- The paper introduces a dual-direction spatial speculative decoding framework leveraging horizontal and vertical draft heads to reduce inference latency.
- It employs a tree-based candidate verification strategy and caches vertical predictions, achieving a 1.71× speedup on benchmarks while preserving image fidelity.
- Experimental results demonstrate that exploiting spatial context improves acceptance rates of speculative tokens and maintains quality across complex image regions.
Hawk: Leveraging Spatial Context for Faster Autoregressive Text-to-Image Generation
Introduction
Autoregressive (AR) models have demonstrated strong capabilities in high-fidelity text-to-image generation, but their sequential token-by-token inference paradigm imposes significant latency, limiting practical deployment. While speculative decoding has yielded substantial acceleration in text generation, its direct application to image generation is nontrivial due to the vastly larger sampling space and the two-dimensional spatial dependencies inherent in images. The Hawk framework addresses these challenges by introducing spatially aware speculative decoding, leveraging both horizontal and vertical spatial contexts to guide draft predictions and accelerate AR image generation without compromising output quality.
Motivation and Challenges
Speculative decoding in text models relies on a lightweight draft model to propose multiple candidate tokens, which are then verified by a larger target model. This approach is effective in text due to the relatively small vocabulary and strong local dependencies. In contrast, AR image generation requires sampling from a much larger token space (20–400× that of text), and the spatial structure of images introduces complex dependencies not captured by sequential raster order alone. Attention analysis reveals that image models focus not only on inference-neighboring points but also on spatially adjacent tokens, especially those in previous rows, indicating the necessity of exploiting both horizontal and vertical contexts for effective speculation.
Hawk Framework Overview
Hawk introduces dual-direction draft heads—horizontal and vertical—that independently speculate future tokens along both axes. Vertical speculations are cached for use in subsequent line processing, while horizontal speculations are combined with cached vertical predictions to form a spatial sampling pool. Candidate tokens are generated from this pool using a tree decoding strategy, followed by a verification step that preserves the statistical behavior of the original AR model.
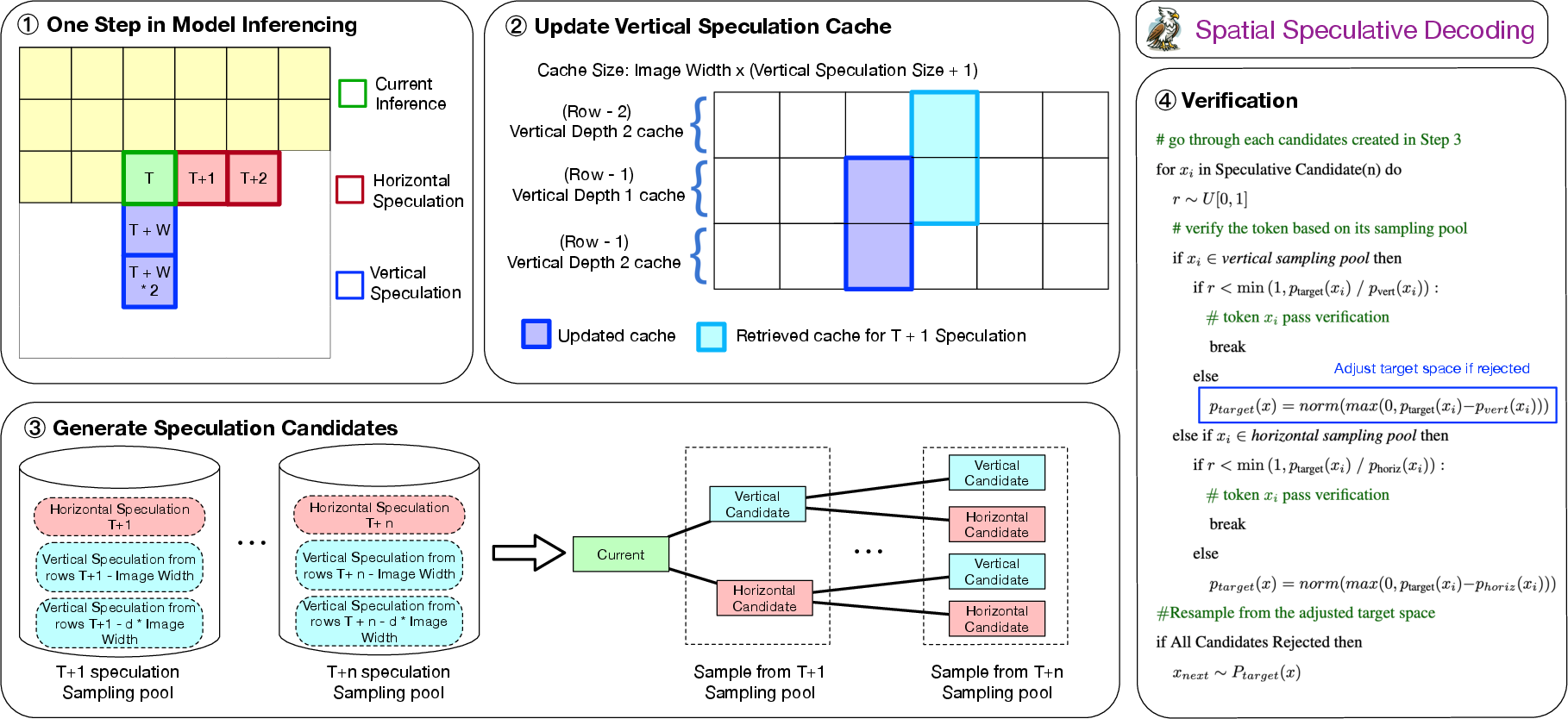
Figure 1: Overview of Hawk’s spatial speculative decoding, integrating horizontal and vertical draft heads, speculation cache, and tree-based candidate verification.
This dual-direction approach expands the candidate space, improves alignment between draft and target distributions, and increases the acceptance rate of speculative tokens, thereby reducing the number of sequential forward passes required for image synthesis.
Attention Sinking and Spatial Dependencies
Empirical attention analysis using Lumina-mGPT demonstrates that AR image models exhibit strong attention to spatially neighboring points, particularly those in previous rows, unlike text models where attention is concentrated on immediate sequential neighbors.
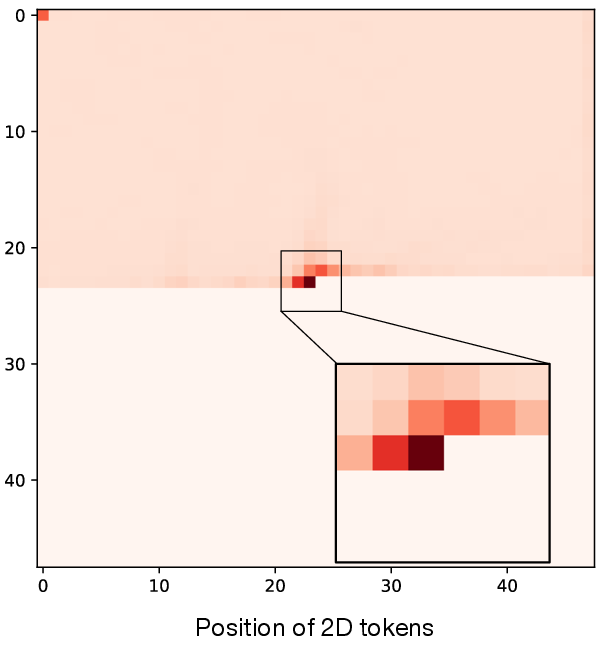
Figure 2: Lumina-mGPT average attention logits visualized in 2D, highlighting spatial attention concentration on adjacent and previous-row tokens.
This observation motivates the use of vertical draft heads, which can effectively leverage information from spatially adjacent regions, mitigating the performance decay typically observed in speculative predictions at greater distances from the current inference point.
Training and Implementation Details
Hawk’s draft heads are implemented as additional linear layers with SiLU activation, appended to the final hidden layers of the base model (Lumina-mGPT). Only the draft heads are fine-tuned, with the rest of the model frozen, using AdamW optimizer and a small subset of the LAION aesthetic dataset. The memory overhead is minimal (<1% of base model parameters), and inference is further optimized via KV caching.
During inference, the vertical draft head predicts tokens at positions offset by multiples of the image width, while the horizontal head predicts tokens at sequential positions. Vertical predictions are cached and reused, and the candidate pool for each speculative step is constructed by merging horizontal and vertical predictions, followed by tree-based candidate expansion and verification.
Quantitative and Qualitative Results
Hawk achieves a 1.71× speedup over standard AR decoding on COCO2017 and Flickr30K benchmarks, with an average accepted speculative length of 1.89 tokens per step. Importantly, Hawk maintains image fidelity (FID and CLIP scores) comparable to the baseline, outperforming alternative speculative decoding methods such as Medusa and LANTERN++ in both efficiency and quality preservation.
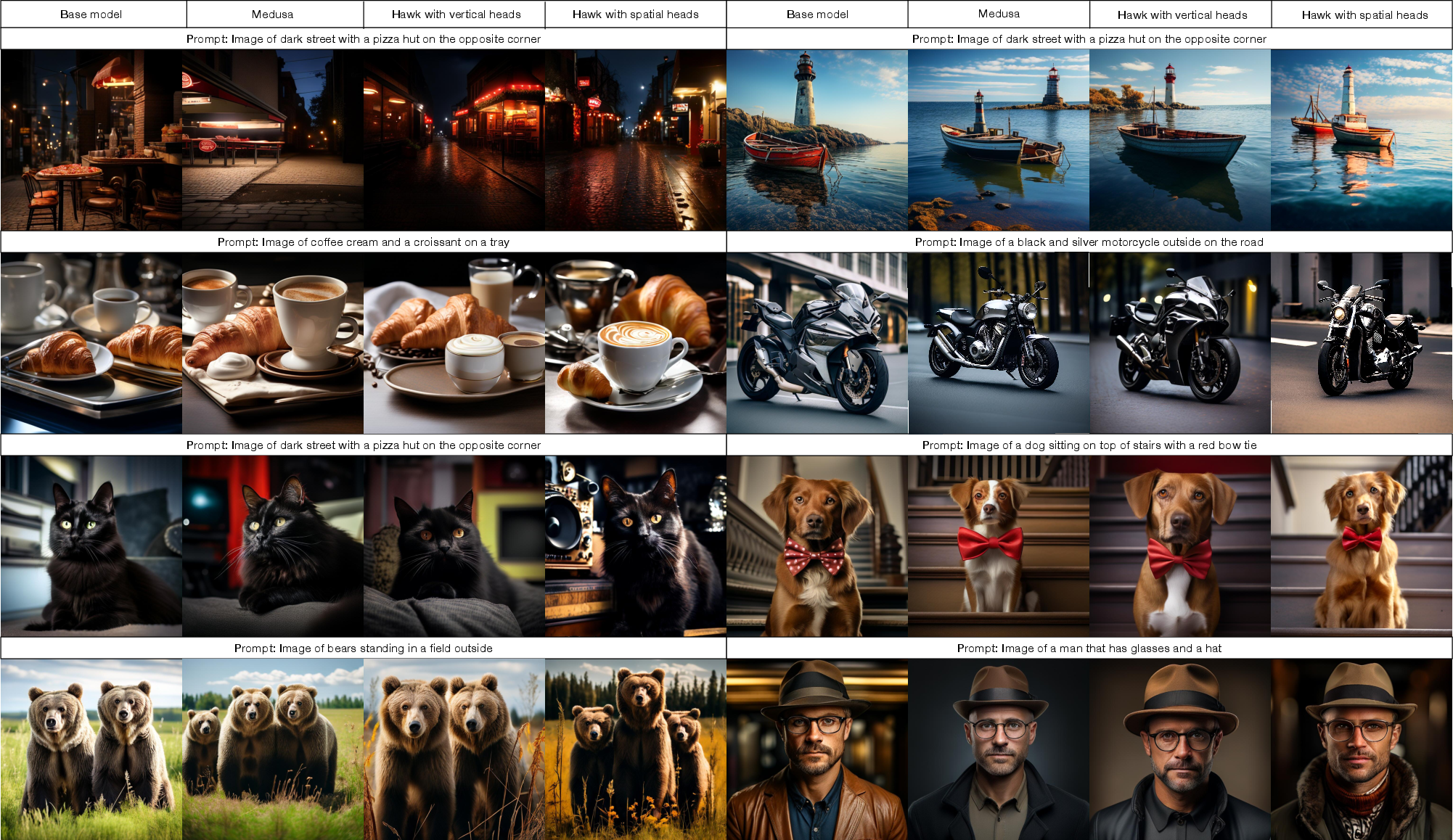
Figure 3: Qualitative comparison of images generated by base model, Medusa, Hawk with vertical heads, and Hawk with spatial heads, demonstrating maintained image quality and enhanced inference speed.
Theoretical analysis confirms that Hawk’s dual-direction speculative decoding preserves the original output distribution, with the residual probability of rejection (r(x)) reduced by the diversity of draft distributions.
Effectiveness of Vertical Draft Heads
Training loss analysis reveals that vertical draft heads experience less performance decay with increasing speculation depth compared to horizontal heads, despite operating at greater spatial distances.
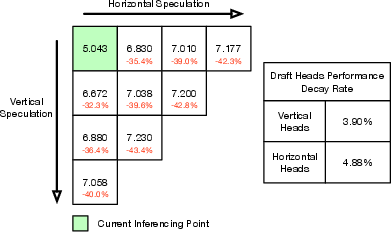
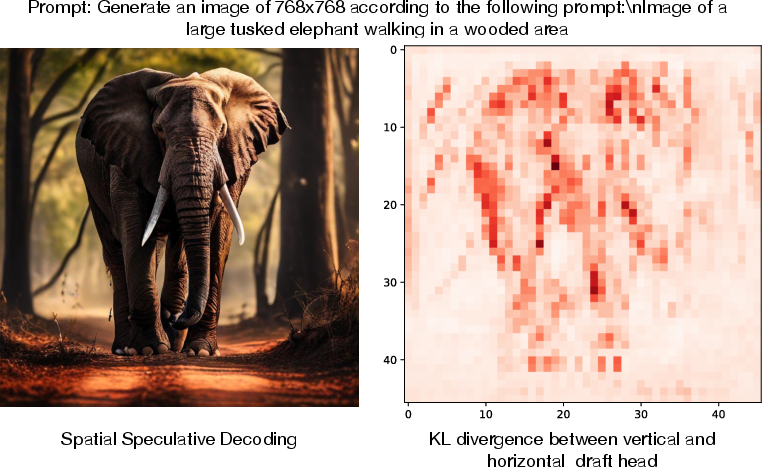
Figure 4: Training loss of draft heads at varying locations; vertical heads show lower loss and slower decay with increased speculation depth.
KL divergence between vertical and horizontal heads is more pronounced in complex image regions, indicating that vertical heads contribute unique information, broadening the candidate space and improving acceptance rates.
Parameter Sensitivity and Sampling Space
Image quality is sensitive to top-k and temperature parameters. Larger top-k values yield more detailed images but reduce speculative acceptance rates, while lower temperatures improve quality but restrict diversity.

Figure 5: Base model performance under varying top-k parameters, illustrating the trade-off between image detail and speculative decoding efficiency.

Figure 6: Base model performance under varying temperature parameters, highlighting the impact on image quality and sampling diversity.
Practical and Theoretical Implications
Hawk demonstrates that spatially aware speculative decoding can substantially accelerate AR image generation without relaxing verification thresholds or degrading output quality. The framework is compatible with existing speculative decoding backbones and can be extended to more advanced algorithms (e.g., Eagle, Hydra) for further efficiency gains. The dual-direction approach is theoretically justified to preserve the original model’s output distribution, and its minimal memory overhead facilitates integration into large-scale generative systems.
Conclusion
Hawk provides a principled and effective solution for accelerating autoregressive text-to-image generation by leveraging spatial context through dual-direction draft heads and spatial speculative decoding. The method achieves significant speedup while maintaining image fidelity, and its design is theoretically sound and practically efficient. Future work may explore integration with state-of-the-art speculative decoding frameworks and further optimization of draft head architectures for even greater acceleration and generalization across modalities.