- The paper introduces a hybrid protocol that leverages dynamically transmitted Rateless Bloom Filters to reduce false positives in set reconciliation.
- It integrates IBLTs for precise element decoding, cutting communication costs by up to 20% in moderate to high similarity scenarios.
- The study demonstrates practical applicability for synchronizing variable-sized elements in distributed systems with large differences.
Rateless Bloom Filters: Set Reconciliation for Divergent Replicas with Variable-Sized Elements
Introduction
The set reconciliation problem, crucial in distributed systems, involves two replicas, each holding a set of elements. The goal is efficient communication to synchronize these sets, revealing differences and merging them to form a complete union. Traditional set reconciliation methods often assume fixed-size elements and small difference cardinalities, which limit their application in real-world scenarios involving variable-sized elements and larger differences. This paper introduces a solution that leverages a hybrid protocol involving Rateless Bloom Filters (RBFs) and Invertible Bloom Lookup Tables (IBLTs), designed to efficiently handle such cases.
Motivations and Challenges
Conventional methods typically synchronize fixed-size hashes of variable-sized elements, which can become inefficient when the number of differences is significant. This approach also suffers from overhead when false positives are involved, preventing guaranteed reconciliation. The core challenge resolved in the paper is determining the optimal configuration of Bloom filters without prior knowledge of difference cardinality. This problem is addressed by introducing RBFs, which adapt to the set differences dynamically, obviating the need for complex estimation or configuration.
Technical Approach
The proposed hybrid protocol operates in two stages. First, it uses RBFs for an initial approximation, which are transmitted incrementally (rateless), allowing the receiver to determine when enough data has been collected to optimize for synchronization without redundant communication. This stage mitigates false positives inherent in Bloom filters, as the rateless nature means that transmission stops at the optimal point.
The second stage employs IBLTs for precise reconciliation. IBLTs work by storing element IDs and facilitating element decoding through XOR operations. This approach enables recovery of the original set with high probability, significantly reducing the number of false positives and overall data needed for accurate synchronization.
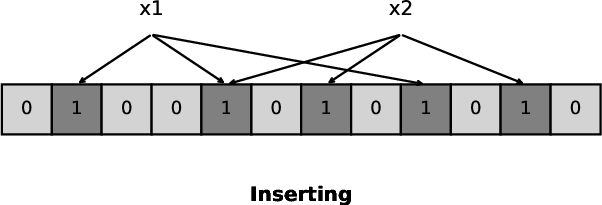
Figure 1: Insertion into a standard Bloom filter (m=12,k=3). Elements x1 and x2 are inserted.
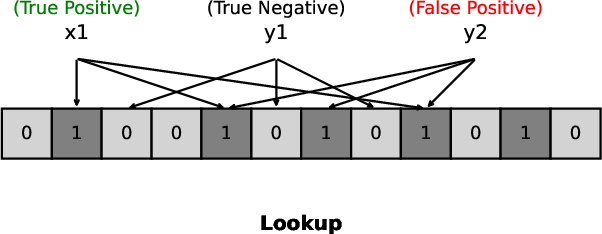
Figure 2: Lookup in a standard Bloom filter. x1 is a true positive, y1 is a true negative, and y2 is a false positive.
Evaluation and Results
The evaluation, conducted under controlled simulations, compares RBF + IBLT with traditional set reconciliation methods like PinSketch, PBS, and RIBLT. The experiments demonstrate that for moderate to high similarity scenarios, RBF + IBLT reduces communication costs by up to 20% compared to the state-of-the-art. Moreover, for Jaccard indices below 85%, the reduction is even more pronounced, making the proposed method particularly efficient in these situations.
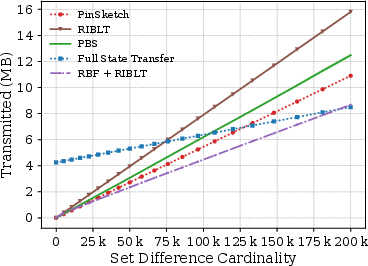
Figure 3: Hybrid Rateless Set Reconciliation vs State-Of-The-Art: Full range - Transmitted total.
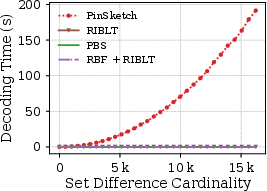
Figure 4: Hybrid Rateless Set Reconciliation vs State-Of-The-Art - Decoding Time with PinSketch.
Conclusion
The paper successfully illustrates how the integration of RBFs and IBLTs into a hybrid protocol enhances the efficiency of set reconciliation for variable-sized elements, particularly in scenarios with large differences post network partition or prolonged downtime. The dynamic adaptation and reduced configuration overhead of the RBF component provide a significant advantage in practical deployments, offering scalable and efficient synchronization without the need for predefined thresholds.
The research suggests a promising direction for future improvements, such as enhancing initial setup protocols or further optimizing the hybrid approach for extreme cases of set similarity. Continued development in this area could lead to broader adoption and more robust implementation of distributed systems requiring efficient synchronization algorithms.