stays stable and realistic, keeping the person recognizable.
- Flexible editing:
- The model can generate heads that keep the same shape while swapping styles, or keep the same style while changing shapes. It also supports zero-shot text edits (you don’t need special training to use text prompts), which is rare and very handy.
- Works frame-by-frame on videos:
- Even though the model is trained on single images, it can reconstruct consistent 3D heads across video frames, handling small expression changes without identity drift.
These results matter because creating believable 3D heads from a single image is hard, and humans are very sensitive to even small mistakes in faces. PercHead’s approach delivers both realism and robustness, which is vital for avatars, games, virtual try-on, and more.
What could this change in the future?
- Easier avatar creation:
- Make lifelike 3D heads from simple photos for video calls, games, or virtual worlds, with smooth camera control and consistent identity.
- Intuitive 3D editing:
- Artists and users can sculpt geometry with simple segmentation maps and style with images or text, speeding up creative workflows.
- New training direction:
- Using “foundation model” features (like DINOv2 and SAM) as training signals might replace older pixel-level losses, leading to better-looking 3D results in many areas.
The authors note a few current limits: it doesn’t yet transfer dynamic expressions in real time, it’s not optimized for instant performance, and lighting is baked into the result. Still, the core idea—training with strong, general visual signals and cleanly separating shape and style—could influence many future 3D face and avatar systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of specific gaps and open questions the paper leaves unresolved, framed to be actionable for future research.
- Dynamic expression modeling and rigging are not supported; investigate integrating expression parameters (e.g., FLAME blendshapes) and evaluate reenactment/animation fidelity.
- Real-time performance is not achieved; profile the pipeline, identify bottlenecks (3D lifting, rasterization, CNN), and explore architectural/pruning/compilation strategies for low-latency inference.
- Lighting is baked into the reconstruction; develop and assess intrinsic decomposition (albedo, normals, BRDF, illumination) and controllable relighting for novel environments.
- The approach depends on GAGAvatar’s tracking/background removal; quantify sensitivity to tracking/cropping errors and test robustness in unconstrained, in-the-wild capture without pre-processing.
- The decoder omits self-attention across 3D patches; evaluate whether sparse/global 3D attention improves long-range structural coherence and identify cases where patch independence fails.
- Evaluation relies on 2D view-based metrics; add 3D geometry metrics (surface/normal errors vs scans, multi-view geometric consistency, self-consistency under view loops).
- Test sets are small; broaden evaluation across demographics, hairstyles, and viewpoints to measure generalization, fairness, and bias (age, gender, skin tone, cultural hair/attire).
- Occlusions (hands, glasses, hats, microphones) and accessories are not analyzed; systematically test and improve robustness to partial visibility and structured occlusions.
- Accuracy of unseen regions (ears, back of head, crown) from single inputs is assumed but not quantified; design protocols to measure plausibility/completion correctness under ground-truth multi-view.
- Editing disentanglement is not quantitatively assessed; define metrics for geometry–style leakage, controllability, and identity preservation during edits across views and time.
- Zero-shot text-driven editing via CLIP is untested for complex/compositional prompts; characterize failure modes (attribute entanglement, stereotype bias, prompt sensitivity) and compare to fine-tuned text encoders.
- FARL’s 19-class segmentation may be too coarse for fine geometry (hair strands, beards, eyebrows); evaluate higher-resolution or instance-level segmentations and their impact on geometric control.
- Synthetic Cafca data is used for reconstruction but excluded for editing; quantify domain-gap effects (hallucination bias, stylization artifacts) and establish guidelines for synthetic–real data mixing.
- Video results are computed frame-wise with no temporal modeling; add and validate temporal consistency metrics and modules (temporal attention/recurrent units) to prevent drift and flicker.
- Gaussian Splatting lacks physically grounded reflectance and hair dynamics; explore hybrid representations (Gaussian + mesh/implicit), dynamic strands, and microgeometry for thin structures.
- Camera intrinsics/extrinsics estimation is delegated to tracking; test robustness to FOV/lens distortion variations and provide calibration-free or self-calibrating alternatives.
- Identity fidelity evaluation uses ArcFace only; complement with stronger face verification suites, human studies, and per-region identity fidelity (eyes, nose, mouth) under extreme views.
- The CNN sharpen module (trained with LPIPS/L1) is decoupled from the main training; analyze artifacts it introduces, and compare end-to-end joint training under foundation-model losses.
- Representation size is fixed (~65k Gaussians); study adaptive sparsity/compression (pruning, quantization, tile-based rendering) to trade off speed, memory, and quality.
- Failure case analysis is missing; collect, categorize, and report typical errors (symmetry mirroring, color tint, geometric drift, hair collapse) with corresponding causal diagnostics.
- Privacy, consent, and misuse risks of single-image 3D head reconstruction are not addressed; propose watermarking, provenance, consent workflows, and anti-abuse safeguards.
- Generalization to atypical heads (children, medical conditions, non-human heads) is unexplored; add out-of-distribution detection and controlled evaluations.
- Multi-image/few-shot extensions are not studied; assess whether additional views improve accuracy and identity, and design training/inference paths that leverage sparse multi-view input.
- Expression transfer/animation pipeline integration is missing; map reconstructions to controllable rigs and evaluate the quality of expression retargeting across identities.
- Relighting and environment consistency are not evaluated; use controlled light-stage datasets to benchmark relighting accuracy and shadow/reflection behavior.
- Robustness to adverse inputs (low resolution, noise, compression, motion blur) is not measured; create stress-test suites and test-time augmentation strategies.
- Edited results’ 3D/temporal consistency is not quantified; define metrics ensuring style edits remain consistent across viewpoints and time (e.g., cross-view style invariance, temporal LPIPS/ID).
- Choice of DINOv2/SAM layers and loss weighting lacks systematic justification; perform hyperparameter sweeps across layers, scales, and model variants (OpenCLIP, IJEPA/V-JEPA) to optimize supervision.
- Cultural/attribute biases from CLIP/DINOv2/SAM are unexamined; audit for bias in styling and identity preservation and explore debiasing or balanced data curation.
- Scalability and resource footprint (VRAM, runtime per frame, batch throughput) are not reported; provide detailed resource profiles and explore deployment on edge devices.
Practical Applications
Immediate Applications
Below are applications that can be deployed now, leveraging the paper’s current capabilities and accompanying GUI.
- Sector: software/entertainment — Single-image avatar creation for games, VR, and AR
- Use case: Convert a selfie into a high-fidelity, view-consistent 3D head for player avatars, NPCs, and XR experiences.
- Tools/products/workflows: PercHead GUI or an SDK/API; export Gaussian assets to Unity/Unreal via a plugin; Blender add-on for asset cleanup and retopology.
- Assumptions/dependencies: Offline generation (not real-time); licensing for DINOv2/SAM2.1/CLIP weights; sufficient GPU for inference; identity consent and rights management for face assets.
- Sector: communications — Asynchronous virtual presence and content for video conferencing
- Use case: Generate avatar headshots that remain identity-consistent across viewpoints for intros, profile cards, scenes and recorded content.
- Tools/products/workflows: A “photo-to-avatar” web service integrated with Zoom/Teams add-ons; templated multi-angle portrait packs.
- Assumptions/dependencies: Not suitable for live, real-time conferencing due to current inference cost and lack of dynamic expression transfer; baked lighting may require post-processing.
- Sector: photography/creative studios — Multi-angle portraits and creative look development
- Use case: Produce consistent multi-view photo sets (e.g., left/right/top angles) from a single image; rapid exploration of styles (hair color/texture, age) via text prompts.
- Tools/products/workflows: Batch processing pipeline for studios; stylization via CLIP prompts and segmentation-map sculpting; export renders for client review.
- Assumptions/dependencies: Style edits are non-physical (e.g., “age” as a semantic change) and require curation; baked-in lighting limits re-lighting flexibility.
- Sector: retail/e-commerce — Visual “try-on” previews for hair and cosmetics
- Use case: Preview hair color/texture, makeup looks, and general appearance changes on a user’s head model from a single photo; marketing content generation for product pages.
- Tools/products/workflows: Web widget that accepts a selfie, reconstructs the head, and applies style via prompt/reference image; export images/videos of various angles.
- Assumptions/dependencies: Geometry-level control is segmentation-map-based (not a precise physical model); fit-critical categories (e.g., eyewear sizing) need caution and disclaimers; baked lighting may conflict with product photography.
- Sector: academia (vision/graphics) — Research baselines and training strategies
- Use case: Benchmark robust single-image 3D head reconstruction under extreme viewpoints; study generalized perceptual losses using DINOv2 + SAM2.1 vs. LPIPS/L1; ablation on data blends (multi-view + single-view).
- Tools/products/workflows: Release of training/inference scripts; reproducible experiments on NeRSemble/Ava-256 and FFHQ; plug-and-play perceptual loss modules.
- Assumptions/dependencies: Access to datasets; compute hours similar to paper (e.g., 70h + 24h training); adherence to dataset licensing and ethics.
- Sector: media/virtual production — Rapid digital-double prototyping
- Use case: Generate hero/reference heads and extras from limited imagery for previz, storyboards, and blocking; produce turntables for asset reviews.
- Tools/products/workflows: Pipeline: single image → PercHead → Gaussian render → post-sharpening CNN → DCC import; versioned style explorations with text prompts.
- Assumptions/dependencies: Not yet production-ready for physically plausible re-lighting; manual touch-up likely required for final shots.
- Sector: social media/daily life — Stylized profile avatars
- Use case: Create identity-preserving avatars with diverse appearances (e.g., hairstyles, age look) controlled via text or a reference photo.
- Tools/products/workflows: Mobile app with guided selfie capture, segmentation-map scribble UI for geometry, and prompt-based style presets.
- Assumptions/dependencies: Responsible data use (GDPR/CCPA compliance); clear disclosures to avoid impersonation risks.
- Sector: policy/security — Risk assessment and content provenance
- Use case: Internal testing of identity-preserving 3D generation to inform platform policies; watermarking and provenance metadata for generated assets; evaluate recognition drift with ArcFace/DreamSim.
- Tools/products/workflows: Integrate ArcFace/DreamSim checks in moderation pipelines; embed provenance tags at export; developer guidelines for consent and disclosure.
- Assumptions/dependencies: Coordination with legal/compliance; provenance systems must be maintained end-to-end; does not replace robust deepfake detection in high-stakes contexts.
Long-Term Applications
Below are applications that require further research, scaling, or system development, including overcoming identified limitations (lack of real-time performance, no dynamic expression transfer, and baked lighting).
- Sector: communications/robotics — Real-time telepresence avatars with dynamic expressions
- Use case: Live video conferencing avatars on AR/VR devices and social robots with accurate expression capture, lip-sync, and head motion.
- Tools/products/workflows: Lightweight on-device encoder; expression retargeting/rigging; hardware acceleration (mobile GPU/ASIC); live Gaussian rasterization pipeline.
- Assumptions/dependencies: Efficient, real-time inference; robust expression transfer; low-latency tracking and rendering; privacy-preserving processing on device.
- Sector: healthcare/telemedicine — Non-diagnostic craniofacial visualization and patient education
- Use case: Visual counseling for cosmetic procedures, hair restoration previews, or dermatology appearance changes from limited imagery.
- Tools/products/workflows: Clinical viewer with controlled style edits; consent and audit logging; integration with EMR for securely stored assets.
- Assumptions/dependencies: Must avoid diagnostic claims; requires high geometric fidelity, lighting separation, and bias audits; regulatory approvals and clinician oversight.
- Sector: retail/fit-tech — Accurate eyewear, AR hats/wigs, and helmet fit simulation
- Use case: True-to-size virtual try-on that respects facial geometry (nose bridge, temple width) and hair volume, across viewpoints.
- Tools/products/workflows: Calibration steps (e.g., scale from device depth sensor); physics-aware hair modeling; re-lightable materials; product CAD alignment.
- Assumptions/dependencies: Metric accuracy, re-lighting, and material disentanglement; device sensors and standards; liability-managed claims.
- Sector: media/virtual production — Re-lightable, production-quality digital humans
- Use case: Film-grade digital doubles with physically-based materials, correct speculars/subsurface scattering, and robust re-lighting.
- Tools/products/workflows: Material/BRDF decomposition; light transport disentanglement; hair/fur simulation; USD-based asset pipeline.
- Assumptions/dependencies: Overcoming baked-lighting; integrating with PBR workflows; significant pipeline engineering and artist tooling.
- Sector: education/training — Conversational tutors with personalized, expressive heads
- Use case: Adaptive teaching agents with identity-consistent, expressive avatars that can lip-sync and emote in real time.
- Tools/products/workflows: Speech-to-expression mapping; low-latency rendering; curriculum-integrated content authoring tools.
- Assumptions/dependencies: Real-time performance; safe identity use; content moderation and bias mitigation.
- Sector: security/identity — Liveness and anti-spoof research (defense and red teaming)
- Use case: Use robust 3D head synthesis to stress-test KYC/biometric pipelines and inform standards for liveness checks.
- Tools/products/workflows: Controlled generation of edge cases (extreme view angles, occlusions); evaluation harnesses for KYC systems.
- Assumptions/dependencies: Strict governance; restricted access to prevent misuse; collaboration with standards bodies.
- Sector: foundational research — Generalized perceptual supervision for 3D beyond heads
- Use case: Transfer DINOv2+SAM2.1 loss formulation and 2D-to-3D cross-attention lifting to other categories (hands, bodies, objects, scenes).
- Tools/products/workflows: New datasets and benchmarks; multi-modal supervision (segmentation + vision-language).
- Assumptions/dependencies: Availability of diverse multi-view data; adaptation of FLAME-like templates where relevant; attention to category-specific biases.
- Sector: mobile/edge computing — On-device personalized avatar generation
- Use case: Private, instant avatar creation on smartphones/AR glasses without server-side processing.
- Tools/products/workflows: Model distillation/quantization; memory-efficient Gaussian pipelines; secure local storage and provenance.
- Assumptions/dependencies: Model compression research; hardware acceleration; user-friendly capture guidance.
- Sector: accessibility — Assistive communication via expressive avatars
- Use case: Real-time expressive heads for users with speech or facial movement impairments to convey affect and intent.
- Tools/products/workflows: Expression synthesis driven by text/intent; integration with AAC devices; personalization via a single photo.
- Assumptions/dependencies: Real-time expression transfer; ethical safeguards; user testing and clinical partnerships.
Notes on feasibility across all applications:
- Current limitations: No dynamic expression transfer, not real-time, and lighting baked into the reconstruction.
- Data and model dependencies: Access to DINOv2/SAM2.1/CLIP, multi-view and single-view data, and GPU resources.
- Governance: Consent, privacy, provenance/watermarking, and bias audits are essential, especially for identity-related applications.
Glossary
- 3D Gaussians: Ellipsoidal Gaussian primitives used as a compact scene representation for differentiable rendering. "and converted into a set of renderable 3D Gaussians."
- 3D Morphable Models (3DMMs): Parametric mesh models that represent facial shape (and often texture) in a low-dimensional space. "mesh-based 3D Morphable Models (3DMMs)"
- ArcFace: A face-recognition loss/embedding used here as a distance metric to measure identity preservation. "and ArcFace \cite{arcface} distance to assess identity preservation."
- Ava-256: A benchmark dataset of human head views used for evaluating reconstruction and view consistency. "We evaluate our model on 11 identities from the completely unseen dataset Ava-256 \cite{ava256}"
- Cafca: A synthetic multi-view dataset of artificial personas used to augment training for 3D consistency. "artificial multi-view head data from Cafca \cite{cafca}"
- CLIP: A contrastive language–image model whose embeddings are used to control style via text or image prompts. "integrates a frozen CLIP~\cite{clip} module"
- Cosine distance: A similarity metric between feature vectors based on the cosine of the angle between them. "using cosine distance on -normalized feature vectors from both DINOv2 and SAM 2.1."
- Cross-attention: A transformer mechanism that allows one set of tokens (here, 3D tokens) to attend to another set (2D image features). "through iterative cross-attention."
- DINOv2: A self-supervised Vision Transformer whose features are used for generalized perceptual supervision. "based on DINOv2~\cite{dinov2} and SAM2.1~\cite{sam2}"
- DreamSim (DS): A learned perceptual similarity metric used to assess visual fidelity. "LPIPS \cite{lpips} and DreamSim (DS) \cite{dreamsim} as perceptual metrics"
- EG3D: A 3D-aware GAN architecture that uses tri-plane features for efficient high-quality rendering. "EG3D~\cite{eg3d} introduced tri-plane representations"
- FaRL segmentation maps: Multi-channel face parsing maps from the FaRL model used to control geometry in editing. "takes 19-channel FaRL~\cite{farl} segmentation maps as input to guide geometry"
- FFHQ: A large-scale high-quality face image dataset used for single-view supervision and diversity. "and diverse single-view images from FFHQ \cite{ffhq}"
- FLAME: A parametric head model providing a canonical mesh template for initialization. "FLAME template~\cite{flame}"
- GAGAvatar: A single-image Gaussian-based avatar method with dual-lifting; used as a baseline and for preprocessing. "GAGAvatar~\cite{gagavatar} introduced a dual-lifting strategy"
- Gaussian Rasterizer: A differentiable renderer specialized for projecting 3D Gaussians into images. "rendered with a differentiable Gaussian Rasterizer~\cite{gaussian_splatting}"
- Gaussian Splatting: A fast, photorealistic 3D rendering technique that represents scenes with 3D Gaussians. "Rendering is performed using Gaussian Splatting."
- GRM (Large Gaussian Reconstruction Model): A large model for reconstructing scenes with 3D Gaussians that inspires the upsampling strategy. "Similar to the Large Gaussian Reconstruction Model (GRM) \cite{grm}"
- L1 loss: A pixel-wise absolute difference loss used as a traditional reconstruction objective. "LPIPS + L1 loss"
- LAM (Large Avatar Model): A transformer-based Gaussian avatar framework trained on multi-frame video supervision. "The Large Avatar Model (LAM)~\cite{lam} employs multi-frame video supervision"
- Latent inversion (PTI): The process of projecting an image into a generative model’s latent space; PTI is a specific inversion refinement. "PTI Inversion \cite{pti} used for 3D reconstruction."
- LGM: A multi-view diffusion-based Gaussian model used as a baseline for 3D consistency. "LGM~\cite{lgm} introduces a multi-view diffusion prior"
- LPIPS: A learned perceptual metric that compares deep features to gauge visual similarity. "LPIPS \cite{lpips}"
- MAE (Masked Autoencoders): A self-supervised pretraining scheme where masked patches are reconstructed, inspiring the encoder/decoder design. "inspired by Masked Autoencoders (MAE)~\cite{mae}."
- NeRF: Neural Radiance Fields, a neural scene representation for novel view synthesis from images. "Early NeRF-based GANs~\cite{pi_gan, style_sdf, style_nerf}"
- NeRSemble: A multi-view head dataset used for training and evaluation of 3D head reconstruction. "on Ava-256 and NeRSemble Datasets."
- PanoHead: A 360° head synthesis method based on 3D GANs and NeRF-like representations. "PanoHead~\cite{panohead} extended this to 360° head generation."
- PixelShuffle: A sub-pixel upsampling operator used to expand feature patches into multiple Gaussians. "we apply PixelShuffle~\cite{pixelshuffle} to upsample"
- PSNR: Peak Signal-to-Noise Ratio, a standard image reconstruction quality metric. "we report PSNR and SSIM \cite{ssim} as standard reconstruction metrics"
- SAM 2.1: The Segment Anything Model (v2.1) image encoder used for segmentation-aware perceptual supervision. "SAM 2.1~\cite{sam2}"
- Segmentation map: A pixel-wise semantic labeling used to specify geometry constraints during editing. "takes 19-channel FaRL~\cite{farl} segmentation maps as input to guide geometry"
- SSIM: Structural Similarity Index, a perceptual image quality metric focusing on structure and contrast. "we report PSNR and SSIM \cite{ssim} as standard reconstruction metrics"
- Tri-grid NeRF: A NeRF variant using a tri-grid structure for efficient 3D-aware generation. "3D GAN with tri-grid NeRF and neural upsampler"
- Tri-plane representations: A 3D scene encoding using three orthogonal feature planes for fast rendering. "EG3D~\cite{eg3d} introduced tri-plane representations"
- VFHQ: A high-quality video face dataset used to test temporal consistency across frames. "Using two VFHQ \cite{vfhq} sequences"
- ViT (Vision Transformer): A transformer architecture for images that processes sequences of patch tokens. "Vision Transformer (ViT) \cite{vit}"
- ViT decoder: The transformer decoder component that lifts 2D features into 3D via cross-attention. "a 3D ViT decoder that lifts 2D features via iterative cross-attention"
Collections
Sign up for free to add this paper to one or more collections.

