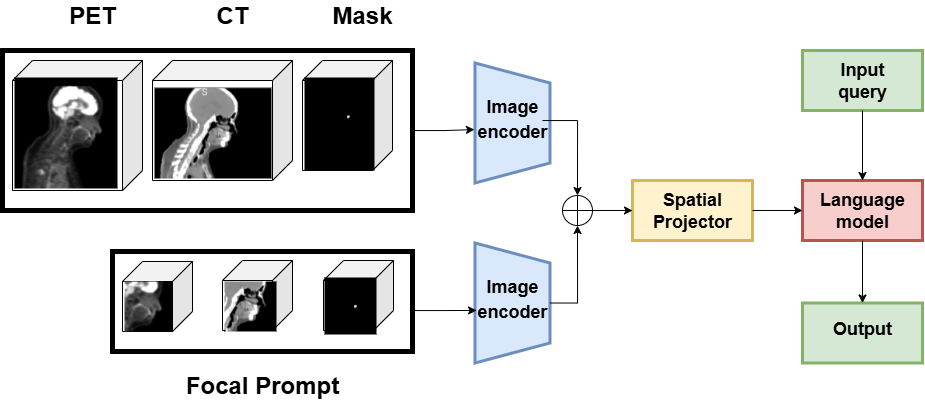
- The paper introduces PETAR, a mask-aware vision-language model that generates fine-grained, spatially grounded reports from 3D PET/CT scans.
- Its methodology integrates lesion segmentation masks with a shared 3D vision transformer, focal prompting, and token fusion to precisely capture lesion features.
- Experimental results demonstrate significant improvements over existing models, with up to 56% gains in key metrics and strong clinical validation.
PETAR: Mask-Aware Vision-Language Modeling for Localized PET/CT Findings Generation
Introduction and Motivation
The PETAR framework addresses the challenge of automated report generation for 3D PET/CT imaging, a domain characterized by high data dimensionality, dispersed small lesions, and complex, lengthy clinical reports. Unlike prior medical VLMs that focus on 2D modalities or mask-agnostic 3D approaches, PETAR introduces explicit mask-aware conditioning, enabling fine-grained, spatially grounded findings generation. The system leverages lesion segmentation masks to guide the model’s attention, facilitating the synthesis of clinically coherent and localized descriptions that reflect both metabolic and anatomical cues.
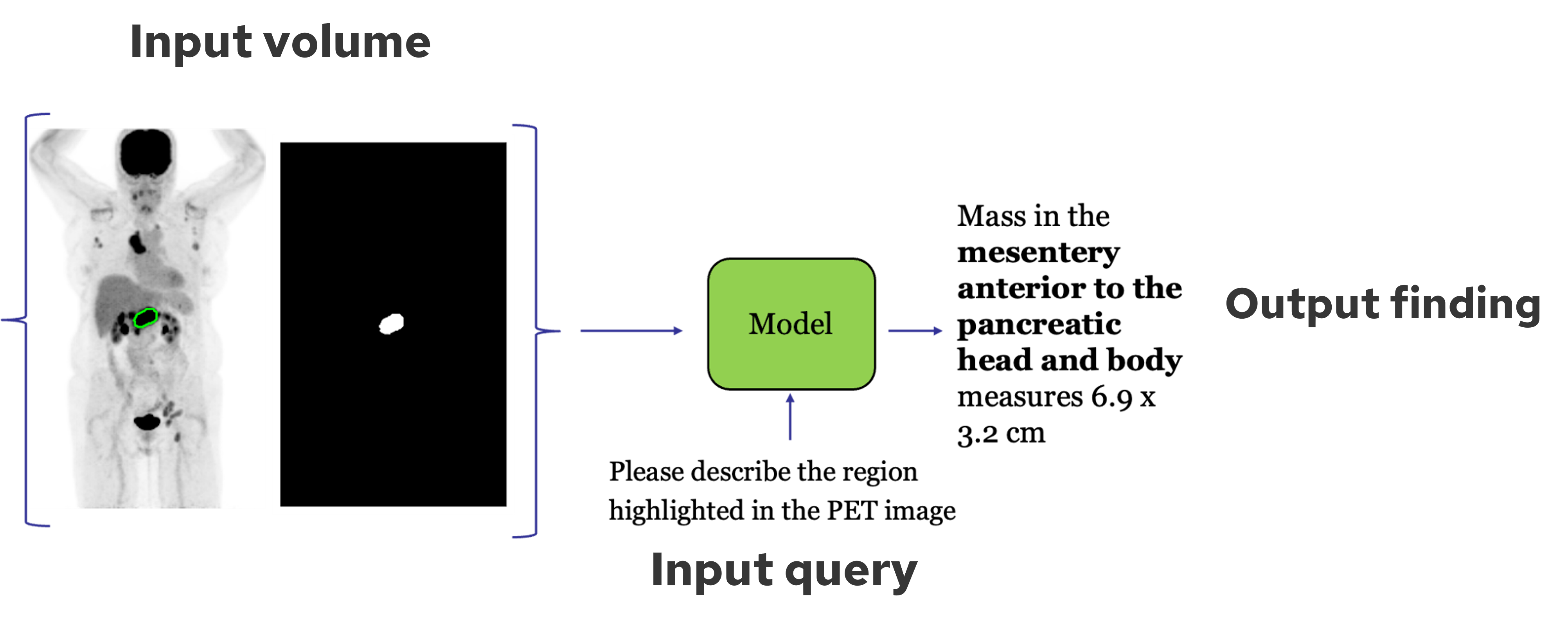
Figure 1: Mask-guided response generation leverages lesion contours to produce spatially grounded findings.
Dataset Construction
PETAR is underpinned by PETAR-11K, a large-scale dataset comprising 11,356 lesion-level descriptions paired with 3D segmentations from over 5,000 PET/CT exams. The dataset was constructed via a hybrid pipeline combining rule-based extraction, RadGraph anatomical term mining, and LLM-based filtering (Mistral-7B-Instruct, Mixtral-8x7B-Instruct, Dolphin-Instruct). Lesion masks are generated using iterative thresholding anchored to reported SUVmax and slice numbers, followed by adaptive refinement to isolate lesion cores. All volumes are resampled to 3 mm isotropic resolution and standardized to 192×192×352 voxels.
To enhance textual consistency and facilitate spatial grounding, lesion descriptions are reformatted using Qwen3-30B-A3B into a structured schema: {region, organ, anatomic subsite, report}. Additionally, TotalSegmentator is applied to CT volumes to generate anatomical segmentations for pretraining, covering 117 classes.
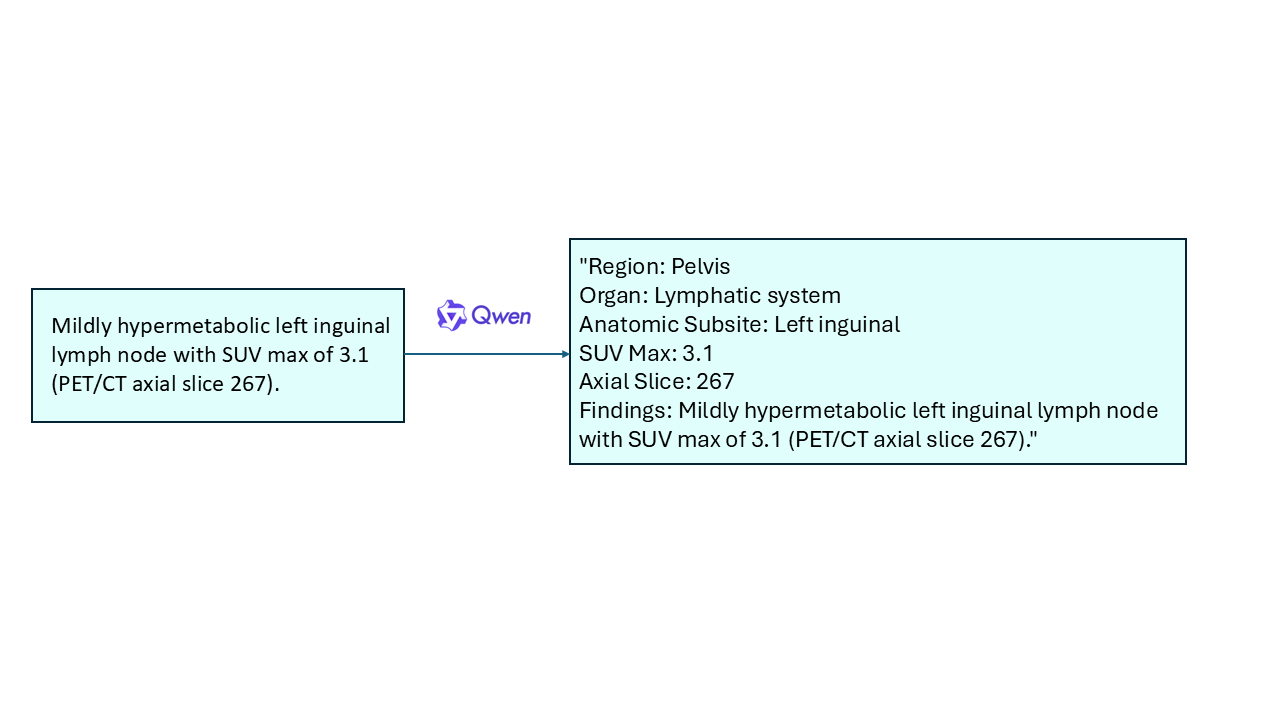
Figure 2: Enhanced data format explicitly links anatomical regions and findings for improved grounding.
Model Architecture
PETAR-4B integrates PET, CT, and lesion mask inputs through a shared 3D vision transformer (M3D-CLIP backbone), followed by token fusion and spatial pooling. The pooled visual tokens are projected into the LLM space and processed by a Phi-3B LLM, which generates lesion-specific reports conditioned on both visual features and textual queries.
Key architectural innovations include:
Training Strategy
A four-stage training pipeline is employed:
- Pretraining: Region classification on TotalSegmentator anatomical masks, framed as text generation.
- Mask Embedding Alignment: Independent training of the mask embedding module for robust mask-to-anatomy correspondence.
- Projector Alignment: Optimization of the projection head to align visual embeddings with the LLM feature space.
- Full Finetuning: End-to-end training on PETAR-11K for lesion-specific report generation.
The training objective is autoregressive negative log-likelihood over the generated report tokens, conditioned on visual inputs and preceding text.
Experimental Results
PETAR-4B is benchmarked against 2D VLMs (InternVL3, Hautuo, MedGemma, Qwen3), 2D mask-aware VLMs (ViP-LLaVA), 3D VLMs (M3D, Med3DVLM, M3D-RAD), and 3D mask-aware VLMs (Reg2RG). Evaluation metrics include BLEU, ROUGE-L, METEOR, CIDEr, BERTScore, BARTScore, RaTEScore, and GREEN.
PETAR-4B achieves the highest scores across nearly all metrics, with notable improvements over the best 2D and 3D baselines:
- BLEU-4: 0.531 (+29% vs. InternVL3)
- ROUGE-L: 0.519 (+46% vs. InternVL3)
- METEOR: 0.557 (+56% vs. InternVL3)
- CIDEr: 0.415 (+0.283 vs. M3D-RAD)
- GREEN: 0.246 (+0.175 vs. M3D-RAD)
Ablation studies confirm the synergistic contribution of mask input, CT modality, and focal prompting, with the full configuration yielding peak performance.
Human Evaluation and Metric Analysis
Two rounds of physician-led evaluation were conducted, assessing interpretation correctness, localization fidelity, and clinical utility. Spearman’s correlation analysis revealed that radiology-specific semantic metrics (GREEN, ROUGE, RaTEScore) align most strongly with expert judgment, validating their use for clinical report generation tasks.
Qualitative Analysis
PETAR-4B produces clinically coherent, spatially grounded findings that accurately reflect lesion characteristics and anatomical context. Comparison with the next best model demonstrates superior localization and descriptive precision.

Figure 4: PETAR-4B generates more accurate and localized findings compared to competing models.
Practical and Theoretical Implications
PETAR establishes a new paradigm for automated PET/CT reporting by explicitly linking lesion segmentation masks to descriptive findings. The mask-aware architecture enables integration with upstream lesion detection models or manual ROI selection, facilitating automated measurement extraction (size, SUV) and report population. The structured approach supports downstream impression generation and templated reporting via LLMs.
Theoretically, PETAR demonstrates the efficacy of mask-guided volumetric reasoning for fine-grained medical captioning, suggesting broader applicability to other 3D modalities and multi-lesion scenarios. The dataset and benchmark (PETAR-Bench) provide a foundation for reproducible evaluation and future research in localized medical VLMs.
Future Directions
Potential extensions include:
- Integration with FDA-cleared lesion segmentation tools for seamless clinical deployment.
- Expansion to additional radiotracers and multi-organ PET/CT datasets.
- Development of impression generators and full-report synthesis pipelines.
- Exploration of multi-lesion and temporal tracking for longitudinal studies.
Conclusion
PETAR introduces a mask-aware, multimodal vision-language framework for PET/CT report generation, supported by the first large-scale, lesion-level PET/CT dataset. The model achieves state-of-the-art performance in both automated and human evaluations, demonstrating robust alignment with clinical expert judgment and setting a new standard for localized findings generation in 3D medical imaging.