- The paper introduces TIRE, a three-stage pipeline that enhances subject fidelity in 3D/4D assets by tracking, inpainting, and resplatting textures.
- It leverages progressive inpainting with a LoRA-finetuned Stable Diffusion model to mitigate identity drift across novel viewpoints.
- Experimental results demonstrate superior geometric consistency and identity preservation compared to existing state-of-the-art methods.
Subject-driven 3D and 4D Generation via Progressive Texture Infilling: The TIRE Framework
Introduction and Motivation
The paper introduces TIRE (Track, Inpaint, Resplat), a three-stage pipeline for subject-driven 3D and 4D asset generation that addresses the persistent challenge of identity preservation across novel viewpoints. Existing 3D/4D generative models, while efficient and photorealistic, often fail to maintain semantic consistency of the subject when rendered from unobserved angles, primarily due to limited cues and dataset biases. TIRE is designed to operate as a post-processing enhancement atop any baseline 3D/4D generative model, leveraging 2D video tracking and inpainting to progressively infill occluded regions and resplat the results back to 3D, thereby improving both appearance and geometric consistency.

Figure 1: Pipeline of TIRE. TIRE starts from a rough 3D asset created by existing models and its rendered multi-view observations. Afterwards, the three stages Track, Inpaint, Resplat target at identifying the inpainting masks, infilling the occluded regions, and unprojecting back to 3D, respectively.
Methodology
Stage 1: Track
The initial step involves rendering multi-view observations from a rough 3D asset generated by a baseline model. These frames are organized as a video sequence, and CoTracker is employed to establish pixel correspondences between the source and target views. The paper demonstrates that backward tracking (from target to source) yields more accurate and contiguous inpainting masks than forward tracking, as it maximizes the use of identity-rich source view information and avoids fragmented mask artifacts.
Stage 2: Inpaint
With infilling masks identified, the next challenge is to inpaint occluded regions such that the subject's identity is preserved, even for views far from the source. The authors personalize a Stable Diffusion inpainting model using LoRA, finetuned on the source image and its augmentations. Inpainting is performed progressively: first on views close to the source (e.g., ±20∘ azimuth), which serve as anchor points for subsequent, more distant views. This staged approach mitigates the risk of identity drift and enables the model to generalize appearance features to less observed regions.
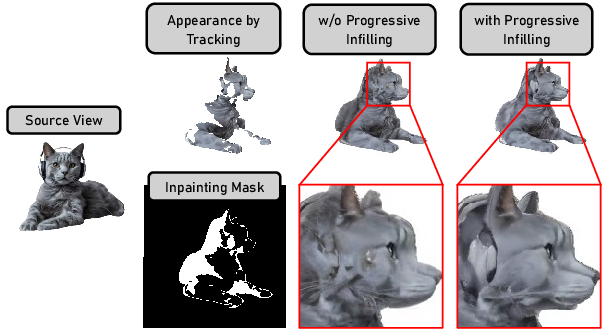
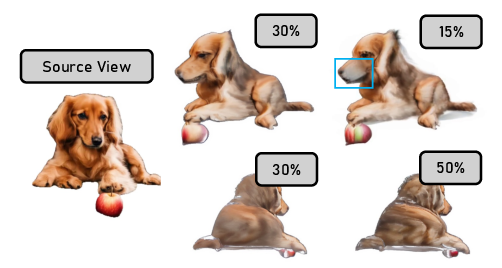
Figure 2: Ablation study on the progressive learning strategy in TIRE. Without adopting progressive learning, the model tends to consistently infill the appearance of the given source view regardless of the current pose, which results in wrongly infilling the textures on the side and back views.
Stage 3: Resplat
After inpainting, multi-view consistency is refined using a mask-aware multi-view diffusion model, which selectively denoises only the unseen viewpoints. The refined multi-view images are then unprojected back to 3D using a multi-view-to-Gaussian process, compatible with various 3D representations. This step ensures that the final 3D/4D asset maintains cross-view consistency and subject fidelity.
Experimental Results
Qualitative Comparisons
TIRE is evaluated on the DreamBooth-Dynamic dataset and in-the-wild samples, with comparisons against state-of-the-art models such as SV3D, Wonder3D, LGM, MeshFormer, TRELLIS, Hunyuan3D-v2.5, STAG4D, SV4D, L4GM, and Customize-It-3D. Across both image-to-3D and video-to-4D tasks, TIRE consistently produces assets with superior identity preservation and improved geometry, as evidenced by reduced ghosting and more realistic textures.

Figure 3: Qualitative comparison on image-to-3D generation with SV3D. TIRE better preserves the identity of the reference image and achieves superior geometry.
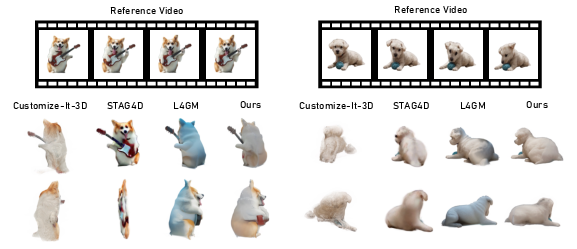
Figure 4: Comparison between TIRE and baselines Customize-It-3D, STAG4D, and L4GM. TIRE yields more faithful subject appearance and geometry.
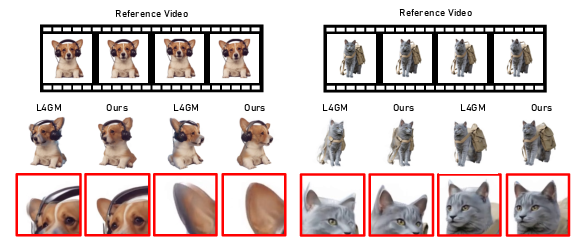
Figure 5: Comparison between TIRE and L4GM. TIRE improves both identity preservation and geometric consistency.
Quantitative Evaluation
DINO feature similarity metrics and VLM-based scoring (using GPT-4o, Gemma 3, Gemini 2.0, Qwen2.5-VL, Mistral-Small) are used to assess subject fidelity. While DINO scores sometimes favor models with incorrect geometry due to appearance similarity, VLM-based scores provide a more holistic evaluation, considering shape, color, texture, and facial features. TIRE achieves the highest average VLM-based score among all tested methods, though all models remain far from perfect subject consistency.
User Study
A user study with 18 participants, scoring overall quality (subject fidelity, cross-view consistency, realism) on a 1-10 scale, confirms that TIRE is subjectively preferred over baselines, even when participants are not explicitly informed about the focus on subject-driven generation.

Figure 6: Screenshot of the instructions of our user study. Participants rate overall quality without explicit mention of subject-driven focus.

Figure 7: Screenshot of an example question, showing side-by-side videos from three methods and the reference image.
Ablation Studies
The paper provides detailed ablations on progressive inpainting, denoising schedule, and degree of progressiveness. Progressive inpainting is shown to be critical for avoiding identity collapse in distant views. The denoising schedule is empirically set to 30% to balance texture refinement and structural preservation; smaller schedules leave artifacts, while larger ones distort appearance.
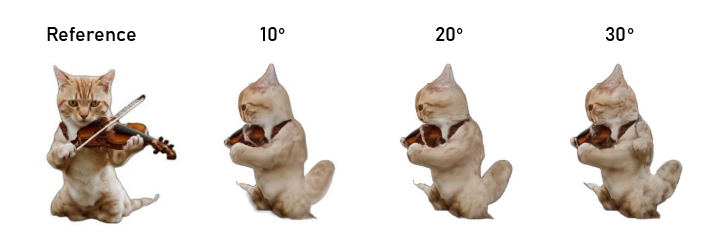
Figure 8: Ablation study on the degree of progressiveness during the Inpaint stage. 20∘ is optimal for balancing quality and efficiency.

Figure 9: Ablation study on the necessity of having the inpainting process. Without inpainting, color and texture quality degrade significantly.
Generalizability and Limitations
TIRE is model-agnostic and can be applied to any 3D/4D generative pipeline, including recent feed-forward models and commercial systems. The method is computationally intensive (∼100 minutes per asset on A100), but future advances in feed-forward subject-driven inpainting are expected to mitigate this. The authors note that current quantitative metrics (e.g., DINO similarity) are insufficient for nuanced evaluation of subject-driven 3D/4D generation, and propose integrating geometric and appearance assessments in future work.
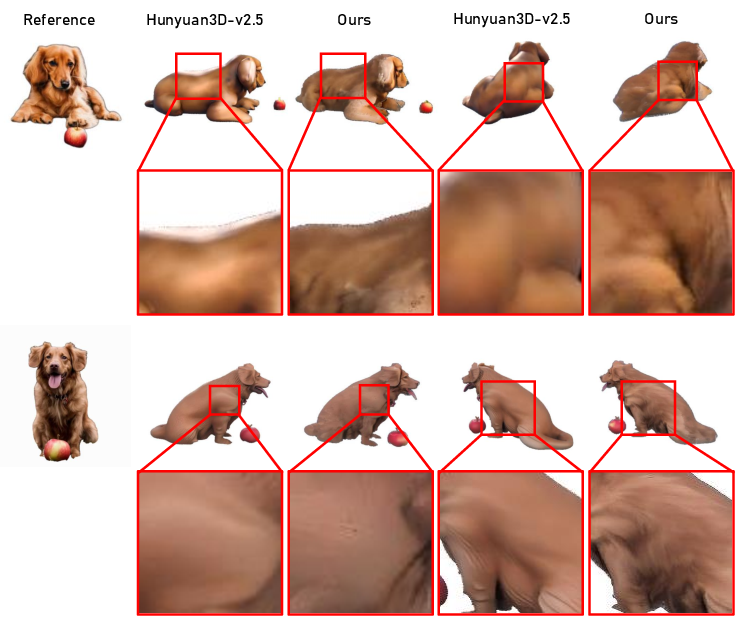
Figure 10: Qualitative results showing the improvement of TIRE when applied to Hunyuan3D-v2.5, demonstrating enhanced texture and identity preservation.

Figure 11: Qualitative comparison with more advanced methods including Hunyuan3D-v1.0, SPAR3D, Sudo AI, and Neural4D. Recent models still struggle with personalized 3D generation.
Societal Impact and Future Directions
TIRE enables more personalized and creative 3D/4D content creation, with potential applications in entertainment, AR/VR, and digital asset customization. However, risks include digital forgery and copyright concerns. The method's reliance on 2D foundation models and progressive infilling offers a complementary direction to efficiency-focused feed-forward pipelines. Future work should address efficient subject-driven inpainting, improved quantitative metrics, and temporal reasoning for dynamic subjects.
Conclusion
TIRE presents a robust, generalizable framework for subject-driven 3D and 4D generation, leveraging progressive texture infilling via 2D tracking and inpainting. Extensive qualitative, quantitative, and user study results demonstrate its superiority in identity preservation and geometric consistency over current state-of-the-art methods. The approach is complementary to existing feed-forward pipelines and highlights the need for further research in personalized 3D/4D asset generation and evaluation.