Adam Reduces a Unique Form of Sharpness: Theoretical Insights Near the Minimizer Manifold
Published 4 Nov 2025 in cs.LG | (2511.02773v1)
Abstract: Despite the popularity of the Adam optimizer in practice, most theoretical analyses study Stochastic Gradient Descent (SGD) as a proxy for Adam, and little is known about how the solutions found by Adam differ. In this paper, we show that Adam implicitly reduces a unique form of sharpness measure shaped by its adaptive updates, leading to qualitatively different solutions from SGD. More specifically, when the training loss is small, Adam wanders around the manifold of minimizers and takes semi-gradients to minimize this sharpness measure in an adaptive manner, a behavior we rigorously characterize through a continuous-time approximation using stochastic differential equations. We further demonstrate how this behavior differs from that of SGD in a well-studied setting: when training overparameterized models with label noise, SGD has been shown to minimize the trace of the Hessian matrix, $\tr(\mH)$, whereas we prove that Adam minimizes $\tr(\Diag(\mH){1/2})$ instead. In solving sparse linear regression with diagonal linear networks, this distinction enables Adam to achieve better sparsity and generalization than SGD. Finally, our analysis framework extends beyond Adam to a broad class of adaptive gradient methods, including RMSProp, Adam-mini, Adalayer and Shampoo, and provides a unified perspective on how these adaptive optimizers reduce sharpness, which we hope will offer insights for future optimizer design.
The paper demonstrates that Adam reduces a unique sharpness metric, tr(Diag(H)^(1/2)), which distinguishes its implicit regularization from that of SGD.
It employs a slow SDE framework to accurately track adaptive gradient dynamics near the minimizer manifold under the Polyak-Łojasiewicz condition.
Empirical results validate that Adam recovers sparse ground truth with less data in diagonal nets, though it may generalize worse in deep matrix factorization.
Adam Reduces a Unique Form of Sharpness: Theoretical Insights Near the Minimizer Manifold
Introduction and Motivation
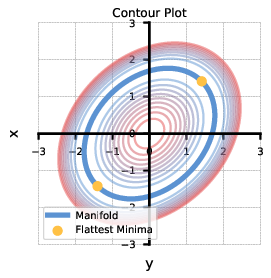
This paper provides a rigorous theoretical analysis of the implicit bias induced by the Adam optimizer, focusing on its behavior near the manifold of minimizers in overparameterized models. While prior work has established that SGD implicitly regularizes the trace of the Hessian (tr(H)), Adam's implicit bias has remained elusive, with most analyses either relying on restrictive assumptions or lacking mathematical rigor. The authors generalize the slow SDE framework to a broad class of Adaptive Gradient Methods (AGMs), including Adam, and demonstrate that Adam minimizes a distinct sharpness measure, tr(Diag(H)1/2), rather than tr(H). This distinction has significant implications for generalization, especially in settings with label noise and structured parameterizations.
Theoretical Framework: Slow SDEs for Adaptive Gradient Methods
The central technical contribution is the derivation of a slow SDE that accurately tracks the projected dynamics of AGMs near the minimizer manifold over a timescale of O(η−2). The analysis is performed under the assumption that the loss landscape admits a smooth minimizer manifold Γ, and the optimizer has converged to a neighborhood of Γ. The slow SDE for Adam (and related AGMs) is shown to take the form:
where PS(t) is an adaptive projection operator, S(t) is the preconditioner, and the drift term corresponds to a semi-gradient descent on a sharpness measure shaped by the optimizer's adaptivity.
The analysis reveals that, unlike SGD, Adam's projection and noise filtering are state-dependent, leading to a qualitatively different implicit bias. The framework is shown to encompass Adam, RMSProp, Adam-mini, Adalayer, and Shampoo, with explicit forms for the implicit regularizer derived for each.
Convergence Analysis and Scaling Regimes
A high-probability convergence bound is established for AGMs under the Polyak-Łojasiewicz condition, directly bounding the optimality gap L(θk)−L∗ rather than averaged quantities. The analysis focuses on the "2-scheme" regime, where 1−β2=O(η2), ensuring that the preconditioner evolves on the same slow timescale as the projected dynamics. This regime is shown to be necessary for tracking the long-term regularization effects of Adam.
Adam's Implicit Bias under Label Noise
Under the label noise condition (Σ(θ)=αH(θ)), the slow SDE reduces to an ODE, and the stationary points of Adam satisfy:
∇Γtr(Diag(H)1/2)=0
In contrast, SGD minimizes ∇Γtr(H). The authors generalize this result to AdamE-λ, showing that tuning the exponent in the preconditioner directly tunes the exponent in the implicit regularizer.
Empirical Validation: Sparse Linear Regression with Diagonal Nets
The theoretical predictions are validated in the diagonal net setting, where the ground truth is sparse and the Hessian is diagonal. Adam is shown to recover the sparse ground truth with significantly less data than SGD, consistent with the fact that minimizing ∥⋅∥0.5 (Adam) is more effective for sparsity than ∥⋅∥1 (SGD).
Figure 1: Final test loss as a function of training data size for Adam, AdamE, and SGD in the diagonal net setting, demonstrating Adam's superior sample efficiency for sparse recovery.
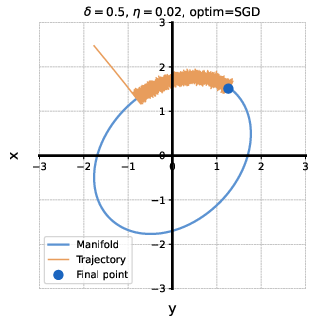
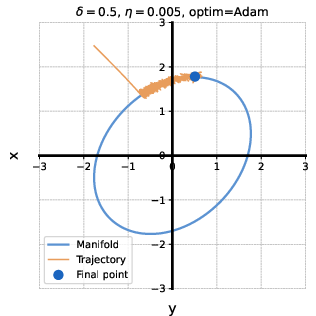
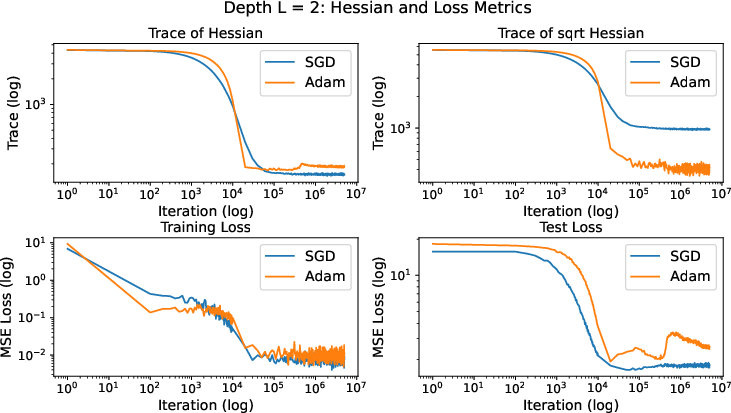
Contrasting Behavior: Deep Matrix Factorization
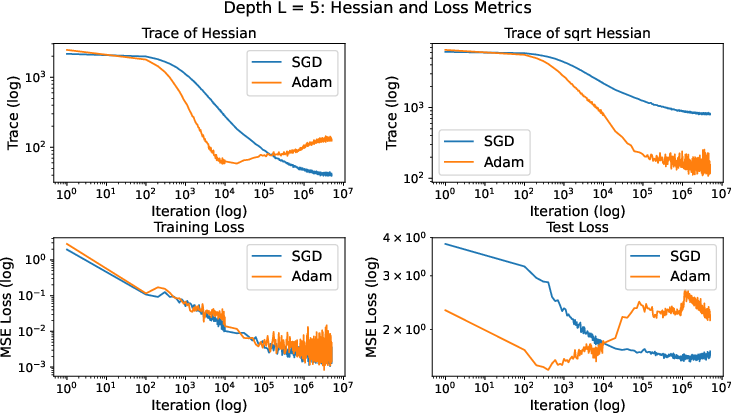
In deep matrix factorization with label noise, the Hessian is not diagonal, and minimizing tr(Diag(H)1/2) does not favor low-rank solutions. Empirically, Adam converges to solutions with higher tr(H) and worse generalization than SGD, confirming the theoretical prediction.
Figure 2: Deep matrix factorization with label noise (L=2); Adam and SGD trained on identical data. Adam achieves lower tr(Diag(H)1/2) but higher tr(H) and test error.
Figure 3: Deep matrix factorization with label noise (L=5); Adam's implicit bias leads to inferior generalization compared to SGD.
Generalization to Other AGMs
The analysis framework is extended to RMSProp, Adam-mini, Adalayer, and Shampoo. For partitioned AGMs (Adam-mini, Adalayer), the implicit regularizer is a sum over blocks/layers of ∣Bi∣⋅tr(HBi), interpolating between Adam and SGD. For Shampoo, the regularization effect cannot be reduced to an explicit potential function, as the induced vector field is non-conservative.
Implementation Considerations
Scaling Regime: The analysis and regularization effects are valid in the regime 1−β2=O(η2); practitioners should ensure this scaling for theoretical guarantees.
Projection Operator: The adaptive projection requires tracking the preconditioner and projecting onto the tangent space of the minimizer manifold, which may be computationally intensive in high dimensions.
Resource Requirements: The slow SDE analysis is most relevant for small learning rates and long training horizons, typical in large-scale deep learning.
Limitations: The framework does not cover weight decay or decoupled regularization (e.g., AdamW), nor does it address behavior far from the minimizer manifold.
Implications and Future Directions
The identification of tr(Diag(H)1/2) as Adam's implicit regularizer provides a principled explanation for its empirical success in settings where sparsity is beneficial, and its failure in settings requiring low-rank solutions. This insight suggests that optimizer choice should be informed by the structure of the underlying problem and the desired inductive bias. The slow SDE framework offers a unified perspective for analyzing and designing new adaptive optimizers with tailored regularization properties.
Future work should extend the analysis to other scaling regimes (e.g., intermediate $1.5$-scheme), incorporate weight decay, and characterize behavior beyond the local neighborhood of the minimizer manifold. Understanding the interaction between optimizer-induced regularization and architectural choices (e.g., normalization layers, parameter partitioning) remains an open challenge.
Conclusion
This work rigorously establishes that Adam minimizes a unique form of sharpness, tr(Diag(H)1/2), leading to distinct generalization behavior compared to SGD. The slow SDE framework provides a mathematically precise characterization of Adam's adaptive regularization near the minimizer manifold, with concrete separations demonstrated in sparse regression and matrix factorization. These results have direct implications for optimizer selection and the design of future adaptive methods in deep learning.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.