- The paper introduces FRIDA, a training-free framework that extracts latent diffusion features to achieve nearly 88.1% detection accuracy on synthetic images using a k-NN classifier.
- It demonstrates that selecting features from the U-Net's first decoder layer at 16x16 resolution provides robust discrimination between real and synthetic images, even with reduced support set sizes.
- The research employs SHAP analysis to interpret generator-specific latent signatures, with an MLP achieving 84.36% attribution accuracy, underscoring the forensic potential of diffusion features.
Deepfake Detection and Source Attribution via Diffusion Model Features
Introduction
The proliferation of high-fidelity synthetic imagery generated by diffusion models has intensified the need for robust forensic tools capable of both deepfake detection and source attribution. The paper "Who Made This? Fake Detection and Source Attribution with Diffusion Features" (2510.27602) introduces FRIDA, a framework that leverages internal activations from pre-trained Stable Diffusion Models (SDMs) for both tasks. The approach is notable for its training-free, data-efficient methodology, relying on latent features extracted from the U-Net architecture of SDMs. This essay provides a technical analysis of the framework, its experimental validation, and its implications for synthetic image forensics.
FRIDA operates by extracting compact image prototypes from specific layers of a pre-trained SDM U-Net. Each input image is resized and encoded via a VAE, then passed through the U-Net at the final denoising step (t=0). Feature maps from a chosen layer are spatially averaged to form a prototype vector.
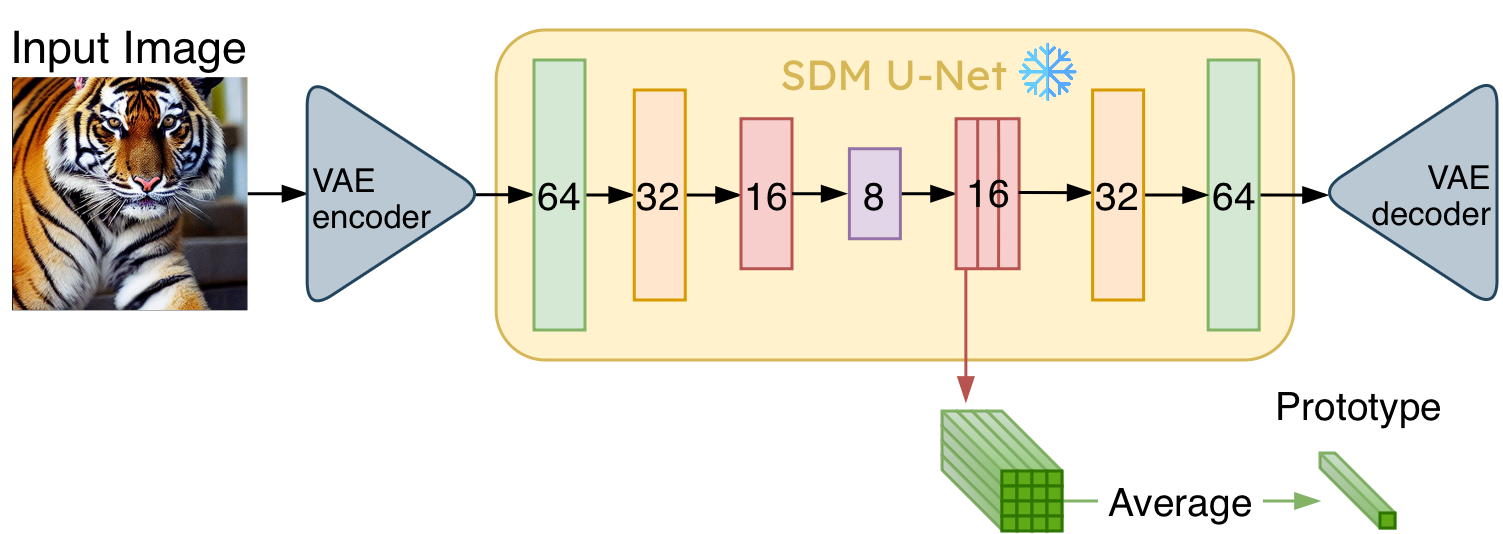
Figure 1: Prototype extraction from Stable Diffusion U-Net. Features are averaged from the first decoder layer at 16×16 resolution.
Layer selection is critical. Linear probing across encoder, bottleneck, and decoder layers at multiple spatial resolutions reveals that the first decoder layer at 16×16 resolution yields the most discriminative features for both detection and attribution tasks.
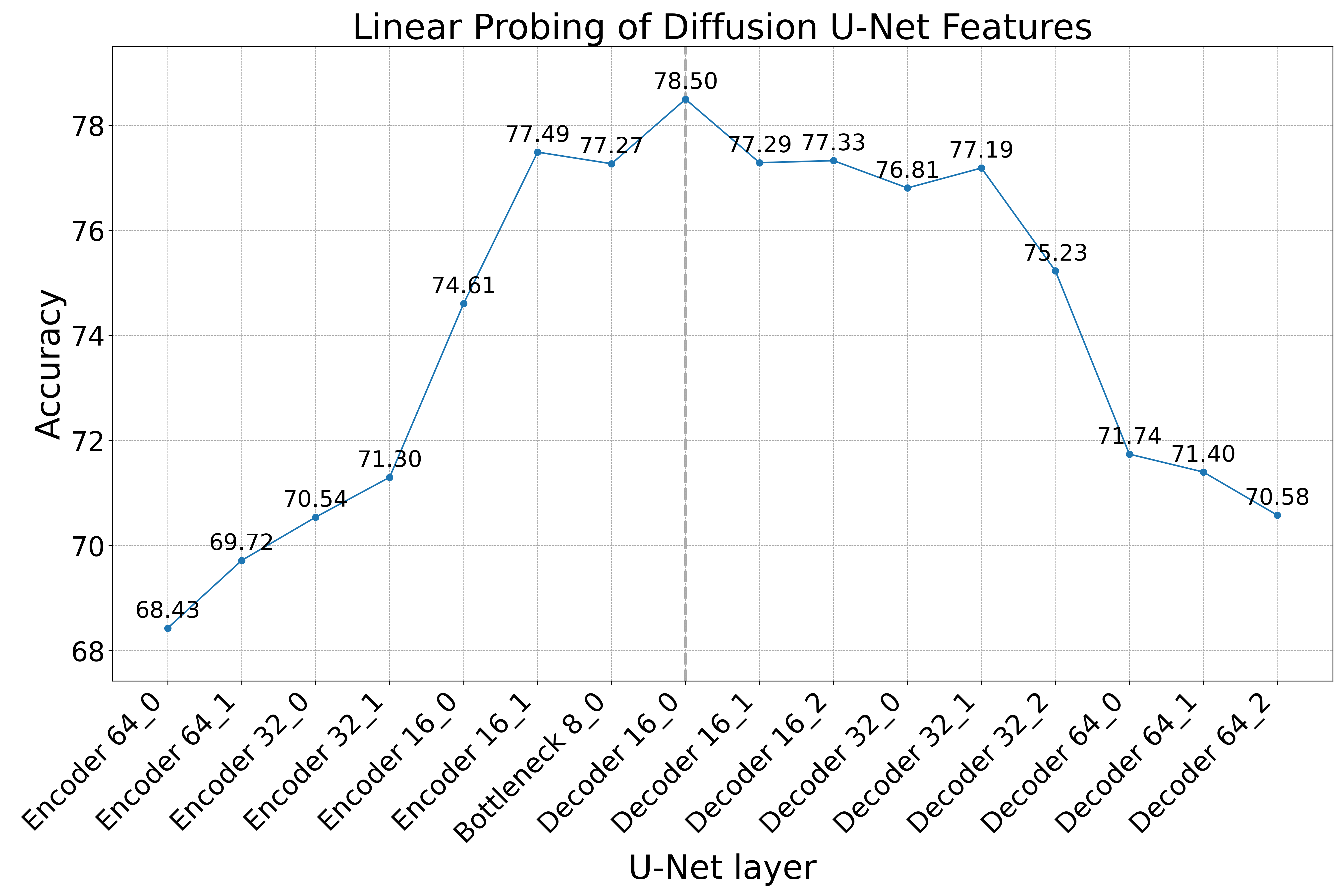
Figure 2: U-Net Layer Selection by Linear Probing. The first decoder layer at 16×16 resolution achieves the highest cross-generator validation accuracy.
Experimental Protocol and Benchmarking
The GenImage dataset, comprising 1.35M synthetic images from eight generators and real images from ImageNet, serves as the benchmark. For each generator, balanced subsets of real and synthetic images are sampled for training, validation, and held-out testing.
Fake Image Detection
Two classifiers are evaluated: a simple MLP and a k-NN. The MLP, while effective at learning generator-specific artifacts, exhibits limited cross-generator generalization. In contrast, the k-NN classifier, operating in the latent feature space, demonstrates superior generalization to unseen generators.
The optimal k-NN configuration (correlation distance, k=101, support size=2000) achieves an average test accuracy of 88.1% across all generators, outperforming prior state-of-the-art methods by a margin of nearly six percentage points. Notably, performance remains robust even with a 90% reduction in support set size, indicating strong data efficiency.
Source Model Attribution
For source attribution, the k-NN classifier is inadequate, peaking at 57.7% accuracy. In contrast, an MLP with a single hidden layer (640 units) achieves 84.36% accuracy on the nine-class attribution task (eight generators plus real), indicating that diffusion features encode generator-specific signatures that are learnable by neural models.
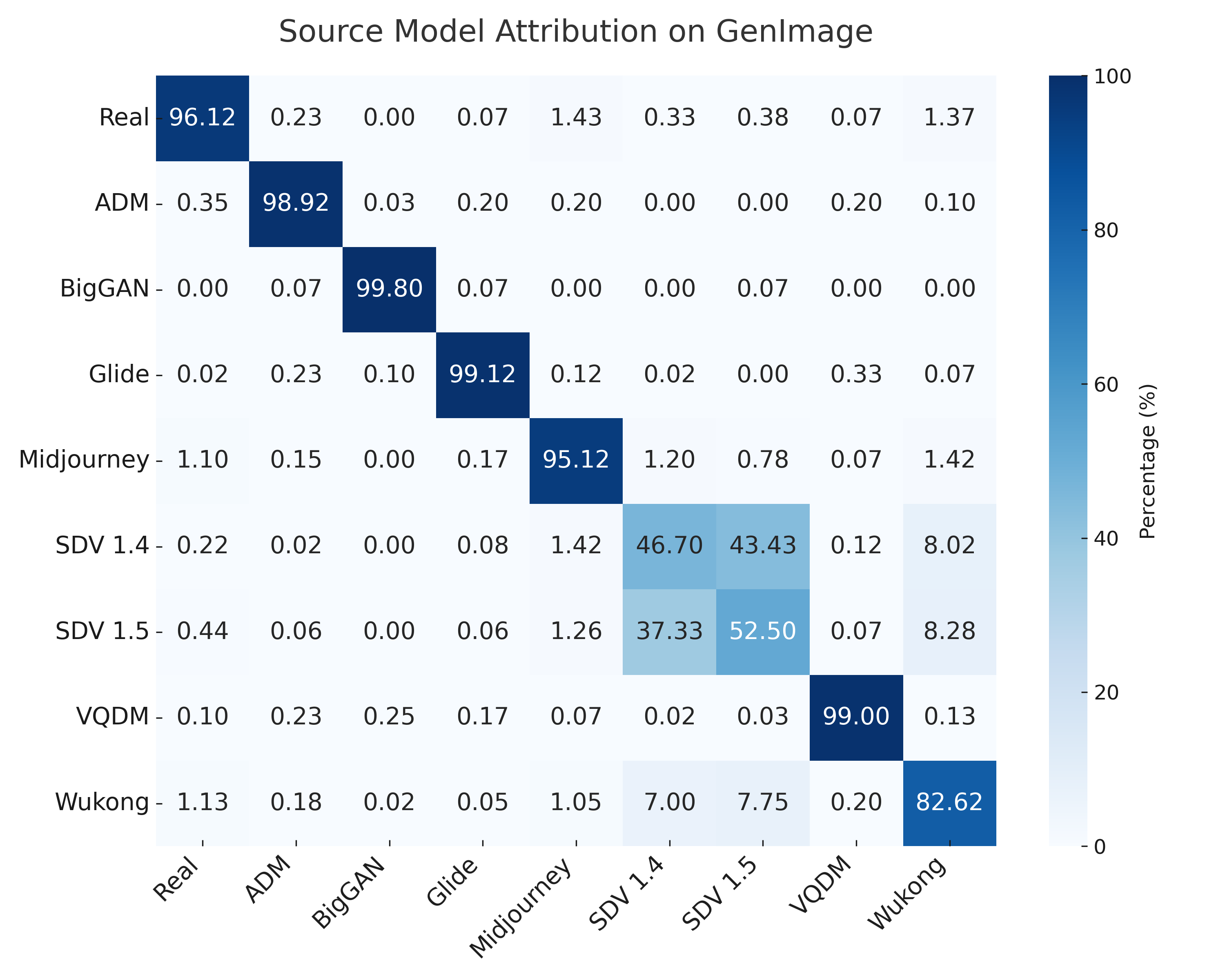
Figure 3: Confusion Matrix for source image attribution. The MLP-640 classifier distinguishes most generators, with confusion primarily between SDM variants.
Feature Analysis and Interpretability
SHAP analysis is employed to interpret the MLP's attribution decisions. The overlap of top-10 most informative features between generator pairs quantifies shared latent characteristics. SDM v1.4 and v1.5 share 50% of their top features, explaining frequent misclassification. Wukong, despite architectural similarity to SDM, shares no top features, yet is occasionally misclassified due to coincidental feature interactions.
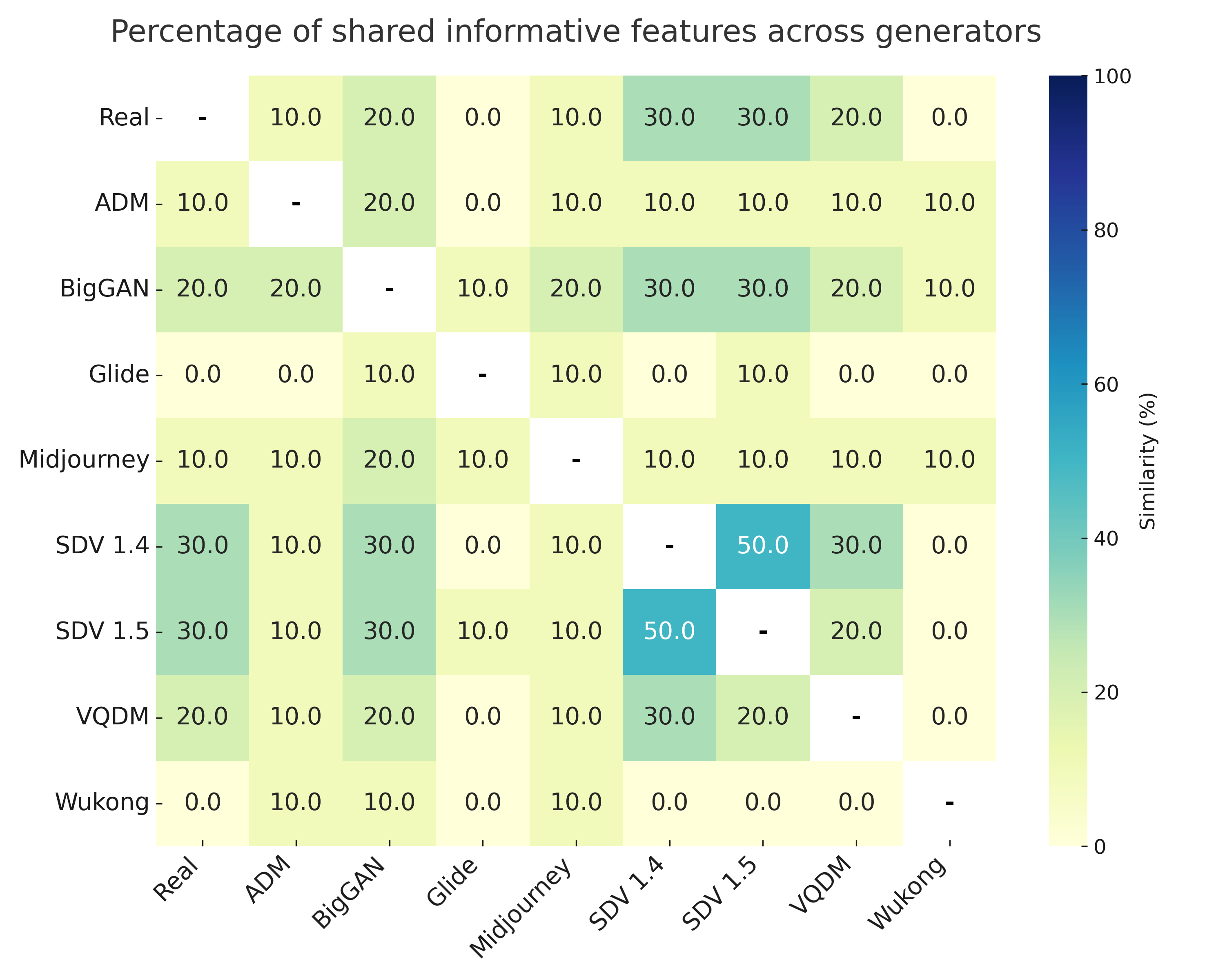
Figure 4: Shared informative features across generators. Percentage overlap of top-10 SHAP features between generator pairs.
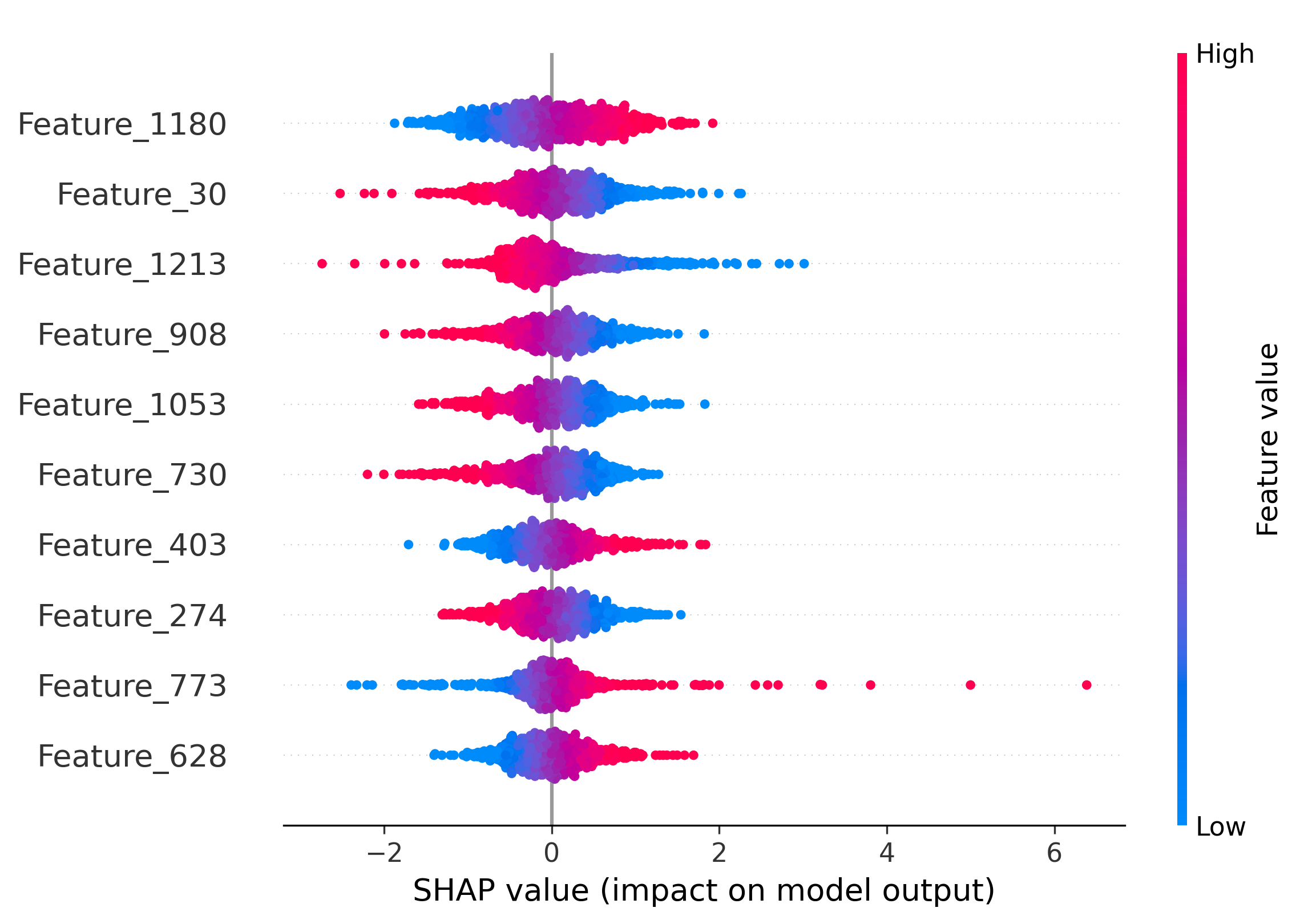
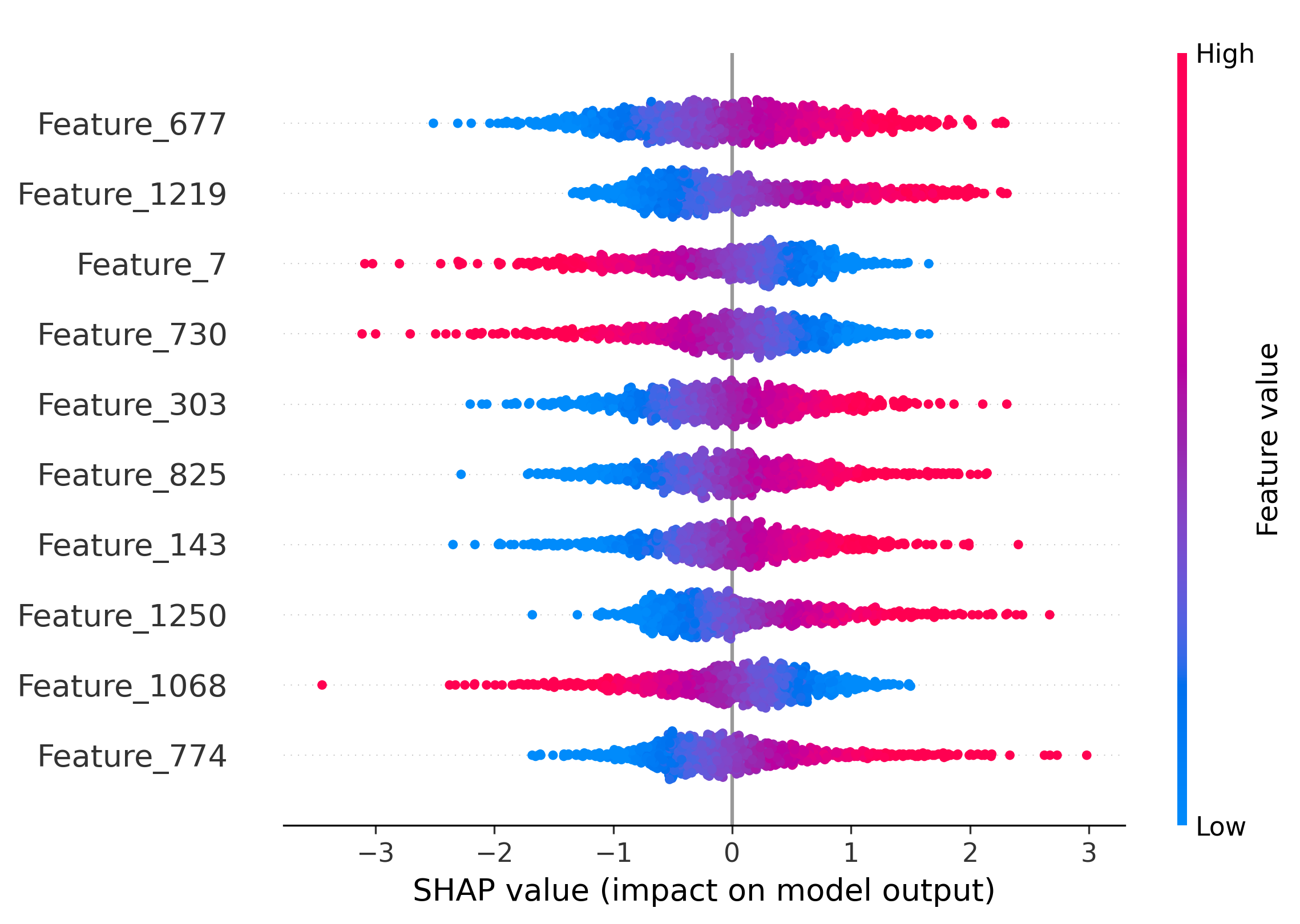
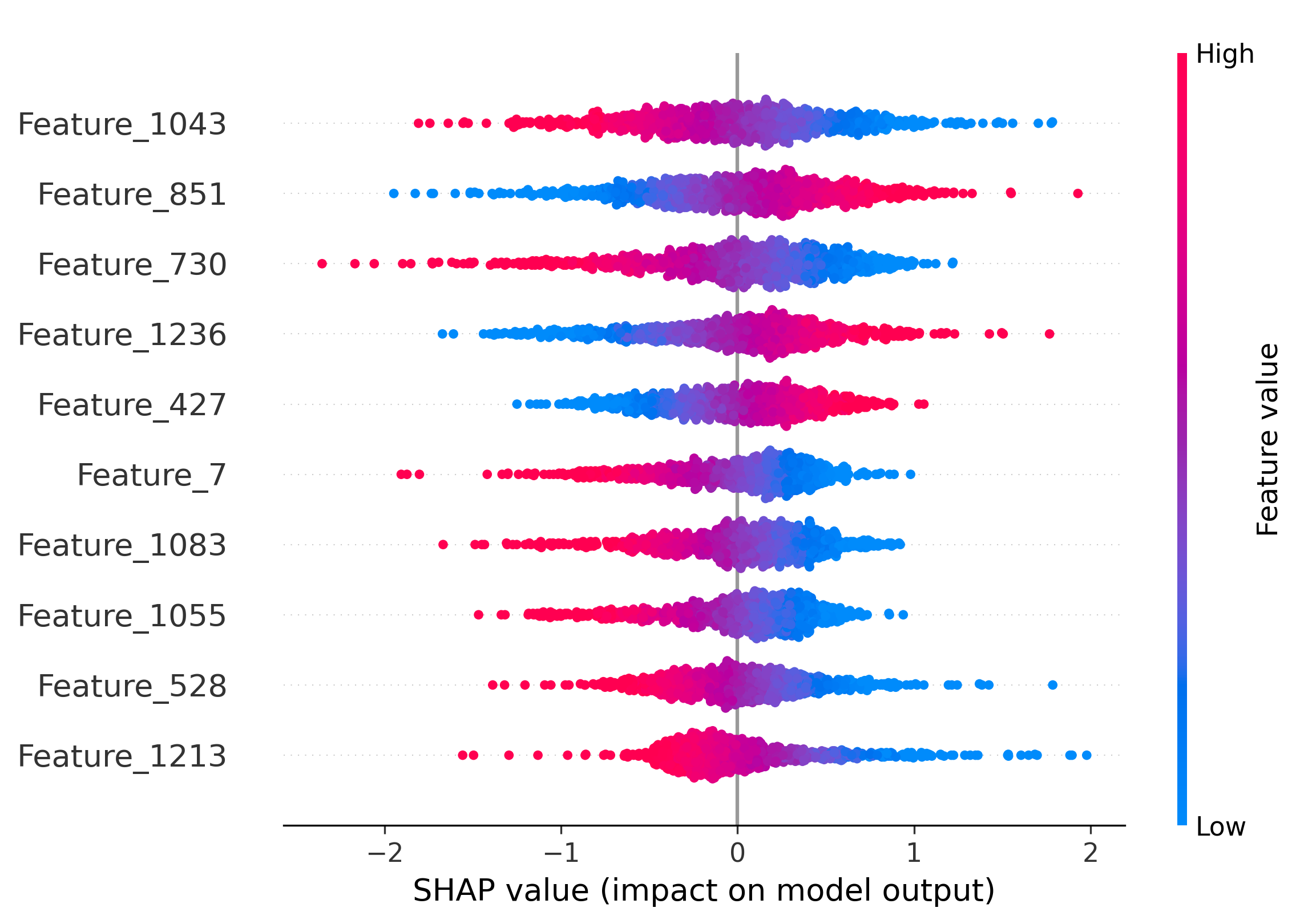
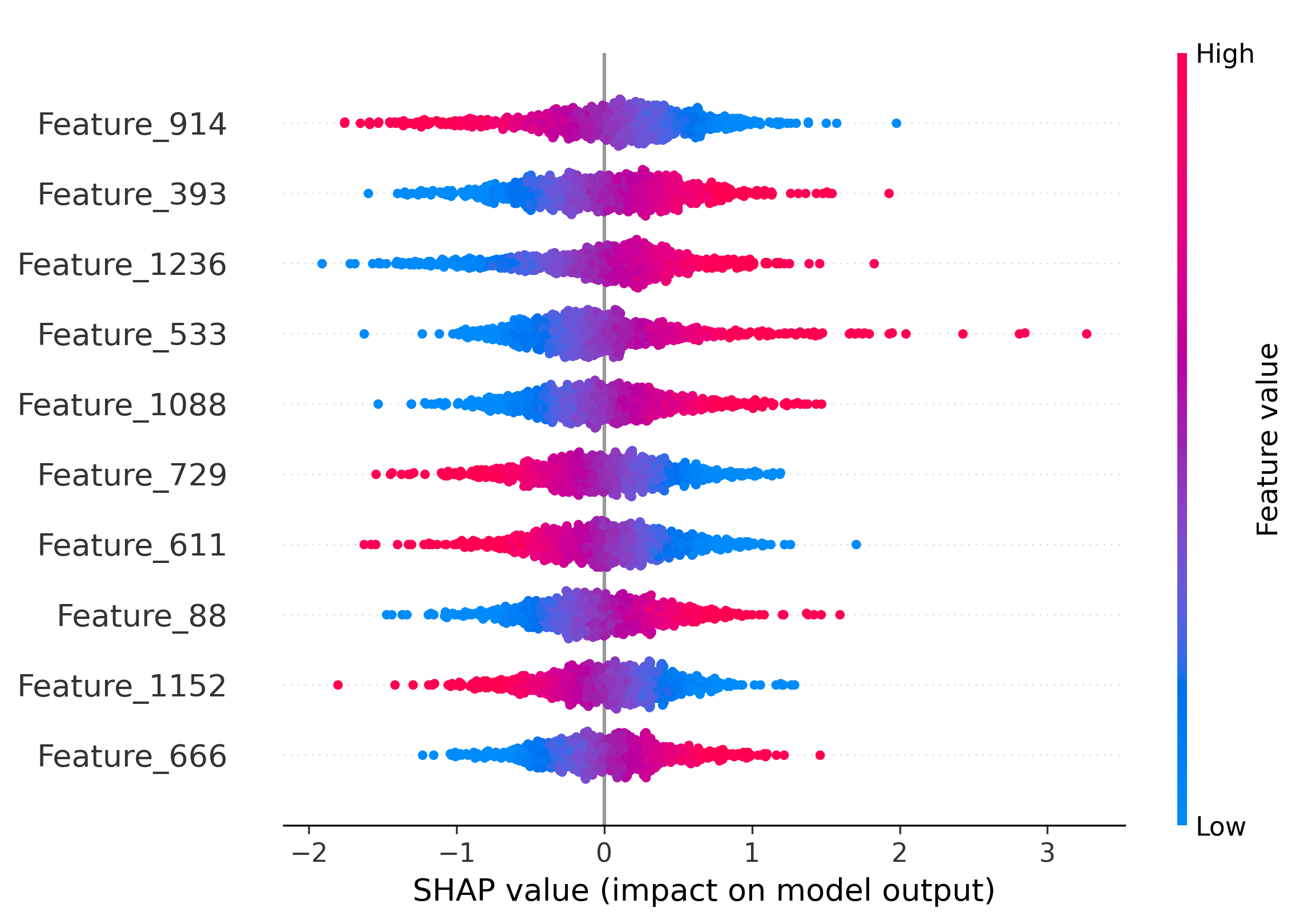
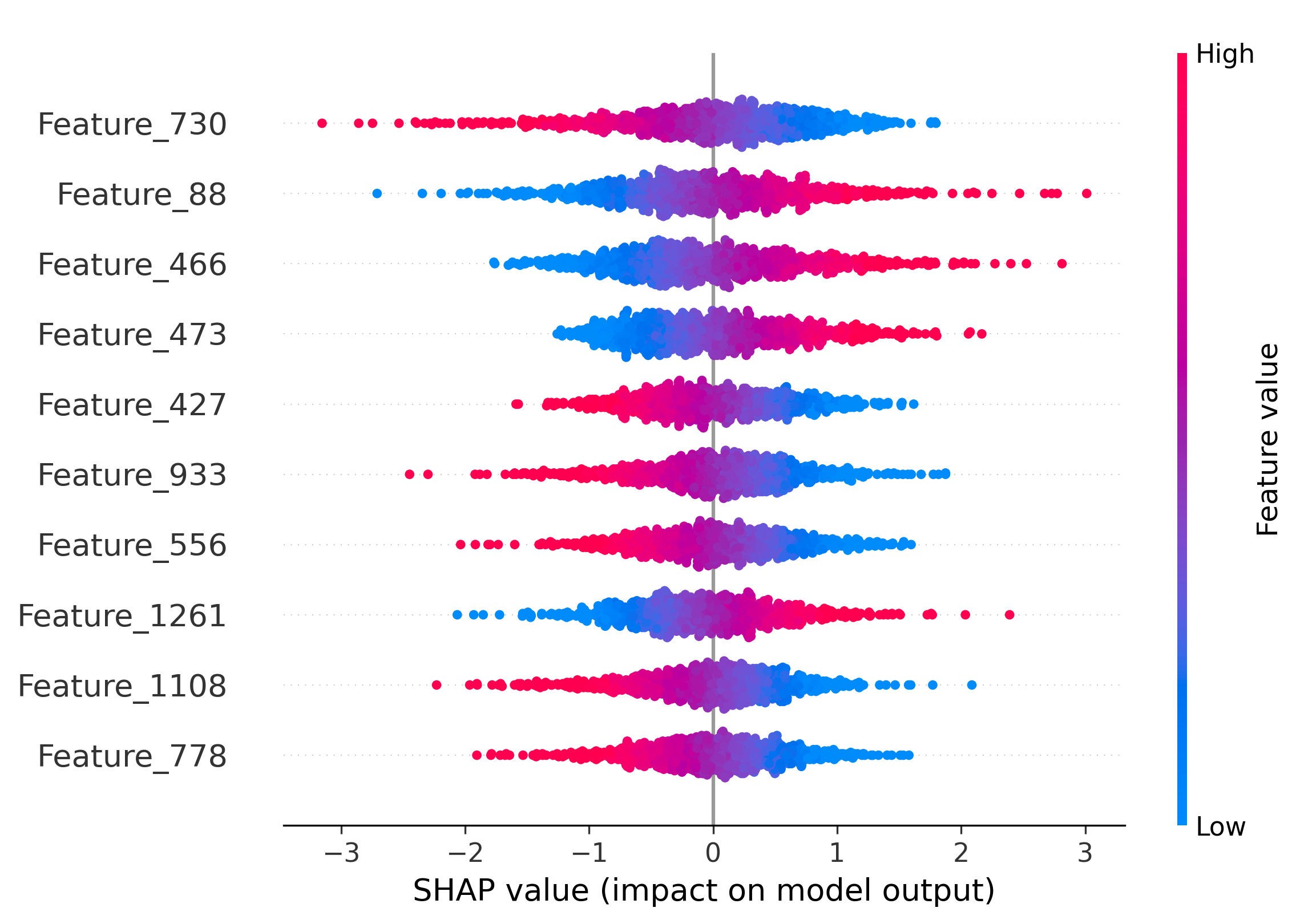
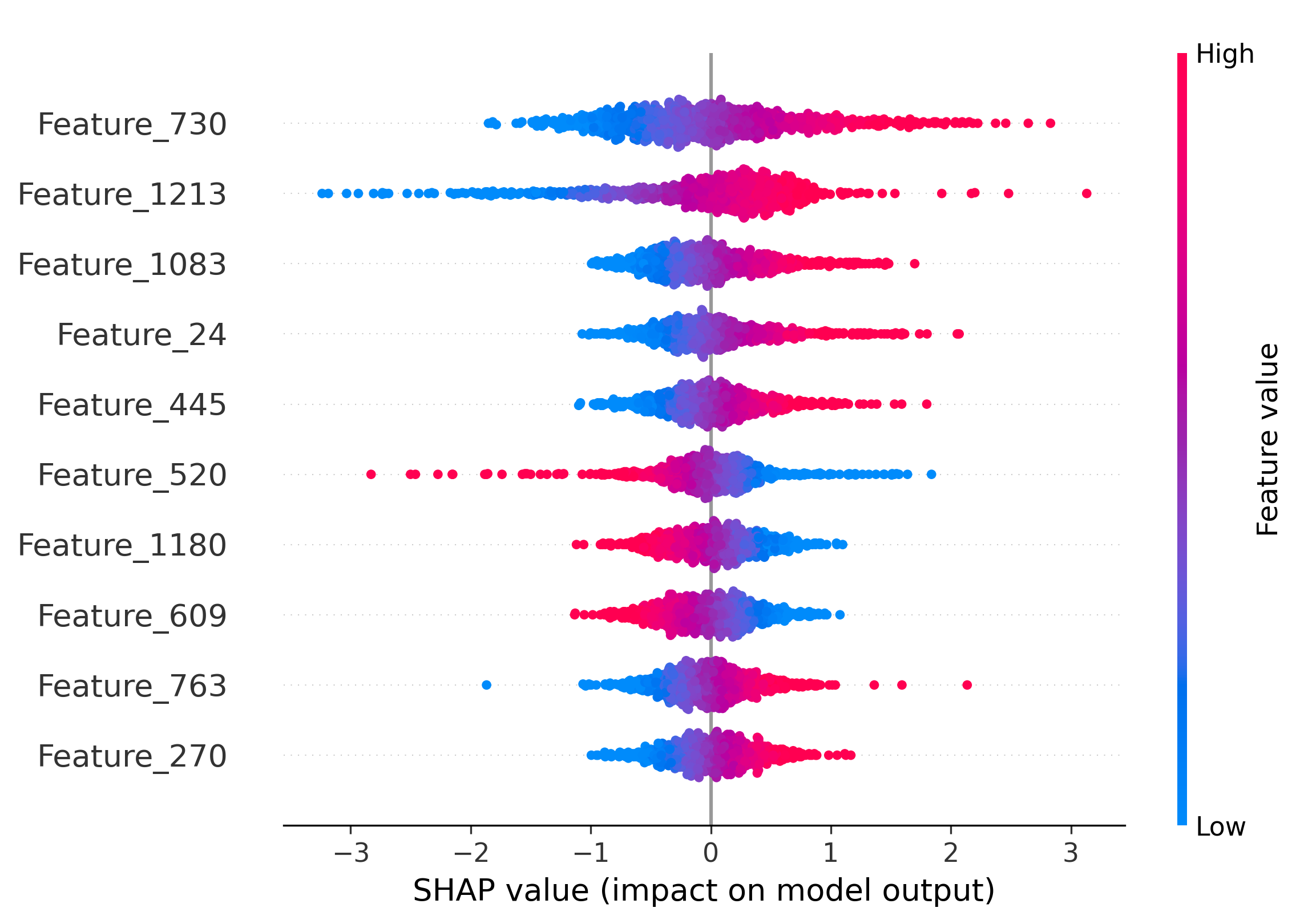

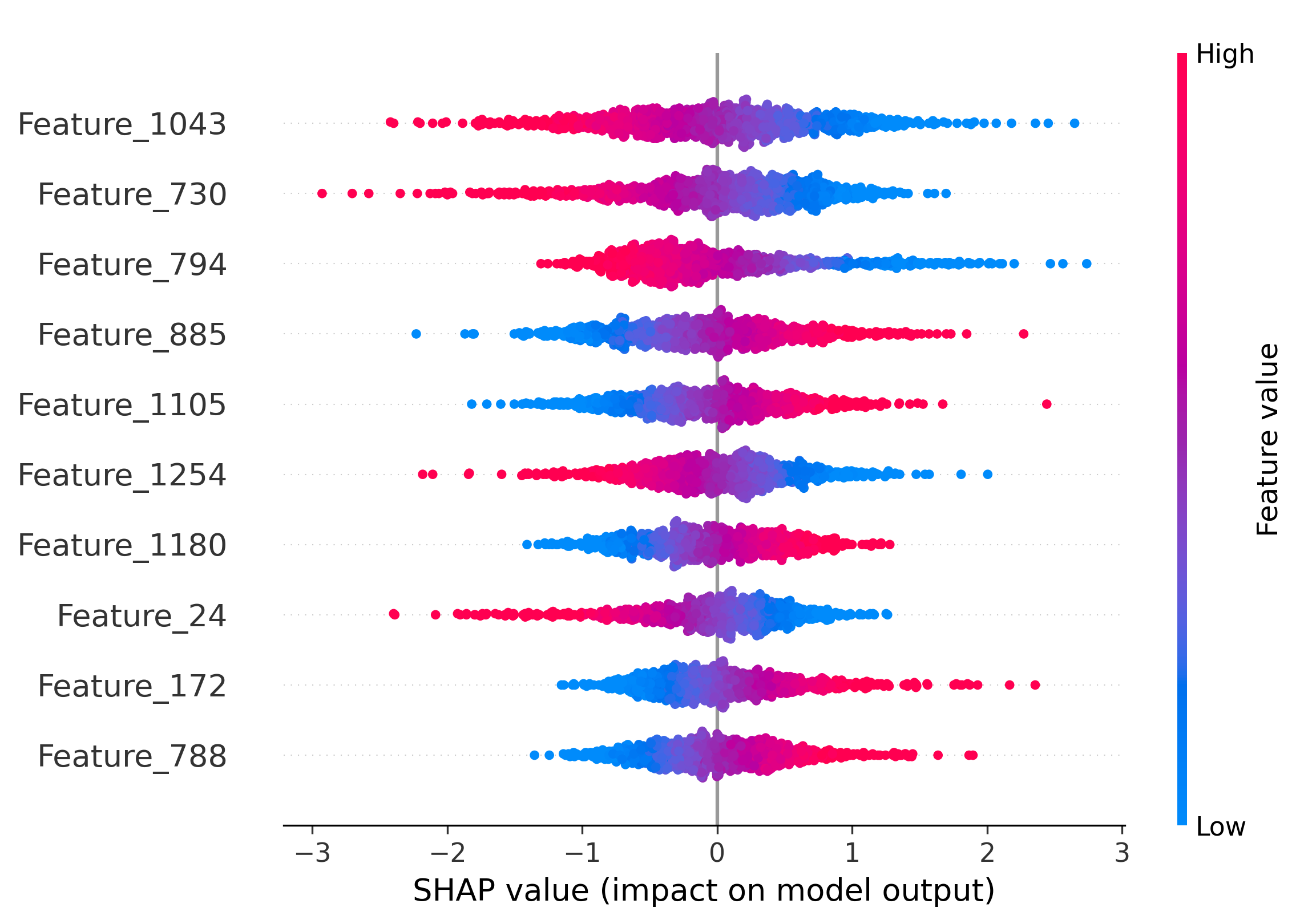
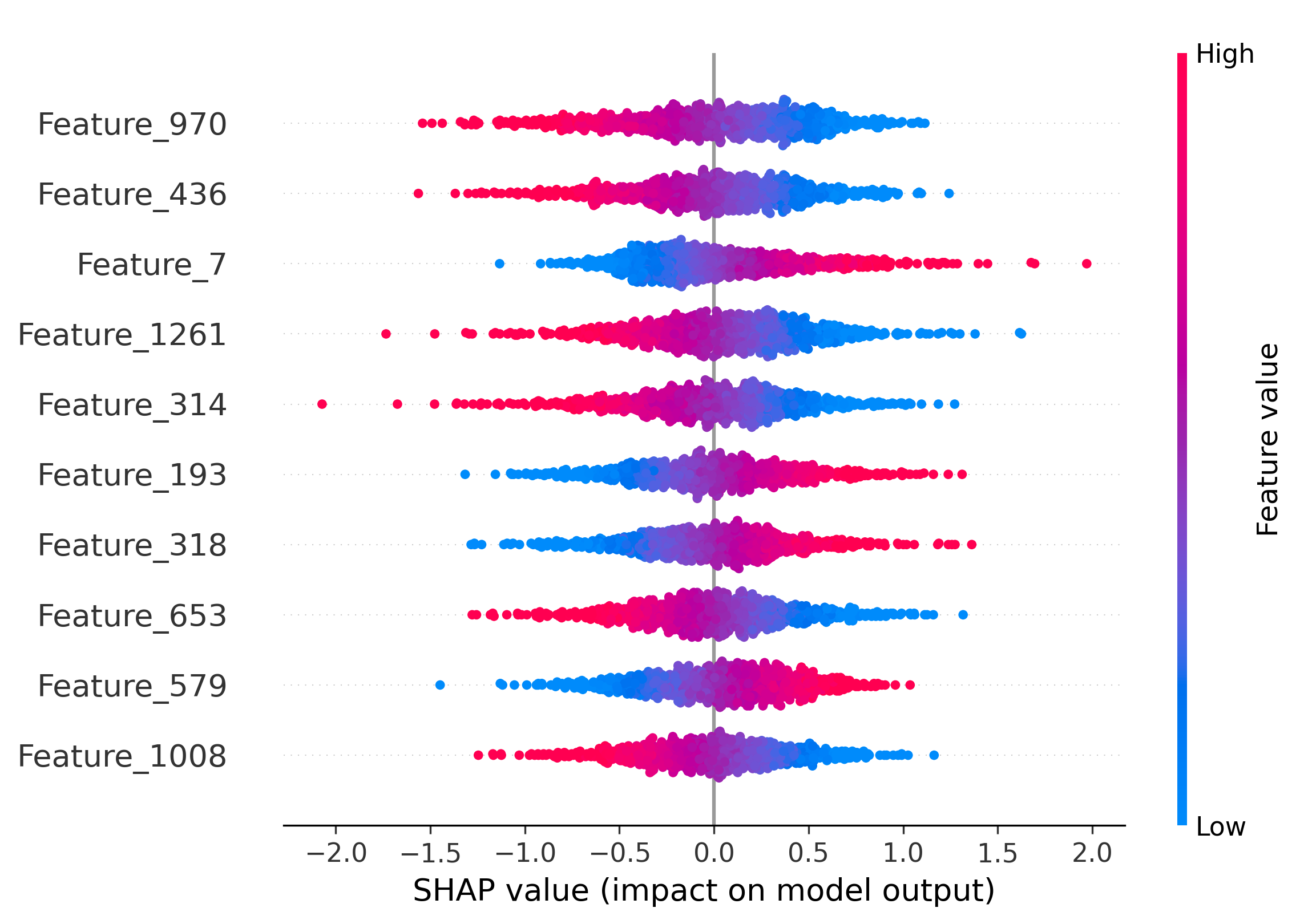
Figure 5: Impact of the top-10 features on model decisions by SHAP analysis. Distinct and shared feature subsets drive attribution across generators and real images.
FRIDA's detection pipeline is training-free, requiring only feature extraction and support set storage. On an NVIDIA RTX 4090, feature extraction averages 2.1 seconds per image, with k-NN classification at 0.0003 seconds. CPU inference is slower but remains practical for batch processing. The method's scalability and adaptability to new generators are facilitated by its minimal retraining requirements and low data demands.
Implications and Future Directions
The results demonstrate that diffusion model features, optimized for generation, inherently encode both authenticity and generator identity. This dual utility positions diffusion features as a universal basis for synthetic image forensics. The training-free nature and strong generalization of FRIDA make it suitable for real-world deployment, especially in environments where new generative models emerge rapidly.
Theoretical implications include the observation that generative models imprint distinct signatures in their latent spaces, which are accessible via simple feature extraction. Future work may explore open-set attribution, robustness to adversarial manipulations, and extension to other modalities (e.g., video, audio). Further research into the interpretability of diffusion features could yield insights into the generative process and its forensic traceability.
Conclusion
FRIDA establishes a new paradigm for deepfake detection and source attribution by repurposing diffusion model features. Its training-free, data-efficient approach achieves state-of-the-art performance on challenging benchmarks, with strong generalization and interpretability. The framework's reliance on latent diffusion features bridges the gap between generative modeling and forensic analysis, offering a scalable solution for synthetic media authentication and provenance tracking.