Sketch-to-Layout: Sketch-Guided Multimodal Layout Generation
Abstract: Graphic layout generation is a growing research area focusing on generating aesthetically pleasing layouts ranging from poster designs to documents. While recent research has explored ways to incorporate user constraints to guide the layout generation, these constraints often require complex specifications which reduce usability. We introduce an innovative approach exploiting user-provided sketches as intuitive constraints and we demonstrate empirically the effectiveness of this new guidance method, establishing the sketch-to-layout problem as a promising research direction, which is currently under-explored. To tackle the sketch-to-layout problem, we propose a multimodal transformer-based solution using the sketch and the content assets as inputs to produce high quality layouts. Since collecting sketch training data from human annotators to train our model is very costly, we introduce a novel and efficient method to synthetically generate training sketches at scale. We train and evaluate our model on three publicly available datasets: PubLayNet, DocLayNet and SlidesVQA, demonstrating that it outperforms state-of-the-art constraint-based methods, while offering a more intuitive design experience. In order to facilitate future sketch-to-layout research, we release O(200k) synthetically-generated sketches for the public datasets above. The datasets are available at https://github.com/google-deepmind/sketch_to_layout.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
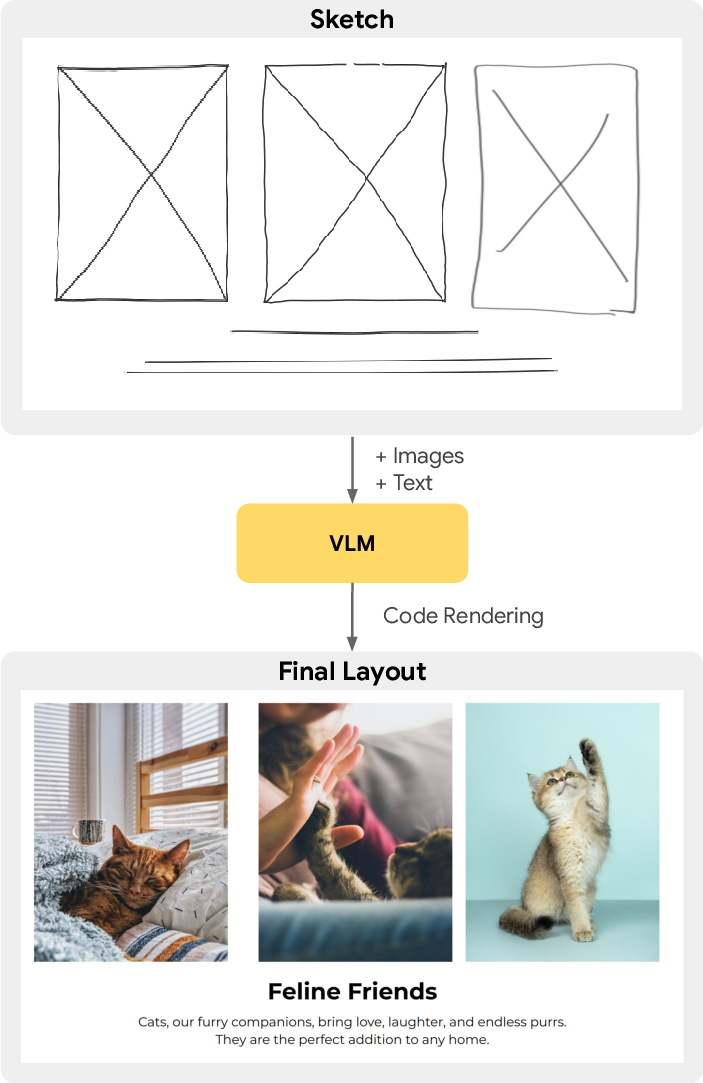
This paper shows a new, simple way to design page layouts (like posters, slides, or documents) using quick sketches. Instead of typing long, detailed instructions, a person can draw a rough sketch that shows where text and pictures should go. An AI model then turns that sketch plus the actual content (the real text and images) into a neat, finished layout.
What questions did the researchers ask?
- Can quick hand-drawn sketches guide an AI to make good-looking, accurate layouts?
- Is sketching faster and easier for people than writing complicated rules or descriptions?
- Can we train an AI to understand sketches without collecting tons of expensive human-drawn data?
- Does giving the AI the real content (the actual text and images) help it make better layouts and reading order?
How did they do it?
The team treats layout design like writing a blueprint instead of painting a picture.
Using sketches as instructions
A sketch is a simple drawing that shows:
- Where big blocks of text and images should go,
- About how big they should be,
- The rough structure of the page.
This is how many designers already start their work, so it feels natural.
The AI model they trained
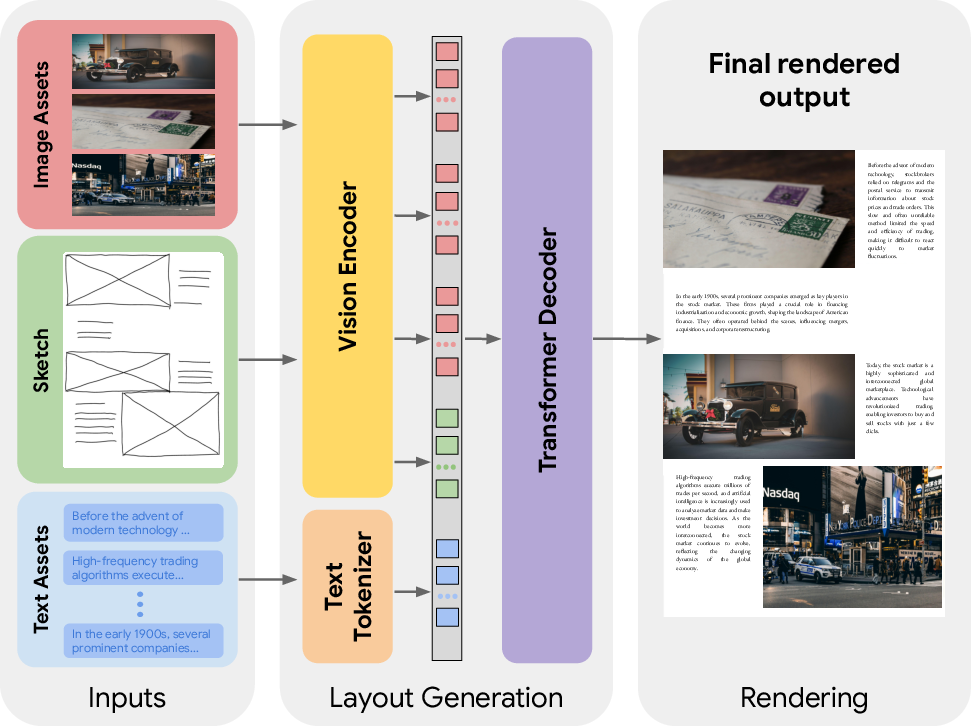
They fine-tuned a Vision-LLM (VLM) called PaLI-Gemma 3B. Think of a VLM as an AI that can both “look” (at images) and “read” (text). It takes:
- The hand-drawn sketch (as an image),
- The actual images and text you want on the page,
- A short text prompt with basic details (page size, asset names, etc.), and outputs a structured layout description (like a clean list of where everything should go), not just a picture. This structured output is like a recipe or blueprint that can be easily checked, edited, and turned into a final layout image.
Making lots of training sketches (synthetic data)
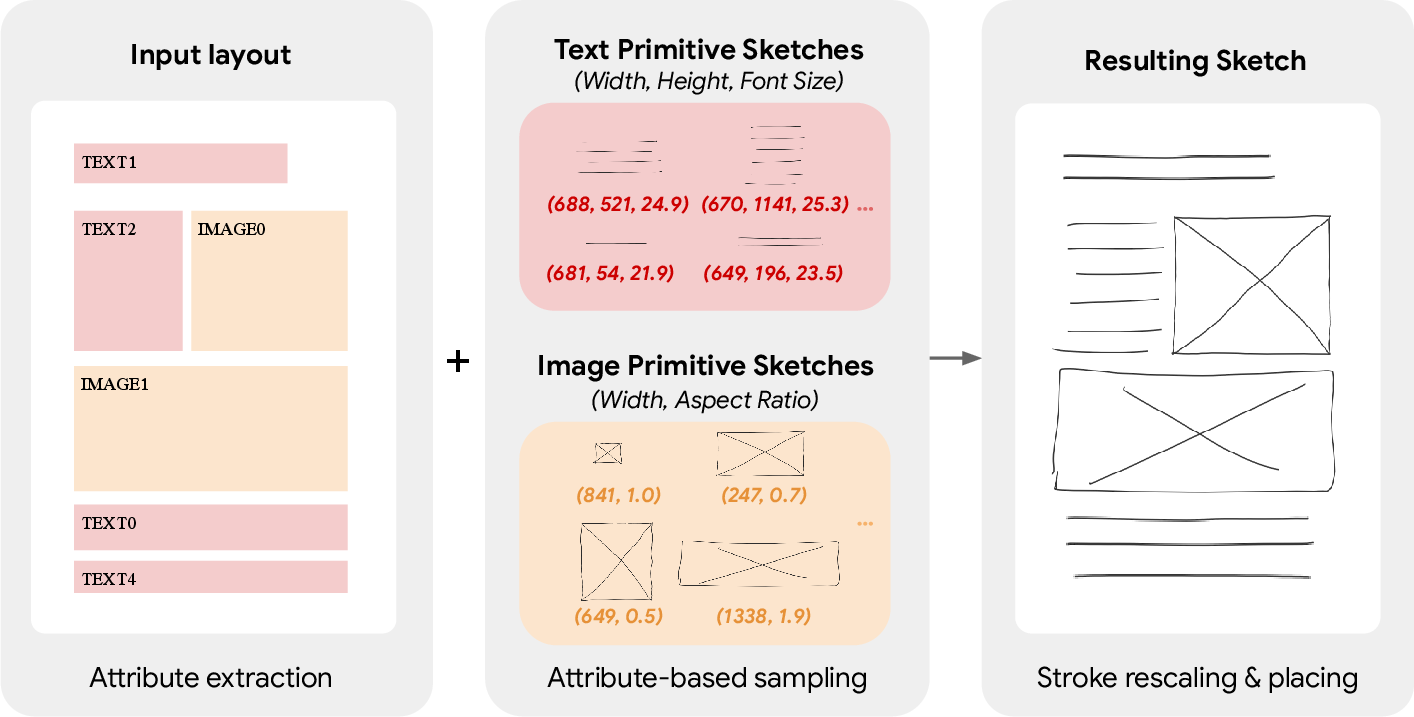
Collecting thousands of real sketches is slow and expensive. So the team invented a smart shortcut:
- First, they asked a few people to draw tiny “primitives” (simple sketch symbols) for text blocks and images, like crossed boxes for pictures and lines for text.
- Then, for each real layout in public datasets, they automatically matched each element to a similar primitive and pasted them together to “compose” a full sketch.
- This let them build about 200,000 sketch–layout pairs quickly.
This method keeps the human effort small but creates a huge training set.
How they judged success
They used simple ideas to measure how close the AI’s layout is to the ground truth:
- Intersection over Union (IoU): Imagine two rectangles. IoU measures how much they overlap. Higher is better.
- Maximum IoU (mIoU): Finds the best possible pairing between the AI’s boxes and the real boxes and measures overlap. Higher is better.
- Content Ordering Score (COS): Checks if the reading order (top-to-bottom, left-to-right) of items is preserved. Higher means the layout flows like the original.
- Overlap and Alignment: Check if elements overlap too much or line up nicely. Lower overlap is better; alignment depends on the design but is tracked.
They tested on three public datasets: PubLayNet, DocLayNet, and SlidesVQA.
What did they find?
Here are the main takeaways from their experiments:
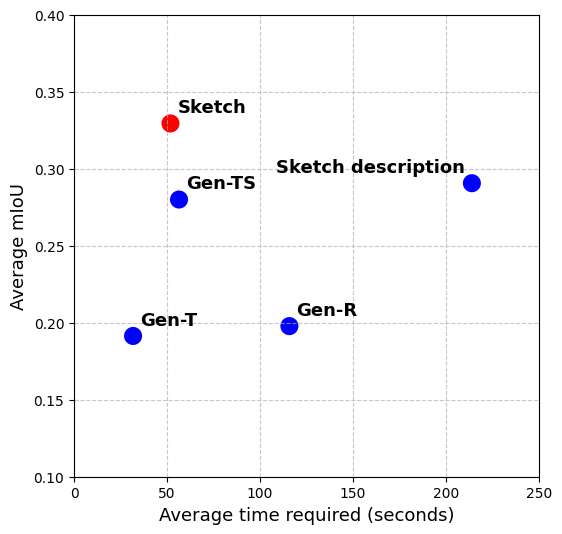
- Sketches are both faster and better than typing rules:
- Drawing a quick sketch took less time and led to better layouts than writing detailed, technical text constraints.
- Their fine-tuned model beat strong baselines by a lot:
- Compared to methods that use typed rules or few-shot prompting with a powerful general model, the sketch-guided model did much better, especially on mIoU (over 40% improvement in many cases).
- It placed items where the sketch suggested and produced layouts that looked like the real ones.
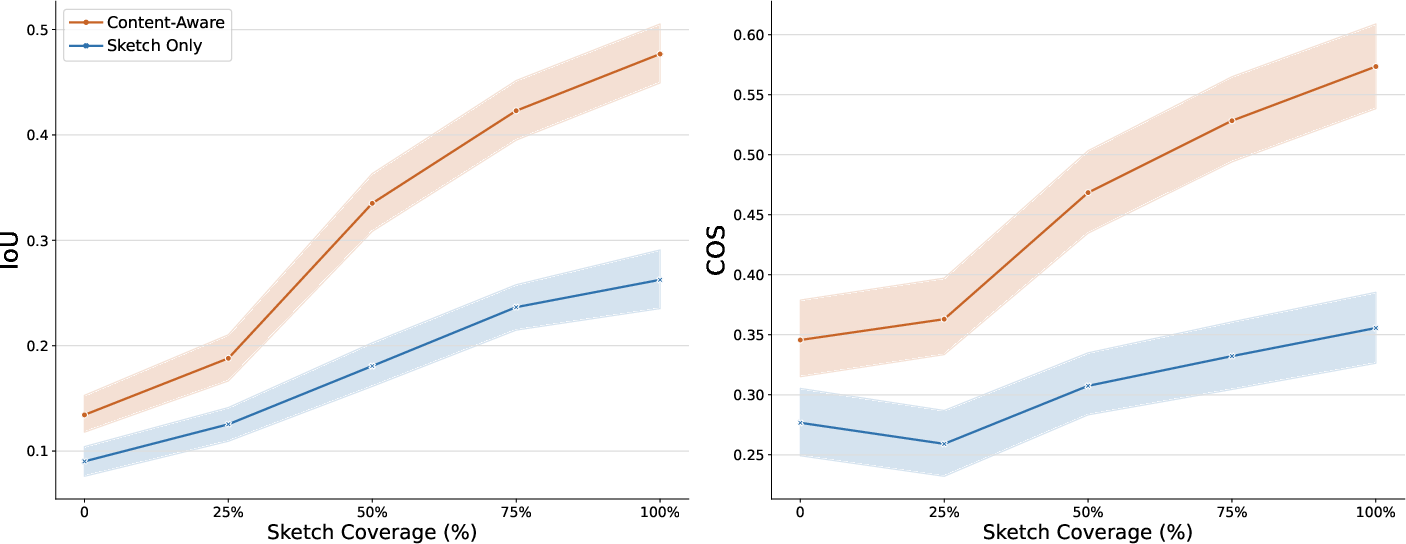
- Content-awareness helps:
- When the model saw the actual images and text, it did better on both placement (IoU/mIoU) and reading order (COS) than when it only saw the sketch.
- Synthetic sketches work almost as well as real human sketches:
- Models trained on composed (synthetic) sketches performed similarly when tested on real human-drawn sketches. That means the synthetic data is a reliable stand-in and saves a lot of human effort.
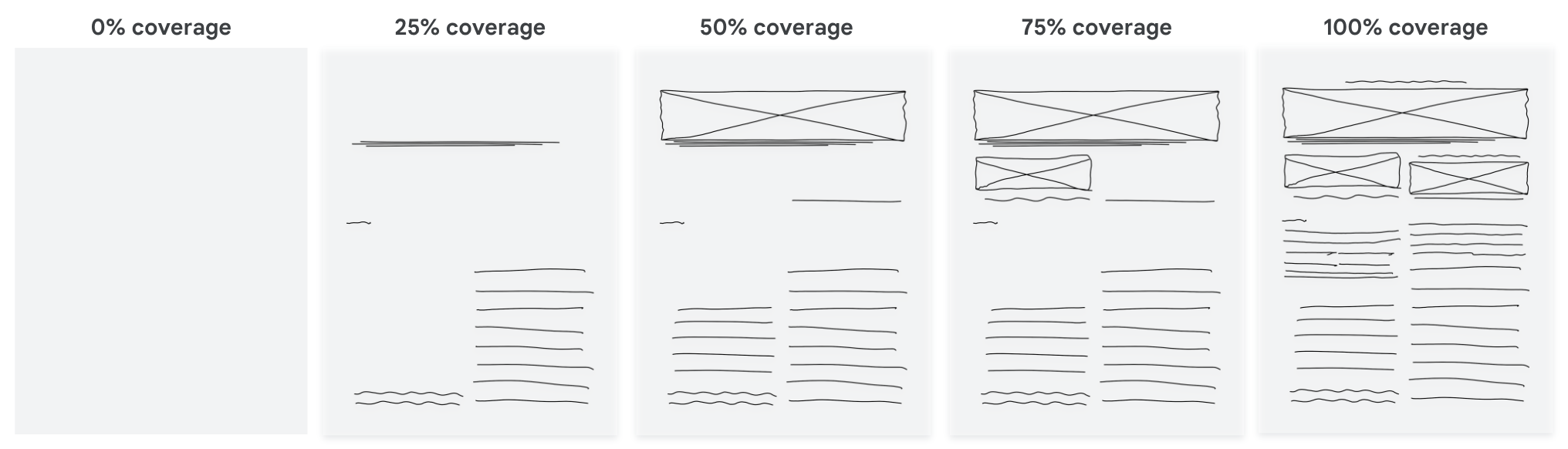
- Partial sketches still guide the model:
- Even if the sketch only shows some elements (not all), performance improves as the sketch covers more of the page. More sketch coverage = better results.
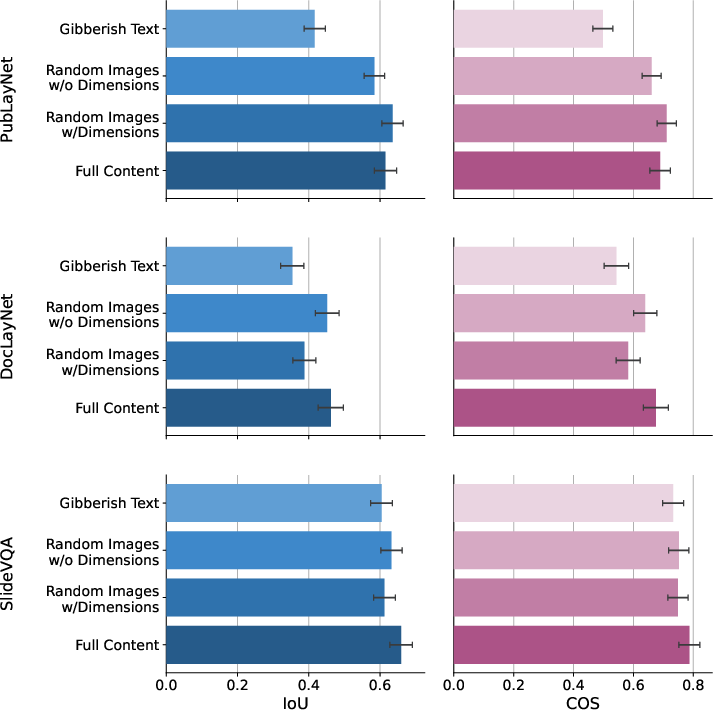
- The model isn’t just “cheating” with shortcuts:
- They tested “gibberish text” and “random images” to see if the model relied on lazy tricks (like text length). The content-aware benefits remained, suggesting the model truly uses content in a meaningful way, though placing a single image is often easy even without its pixels.
Why does it matter?
- Easier design tools: Sketching is natural and fast. This approach could make layout design tools more intuitive for everyone, not just experts.
- Faster from idea to draft: You can quickly sketch what you want and let the AI do the heavy lifting to produce a clean layout.
- Better content flow: Because the model “sees” the real text and images, it can arrange elements in a logical reading order.
- Scalable training: Their synthetic-sketch trick means researchers and companies can train similar systems without massive, costly human sketch collections.
- Community resources: They’re releasing about 200,000 synthetic sketches for public datasets to help others build on this work.
In short, this research shows that “sketch-to-layout” is a practical, powerful way to control AI layout generation: it’s intuitive for users, improves quality, and can be trained at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper, organized as a single list with brief topical cues.
- Data coverage and sketch diversity: The synthetic sketch pipeline relies on only 237 training primitives from 10 annotators and two asset types (text/image). It is unclear how well the model generalizes to broader sketching styles (e.g., varied stroke weights, clutter, scribbles, arrows, annotations), complex wireframing conventions, or additional asset types (tables, charts, lists, decorative shapes, backgrounds).
- Generalization beyond three datasets: All experiments target document/slide datasets (PubLayNet, DocLayNet, SlidesVQA). The method’s robustness for visually richer domains (posters, magazines, web/mobile UI, infographics) and very different aesthetic norms remains untested.
- Reading order and language coverage: The Content Ordering Score (COS) assumes left-to-right, top-to-bottom reading; no evaluation on right-to-left (Arabic/Hebrew), vertical scripts (CJK), or mixed scripts. How to generalize COS and model behavior across languages and reading directions is open.
- Real sketch fidelity vs synthetic sketches: Although performance is “comparable,” human test sets are small (≈250 samples per dataset). There is no analysis of inter-annotator variability, sketch style distribution, or failure cases where synthetic sketches diverge from realistic hand sketches (e.g., noisy strokes, misalignments, incomplete boxes).
- Limited asset taxonomy: The approach models only bounding boxes for text/images. It does not address tables, multi-column text flows, graphs, captions, footnotes, callouts, z-order layering, groups, or typography-level attributes (fonts, line breaks, ragging, kerning).
- Incomplete content-use evidence: Content ablations suggest limited benefit from images (especially when there is only one image). There is no thorough analysis of whether and when image or text semantics influence placement (e.g., face/subject saliency, text length/semantics, semantic grouping).
- Weak binding between assets and geometry: The model consumes multiple images plus a textual prompt, but the mechanism to reliably bind each asset (image/text) to its corresponding generated box is under-specified and not explicitly evaluated (e.g., ID mismatches, duplicate/missing assets).
- No hard-constraint satisfaction guarantees: Although structured outputs reduce hallucinations, the paper does not quantify constraint violations (missing/extra assets, invalid geometry, overlaps beyond tolerance). There is no constrained decoding or grammar-check that guarantees correctness.
- Metric limitations and missing user studies: IoU/mIoU and Alignment/Overlap may not capture aesthetic quality, usability, or designer preferences. COS is geometric and order-based, not semantic. No human preference studies, designer evaluations, or perceptual metrics (balance, rhythm, white space, visual hierarchy) are reported.
- Missing “sketch fidelity” metric: There is no direct quantitative measure of how faithfully the generated layout follows the sketch structure (e.g., distance between sketched strokes and final boxes, stroke-to-box alignment metric).
- Baseline comparability: The proposed method is fine-tuned, while baselines are few-shot prompted; this is not an apples-to-apples comparison. It remains open whether fine-tuning alternative baselines or stronger multimodal models would close the gap.
- Scalability and model size: Only PaLI Gemma 3B is tested. It is unknown how performance scales with larger VLMs, more training data, or different pretraining (e.g., multi-image pretraining), nor are there data/model scaling laws.
- Interactive design loop: Partial sketches are simulated by random masking, not by iterative user sessions. The system’s responsiveness, latency, and behavior under real-time sketch refinement (add/erase strokes, repositioning) are not studied.
- Robustness to sketch noise and domain shifts: There is no stress testing for noisy inputs (overlapping strokes, occlusions, jittery strokes, variable pen widths/colors, background clutter), extreme aspect ratios, rotated canvases, multi-page documents, or out-of-distribution asset counts.
- Synthetic sketch generator limitations: KNN selection on size/aspect ratio and simple rescaling cannot model realistic stroke dynamics (pen pressure, jitter), composition errors, or non-rectilinear hints (arrows/grouping brackets). The effect of the number/diversity of primitives on performance is not ablated.
- Multi-image reasoning: The model was not pretrained on multiple uncorrelated images, and the paper notes difficulty in learning this during short fine-tuning. An open question is how to better pretrain or architect models for multi-image grounding and content-aware placement.
- Constraint types beyond geometry: The method does not incorporate explicit constraints such as alignment rules, grid systems, non-overlap with tolerances, margins, or proportion constraints. How to encode and satisfy such constraints at training/inference time is unresolved.
- Output schema robustness: Protocol buffer output is convenient, but there is no study of robustness to schema evolution, long sequences (many elements), or error recovery (e.g., partial decoding, auto-fixers for invalid fields).
- Error analysis and failure modes: The paper lacks a systematic categorization of typical errors (e.g., swapped assets, drift from sketch, crowding, overlap) and actionable insights for mitigation (e.g., loss terms, constrained decoding, post-processing).
- Multi-page and temporal consistency: The approach is evaluated on single pages/slides. There is no method for multi-page documents or maintaining global consistency (headers/footers, recurring elements, cross-page alignment).
- Resource and deployment constraints: Inference-time costs, latency, and memory footprint are not reported. The feasibility of on-device or real-time deployment—and the trade-offs with model size/precision—remains open.
- Privacy and data pipeline integration: Realistic workflows require OCR/asset extraction and content sanitization; the paper assumes text and image assets are available and clean. The impact of OCR errors or noisy asset extraction on layout quality is not studied.
- Aesthetic/style controllability: There is no mechanism for controlling style (minimalist, grid-heavy, editorial, playful), color palettes, or alignment preferences. How to condition layouts on style descriptors or reference designs remains unaddressed.
- Reproducibility and releases: Only synthetic sketches are released. It is unclear whether code, trained checkpoints, prompts, and evaluation scripts will be released to ensure reproducibility and fair comparison.
- Safety, bias, and fairness: Datasets are academic/document-heavy and may bias learned layouts toward certain conventions. There is no analysis of bias, accessibility (e.g., readability constraints), or safety considerations (e.g., avoiding tiny text or low contrast placements).
- Training objectives: The model is trained with a pure language modeling objective; no auxiliary losses target overlap minimization, alignment, or sketch adherence. Exploring multi-objective training or differentiable constraint penalties is an open direction.
- Ambiguity handling: Real sketches can be underspecified or contradictory relative to assets. There is no strategy for uncertainty modeling, multiple diverse candidates, or interactive disambiguation.
- Data efficiency: The paper shows synthetic data helps, but does not quantify how performance scales with the number/diversity of primitives, the ratio of synthetic to human sketches, or semi-supervised/self-training regimes.
Practical Applications
Immediate Applications
These applications can be prototyped and deployed now using the paper’s released datasets (∼200k synthetic sketches), the PaLI-Gemma 3B fine-tuning approach, the structured (protobuf→SVG) layout representation, and the demonstrated sketch-guidance workflow.
- Sketch-to-Layout plugins for design tools (Software, Marketing/Advertising, Publishing)
- What: Generate high-quality, editable layouts from rough ink sketches and content assets within tools like Figma, Adobe XD/InDesign, Canva.
- Workflow: User draws a quick wireframe → drops in text/images → model outputs an editable, structured layout (SVG/JSON/protobuf) → designer iterates.
- Potential tools/products: “Sketch-to-Layout” plugin; auto-layout assistant panel; layout generator API inside creative suites.
- Assumptions/Dependencies: Integration with design tool APIs; small on-domain fine-tune may be needed for brand-specific element types; user sketch capture (stylus/camera) available.
- “Draw-to-Slide” presentation assistant (Education, Enterprise Productivity)
- What: Convert a hand-drawn slide plan into a polished slide with content-aware placements in Google Slides, PowerPoint, Keynote.
- Workflow: Instructor/student sketches structure on tablet or whiteboard (photo capture) → select assets → slide is auto-composed with reading order preserved (COS-aware).
- Assumptions/Dependencies: Connector to slide templates/themes; in-app sketch canvas or camera capture; optional school-specific templates for best results.
- Email and landing page layout generator (MarTech, E-commerce)
- What: Turn a wireframe sketch + asset list into responsive email or hero landing section variants for campaigns.
- Workflow: Marketer sketches sections (hero, product grid, CTA) → uploads assets → exporter renders HTML/CSS modules or CMS blocks.
- Potential products: Mailchimp/Braze/HubSpot add-ons; Shopify/WooCommerce section generator.
- Assumptions/Dependencies: Exporters to HTML/CSS/module systems; responsive rules; brand token mapping.
- Fast document and report layouting (Publishing, Finance, Energy, Enterprise Docs)
- What: Auto-compose memos, reports, and one-pagers from a sketch and asset list (charts, tables, images).
- Workflow: Analyst sketches page structure → links content (tables/images) → outputs structured layout convertible to PDF/HTML.
- Assumptions/Dependencies: Extend primitive set to include tables/charts; domain schema for structured content.
- Accessible reading-order QA and remediation using COS (Policy/Government, Accessibility, Enterprise Compliance)
- What: Use the paper’s Content Ordering Score (COS) as an automated check for reading order and narrative flow.
- Workflow: Generate layouts → compute COS vs. target reading order → flag problematic pages → remediation suggestions (e.g., reorder blocks).
- Potential tools: Accessibility QA plugin for InDesign/Acrobat; CI checks for publishing pipelines.
- Assumptions/Dependencies: Ground-truth or policy-defined reading order; integration with accessibility standards (WCAG/PDF/UA).
- A/B testing of layout variants from a single sketch (Marketing/Advertising)
- What: Generate multiple, controlled layout variants (e.g., spacing, hierarchy) from the same sketch and content for experimentation.
- Workflow: Single sketch → N layout variants → export to CMS/email → measure performance.
- Assumptions/Dependencies: Variant generation settings; connection to experimentation platforms.
- Synthetic sketch data generation for model training (Academia, Software)
- What: Use the primitive-composition pipeline to cheaply create large training sets for document/GUI layout tasks and reduce labeling cost.
- Workflow: Collect a small set of primitives → compose synthetic sketches at scale over existing labeled layouts → fine-tune VLMs or detectors.
- Assumptions/Dependencies: Minimal primitive collection for each new domain (e.g., charts, UI widgets); quality control to avoid domain shift.
- Rapid UX wireframe-to-hi-fi transition (Software, Product Design)
- What: Transform whiteboard or tablet wireframes into initial hi-fi layouts using real assets during design sprints.
- Workflow: Photo/ink capture → content-aware layout generation → designer refines and applies design system tokens.
- Assumptions/Dependencies: Good photo preprocessing for whiteboard sketches; mapping to design system components.
- Consumer templates from sketches (Daily Life)
- What: Generate flyers, resumes, invitations from a drawn layout skeleton and content.
- Workflow: Draw sections on phone/tablet → fill text/images → export printable or shareable design.
- Assumptions/Dependencies: Lightweight mobile app; prebuilt style presets; content privacy safeguards.
- Benchmarking and curriculum resources (Academia)
- What: Use released data and COS to build assignments and benchmarks for courses in HCI, CV, and document intelligence.
- Workflow: Students train/fine-tune layout models; compare sketch-guidance vs. textual constraints; assess with mIoU/COS.
- Assumptions/Dependencies: Course infra (compute); dataset licensing adherence.
Long-Term Applications
These require further research, scaling, domain adaptation, or productization (e.g., richer primitives, multi-page documents, brand/style conditioning, stronger multi-image reasoning).
- Brand-, style-, and compliance-aware auto-layout across channels (Marketing, Enterprise, Policy/Government)
- What: Generate on-brand, policy-compliant layouts (logo safe zones, disclaimers, accessibility) for print, web, and mobile from a single sketch.
- Potential workflows: Ingest brand guides → learn brand/style embeddings → enforce constraints during generation (color contrast, legal text placement).
- Dependencies: Robust constraint satisfaction during decoding; policy/brand rule engines; evaluation beyond IoU/COS (contrast, spacing, brand KPIs).
- Multi-page and responsive document assembly (Publishing, Enterprise, Education)
- What: From a single sketch for a section or TOC, generate coherent multi-page documents and responsive variants (desktop/tablet/mobile).
- Dependencies: Pagination and cross-page flow modeling; responsive rules; long-context VLMs; table/figure indexing; dynamic reflow.
- Sketch-to-code for production UIs (Web/App, Software)
- What: Produce maintainable, accessible code (HTML/CSS/React/Flutter) from a sketch + content, preserving reading order and hierarchy.
- Products: “Sketch-to-React” or “Sketch-to-Flutter” pipelines; GUI builders powered by content-aware generation.
- Dependencies: Richer element taxonomy (forms, nav, modals); accessibility/lighthouse checks; design system bindings; testable layouts.
- Localization- and culture-aware layout adaptation (Publishing, Global Marketing, Public Health)
- What: Automatically adapt layout for right-to-left scripts, different typographic conventions, and cultural norms from the same sketch.
- Dependencies: Language-aware reading order and typographic models; culturally appropriate templates; region-specific compliance rules.
- Real-time co-creative assistants with on-canvas constraints (Software, Education)
- What: Live, incremental layout refinement as users draw/edit constraints (e.g., drag boundaries, scribble arrows to indicate relationships).
- Dependencies: Low-latency inference; incremental decoding; stable behavior under partial/ambiguous sketches; UI for constraint editing.
- Domain-specialized layout systems (Healthcare, Finance, Legal, Energy)
- Healthcare: Patient education leaflets and discharge summaries with guaranteed reading order and high legibility.
- Finance/Energy: Auto-assembled dashboards and regulatory reports with strict placement of risk disclosures/metrics.
- Legal: Briefs/contracts with standardized section ordering and citation blocks.
- Dependencies: Domain-specific primitives (tables, charts, forms), strict compliance constraints, human-in-the-loop review.
- Standardized layout interchange and evaluation (Industry consortia, Policy)
- What: Establish a neutral structured schema (e.g., protobuf/JSON) and common metrics (including COS) for layout interoperability and quality assurance.
- Impact: Easier vendor integration, reproducible benchmarks for government and enterprise procurement.
- Dependencies: Stakeholder alignment; reference implementations; governance and conformance testing.
- Enhanced multi-image reasoning and content semantics (Research, Software)
- What: Robust placement decisions informed by multiple images’ semantics (saliency, relationships, captions) to improve complex layouts (magazines, catalogs).
- Dependencies: Pretraining on multi-image inputs; joint text–vision reasoning; richer training datasets beyond single-image cases.
- Accessibility-first layout generation (Policy, Education, Public Sector)
- What: Generation that optimizes for readability (e.g., dyslexia-friendly spacing, font choices), screen reader order, and contrast by design.
- Dependencies: Expanded metrics beyond COS (contrast, font size, line length); user studies; integration with assistive tech.
- Whiteboard-to-document pipeline for field teams (Public Sector, NGOs, Enterprise)
- What: Capture sketches in the field (paper/whiteboard photos) and convert to ready-to-publish leaflets, posters, or field reports.
- Dependencies: Robust image preprocessing (de-skew, denoise); offline/on-device inference; data privacy/security.
Notes on Feasibility and Dependencies (cross-cutting)
- Model and data
- Domain adaptation: For new sectors (e.g., medical forms, complex tables), collect a small primitive set and fine-tune on representative layouts.
- Multi-image/generalization limits: Current results are strongest with few images per page; improved pretraining may be needed for complex image sets.
- Data privacy/IP: Enterprise deployments must ensure content and brand assets are handled securely.
- Integration and standards
- Structured output: The protobuf→SVG pipeline eases interoperability, but standardization across vendors will accelerate adoption.
- Human-in-the-loop: Production use (especially regulated domains) should keep review/approval steps.
- UX and adoption
- Input ergonomics: Best results require reliable sketch capture (stylus/tablet or high-quality photo).
- Training: Users may need light guidance on drawing effective primitives for desired outcomes.
These applications leverage the paper’s core innovations: sketch-as-constraint for superior time–performance trade-offs; a scalable synthetic sketch pipeline for training; content-aware generation via a multimodal VLM; structured, code-like layout outputs for editability; and COS for assessing narrative/reading order.
Glossary
- Alignment: A metric assessing how well elements are visually aligned in a layout. "Alignment~\cite{li2020attributeconditionedlayoutganautomatic} measures the graphical alignment for the layout."
- Aspect ratio: The proportional relationship between an element’s width and height. "uses the area, aspect ratio and reading-order of the input elements as the input constraints."
- Auto-regressive transformer: A transformer that generates sequences by predicting each token conditioned on previous ones. "propose an auto-regressive transformer to frame layout generation as a sequence-to-sequence task"
- Beautification constraints: Design rules (e.g., alignment, non-overlap) used to improve aesthetic quality. "can additionally take beautification constraints, such as alignment and non-overlap."
- BERT: A bidirectional transformer LLM used here to encode text. "and BERT \cite{devlin2019bertpretrainingdeepbidirectional} to encode input images and texts."
- CLIP: A model for joint image–text representation learning used to embed multimodal features. "uses CLIP to embed textual and visual features."
- CNN-LSTM-based-GAN: A generative adversarial architecture combining CNNs and LSTMs for layout tasks. "such as CNN-LSTM-based-GAN \cite{hsu2023posterlayout}"
- Code generation (formulation): Casting layout generation as producing structured code that specifies elements. "we formulate the sketch-to-layout problem as a code generation task."
- Content-aware: Incorporating the actual asset content (text/images) into layout generation decisions. "As we claim our approach is content-aware, it is necessary to introduce metrics measuring this awareness"
- Content Ordering Score (COS): A metric based on sequence edit distance that evaluates whether the generated layout preserves the intended reading order. "We introduce Content Ordering Score (COS), a new metric inspired by the order loss \cite{li2020attributeconditionedlayoutganautomatic}, designed to assess the content-awareness of a generated layout."
- Decoder-only transformer: A transformer architecture consisting solely of a decoder stack, often for generation. "Gemma \cite{gemma}, a decoder-only transformer pre-trained on code generation tasks."
- DETR: A transformer-based object detection model leveraged for layout element placement. "uses an object detection transformer model (DETR\cite{carion2020end}) to guide the generation"
- Diffusion models: Generative models that iteratively denoise samples to produce data like layouts. "Later work using diffusion models \cite{Inoue_2023_CVPR, cheng2023playparametricallyconditionedlayout}"
- Euclidean distance: A geometric distance measure used here to match assets to sketch primitives. "closest in terms of euclidean distance computed on the standardized width and aspect ratio for images"
- Few-shot prompting: Guiding a large model with a small number of in-context examples. "We use a few-shot (=32) prompted Gemini 1.5 Pro~\cite{gemini15multimodal}"
- GANs: Generative Adversarial Networks used for synthesizing layouts. "including image generation methods such as GANs \cite{li2020layoutgan,Kikuchi_2021}"
- Gemma: A decoder-only transformer backbone used for code-style generation. "The language backbone of the architecture consists of Gemma \cite{gemma}, a decoder-only transformer pre-trained on code generation tasks."
- Gemini 1.5 Pro: A large multimodal model used as a strong few-shot baseline. "we substitute it with a few-shot prompted Gemini 1.5 Pro~\cite{gemini15multimodal}"
- Graph-based model: A method that represents and reasons over relational constraints via graphs. "models the relationships using a graph-based model."
- Grid-based guidelines: Predefined grid constraints that guide element positioning in layouts. "grid-based guidelines \cite{cheng2023playparametricallyconditionedlayout}"
- Intersection over Union (IoU): The area overlap metric between predicted and ground-truth boxes. "Intersection over Union (IoU) and Maximum Intersection Over Union (mIoU) \cite{Kikuchi_2021}."
- LLM: A high-capacity LLM used for layout reasoning/generation. "LLM-based methods \cite{tang2023layoutnuwa, lin2024layoutprompter, yang2024posterllava}."
- Levenshtein Distance: An edit distance metric used to compare reading-order sequences. "leveraging the Levenshtein Distance~\cite{levenshteindistance} to measure if the ground truth reading order and narrative flow are preserved"
- Maximum Intersection over Union (mIoU): Best possible IoU under optimal matching between predicted and reference elements. "We evaluate performance using the maximum Intersection over Union (mIoU), i.e. the largest possible IoU"
- Multimodal: Involving multiple input modalities, such as text and images, in a single model. "we propose a multimodal transformer-based solution using the sketch and the content assets as inputs"
- Order loss: A loss function from prior work related to preserving order, used here as inspiration for COS. "a new metric inspired by the order loss \cite{li2020attributeconditionedlayoutganautomatic}"
- Overlap: A metric quantifying how much generated elements undesirably overlap. "Overlap~\cite{li2020attributeconditionedlayoutganautomatic} measures the percentage of overlap between generated assets."
- PaLIGemma 3B: An open-source vision-LLM fine-tuned for sketch-to-layout. "we use PaLIGemma 3B \cite{beyer2024paligemmaversatile3bvlm} as an example open-source VLM."
- Patch embeddings: Fixed-size representations of image patches produced by a vision transformer. "the patch embeddings are concatenated."
- Protocol buffer: A structured serialization format used to represent layouts as code. "Layouts are encoded as protocol buffer strings \cite{protobuf}, with attributes describing the position of assets and their properties."
- Reading order: The intended sequence in which content should be consumed (e.g., top-to-bottom, left-to-right). "Assets should have consistent semantic relationships such as an engaging reading order."
- Saliency map: A heatmap highlighting important regions, used to guide composition. "leverages its saliency map to guide the generation process."
- Sequence-to-sequence task: A mapping from input sequences to output sequences, used to model layout generation. "frame layout generation as a sequence-to-sequence task"
- SVG: A vector graphics format to which structured layouts can be converted for rendering. "allows for straightforward conversion to SVG and therefore image rendering."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs. "Our VLM-based approach is general and applicable to any VLM."
- Vision Transformer (ViT): A transformer-based vision backbone operating on image patches. "the ViT \cite{dosovitskiy2020image} serves as a feature extractor"
- Wireframing: A schematic sketching technique for outlining layout structure. "Inspired by wireframing, we defined primitives for image and text elements"
Collections
Sign up for free to add this paper to one or more collections.

