- The paper demonstrates that filter heads encode abstract predicates via causal mediation analysis, enabling modular list processing across various tasks.
- It reveals dual strategies—lazy evaluation at answer time and eager evaluation using is_match flags—in transformer models like Llama-70B and Gemma-27B.
- Ablation and activation patching experiments confirm the portability of filter heads, supporting zero-shot concept detection and enhanced interpretability.
Mechanistic Interpretability of List Processing in LLMs via General Filter Heads
Introduction
This paper presents a mechanistic analysis of how LLMs, specifically transformer-based architectures such as Llama-70B and Gemma-27B, implement list-processing tasks. The authors identify a set of specialized attention heads, termed filter heads, that encode compact, causal representations of filtering predicates. These heads generalize across predicates, formats, languages, and even tasks, mirroring the abstract "filter" function in functional programming. The work leverages causal mediation analysis and activation patching to dissect the internal computations, revealing both lazy and eager evaluation strategies for filtering, and demonstrating the portability and compositionality of predicate representations.
Filter Heads: Localization and Mechanism
Filter heads are concentrated in the middle layers of transformer LMs. They encode the filtering predicate as a geometric direction in query space at specific token positions, typically where the model is required to produce an answer. The interaction between these query states and the key states of preceding tokens produces attention patterns that select items satisfying the predicate.
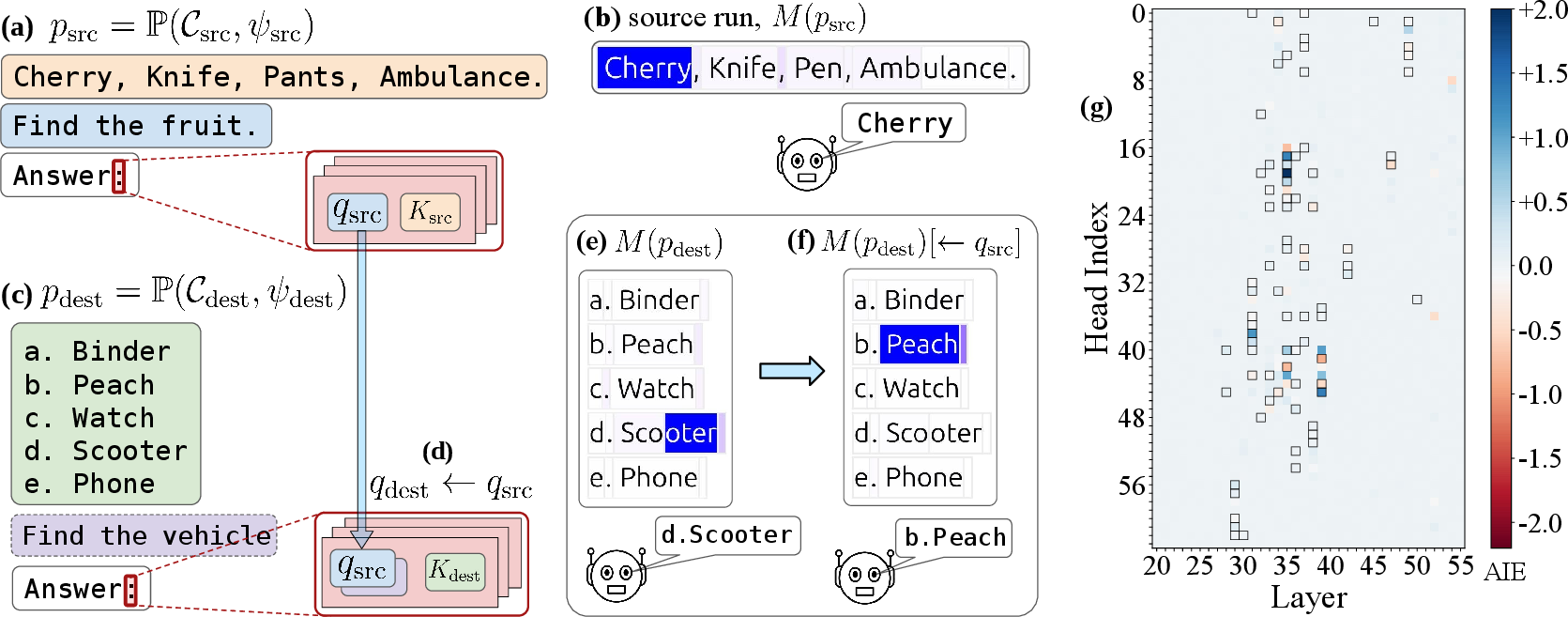
Figure 1: A filter head [35, 19] in Llama-70B encodes a compact representation of the predicate ``is this fruit?'' and selectively attends to the correct item in the list.
The identification of filter heads is achieved via causal mediation analysis (CMA) with activation patching. By patching the query state from a source prompt (encoding a predicate) into a destination prompt, the model can be made to execute the source predicate in the new context, demonstrating that the query state encodes a generalizable predicate representation.
Generalization and Portability
Filter heads are not tied to specific predicates or formats. The predicate representation extracted from one context can be patched into another, triggering the same filtering operation across different collections, languages, and even tasks.
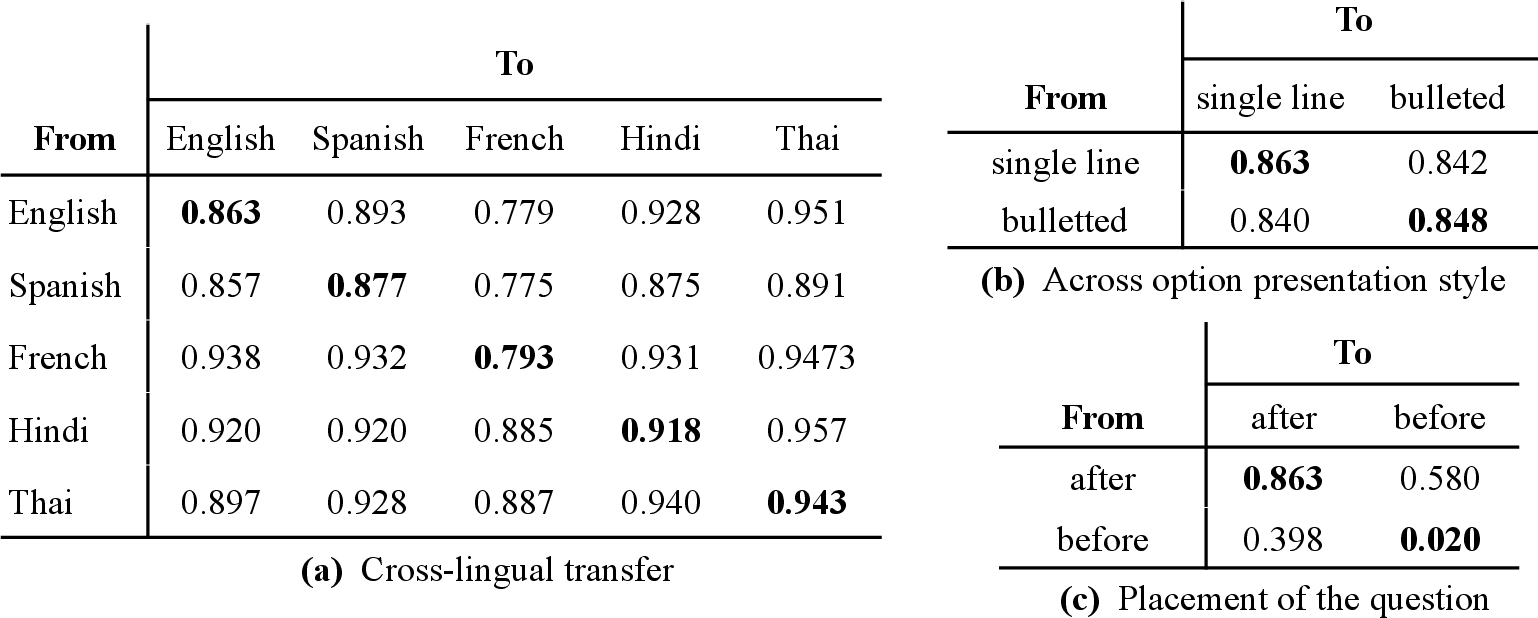
Figure 2: Portability of predicate representations across linguistic variations, presentation formats, and question placement.
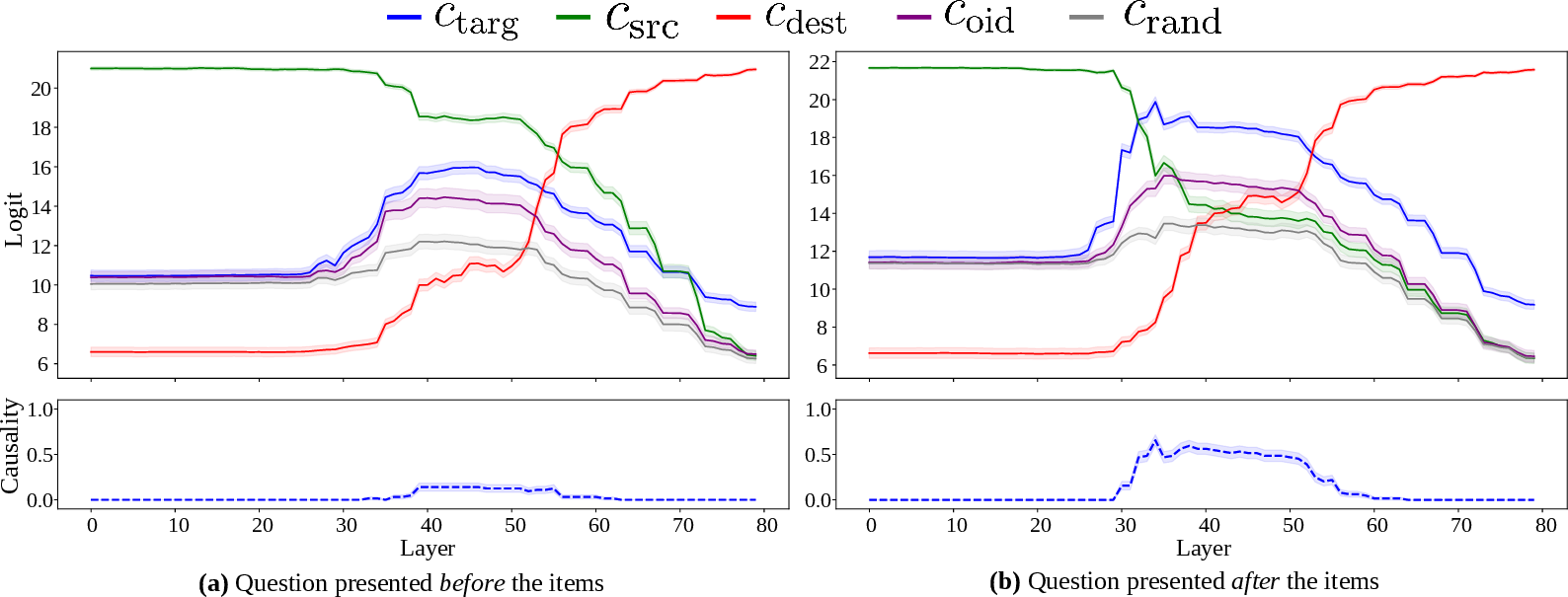
Causality scores remain high when transferring predicates across languages and formats, confirming that filter heads encode abstract semantic predicates rather than surface-level linguistic patterns. However, when the question precedes the collection, causality drops, indicating a shift in computational strategy.
Dual Implementation: Lazy vs. Eager Filtering
The model can implement filtering in two ways:
Activation patching experiments confirm that manipulating the is_match flag directly affects the model's output in question-first prompts, validating the existence of an eager evaluation pathway.
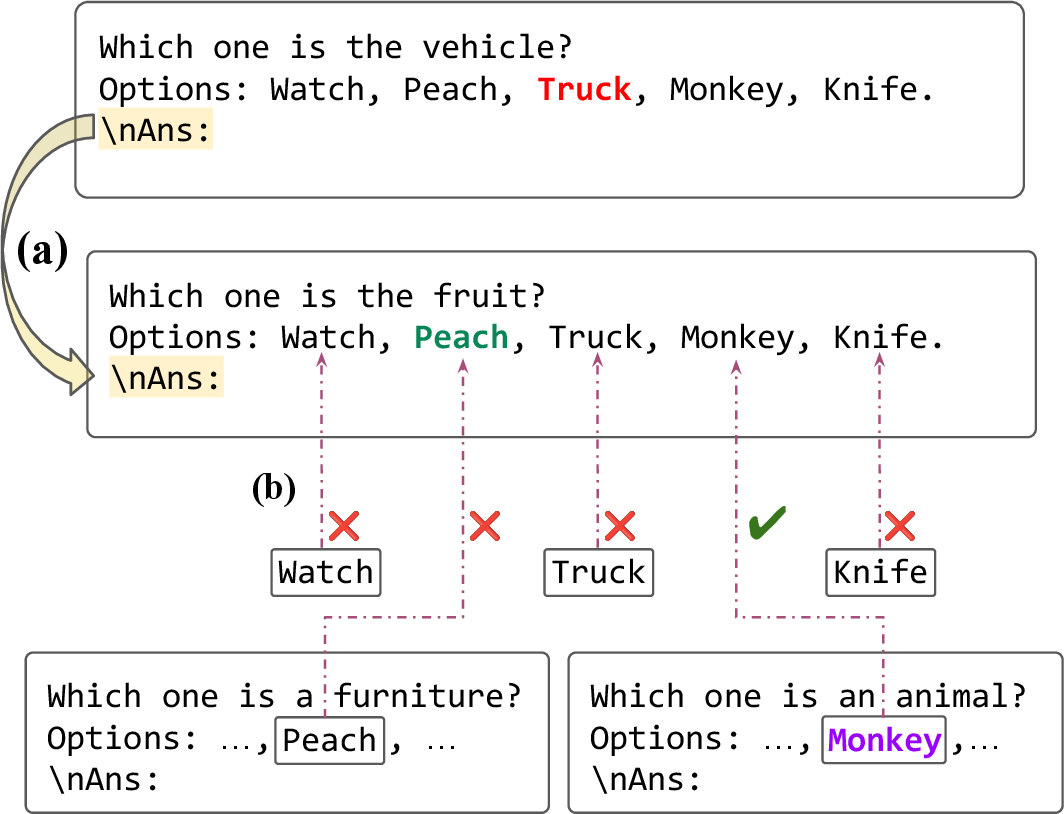
Figure 4: Counterfactual patching setup to swap the is_match flag between items, demonstrating the model's reliance on pre-computed flags in certain prompt formats.
Filter heads generalize across a range of filter-reduce tasks, including selection, counting, and existence checking. Heads identified in one task often retain causal influence in others, especially among selection tasks. However, more complex aggregation tasks (e.g., counting) involve additional circuits.
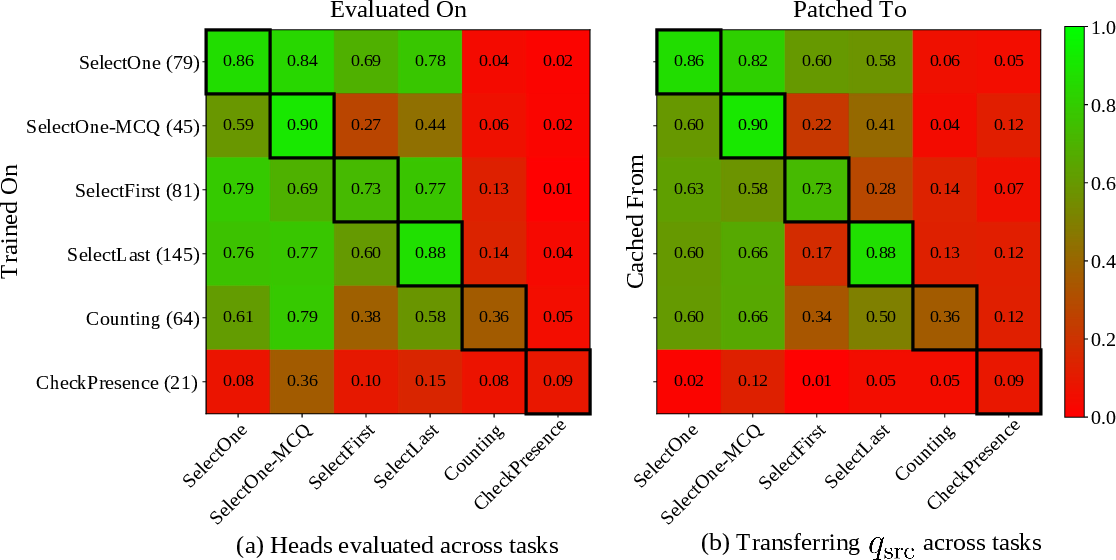
Figure 5: Generalization across different tasks, showing portability of filter heads and predicate representations.
Ablation studies demonstrate that filter heads are necessary for selection tasks, with performance dropping catastrophically when they are ablated, while counting and existence tasks are less affected.
Predicate Representation: Compositionality and Algebra
Predicate representations in filter heads are compositional. Adding the query vectors of two predicates results in a representation that implements the disjunction of the predicates.

Figure 6: Aggregated attention pattern of filter heads under predicate composition, showing selection of items satisfying either predicate.
SVD decomposition of the query-key projection matrices reveals that predicate information is concentrated in low-rank subspaces, supporting the hypothesis that filter heads implement filtering via coordinated interactions between low-dimensional subspaces.
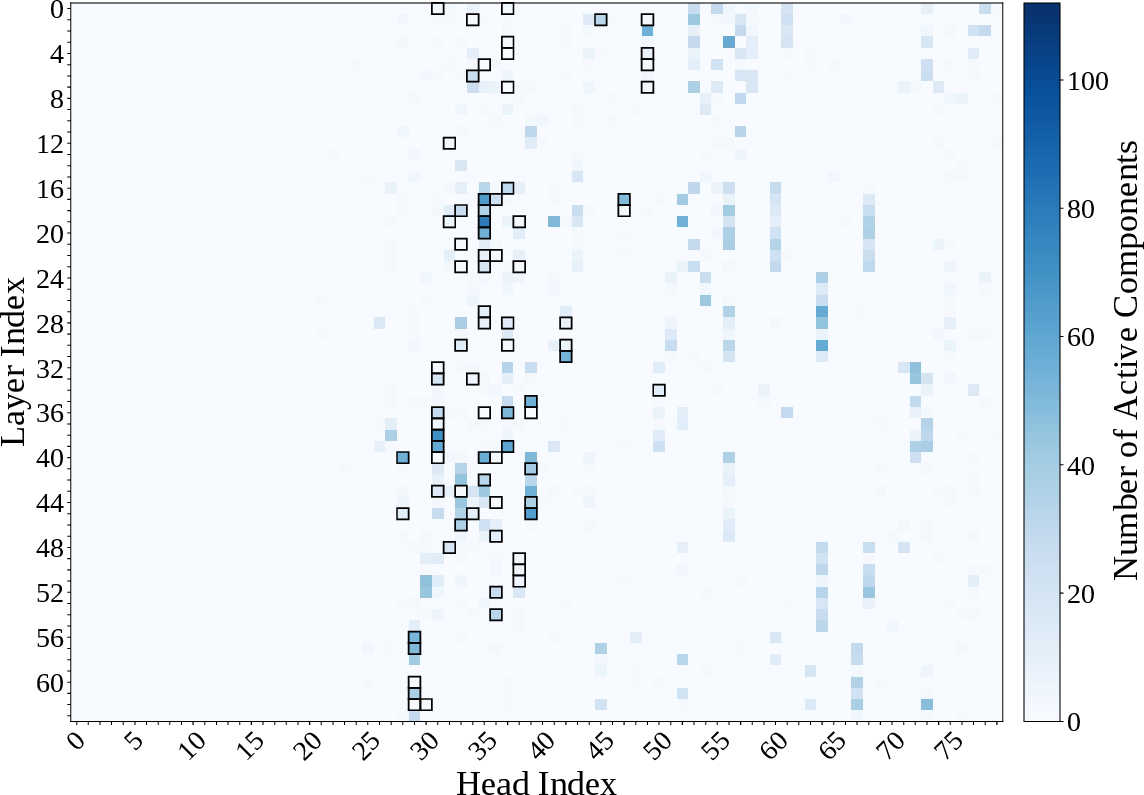
Figure 7: Distribution of critical SVD components of WQK, showing concentration in middle layers.
Application: Training-Free Concept Probes
The predicate information encoded by filter heads can be repurposed for zero-shot concept detection. By extracting the query state for a given predicate, one can classify item representations by affinity, achieving strong performance without any training.

Figure 8: Averaging qsrc across prompts to remove order information and improve causality scores.
Comparison with Other Head Types
Filter heads are functionally distinct from previously documented attention head types such as Function Vector heads and Concept Induction heads. They exhibit unique causal roles in filtering tasks and minimal overlap with other head types.
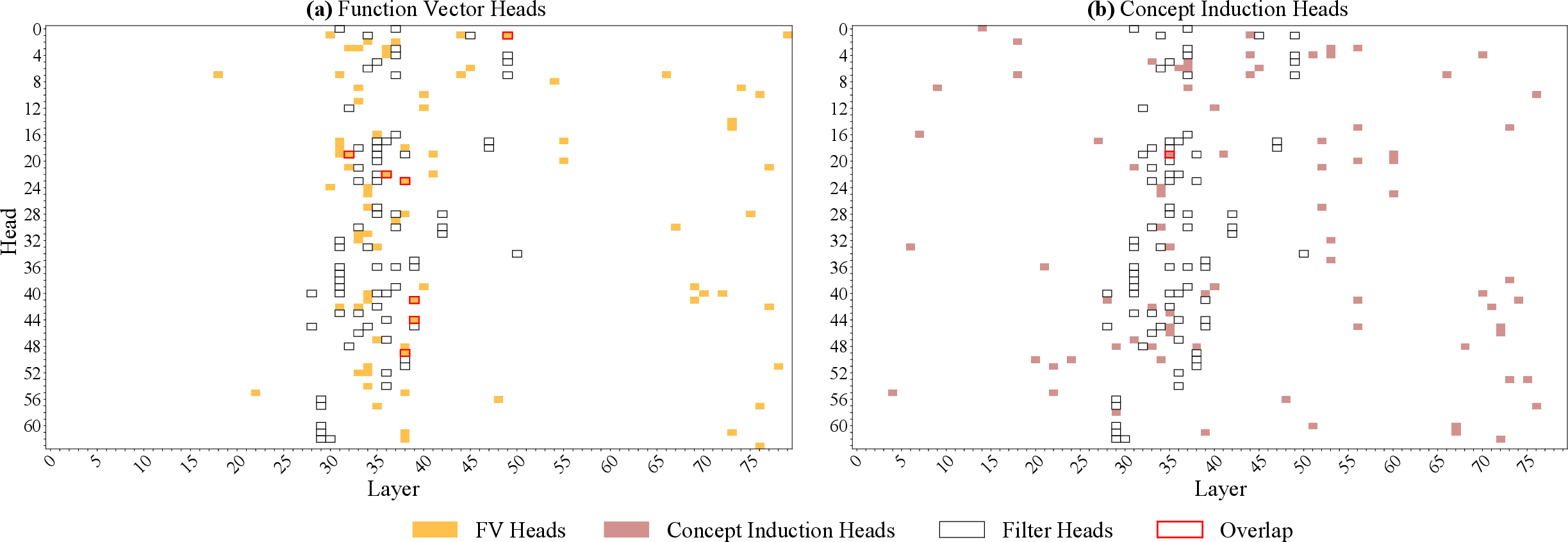
Figure 9: Distribution of specialized attention heads in Llama-70B, showing concentration and minimal overlap between filter heads and other types.
Replication in Gemma-27B
Experiments replicated in Gemma-27B confirm the existence and generalization properties of filter heads, supporting the hypothesis that these mechanisms are robust across model families and scales.
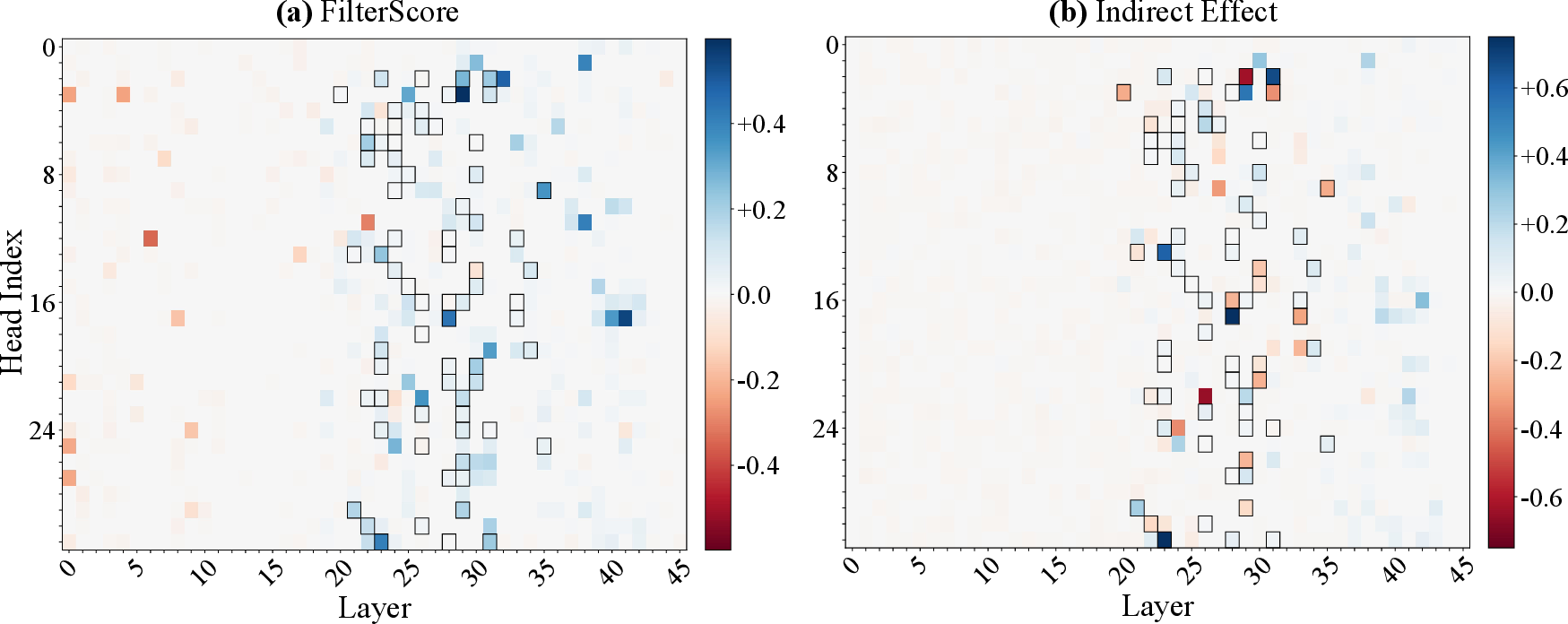
Figure 10: Location of filter heads in Gemma-27B-it, mirroring findings in Llama-70B.
Limitations and Future Directions
The analysis is restricted to a limited set of tasks and model families. While filter heads are robustly identified in Llama-70B and Gemma-27B, architectural or dataset differences may yield alternative implementations in other models. The study focuses on larger LMs; smaller models may exhibit higher superposition and entanglement of predicate representations. The prompt templates used may bias the computational strategies observed.
Future work should extend the analysis to broader task sets, model architectures, and investigate the interaction between filter heads and other computational primitives. Understanding the emergence and coordination of such universal computational modules may inform the design of more interpretable and controllable AI systems.
Conclusion
This paper provides a detailed mechanistic account of how transformer LMs implement list-processing via general filter heads. These heads encode abstract, portable predicate representations, generalize across tasks and formats, and support both lazy and eager evaluation strategies. The findings advance the interpretability of LLMs, revealing the emergence of modular computational primitives analogous to those in functional programming. The identification and characterization of filter heads open avenues for training-free concept probing and deeper understanding of symbolic reasoning in neural networks.