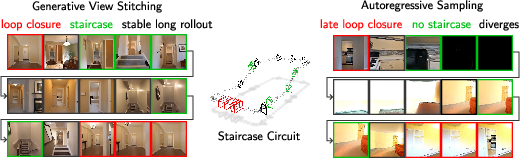
Generative View Stitching
Abstract: Autoregressive video diffusion models are capable of long rollouts that are stable and consistent with history, but they are unable to guide the current generation with conditioning from the future. In camera-guided video generation with a predefined camera trajectory, this limitation leads to collisions with the generated scene, after which autoregression quickly collapses. To address this, we propose Generative View Stitching (GVS), which samples the entire sequence in parallel such that the generated scene is faithful to every part of the predefined camera trajectory. Our main contribution is a sampling algorithm that extends prior work on diffusion stitching for robot planning to video generation. While such stitching methods usually require a specially trained model, GVS is compatible with any off-the-shelf video model trained with Diffusion Forcing, a prevalent sequence diffusion framework that we show already provides the affordances necessary for stitching. We then introduce Omni Guidance, a technique that enhances the temporal consistency in stitching by conditioning on both the past and future, and that enables our proposed loop-closing mechanism for delivering long-range coherence. Overall, GVS achieves camera-guided video generation that is stable, collision-free, frame-to-frame consistent, and closes loops for a variety of predefined camera paths, including Oscar Reutersv\"ard's Impossible Staircase. Results are best viewed as videos at https://andrewsonga.github.io/gvs.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to make long, smooth, and believable videos using AI when the camera’s path is decided ahead of time (like planning a drone’s flight). The method is called Generative View Stitching (GVS). It helps the AI “plan ahead,” so the video matches the entire camera path without crashing into objects or falling apart.
Simple Goals of the Study
The authors wanted to solve a common problem in AI video generation:
- Current AI video models can stay consistent with the past but struggle to be consistent with the future. That means they sometimes create scenes that the camera later has to move through (like walls), causing the video to “break.”
- The goal is to generate long videos that follow a predefined camera path, avoid collisions, stay consistent frame-to-frame, and even “close loops” (for example, when the camera goes around a circle and returns to the starting point, it should look like the same place).
How Did They Do It? Methods in Everyday Terms
To make this understandable, picture these ideas:
The problem with “autoregressive” videos
- Many AI video systems work like writing a story one paragraph at a time: they only look at what was already written and don’t know what’s coming next.
- If your camera path is already planned (e.g., walk forward then turn right), the AI might invent a wall right in front of you. Later, when the camera must follow the path, it would “walk through” the wall, and the video collapses.
The GVS idea: generate all parts together
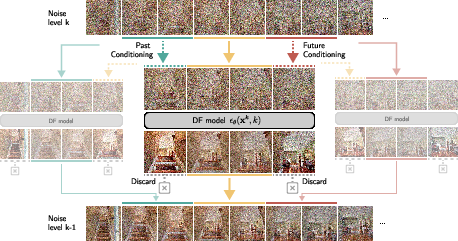
- Instead of making the video strictly one piece at a time, GVS splits the whole video into chunks (short sections) and generates them in parallel (at the same time), while making neighboring chunks talk to each other.
- Think of sewing patches of a quilt: you design each patch while constantly checking that it fits nicely with the patches next to it, so the seams are invisible and everything lines up.
Here’s the high-level recipe:
- Divide the full video into chunks that are shorter than what the model can handle at once (its “context window”).
- For each chunk, the model also brings in a bit of the past and a bit of the future chunk so it can make the current piece agree with both sides.
- After each small step, the model updates the current chunk and discards the helper chunks (it doesn’t replace them yet—those get generated in their own turns).
This works with off-the-shelf video models trained using “Diffusion Forcing,” a popular training style that lets the model flexibly use or ignore context. No special retraining is needed.
Omni Guidance: listen to past and future more strongly
- “Guidance” means steering the model to produce images that fit certain conditions (like following the camera path).
- In diffusion models, you start from random noise (like TV static) and slowly clean it up. The “score function” is the model’s internal sense of “how to change the picture so it gets closer to a realistic scene.”
- Omni Guidance strengthens the model’s attention to both the past and the future chunks during generation. It’s like telling the model: “Make this part match your neighbors and the planned camera route,” not just “make a good picture.”
In simple terms:
- Without Omni Guidance, the model may treat all chunks equally noisy and fail to learn enough from neighbors.
- With Omni Guidance, the model better respects the path and nearby chunks, leading to smoother transitions and fewer “scene jumps.”
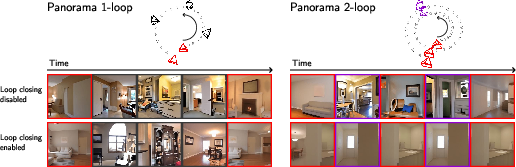
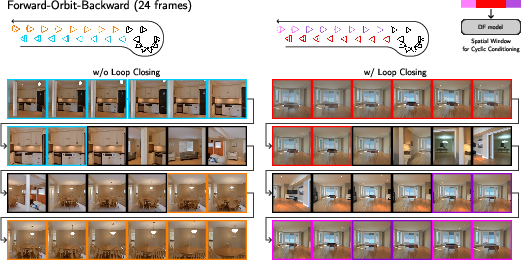
Closing loops: cyclic conditioning
- Loop closing means: if the camera goes in a loop (like a full circle), the view when you get back should look like the same place.
- The model alternates between two types of windows:
- Temporal windows: look at chunks just before and after in time.
- Spatial windows: look at chunks that are far apart in time but close together in 3D space (for example, frames at the start and end of a circular path).
- By alternating these windows step-by-step, information spreads across the whole video so loops visually “lock in” and feel coherent.
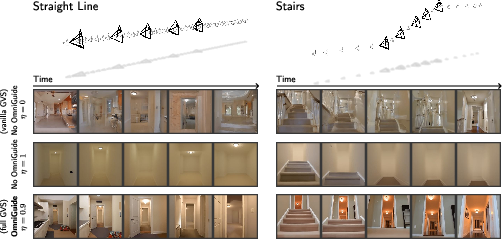
A note on “stochasticity” (randomness) and smoothness
- Diffusion models add a little random noise at each step to explore possibilities. Adding more noise can help different chunks agree (better consistency), but too much can make the video overly smooth or blurry.
- The paper shows that using “partial” randomness plus Omni Guidance gives the best of both worlds: strong consistency without losing detail.
Main Findings and Why They Matter
The authors tested GVS on several camera paths:
- Straight lines
- Circles and panoramas with 1 or 2 loops
- Staircases, including an “Impossible Staircase” inspired by optical illusions
They compared GVS with:
- Autoregressive sampling (the “one step at a time” approach)
- A stitching baseline called StochSync
Key results:
- GVS produced videos that stayed consistent frame-to-frame and over long ranges (especially when closing loops), avoided collisions with the generated scene, and matched the planned camera trajectory.
- Autoregressive methods often collided with objects or stitched together mismatched scenes at the last minute to close loops.
- StochSync avoided collisions but often “shape-shifted” the scene, causing poor temporal consistency.
- GVS achieved similar or better visual quality while being more stable and reliable.
Why this matters:
- If you want to generate long camera-guided videos—like movie scenes, drone routes, or driving simulations—you need the AI to plan for the future, not just remember the past. GVS makes that possible without expensive retraining.
Implications and Potential Impact
- Film and animation: Creators can design long, complex camera movements and trust the AI to produce stable, continuous scenes without sudden glitches.
- Virtual reality and games: Smooth loop closures and collision-free paths improve immersion and realism.
- Robotics and autonomous driving simulations: Predefined routes need future-aware generation to avoid impossible scenes and crashes.
- Research and engineering: GVS is “training-free” with common diffusion video models, making it easier to adopt and extend.
In short, Generative View Stitching helps AI “think ahead” while generating videos, leading to longer, cleaner, and more reliable results—especially for camera paths that loop or traverse complex spaces.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored, and suggests concrete directions future work could pursue:
- Lack of theoretical guarantees for Omni Guidance: no formal analysis of whether the modified score function provably approximates the intended conditional , nor of its convergence, bias, and stability properties under different guidance scales and noise schedules.
- Effective receptive field is not global in practice: the paper observes that information does not propagate sufficiently to close loops without explicit cyclic conditioning; a quantitative analysis of cross-chunk information flow and an objective measure of the “effective receptive field” across denoising steps is missing.
- Guidance parameterization and scheduling: the guidance scale and stochasticity factor are hand-tuned; there is no principled scheduler (per-timestep or per-chunk) to balance consistency vs. sharpness, nor adaptive schemes driven by online consistency metrics.
- Chunking strategy design: only non-overlapping chunks are used; the impact of overlapping chunks, variable chunk lengths, and boundary-handling strategies on temporal consistency, detail preservation, and compute is unexplored.
- Spatial window selection algorithm: cyclic conditioning relies on manually specified “spatial windows” based on field-of-view overlap; a general, automatic method to construct spatial neighborhoods for arbitrary trajectories (figure-eights, branched paths, wide baselines) is absent.
- Geometry-aware conditioning: loop closing deteriorates for wide-baseline viewpoints; integrating depth/pose priors, 3D scene graphs, or geometry-aware constraints into stitching and guidance remains an open path.
- Runtime and memory footprint: the paper does not report compute/memory scaling, throughput, or latency relative to autoregression and prior stitching baselines, nor how these scale with sequence length, chunk size, and number of windows.
- Generalization beyond a single backbone: results use one Diffusion-Forcing (DF) Transformer trained on RealEstate10K; the robustness of GVS across architectures (e.g., different context lengths, attention types), training frameworks (non-DF models), and datasets (outdoor, dynamic scenes) is unknown.
- External conditioning propagation: GVS struggles to propagate external context frames through the entire video; methods to reliably inject and maintain image/text conditioning across stitched segments (e.g., cross-attention routing, conditioning caches) are not developed.
- Dynamic scene handling: evaluations focus on static indoor scenes; how GVS handles moving objects, time-varying lighting, or non-rigid motion while maintaining consistency and avoiding collisions is untested.
- Collision avoidance metrics: “collision-free” is inferred via depth estimation thresholds; the reliability of this proxy (and its sensitivity to depth model errors) and the relationship to physically plausible camera-scene interactions are not validated.
- Consistency–detail trade-off: stochasticity improves consistency but oversmooths; beyond tuning , strategies to preserve high-frequency detail (e.g., step-wise stochasticity schedules, detail-preserving guidance terms, multi-band denoising) are not explored.
- Diversity and distributional fidelity: the impact of Omni Guidance and cyclic conditioning on sample diversity, mode coverage, and distributional correctness (e.g., FID, precision/recall, LPIPS) is not assessed.
- Hybrid AR–stitching designs: combining retrieval-augmented autoregression with GVS (e.g., alternating AR and stitched phases, shared memory across methods) could mitigate failure modes of each; this integration is not investigated.
- Noise schedule sensitivity: how different diffusion schedules (e.g., EDM, DDPM/DDIM variants) affect stitching stability, loop closure, and oversmoothing is not characterized.
- Seeding and synchronization: best practices for initializing noise across chunks/windows (e.g., correlated vs. independent seeds) to reduce inconsistencies or seam artifacts are not studied.
- Robustness to camera path errors: the method assumes accurate predefined camera trajectories; handling pose uncertainty, calibration noise, or trajectory deviations (including planning under uncertainty) is an open question.
- Automatic loop detection and closure: there is no algorithm to detect when the trajectory should “visually return” and to trigger cyclic conditioning; designing topology-aware loop detectors and closure policies is left open.
- Longer-horizon limits: while 120-frame sequences are shown, the failure modes, degradation characteristics, and practical limits when scaling to minutes-long videos (and strategies to extend beyond) are not quantified.
- Integration with 3D neural representations: leveraging NeRF/SDF/GS-based world models or differentiable rendering to enforce multi-view consistency and geometry-aware stitching is unaddressed.
- Model training synergies: although GVS is training-free, whether modest, targeted training (e.g., DF variants with stitching-aware curriculum or auxiliary losses) could significantly improve consistency and loop closure remains unexplored.
- Evaluation breadth: metrics and datasets primarily target indoor navigation; broader benchmark suites covering outdoor scenes, complex trajectories, and dynamic content, with standardized loop-closure and collision protocols, are needed.
- Failure characterization: specific observed failures (e.g., confusing staircase start/end, wide-baseline loop closure) are noted but not systematically analyzed; diagnostic tools (e.g., per-chunk consistency heatmaps, mutual information across windows) could guide method improvements.
Practical Applications
Summary
The paper introduces Generative View Stitching (GVS), a training-free sampling method for camera-guided video generation that stitches long sequences in parallel using off-the-shelf Diffusion Forcing (DF) video backbones. Its core innovations are:
- Training-free stitching that composes a long video from overlapping chunks denoised jointly with past and future neighbors.
- Omni Guidance, which strengthens conditioning on both past and future to improve temporal consistency without oversmoothing.
- Cyclic conditioning for loop closing, enabling long-range coherence and visually closed loops for predefined camera paths.
Below are practical, real-world applications of these findings, categorized by deployment readiness and mapped to sectors, along with feasible tools/workflows and key assumptions or dependencies.
Immediate Applications
These can be deployed now with existing DF video models and moderate engineering.
- Film/TV, Virtual Production, Advertising
- Use case: Camera-path-aware previsualization and one-shot cinematography planning that respects future camera moves; seamless looping plates for LED volumes; consistent long flythroughs and product loops for ads.
- Tools/Workflows:
- “GVS Sampler” plugin for DCC tools (Blender, Unreal, After Effects): author a camera path via keyframes, run GVS with Omni Guidance, preview loop closure, export plates.
- Preset cyclic-conditioning templates for panoramas/circles; parameter presets for stochasticity η and guidance γ.
- Dependencies/Assumptions: Requires DF-trained video model with classifier-free guidance and per-token noise masking; GPU resources; content domain close to model training (e.g., indoor/outdoor scenes). External image conditioning is currently weak.
- VR/AR and Creative Platforms
- Use case: Seamless 360° panoramas and long-loop background videos for VR scenes and social media; infinite scrolling or orbiting camera loops for immersive ambiences.
- Tools/Workflows: Web UI to import a path (e.g., panoramic yaw sweep), enable cyclic conditioning, auto-check loop closure with MEt3R-based long-range consistency metrics.
- Dependencies/Assumptions: Headset-friendly framerate and resolution may require upscaling; tune η, γ to avoid oversmoothing; wide-baseline loop closures are less reliable today.
- Gaming and Interactive Media
- Use case: Procedural flythroughs for level previews; consistent, collision-free in-engine cutscenes with predefined rails; skybox and world-loop assets that visually return to the same place.
- Tools/Workflows: GVS as a build step in content pipelines; automatic collision QA via learned depth estimation to reject paths that produce camera-scene collisions.
- Dependencies/Assumptions: Domain gap vs. game art style; may use style-consistent post-processing or video stylization; compute budget during asset build, not runtime.
- Robotics and Autonomy (Synthetic Perception Data)
- Use case: Camera-guided synthetic navigation videos consistent with future motion, avoiding “walk-through walls” artifacts; stress tests for perception models over long horizons.
- Tools/Workflows: Given a planned drone/robot trajectory, generate videos with GVS; evaluate with depth-based collision checks; compute frame-to-frame and long-range consistency (MEt3R) as QA gates.
- Dependencies/Assumptions: Visual realism limited by backbone; not a physics-grounded simulator; best for perception pretraining, not for dynamics/policy learning.
- Real Estate, Museums, Tourism
- Use case: Long, consistent walkthroughs and circular tours with seamless returns to starting views; “impossible” but visually convincing loops for engagement.
- Tools/Workflows: Path authoring from floorplans or waypoints; GVS generation with loop closure; automated rejection of loops with poor long-range consistency.
- Dependencies/Assumptions: Indoor scene familiarity in the backbone (e.g., trained on RealEstate10K-like data); accurate camera FOV and path export.
- Education and Science Communication
- Use case: Visual demonstrations of perceptual illusions (e.g., “Impossible Staircase”), camera path effects, and spatial consistency; looped learning snippets.
- Tools/Workflows: Template camera paths for illusions; parameter sweeps for η/γ to teach effects of stochasticity and guidance.
- Dependencies/Assumptions: Requires careful curation to avoid oversmoothing; pedagogical validation.
- Research Infrastructure
- Use case: Baseline for long-horizon video generation; benchmarking loop closure and collision avoidance; method ablation platform (η, γ, cyclic windows).
- Tools/Workflows: Open-source GVS sampler with evaluation suite (MEt3R F2FC/LRC, VBench IQ/AQ, collision checks).
- Dependencies/Assumptions: DF backbones with proper masking and classifier-free guidance; access to consistent metric depth for collision proxy.
- Creator Tools (Daily Life)
- Use case: Seamless loops for social posts; orbiting product or pet videos that return to the same frame without cuts.
- Tools/Workflows: Mobile/desktop app feature “Make Seamless Loop from Path” with simple sliders for consistency vs. detail.
- Dependencies/Assumptions: Cloud or on-device acceleration; content safety and usage rights.
Long-Term Applications
These require further research, scaling, or integration with additional systems.
- Autonomous Driving and Robotics Simulation (Policy, Industry)
- Use case: Large-scale, controllable, multi-camera, long-horizon scenario generation that respects future plans and supports closed-loop testing against safety policies.
- Tools/Workflows: Integrate GVS with world models and sensor suites (LiDAR, multi-view) to produce coherent scenarios; use policy-driven test catalogs.
- Dependencies/Assumptions: Extension beyond monocular video to multi-sensor realism; stronger grounding in 3D geometry; regulatory acceptance of synthetic test evidence.
- Hierarchical and Goal-Conditioned Robot Planning
- Use case: Combine GVS-like stitching with planning to visualize long-term goals and subgoals; “mental videos” that remain consistent over long paths and close loops in exploration.
- Tools/Workflows: Planner proposes waypoints; GVS generates coherent visuals conditioned on both past and future waypoints (Omni Guidance); planner refines based on perceived feasibility.
- Dependencies/Assumptions: Coupling with control and geometry-aware modules; data for out-of-distribution environments; real-time constraints.
- Real-Time Virtual Production for LED Volumes
- Use case: On-set, path-aware background plates that adapt to live camera tracking while preserving global consistency and loops for repeated takes.
- Tools/Workflows: Low-latency GVS variants with model distillation; scene state caching; dynamic cyclic conditioning driven by live camera telemetry.
- Dependencies/Assumptions: Significant acceleration (model compression/streaming inference); stringent artistic quality; robust loop closure under wide baselines.
- Digital Twins and Urban Planning
- Use case: City-scale long flythroughs with consistent loops across neighborhoods; public consultation media that depict proposed routes repeatedly without stitching artifacts.
- Tools/Workflows: GIS-to-path pipelines; hybrid integration with 3D GIS models; long-range cyclic conditioning over large maps.
- Dependencies/Assumptions: Scaling to kilometers of path; diverse outdoor/backbone training; policy transparency about synthetic content.
- Healthcare and Training VR
- Use case: Therapeutic or training VR environments with long, stable loops that avoid scene “drift,” reducing cybersickness; repeated, predictable navigation for exposure therapy.
- Tools/Workflows: Clinical content pipelines with loop-closure QA; fine control of η/γ to balance detail vs. stability.
- Dependencies/Assumptions: Clinical validation; safety assessments; alignment of generated content with therapeutic protocols.
- Consumer AR Navigation and Memory Reconstruction
- Use case: AR overlays that maintain global visual consistency along long paths (e.g., campus tours); reconstruct long, seamless loops from personal camera path prompts.
- Tools/Workflows: Path capture from IMU/SLAM; post-hoc GVS generation; loop closure aided by map priors.
- Dependencies/Assumptions: Robustness to wide-baseline changes; privacy-preserving generation policies; device constraints.
- Content Governance and Standards (Policy)
- Use case: Evaluation standards for long-horizon consistency, loop closure, and collision avoidance in generative video; disclosure and watermarking for synthetic walkthroughs.
- Tools/Workflows: Benchmark suites using MEt3R F2FC/LRC and collision proxies; best-practice guidance for “path-faithful” synthetic media in public communication.
- Dependencies/Assumptions: Community consensus on metrics; legal frameworks for synthetic environment disclosures.
- Multi-Modal Conditioning and Image/Scene Grounding
- Use case: Text- and image-grounded GVS that propagates conditioning frames throughout long sequences (e.g., story-driven loops).
- Tools/Workflows: New backbones or adapters that improve propagation of external conditions; “anchor frame” mechanisms to turn images into strong constraints during stitching.
- Dependencies/Assumptions: Advances in DF backbones; training or fine-tuning for robust conditioning propagation (not purely training-free).
- Enterprise APIs and SDKs
- Use case: Managed services that expose “Camera-Path-Aware Generation” with loop closure and QA; integrations in MAM/DAM systems.
- Tools/Workflows: REST/gRPC APIs; job queues with chunk-level caching; automated tuning of η, γ; report cards: F2FC, LRC, AQ/IQ, collision flags.
- Dependencies/Assumptions: Operational cost; content compliance; model licensing and IP.
Cross-Cutting Assumptions and Dependencies
- Backbone requirements: DF video models with per-token noise control and classifier-free guidance; quality and domain coverage of the backbone limit outputs.
- Parameter sensitivity: Stochasticity η and guidance γ trade off detail vs. consistency; cyclic conditioning design depends on camera path geometry.
- Loop closure limits: Wide-baseline viewpoints and strong parallax are challenging; explicit loop-closing windows are needed for long-range coherence.
- Compute and latency: Parallel sampling is compute-intensive; real-time use cases need acceleration (distillation, caching, mixed precision).
- Evaluation and safety: Collision checks rely on depth estimators; MEt3R-based consistency metrics should be part of QA; content safety, disclosures, and usage rights must be respected.
- Conditioning constraints: Current method struggles to propagate external images across long sequences; future work needed for robust multi-modal conditioning.
Glossary
- Adaptive LayerNorm: A conditioning mechanism that adapts layer normalization parameters based on auxiliary inputs to inject conditioning information into a model. Example: "Adaptive LayerNorm"
- Aesthetic quality (AQ): A metric intended to evaluate the aesthetic appeal of generated video frames. Example: "aesthetic quality (AQ)"
- Autoregressive sampling: A generation procedure that produces future frames conditioned only on a limited past context, step by step, which can accumulate errors. Example: "Autoregressive sampling diverges due to collisions with the generated scene"
- Camera-guided video generation: Video synthesis conditioned on a specified camera path so that generated content aligns with the camera’s motion. Example: "camera-guided video generation with a predefined camera trajectory"
- Classifier-free guidance: A guidance technique for diffusion models that interpolates between conditional and unconditional scores to strengthen conditioning. Example: "classifier-free guidance"
- Collision avoidance (CA): An evaluation criterion measuring whether the camera collides with generated scene geometry during navigation. Example: "collision avoidance (CA)"
- CompDiffuser: A diffusion stitching method that composes sequences via specialized conditioning but requires custom model training. Example: "CompDiffuser"
- Compositional trajectory distribution: A factorized probabilistic model that composes a sequence from overlapping, locally conditioned chunks. Example: "compositional trajectory distribution:"
- Context window: The fixed-length span of frames a model can condition on at once during generation. Example: "context window"
- Cyclic conditioning: Alternating conditioning schemes (e.g., temporal vs. spatial neighbors) across denoising steps to propagate information globally and close loops. Example: "GVS closes loops via cyclic conditioning"
- Denoising step: One iteration of the diffusion sampling process that reduces noise according to the model’s predicted score. Example: "denoising step"
- Diffusion Forcing (DF): A training framework for sequence diffusion models with per-token noise levels enabling flexible masking and conditioning. Example: "Diffusion Forcing (DF)"
- Diffusion stitching: A family of sampling techniques that generate long sequences by synchronizing overlapping segments in parallel. Example: "diffusion stitching"
- Diffusion-Forcing Transformer (DFoT): A Transformer-based video backbone trained under Diffusion Forcing to handle sequence generation. Example: "a Diffusion-Forcing Transformer model"
- Field-of-view-based retrieval: A memory mechanism that retrieves past frames based on camera frustum overlap to maintain long-term consistency. Example: "field-of-view-based retrieval"
- Fractional History Guidance: A guidance method for DF models that conditions on a fraction of historical tokens to steer generation. Example: "Fractional History Guidance"
- Frame-to-frame consistency (F2FC): A metric measuring visual consistency between consecutive frames in a video. Example: "frame-to-frame consistency (F2FC)"
- Generative View Stitching (GVS): The proposed training-free stitching method that jointly denoises overlapping chunks to achieve consistent, camera-guided long videos. Example: "Generative View Stitching (GVS)"
- Goal-conditioned planning: A generation or control setup where outputs must satisfy start and goal constraints across a trajectory. Example: "goal-conditioned planning"
- History-Guided Autoregressive (AR) Sampling: An AR baseline that augments generation with history guidance for longer, more stable rollouts. Example: "History-Guided Autoregressive (AR) Sampling"
- Imaging quality (IQ): A metric assessing perceptual fidelity and clarity of generated frames. Example: "imaging quality (IQ)"
- Inception Score (IS): A commonly used generative quality metric based on classifier confidence and diversity. Example: "inception score (IS)"
- Inner Guidance: A guidance strategy that modifies the sampling distribution using model-internal signals rather than external classifiers. Example: "Inner Guidance"
- Long-range consistency (LRC): A metric measuring visual consistency between temporally distant but spatially corresponding frames. Example: "long-range consistency (LRC)"
- Loop-closing mechanism: An explicit procedure to ensure the video visually returns to the same location after traversing a looped path. Example: "loop-closing mechanism"
- Maximum stochasticity: A sampling setting that maximizes injected noise each step to encourage synchronization (but may oversmooth). Example: "maximum stochasticity"
- MEt3R cosine: A metric used to score consistency (e.g., F2FC, LRC) by comparing frame pairs using a learned representation. Example: "MEt3R cosine"
- Null condition: The empty conditioning used in classifier-free guidance to form an unconditional prediction. Example: "null condition"
- Omni Guidance: The proposed guidance technique that strengthens conditioning on both past and future chunks to improve temporal coherence. Example: "Omni Guidance"
- Out-of-distribution: Generated frames that deviate from the model’s training distribution, often causing failures. Example: "out-of-distribution"
- Predefined camera trajectory: A fixed path of camera poses provided as conditioning for video generation. Example: "predefined camera trajectory"
- RAG: Retrieval-augmented generation, where external memory is used to guide current outputs; here used as an AR augmentation. Example: "even when augmented with RAG"
- Receptive field: The span of frames whose information can influence a target frame during stitching; grows across denoising steps. Example: "theoretical receptive field"
- Retrieval-based techniques: Methods that fetch relevant past information to extend context and maintain consistency. Example: "retrieval-based techniques"
- Score function: The model’s prediction of noise (or gradient of log-density) used to denoise samples in diffusion. Example: "score function"
- StochSync: A prior stitching baseline emphasizing stochastic synchronization, originally for panoramas and textures. Example: "StochSync"
- Temporal consistency: Coherence of appearance and geometry across adjacent frames in a generated video. Example: "temporal consistency"
- VBench: A benchmark suite providing video quality metrics such as IQ and AQ. Example: "VBench"
Collections
Sign up for free to add this paper to one or more collections.