The Economics of AI Training Data: A Research Agenda
Abstract: Despite data's central role in AI production, it remains the least understood input. As AI labs exhaust public data and turn to proprietary sources, with deals reaching hundreds of millions of dollars, research across computer science, economics, law, and policy has fragmented. We establish data economics as a coherent field through three contributions. First, we characterize data's distinctive properties -- nonrivalry, context dependence, and emergent rivalry through contamination -- and trace historical precedents for market formation in commodities such as oil and grain. Second, we present systematic documentation of AI training data deals from 2020 to 2025, revealing persistent market fragmentation, five distinct pricing mechanisms (from per-unit licensing to commissioning), and that most deals exclude original creators from compensation. Third, we propose a formal hierarchy of exchangeable data units (token, record, dataset, corpus, stream) and argue for data's explicit representation in production functions. Building on these foundations, we outline four open research problems foundational to data economics: measuring context-dependent value, balancing governance with privacy, estimating data's contribution to production, and designing mechanisms for heterogeneous, compositional goods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
The Economics of AI Training Data — Explained for a 14-year-old
1. What is this paper about?
This paper is about the “fuel” that powers AI: data. It asks a simple question with big consequences: if data is so important for training AI models, why don’t we have clear rules for how to buy, sell, measure, or reward it? The authors try to start a new field called “data economics” that explains how data should be treated in business and policy, just like we already do for things like labor and capital.
2. What questions are the authors trying to answer?
The paper focuses on a few plain questions:
- What makes data different from normal goods like oil or grain?
- How are AI companies actually buying and using data today?
- What are the right “units” for measuring and pricing data?
- How should economists include data in the “recipe” that produces AI?
- What are the biggest unsolved problems we need to crack next?
3. How did they study it? (Methods in simple terms)
The authors use four main approaches:
- They describe what makes data unusual:
- Nonrivalrous: If you and I both use the same dataset, it doesn’t get “used up.” It’s like a song file—many people can listen at once.
- Context-dependent: Data’s value depends on who’s using it and what they already have. A medical dataset might be priceless to a health lab, but useless to a game studio.
- Contamination risk: Overuse, copying errors, or hidden leaks can make data less useful over time—like clean water getting polluted.
- They look at history for clues:
- In the past, messy markets (like grain or oil) became easy to trade after people agreed on standards (like quality grades and benchmarks). The idea: perhaps we can do something similar for data.
- They collect real-world examples:
- They compile public information about AI data deals from 2020–2025. They find lots of one-off, private deals worth tens or even hundreds of millions of dollars, with no common price tags or clear rules.
- They propose a shared “language” for data units and pricing:
- A simple ladder of data units:
- Token: tiny pieces of text or numbers (like Lego studs).
- Record: one example (like one labeled photo or one sentence).
- Dataset: a curated collection of records (a well-organized folder).
- Corpus: a big bundle of datasets (a whole library).
- Stream: data that keeps coming over time (like a live news feed).
- They also suggest data should appear explicitly in the “production function” for AI. In normal words: when we model how AI output is made, we should write it as something like , where K is capital (like computers), L is labor (people’s work), D is data, and A is algorithms/technology. That way, data isn’t hidden—it’s counted on its own.
Some tricky ideas they explain with everyday language:
- Verification paradox: Buyers want to inspect data to see if it’s good, but if they see it, they can copy it. It’s like asking for a full copy of a secret recipe just to “check it”—once you see it, you have it.
- Legal opacity: Even if data looks fine, it’s hard to be sure who owns what or whether consent and copyrights are valid. Contracts and laws are complicated and unclear.
4. What did they find, and why does it matter?
The authors highlight several key findings:
- The data market is fragmented and messy.
- Most data deals are custom, private, and inconsistent. There’s no standard “price per dataset,” and different buyers pay different amounts depending on their needs.
- There are five main ways people pay for data (plus one quiet, hidden way).
- Per-unit pricing: pay per book, per minute of video, per labeled example.
- Aggregate licensing: pay for time-limited access to a big collection.
- Service-based pricing: pay people to label, clean, or prepare data.
- Commissioning: pay to create brand-new, custom data.
- Open commons: public datasets funded by governments or volunteers.
- Also common but quieter: “implicit exchanges,” where platforms collect user data in return for free services (your activity trains their AI).
- Most money doesn’t reach original creators.
- In many deals, platforms and publishers get paid, but the people who actually made the content (like users or journalists) are often left out. A few exceptions exist, but they’re rare.
- A shared set of data “units” can reduce confusion.
- Talking clearly about tokens, records, datasets, corpora, and streams helps everyone understand what’s being bought and how to price it.
- Data should be treated as its own input in AI production.
- AI quality depends on data, computers, and algorithms working together. Sometimes you can swap one for another (e.g., generate synthetic data), but they’re often complementary. This matters for companies deciding where to invest—and for making fair policies.
- Big open problems remain. The four most important ones: 1) Measuring context-dependent value: How do you price data that changes in value depending on who else has it and what it’s mixed with? 2) Governance and privacy: How do we protect people while still letting useful data be pooled and shared fairly? 3) Estimating contribution: How much of an AI model’s success comes from data versus compute versus algorithms? 4) Market design: How do you build marketplaces for “combinable” goods like data, where value depends on the mix?
Why it matters:
- Without standards, the AI economy is inefficient and unfair: prices are unpredictable, deals take too long, creators get skipped, and legal risks are high. With standards, we could grow faster, pay people more fairly, and reduce conflicts.
5. What could this change in the real world?
If this research agenda moves forward, it could:
- Help build fairer data markets where creators, platforms, and AI labs each get a reasonable share.
- Make AI development safer and cheaper by improving data quality and preventing contamination (like benchmark leaks or poisoned examples).
- Guide governments to craft smarter rules about ownership, consent, and privacy—so data can be useful without harming people.
- Encourage industry to set standards (like “grades” for data quality and clear licenses), similar to what happened with grain and oil.
- Clarify how much to invest in data versus compute, making the whole AI pipeline more efficient.
In short: this paper lays the foundation for treating data as a first-class economic good—something we can measure, price, trade, and govern—so the benefits of AI are larger, safer, and more fairly shared.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed as actionable directions for future research.
- Operationalizing the proposed data-unit hierarchy: define interoperable metadata schemas, quality/coverage metrics, and APIs for tokens/records/datasets/corpora/streams; validate across modalities (text, audio, video, multimodal).
- Standardized, comprehensive registry of AI training data deals: build an open, verifiable database with structured fields (price, modality, exclusivity, term, indemnities, API-credit components, rev-share, creator compensation), addressing current reliance on selective public reports.
- Functional form of data in production: estimate the specific form of Y = f(K, L, D, A), including returns to scale in D, cross-partial elasticities with K and L, and domain/task heterogeneity (pre-training vs fine-tuning vs inference).
- Mapping technical to economic value: quantify how tokens/records/diversity/quality translate to marginal revenue, cost savings, or productivity; run controlled training experiments linked to business KPIs.
- Verification paradox solutions: design and test “try-before-you-buy” mechanisms (e.g., TEEs, secure enclaves, privacy-preserving sampling, cryptographic proofs) that allow value assessment without enabling copying; analyze incentive compatibility and pricing implications.
- Legal provenance and rights clarity: create machine-readable licensing ontologies and provenance standards spanning copyright, privacy, consent, and terms-of-service; measure rights-clearance costs and litigation risk across jurisdictions.
- Dynamic consent and revocation: mechanisms to reflect consent changes post-ingestion; economic and technical feasibility of partial unlearning/redistribution and associated liability allocation.
- Attribution and remuneration: develop practical, robust data-contribution attribution (post-training) for multi-source corpora; design micro-royalty mechanisms and payment rails; pilot and evaluate data unions/co-ops for bargaining and payout governance.
- Contamination and emergent rivalry: quantify leakage, overuse, poisoning, and staleness externalities; model optimal access/refresh policies and pricing that internalize contamination risks.
- Market power from exclusive access: causal identification of exclusivity’s competitive effects; evaluate antitrust remedies (e.g., data portability, interoperability mandates) on innovation and welfare.
- Synthetic data economics: when does synthetic data substitute/complement real data; quality-adjusted pricing and valuation; legal exposure from training on synthetic derivatives; feedback loops and mode collapse risks.
- Cross-border data trade: model effects of data localization, adequacy decisions, and trade agreements on costs, access, and competitiveness; design compliance-efficient cross-border mechanisms.
- Externalities and welfare pricing: methods to price-in privacy loss, bias, and safety risks (e.g., Pigouvian fees, liability rules); empirical welfare analyses of alternative governance regimes (platform ownership, data trusts, commons).
- Provenance and authenticity at training-time: test robustness of watermarking and C2PA-like approaches under transformations and model training; standardize audit trails linking inputs to trained artifacts.
- Auditing closed labs: protocols for third-party verification of training sets (e.g., secure logging, attestation, redacted proofs); regulatory reporting templates and enforcement mechanisms.
- Token-level metering for training: privacy-preserving usage accounting that can support per-token or per-record remuneration during training (not just inference); resistance to gaming.
- Contract design for hybrid deals: model the long-run lock-in effects of cash + API-credit structures and exclusivity; test clauses that mitigate anticompetitive switching costs (e.g., credit portability, MFN transparency).
- Sustainability of open data commons: viable funding, governance to prevent capture, and quality assurance; interaction effects with private markets (e.g., price discipline vs free-riding).
- Data depreciation and concept drift: estimate obsolescence rates by domain; build early-warning indicators and refresh policies; incorporate decay into asset valuation and contracts.
- Extending beyond text: modality-specific quality metrics, sampling strategies, and cost models for audio/video/sensor/multimodal data; compute–data trade-offs differ by modality and need measurement.
- Unlocking “dark data”: sector-by-sector mapping of availability, legal constraints, and cleaning costs; ROI benchmarks for data capital formation; privacy-preserving release mechanisms (e.g., synthetic twins, secure federations).
- Exclusivity pricing and allocation: auction formats for interdependent, compositional goods; design for partial exclusivity, tiered access, and time-limited rights with externality-aware pricing.
- Contract standardization: machine-readable licenses with default clauses for indemnity, provenance warranties, revocation, and opt-outs; open templates and compliance tooling for small creators and SMEs.
- Safe preview protocols: systems for performance probing via secure querying/sandboxes without exfiltration; statistical guarantees on representativeness of previews for price discovery.
- Econometric identification strategies: instruments and natural experiments (policy shocks, robots.txt changes, platform outages) to isolate causal effects of data access on model performance and firm outcomes.
- Distributional impacts on creators: measure revenue flows across creators vs intermediaries; study cross-country and demographic equity; test minimum compensation standards and collective bargaining frameworks.
- Accounting treatment and finance: methods for capitalizing data assets (amortization, impairment), fair value estimation, and disclosure standards; links between data investment and firm valuation.
- Risk transfer markets: warranties/indemnities/insurance products for data legality and quality; actuarial models and pricing; empirical loss data collection.
- Environmental footprint: quantify energy, storage, and collection costs of data pipelines; mechanisms to internalize environmental costs (e.g., green premiums, reporting standards).
- License interoperability and revocation at scale: resolve conflicts among heterogeneous licenses; mechanisms for machine-readable, enforceable revocation across downstream derivatives and checkpoints.
- Evidence limitations in the paper’s dataset: address selection bias toward large, English-language, publicized deals; include failed/terminated deals and smaller transactions; propose representative sampling frames.
- Modeling heterogeneous buyer contexts: game-theoretic models for interdependent valuations and compositional synergies among buyers; contract menus that screen by type and existing holdings.
- Validity of lifecycle segmentation: test whether pre-train/fine-tune/inference market segmentation persists under evolving architectures (e.g., retrieval-augmented, continual learning).
- Policy experimentation: design and evaluate sandboxes for data trusts, collective licensing regimes, and government-facilitated exchanges; define outcome metrics (price discovery, inclusion, innovation).
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting the paper’s documented pricing mechanisms, unit hierarchy, and governance insights to practical workflows.
- Token- and record-level metering and billing for AI data services
- Sectors: software, media, education
- What: Introduce usage-based billing at the token/record level for data access and transformation (annotation, cleaning), aligning costs to data consumption.
- Tools/products/workflows: Stripe usage-based billing APIs; LLM proxy metering (OpenRouter, Cloudflare, Vercel, Helicone); labeling platforms (Scale AI).
- Assumptions/dependencies: Reliable metering; clear ToS permitting AI training use; acceptance of per-unit pricing by data owners and buyers.
- Deal structuring toolkit for data licensing and commissioning
- Sectors: software, media, finance (corporate development), healthcare (data partnerships)
- What: Standardize negotiation playbooks across per-unit licensing, aggregate licenses, service-based pricing, and commissioning (custom data creation).
- Tools/products/workflows: Term sheet templates for exclusivity, duration, hybrid cash+API credits; legal checklists for copyright/consent verification; price calculators referencing public deals.
- Assumptions/dependencies: Legal clarity on rights; access to benchmarking data; broker/intermediary capacity for verification.
- Data contamination and aging hygiene programs
- Sectors: software, healthcare, education, robotics
- What: Operationalize contamination risk management (benchmark leakage, preference leakage, poisoning, dataset staleness) during pretraining and finetuning.
- Tools/products/workflows: Data observability dashboards; contamination scanners and red-teaming; dataset freshness SLAs; provenance tags to quarantine suspect sources.
- Assumptions/dependencies: Ability to instrument pipelines; internal incentives to prioritize quality over volume; access to trusted reference sets.
- Provenance-aware ML auditing and compliance
- Sectors: media, healthcare, finance, public sector
- What: Trace training inputs and transformations to meet licensing, consent, and audit requirements.
- Tools/products/workflows: C2PA metadata; content credentials; tamper-evident logs; “proofs of retrievability” (PoR) for source data; audit trails for ML (Boenisch et al.).
- Assumptions/dependencies: Adoption of provenance standards by data providers; storage of immutable logs; tolerance for overhead in regulated contexts.
- Consent-aware crawling and policy updates for data platforms
- Sectors: media, education platforms, forums, enterprise SaaS
- What: Update robots.txt and ToS to explicitly govern AI training use; implement opt-outs and consent signals aligned with Longpre-style consent protocols.
- Tools/products/workflows: “AI use” flags in site metadata; consent management dashboards for creators/users; rate-limited and policy-compliant crawlers.
- Assumptions/dependencies: Legal counsel alignment; engineering bandwidth; clear creator communications.
- Commissioning pipelines for domain-specific datasets
- Sectors: healthcare (clinical notes, imaging), finance (transactions anomalies), energy (sensor telemetry), robotics (fleet logs)
- What: Fund targeted data creation when suitable corpora don’t exist; contract experts and operators to collect or synthesize high-quality domain data.
- Tools/products/workflows: Expert marketplaces (e.g., Mercor-style); standardized data schemas and QA protocols; secure upload and validation; payment rails tied to deliverables.
- Assumptions/dependencies: Access to domain experts; buyer specifications; safe handling of sensitive data.
- Hybrid cash + API credit licensing to control lock-in
- Sectors: software, media, education
- What: Use mixed payments (cash plus credits) to finance data access while managing vendor lock-in via explicit switching clauses and caps.
- Tools/products/workflows: Contract clauses for credit usage windows; multi-provider strategy for redundancy; metering to prevent overuse.
- Assumptions/dependencies: Negotiation leverage; awareness of future switching costs; finance/legal collaboration.
- Creator collectives, unions, and negotiated revenue sharing pilots
- Sectors: media (newsrooms, authors), music, education
- What: Implement per-unit splits and revenue-sharing agreements (e.g., 50/50 book splits, track-level payments, newsroom shares) via collective bargaining or platform mediation.
- Tools/products/workflows: Creator portals showing usage and payouts; standardized content registries; dispute resolution processes.
- Assumptions/dependencies: Aggregator cooperation; reliable attribution at the dataset level; union or association leadership.
- Open-commons funding and curation playbooks
- Sectors: public policy, academia, energy (satellite), healthcare (non-PHI research data)
- What: Expand public datasets (text, images, satellite, protein structures) to discipline prices and increase equitable access.
- Tools/products/workflows: Grants targeting under-supplied domains; stewardship bodies; FAIR data principles; mandatory open access for funded research outputs.
- Assumptions/dependencies: Budget allocation; governance to prevent misuse; sustainability plans for maintenance.
- Privacy-preserving data access for regulated domains
- Sectors: healthcare, finance, energy
- What: Allow training/analytics without raw data transfer using federated learning, confidential computing, and differential privacy.
- Tools/products/workflows: Secure enclaves (e.g., Ekiden-like platforms); FL frameworks; DP budgets; access audits.
- Assumptions/dependencies: Performance overhead acceptance; regulatory buy-in; partner infrastructure readiness.
- Internal data investment dashboards treating data as a distinct production input
- Sectors: software, finance (strategy), robotics
- What: Track spend and returns on data separate from compute and labor to inform model training strategies and ROI.
- Tools/products/workflows: Data capital expenditure (CapEx) trackers; marginal performance per dataset reports; procurement roadmaps by pipeline stage.
- Assumptions/dependencies: Cross-functional data, finance, and ML ops coordination; basic measurement of data’s marginal impact.
Long-Term Applications
The following applications need further research, standardization, or institutional development, drawing on the paper’s proposed hierarchy, pricing taxonomy, and production-function framing.
- Standardized data exchanges, registries, and grading (commodity market analogs)
- Sectors: software, media, healthcare, robotics
- What: Create exchanges with listing requirements, grading standards, and verified provenance to trade datasets, corpora, and streams.
- Tools/products/workflows: Data grading rubrics; third-party certifiers; reference benchmarks and futures-like contracts for data access.
- Assumptions/dependencies: Resolution of verification paradox (inspect-without-copy mechanisms); legal standardization across jurisdictions.
- Corporate data accounting standards and disclosure
- Sectors: finance, software, public companies
- What: Recognize data as a capital asset in financial reporting; disclose data investments and quality metrics.
- Tools/products/workflows: GAAP/IFRS updates; audit procedures; valuation models linked to production outcomes.
- Assumptions/dependencies: Regulator and accounting-body consensus; reliable valuation methods; minimal greenwashing.
- Mechanism design for heterogeneous, compositional data markets
- Sectors: software, finance (market design), policy
- What: Auctions and contracts that handle interdependent valuations and compositional effects without full inspection.
- Tools/products/workflows: Privacy-preserving sampling proofs (e.g., zero-knowledge); sealed-bid auctions with reveal-later verification; managed marketplaces with partial preview.
- Assumptions/dependencies: Practical cryptographic protocols; buyer/seller adoption; scalable enforcement.
- Attribution and creator compensation rails
- Sectors: media, education, music
- What: Build lineage and attribution systems to support micropayments or revenue shares to original creators whose works train models.
- Tools/products/workflows: Proof of Learning; robust watermarking; content registries; payout orchestration (“Data Capital Locked” instruments).
- Assumptions/dependencies: Attribution feasibility at scale; low false positives; alignment of platform incentives.
- Data contamination insurance and ratings
- Sectors: finance (insurance), software, healthcare
- What: Underwrite risks from poisoned/aged datasets; rate providers on quality and contamination resistance.
- Tools/products/workflows: Risk models using contamination scans; insurer-backed remediation playbooks; market-wide quality indices.
- Assumptions/dependencies: Actuarial data; standardized incident reporting; accepted rating methodologies.
- National and cross-border data commons and treaties
- Sectors: policy, energy (satellite/climate), healthcare (research), education
- What: Formalize public-good datasets and cross-jurisdictional sharing agreements with privacy, security, and reciprocity.
- Tools/products/workflows: International standards; treaty governance boards; funding tied to open access and provenance guarantees.
- Assumptions/dependencies: Diplomatic coordination; harmonized privacy laws; cyber resilience.
- Competition policy for continuous data streams
- Sectors: policy, software, e-commerce
- What: Regulate access to incumbent platforms’ streams to reduce data moats while preserving privacy and innovation.
- Tools/products/workflows: Access regimes with privacy budgets; regulated APIs; transparency reporting on data withholding.
- Assumptions/dependencies: Legal authority; robust privacy techniques; measured thresholds to avoid overregulation.
- Sector-specific data unions and trusts (patient, worker, student)
- Sectors: healthcare, labor, education
- What: Collective governance enabling pooled bargaining for data licensing and privacy-preserving access.
- Tools/products/workflows: Trust charters; consent orchestration; benefit-sharing contracts; compliance audits.
- Assumptions/dependencies: Enabling legislation; institutional capacity; equitable governance to prevent capture.
- Empirical estimation programs for data’s production function contribution
- Sectors: academia, software, finance (investment analysis)
- What: Multi-year studies linking dataset composition to model performance and economic outcomes, informing elasticities and substitution with compute.
- Tools/products/workflows: Access to firm-level training data; controlled experiments; open benchmarks on performance-per-token or per-record.
- Assumptions/dependencies: Data-sharing incentives; privacy safeguards; reproducibility culture.
- Synthetic–real data optimization markets
- Sectors: software, robotics, healthcare imaging
- What: Tradeoffs and procurement strategies balancing synthetic and real data for coverage, edge cases, and cost.
- Tools/products/workflows: Quality grading for synthetic data; contamination-aware mixing; SLA-backed synthetic providers.
- Assumptions/dependencies: Reliable quality measures; domain-specific transferability; monitoring for model collapse.
- Data-backed financing instruments
- Sectors: finance, software
- What: Collateralize high-quality data assets; structure revenue-sharing securities linked to data access streams.
- Tools/products/workflows: Valuation models; custodial services; legal frameworks for data collateral and default remedies.
- Assumptions/dependencies: Recognized property rights; standardized valuation and custody; investor appetite.
- Robotics and energy telemetry clearinghouses
- Sectors: robotics (autonomy), energy (grid, renewables)
- What: Shared repositories for fleet logs and grid sensor data with standardized schemas and tiered access.
- Tools/products/workflows: Secure ingestion; privacy-preserving analytics; pay-per-stream pricing; safety certification layers.
- Assumptions/dependencies: Operator participation; standardization across vendors; strong safety and privacy controls.
These applications leverage the paper’s core contributions: a hierarchy of exchangeable data units, documented pricing mechanisms, explicit inclusion of data in production analysis, and a targeted research agenda. Feasibility hinges on resolving the verification paradox, establishing provenance and rights, and aligning incentives across creators, platforms, buyers, and regulators.
Glossary
- Adverse selection: A market failure where sellers know more about product quality than buyers, leading to low-quality goods dominating exchanges. "creating severe adverse selection where sellers cannot credibly signal quality and buyers cannot distinguish high-quality from low-quality data without access"
- Adversarial poisoning: The deliberate insertion of harmful or misleading examples into datasets to degrade model performance. "contamination effects (dataset aging, adversarial poisoning, benchmark leakage, preference leakage) and overuse create practical rivalry"
- Aggregate licensing: A contract granting time-limited access to a curated body of data for a fixed fee, without transferring ownership. "Aggregate licensing dominates large-scale enterprise deals: buyers pay fixed fees for time-limited access to curated corpora or feeds."
- Attribution: The identification and crediting of specific data sources that contributed to a trained model. "Attribution is computationally intractable when models train on millions of sources."
- Benchmark leakage: Unintended exposure of test content in training data, inflating evaluation scores. "contamination effects (dataset aging, adversarial poisoning, benchmark leakage, preference leakage) and overuse create practical rivalry"
- CES (Constant Elasticity of Substitution): A production function family where input substitution elasticity is constant, used to model trade-offs among factors. "We remain agnostic about whether data follows Cobb-Douglas, CES, or other functional formsâthat is an empirical question subsequent research should address."
- Cobb-Douglas: A production function with multiplicative inputs and unitary elasticity of substitution, often used in growth and productivity analysis. "We remain agnostic about whether data follows Cobb-Douglas, CES, or other functional formsâthat is an empirical question subsequent research should address."
- Commissioning: Paying to create new, tailored data assets rather than licensing existing ones. "Commissioning pays for new data creation when required corpora don't exist."
- Complementarity: When the productivity of one input increases with the quantity or quality of another input. "We observe both complementarity and substitutability."
- Compositional goods: Assets whose value depends on how they combine with other heterogeneous components. "Can we design markets and mechanisms for heterogeneous, compositional goods?"
- Consent protocols: Technical or policy mechanisms by which data owners restrict automated collection or specific uses of their data. "While nonrival in principle, data has become effectively excludable as consent protocols restrict crawling and AI use"
- Context-dependence: The property that a dataset’s value varies with the application, holder’s existing data, and competitive access. "nonrivalry, context-dependence, and emergent rivalry through contamination"
- Corpus: A large, aggregated collection of datasets used for training or analysis. "Aggregate of datasets"
- Data unions: Collective organizations that pool individuals’ data to negotiate rights and compensation. "Emerging data unions are experimenting with collective bargaining to address this"
- Data wall: A practical limit in available high-quality training data beyond which further scaling evidence is sparse. "researchers face a ``data wall'' around 15 trillion tokens of public internet text"
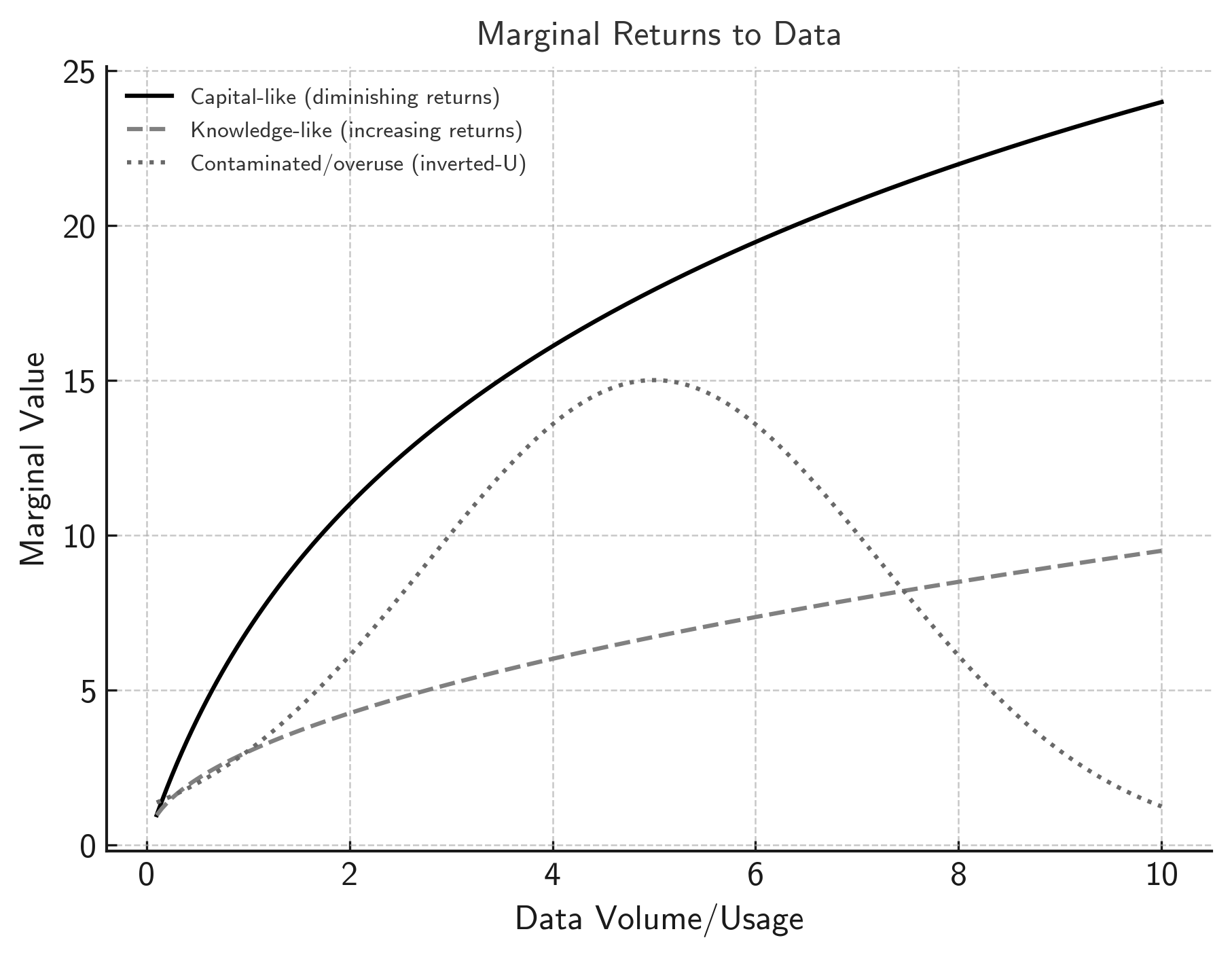
- Diminishing marginal returns: A pattern where each additional unit of an input contributes less to output than the previous one. "suggesting diminishing marginal returns from a model performance perspective."
- Excludable: A characteristic of a good where access can be restricted to paying or authorized users. "it is nonrivalrous in principle: its reuse does not diminish its supply, and only partially excludable, since access can be restricted but copies are easily made."
- Exclusivity: Contractual arrangements granting sole access rights to a dataset, often at a premium. "Most licenses are non-exclusive---providers retain ownership and monetize simultaneous access to multiple buyers, but exclusivity like the News Corp deal commands price premiums."
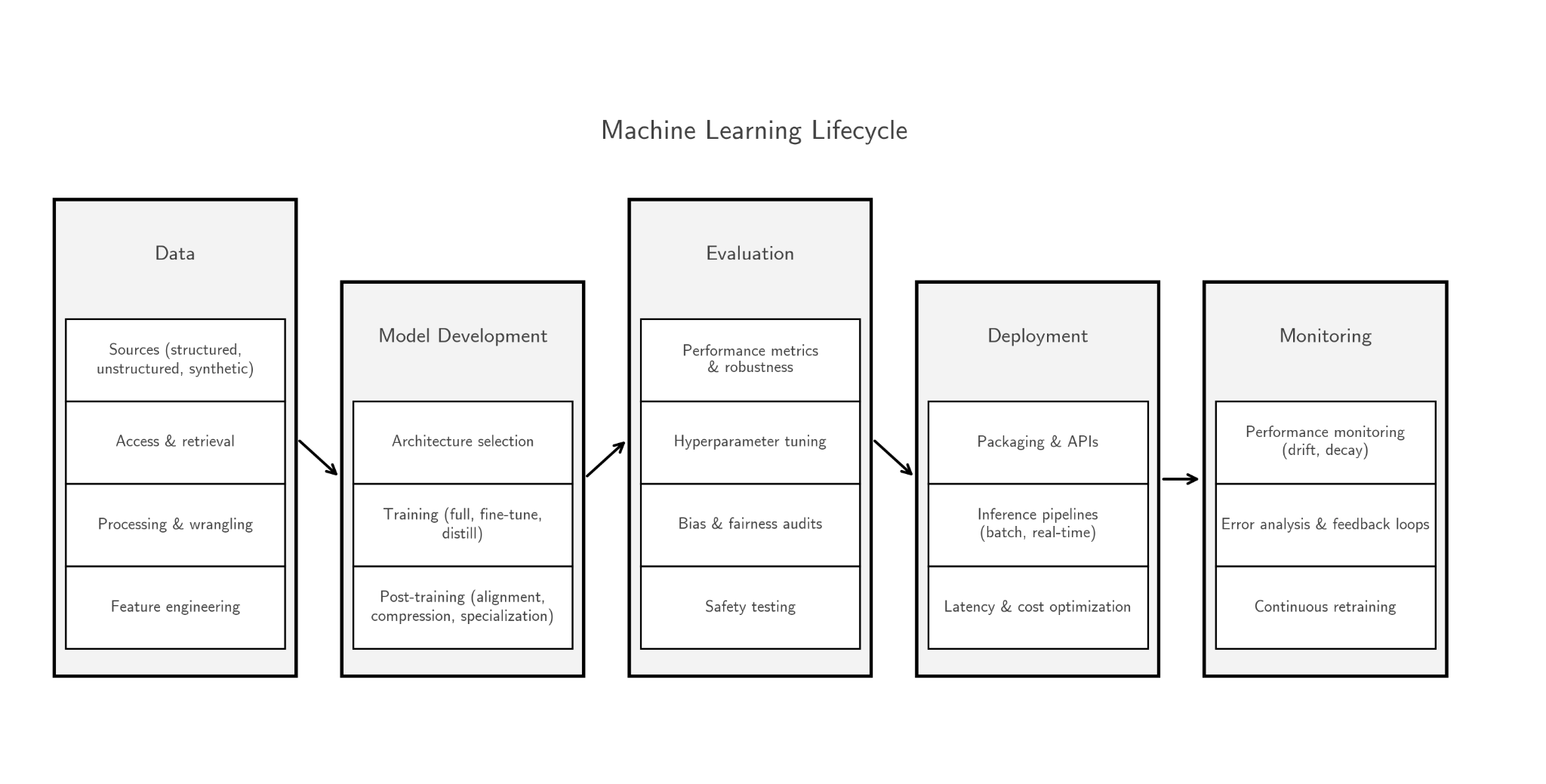
- Fine-tuning: Post-training adaptation of a model on targeted, high-quality data to specialize or align behavior. "pre-training, fine-tuning, and inference"
- Futures contracts: Standardized agreements to buy or sell a commodity at a future date and price, aiding market standardization and hedging. "Futures contracts and spot benchmarks: standardized delivery and pricing"
- Heterogeneity: The high diversity across datasets that leads to varied marginal value and complicates standard pricing. "heterogeneity creates variation in marginal value."
- Inference pricing: Charging based on model usage during inference, often metered at the token level. "traded implicitly (e.g., through inference pricing); value tied to marginal compute cost."
- Legal opacity: Uncertainty about rights and permissions over data that cannot be resolved by inspection alone. "Second, legal opacity: data's legal status (licensing rights, copyright clearance, consent validity) cannot be verified through inspection alone"
- Lock-in: Increased switching costs that entrench a buyer-supplier relationship, often via credits or integration. "These hybrid payments create lock-in: as providers integrate APIs into production systems, switching costs rise and relationships entrench."
- Marginal product (of data): The additional output attributable to a small increase in data input, holding other factors constant. "deriving the marginal product of data and its elasticities with other inputs"
- Nonrivalry: A property where multiple agents can use the same data simultaneously without depleting it. "nonrivalry, context-dependence, and emergent rivalry through contamination"
- Open commons: Publicly accessible datasets maintained by institutions or communities, providing a competitive floor for private markets. "Open commons as competitive baseline."
- Per-unit pricing: Charging proportionally to the number of discrete items accessed or used (e.g., books, tracks, minutes of video). "Per-unit pricing charges per discrete unit: licensing books at US$5,000 each with 50/50 author splits, music at â¬0.30--â¬2.00 per track, and videos at US$1--4 per minute."
- Perplexity: A language modeling metric indicating how well a model predicts a sample; lower is better. "this research measures contribution in technical metrics (perplexity, accuracy) rather than economic units (prices, marginal products)"
- Pre-training: The stage of training on very large, general-purpose datasets before specialization. "Pre-training predominantly uses large-scale publicly available datasets, where volume drives value."
- Preference leakage: Unintended exposure of users’ preferences via training data, potentially harming privacy or evaluation integrity. "contamination effects (dataset aging, adversarial poisoning, benchmark leakage, preference leakage) and overuse create practical rivalry"
- Privacy-preserving computation: Techniques that enable data analysis or learning without exposing sensitive information. "technical infrastructure for privacy-preserving computation and provenance tracking"
- Production function: A formal mapping from inputs (capital, labor, data, technology) to output used to analyze productivity. "Current production function formulations do not explicitly model data as a distinct input."
- Provenance tracking: Recording the origins and transformations of data to establish lineage, integrity, and compliance. "technical infrastructure for privacy-preserving computation and provenance tracking"
- Returns to scale: How output changes as all inputs are proportionally scaled, here focusing on data’s scaling behavior. "Returns to scale on data represent another critical dimension."
- Service-based pricing: Paying for data transformation services (annotation, cleaning, validation) rather than the data asset itself. "Service-based pricing bundles data with transformation labor"
- Stream: A continuous, time-ordered flow of data, often priced by access or throughput rather than ownership. "Continuous, time-ordered feed"
- Substitutability: The extent to which one input (e.g., compute) can replace another (e.g., data) in production. "We observe both complementarity and substitutability."
- Token: The smallest processable unit of text or input used by LLMs for training or inference. "Smallest processable data fragment (e.g., tokenized text or scalar input)"
- Verification paradox: The dilemma where buyers must inspect data to assess quality, but inspection enables perfect copying. "First, the verification paradox: quality and suitability cannot be assessed without examining data, yet examination enables copying"
- Warehouse receipts: Documents certifying stored commodity quality/quantity, enabling standardized trade and financing. "Grain futures and warehouse receipts: standardized grading and storage contracts"
Collections
Sign up for free to add this paper to one or more collections.