- The paper introduces Lookahead Anchoring, a method that repositions keyframes as soft, future anchors to preserve character identity in extended audio-driven animations.
- The approach leverages temporal decoupling and fine-tuning of distant keyframes to improve lip synchronization and maintain visual consistency across diverse DiT models.
- Experimental results show that the method outperforms traditional keyframe anchoring by achieving stable facial consistency and natural motion over long sequences.
Lookahead Anchoring for Robust Character Identity in Audio-Driven Human Animation
Introduction and Motivation
Audio-driven human animation with video diffusion transformers (DiTs) has achieved high-fidelity lip synchronization and expressive motion, but suffers from identity drift in long-form autoregressive generation. Existing solutions, such as keyframe-based anchoring, mitigate drift by enforcing intermediate identity constraints, but at the cost of natural motion dynamics and increased inference complexity. The "Lookahead Anchoring" framework redefines the role of keyframes: rather than serving as rigid segment endpoints, keyframes are positioned at future timesteps beyond the current generation window, acting as soft, directional beacons for identity preservation. This decouples identity guidance from immediate audio-driven motion, enabling both self-keyframing (using the reference image as a perpetual anchor) and flexible integration with external image editing models.
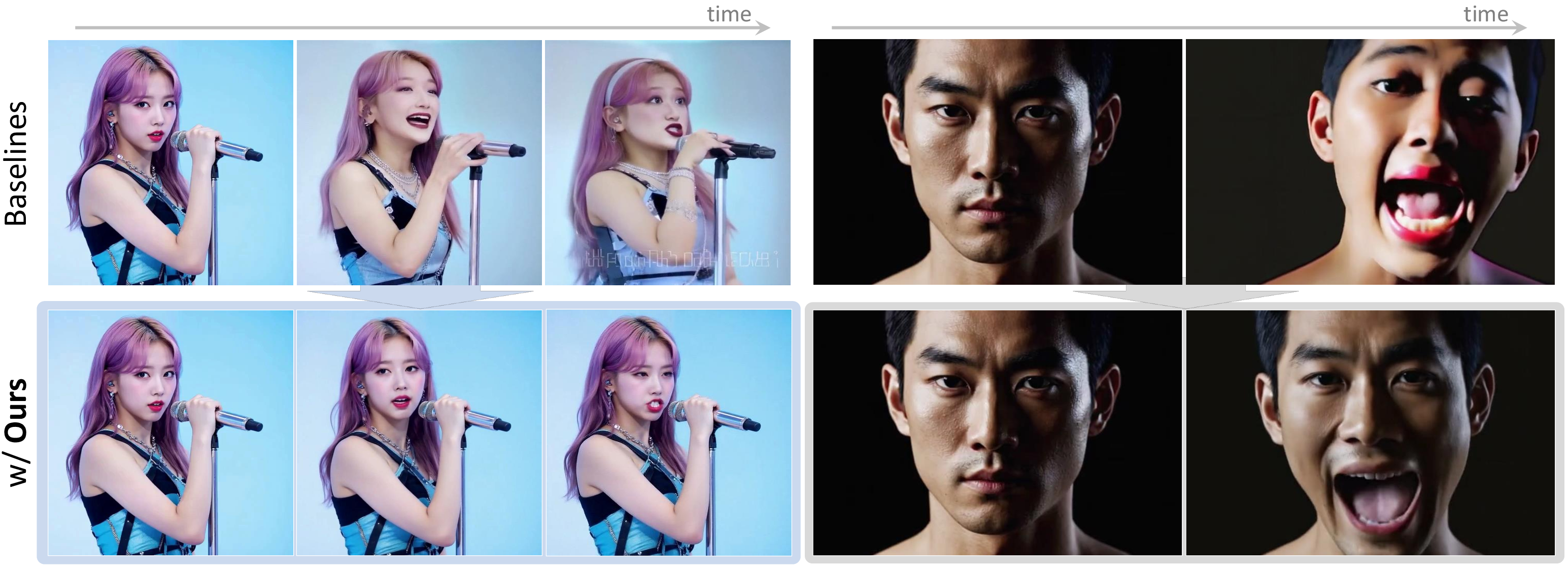
Figure 1: Lookahead Anchoring enables robust long-form audio-driven animation, maintaining character identity and lip sync quality over extended sequences compared to conventional autoregressive DiT baselines.
Methodology
Temporal Decoupling and Keyframe Repositioning
Traditional segment-wise autoregressive generation divides videos into short segments, each conditioned on previous frames and a reference image. However, error accumulation leads to progressive identity drift. Keyframe-based methods (e.g., KeyFace) introduce audio-synchronized keyframes as segment boundaries, but require a two-stage inference and constrain motion to predetermined poses.
Lookahead Anchoring repositions keyframes as temporally distant anchors, always ahead of the current segment. Formally, for segment Vi spanning frames [iL,(i+1)L), the model conditions on a keyframe at (i+1)L−1+D, where D is the lookahead distance:
Vi=GLA(aiL:(i+1)L,Vi−1end,k(i+1)L−1+D)
This transforms the keyframe from a hard constraint to a soft, persistent guidance signal, allowing the model to "chase" the anchor without ever reaching it.
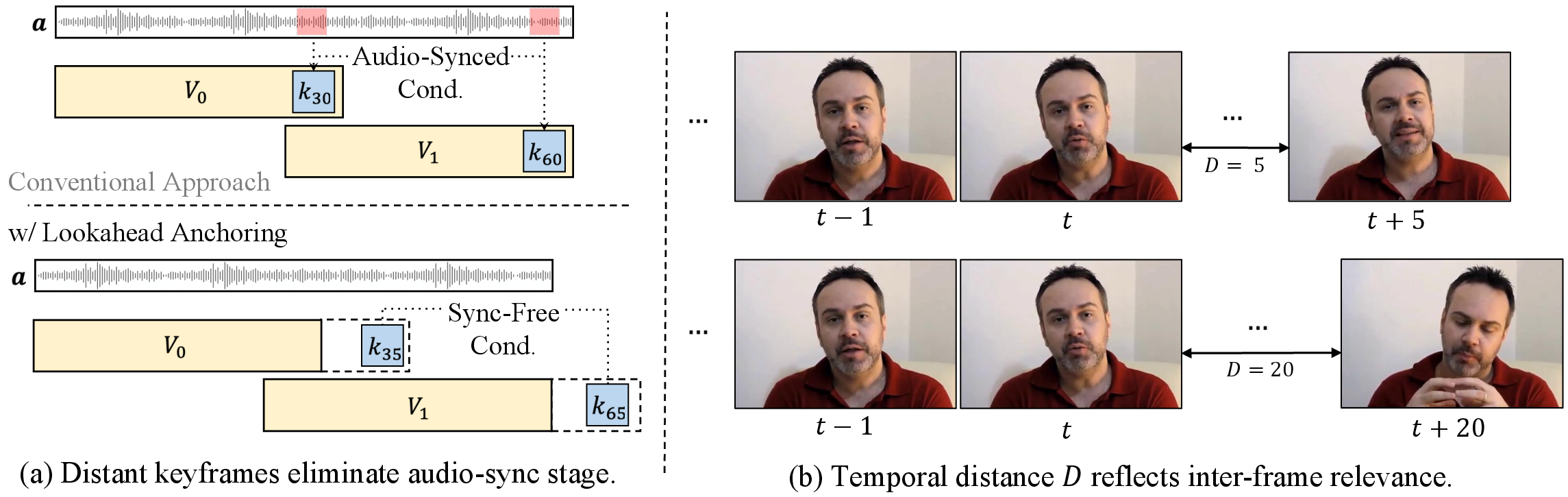
Figure 2: Keyframes are repositioned as distant anchors, decoupling them from the generated sequence and enabling flexible conditioning and diverse scene variation.
Integration with Video DiTs
Lookahead Anchoring is implemented by manipulating temporal positional embeddings in DiT architectures. During training, clean latent representations of distant keyframes are appended to the noisy video latent sequence, with their temporal embeddings set to future positions. A projection layer maps clean conditioning latents into the noisy token space. At inference, any image (reference, edited, or prompt-generated) can serve as the anchor, with its latent assigned a distant temporal embedding.
Empirical analysis shows that pretrained DiTs exhibit adaptive motion behavior when conditioned on distant frames, but require fine-tuning to maintain visual quality and identity consistency.

Figure 3: Pretrained video DiTs adaptively increase motion magnitude with larger temporal gaps, validating the model's intrinsic understanding of temporal dynamics.
Training Strategy
Fine-tuning samples keyframe positions from both inside and outside the generation window, allowing the model to learn a smooth attenuation of keyframe influence with temporal distance. Flexible anchoring outperforms fixed anchoring, achieving superior lip synchronization and facial consistency.
Experimental Results
Quantitative and Qualitative Evaluation
Lookahead Anchoring was integrated into three state-of-the-art DiT models: Hallo3, HunyuanVideo-Avatar, and OmniAvatar. Evaluations on HDTF and AVSpeech datasets demonstrate consistent improvements in lip synchronization (SyncNet distance/confidence), face and subject consistency (ArcFace/DINO cosine similarity), FID, FVD, and motion smoothness. Notably, identity preservation and video quality remain stable over long sequences, while baselines degrade progressively.

Figure 4: Qualitative results comparing Lookahead Anchoring with DiT baselines on AVSpeech and HDTF, showing superior identity preservation and visual quality.
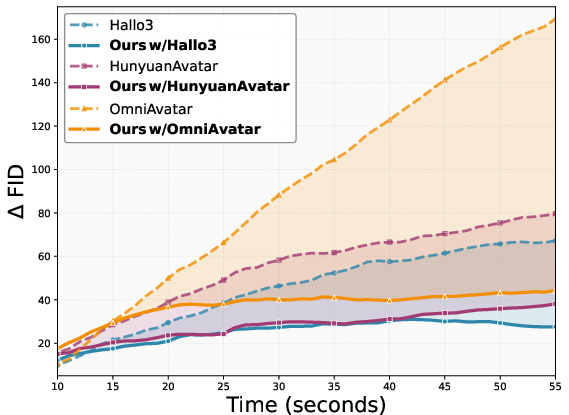
Figure 5: FID over time, normalized to the first window, demonstrates that Lookahead Anchoring maintains consistent quality while baselines degrade.
User studies confirm strong perceptual preference for Lookahead Anchoring across all criteria.
Comparative Analysis
Compared to Sonic (sliding window), KeyFace (keyframe interpolation), and past-time conditioning, Lookahead Anchoring achieves the best trade-off between lip synchronization, facial consistency, and motion smoothness, without additional architectural complexity.
Temporal Distance Trade-Off
Increasing the lookahead distance enhances motion expressiveness but reduces facial consistency. Lip synchronization peaks at moderate distances (e.g., 12 frames), indicating an optimal zone for balancing expressiveness and identity.
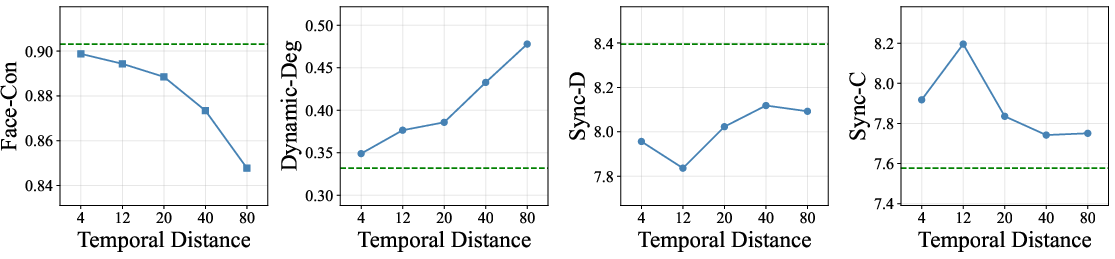
Figure 6: Increasing temporal distance yields higher dynamicity but reduced facial consistency; lip synchronization is optimal at moderate distances.
Ablation Studies
Flexible anchoring and distant future temporal embeddings for keyframes yield the best performance. Zero or learnable embeddings degrade identity preservation.
Narrative-Driven Generation and Applications
Lookahead Anchoring enables narrative-driven video generation by conditioning on edited keyframes representing different emotional states or contexts. External text-to-image editing models (e.g., Nano Banana) can generate anchors, allowing smooth narrative transitions while maintaining audio synchronization and character identity.

Figure 7: Narrative-driven generation using edited keyframes as lookahead anchors, guiding transitions while preserving identity and synchronization.
Figure 8: Additional qualitative results across diverse characters and scenarios, demonstrating consistent identity and natural motion.

Figure 9: Extended qualitative comparisons on AVSpeech, showing Lookahead Anchoring maintains facial detail and identity over long sequences.

Figure 10: Further qualitative comparisons on AVSpeech, highlighting the robustness of identity preservation.

Figure 11: Narrative-driven long video generation application, integrating external editing models for dynamic storylines.
Implementation Considerations
- Computational Requirements: Lookahead Anchoring introduces minimal overhead, requiring only additional latent concatenation and a projection layer for conditioning.
- Fine-Tuning: Training with a range of temporal distances is essential for generalization.
- Deployment: The method is compatible with existing DiT architectures and can be applied to any autoregressive video generation pipeline.
- Limitations: The approach inherits limitations of the base DiT model (e.g., hand gesture fidelity, extreme scene transitions). Future work may explore dynamic scene changes and more granular control over anchor influence.
Implications and Future Directions
Lookahead Anchoring offers a principled solution to long-term identity drift in audio-driven human animation, enabling arbitrarily long, high-quality video generation with intuitive control over the identity-expressiveness trade-off. The decoupling of identity and motion guidance facilitates integration with external editing models and supports narrative-driven applications. Theoretical implications include a redefinition of temporal conditioning in generative models, suggesting that soft, persistent guidance can outperform rigid constraints in maintaining global consistency.
Potential future developments include:
- Adaptive scheduling of anchor distances for dynamic expressiveness control
- Extension to multi-character and multi-modal scenarios
- Integration with scene-aware and gesture-aware conditioning for richer animation
Conclusion
Lookahead Anchoring transforms keyframe conditioning from rigid segment boundaries to flexible, temporally distant guidance, achieving robust character identity preservation in long-form audio-driven human animation. The method generalizes across architectures, supports narrative-driven generation, and provides a practical framework for high-quality, expressive video synthesis at scale.

