ACG: Action Coherence Guidance for Flow-based VLA models
Abstract: Diffusion and flow matching models have emerged as powerful robot policies, enabling Vision-Language-Action (VLA) models to generalize across diverse scenes and instructions. Yet, when trained via imitation learning, their high generative capacity makes them sensitive to noise in human demonstrations: jerks, pauses, and jitter which reduce action coherence. Reduced action coherence causes instability and trajectory drift during deployment, failures that are catastrophic in fine-grained manipulation where precision is crucial. In this paper, we present Action Coherence Guidance (ACG) for VLA models, a training-free test-time guidance algorithm that improves action coherence and thereby yields performance gains. Evaluated on RoboCasa, DexMimicGen, and real-world SO-101 tasks, ACG consistently improves action coherence and boosts success rates across diverse manipulation tasks. Code and project page are available at https://github.com/DAVIAN-Robotics/ACG and https://DAVIAN-Robotics.github.io/ACG , respectively.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the paper
This paper is about teaching robots to move their arms and hands more smoothly and reliably when they follow instructions given through vision and language. The authors introduce a simple trick called Action Coherence Guidance (ACG) that makes a robot’s actions less shaky and more consistent without needing to retrain the robot’s brain. They show that this trick helps robots do precise tasks better, like pressing buttons or picking up small objects.
Key objectives and questions
The paper sets out to answer a few clear questions:
- How can we make robot actions smoother and steadier, especially when training data from humans includes mistakes like pauses, jitters, and jerks?
- Can we improve action smoothness at test time (when the robot is actually working) without changing or retraining the model?
- Will smoother actions help robots succeed more often on real tasks, in simulation and in the real world?
- Does this method work across different robot models that use similar technology?
How did they do it? Methods in everyday terms
First, some quick background:
- VLA models: These are Vision-Language-Action models. They take in what a robot sees (vision), what we tell it to do (language), and then decide what movements to make (action).
- Flow matching/diffusion models: Think of these as smart “generators” that start from random noise and, step by step, figure out a good set of actions. Imagine polishing a rough plan into a smooth one over several small updates.
The problem:
- When robots learn from human demonstrations, they sometimes copy human mistakes—like tiny hesitations or shaky motions—which makes their own movements jumpy or inconsistent. This loss of “action coherence” can cause failures, especially in precise tasks.
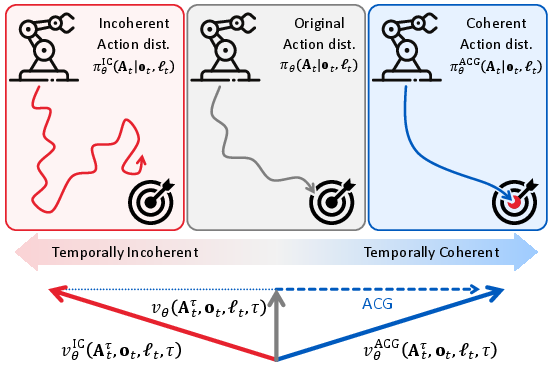
The ACG idea (an everyday analogy):
- Imagine you want to teach a robot to drive smoothly. You create a “bad driver” version of its brain that ignores what happened a moment ago and only thinks about right now. This “bad driver” makes jerky, incoherent moves.
- Then, when the real robot plans its moves, you steer it away from the “bad driver’s” directions and toward smoother, coherent actions.
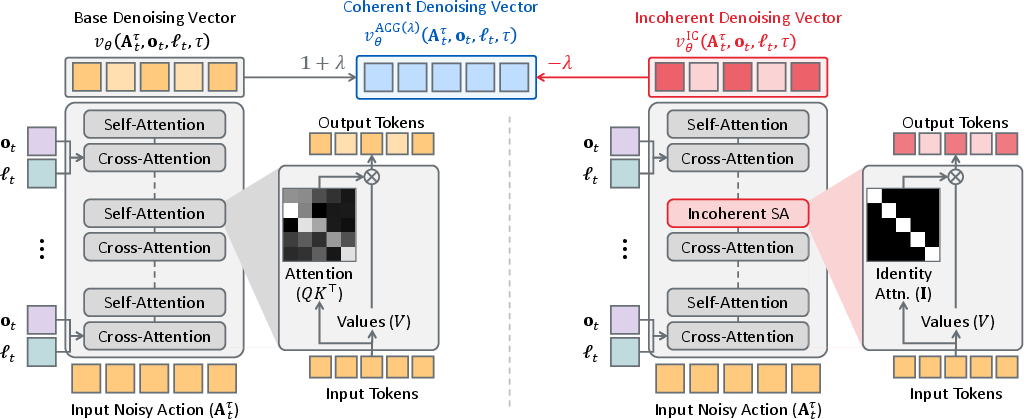
How they build the “bad driver”:
- Inside the robot’s model, there’s a part called self-attention that lets different time steps “talk” to each other, so actions coordinate over time.
- ACG temporarily breaks this “conversation” at test time by replacing the attention map with an identity map. In simple words: each moment only listens to itself and ignores the rest. That produces an intentionally incoherent action suggestion.
- During the normal action generation, the model uses many small steps guided by “vectors” (think of arrows that tell it how to adjust actions). ACG computes both the normal arrow and the “bad driver” arrow and then pushes the robot away from the bad one and more toward the good one.
- This needs no retraining. It’s just a smarter way to use the model at test time.
Main findings and why they matter
The authors tested ACG on:
- RoboCasa (a set of 24 simulated kitchen manipulation tasks),
- DexMimicGen (dexterous bimanual manipulation in simulation),
- Real-world pick-and-place tasks using an SO-101 robot (like grabbing strawberries and playing tic-tac-toe).
Key results:
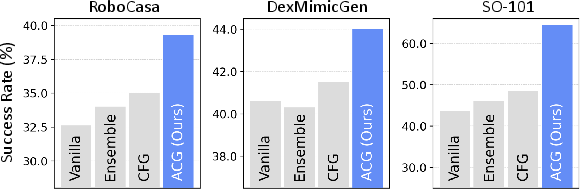
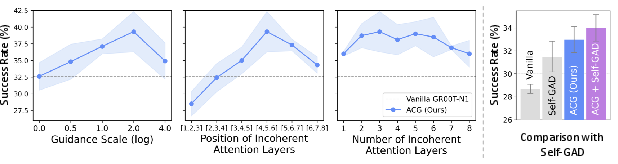
- ACG improves success rates across the board. Examples:
- RoboCasa: +6.7 percentage points over the strong baseline model.
- DexMimicGen: +3.4 percentage points.
- Real-world “Three Strawberries” task: +30.8 percentage points.
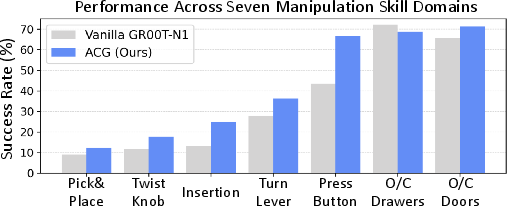
- It showed the biggest gains in fine-grained tasks (where precision matters), like:
- Button pressing: +23.1 percentage points.
- Insertion tasks: +11.8 percentage points.
- Smoother actions were measured with two metrics:
- Action Total Variation (ATV): how much actions change step-to-step. Lower is smoother.
- JerkRMS: how quickly acceleration changes. Lower means less jerk.
- ACG lowered these metrics, indicating smoother, more coherent movements.
- Compared to other baselines:
- Simple “smoothing” methods (like averaging multiple action plans or applying filters) helped a little but often blurred important details.
- Classifier-Free Guidance (a popular trick from image generation) didn’t help much with action coherence for robot tasks.
- ACG outperformed a “white noise” guidance method, which can disrupt timing but can also harm accuracy. ACG kept precision while improving smoothness.
Why it matters:
- Robots that move more coherently are safer, more reliable, and less likely to slowly drift off target.
- ACG helps especially when tasks require fine control—exactly where small wobbles lead to big failures.
Implications and potential impact
- Training-free improvement: ACG doesn’t need extra training. It’s a plug-and-play way to make existing VLA models more reliable.
- Works across models: The authors show it generalizes to other flow-based VLA models (like GR00T-N1, π0, and SmolVLA).
- Practical trade-off: ACG adds some computing cost at test time (roughly 1.5–2× more), but this can be reduced by reusing parts of the model’s work.
- Complementary approach: ACG focuses on making each chunk of actions coherent. It can be combined with methods that make coherence across chunks better for even more gains.
- Bigger picture: This work encourages using guidance (a trick popular in image/video generation) to improve robot action quality, potentially inspiring new test-time strategies to fix other weaknesses in robot policies.
In simple terms: ACG is like giving robots a “don’t be jittery” compass. It shows them what incoherent actions look like, then guides them away from those mistakes. The result is smoother, steadier motions and better performance on tasks that demand precision.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Theoretical guarantees: No analysis proves that ACG’s guided vector field corresponds to a valid probability flow, preserves policy consistency, or guarantees improved stability/convergence; a formal connection between coherence metrics (e.g., ATV/JerkRMS) and task success is absent.
- Incoherent field design space: Identity attention is one specific perturbation; the paper does not compare alternative constructions (e.g., per-head identity, scaled/soft identity, randomized attention routing, positional encoding perturbations, head dropout, causal masking tweaks) or justify why identity is optimal.
- Layer-level choices: The selection of middle/later self-attention layers (4–6 of 8) is empirically motivated but not systematically derived; it is unknown how layer position, depth, and architecture (e.g., deeper/wider models) affect ACG’s efficacy or whether perturbing a minimal subset suffices.
- Hyperparameter tuning: Guidance scale selection is heuristic and task-specific; there is no principled or automated method to set λ relative to model size, denoising steps, action chunk length, or dataset characteristics.
- Action chunk size dependency: ACG’s benefits may depend on the chunk length k; the paper does not examine sensitivity to k or trade-offs between intra-chunk coherence and reactiveness across different horizons.
- Integration scheme effects: Only forward Euler with 16 steps is used; the impact of solver choice (Heun, RK methods, adaptive steppers) and timestep schedules on ACG’s performance and stability is unexplored.
- Compute/latency constraints: While ~1.5× inference overhead is reported, there are no measurements of real-time latency, control loop frequency, jitter, or performance on limited hardware; practical deployability on embedded systems remains unclear.
- Reactiveness vs coherence: ACG may bias toward smoothing; the paper does not quantify whether coherence reduces responsiveness to sudden changes, contact events, or dynamic scene elements, potentially harming tasks that need rapid corrections.
- Coherence metrics coverage: ATV and JerkRMS are measured only on one real-world task (SO-101) during an approach phase; coherence is not quantified across RoboCasa/DexMG tasks, contact phases, or end-effector forces/torques.
- Accuracy–coherence trade-offs: The paper claims ACG maintains accuracy, but a systematic analysis of failure cases or conditions where coherence harms precision (e.g., tight tolerances, impulsive actions) is missing.
- Language adherence and conditioning: ACG’s effect on instruction fidelity and goal adherence is not measured; whether coherence guidance degrades language-conditioned objectives (compared to CFG) remains an open question.
- Data quality sensitivity: Claims on robustness to noisy demonstrations are not validated under controlled noise injection or varying dataset quality; the extent to which ACG compensates different noise modes (jerks, pauses, mislabels) is unknown.
- Domain shift robustness: Generalization is tested on limited tasks and embodiments; performance under strong visual/language domain shifts, cluttered/dynamic environments, occlusions, and new robots is not studied.
- Training-time alternatives: ACG is only contrasted with inference-time baselines; comparisons to training-time temporal regularizers (e.g., jerk penalties, smoothness priors, temporal consistency losses) or dataset denoising are missing.
- Multi-guidance interactions: Combining ACG with CFG/WNG/Self-GAD is only partially explored; scheduling, weighting, and conflict resolution among multiple guidance signals over timesteps/chunks are not characterized.
- Policy diversity and exploration: The impact of ACG on action diversity, mode coverage, and exploration (potentially reduced by coherence guidance) is not evaluated; diversity–performance trade-offs are unknown.
- Applicability beyond DiT-like transformers: ACG relies on self-attention over action tokens; how to construct incoherent guidance for non-attention policies (CNN/MLP/RNN), diffusion-based action heads, or discrete action spaces is left open.
- Contact-rich manipulation: Real-world evaluation focuses on pick-and-place; there is no assessment on high-precision contact-rich tasks (assembly, fastening, peg-in-hole, sliding with frictional constraints) to test whether coherence helps under tight tolerances.
- Long-horizon tasks: Effects on lengthy tasks with compounding errors and delayed rewards are not measured; whether increased intra-chunk coherence reduces long-horizon drift is not established.
- Safety and physical limits: The paper does not examine whether ACG reduces excessive accelerations/forces, improves safety margins, or adheres to hardware limits; force/torque profiles and contact safety are not analyzed.
- Scaling with model size: ACG’s behavior on substantially larger/smaller models and deeper attention stacks is uncertain; whether perturbing a tiny fraction of late layers suffices for very deep networks is explicitly noted as open.
- Robustness to instruction ambiguity: Since CFG can be unstable with subtle language changes, it is unclear if ACG is robust under ambiguous, multi-step, or compositional instructions where action semantics vary strongly.
- End-to-end pipeline interactions: Effects of perception errors (e.g., camera noise, misdetections), calibration drift, and state estimation uncertainties on ACG’s benefits are not evaluated; resilience in full robotic stacks remains untested.
- Receding-horizon policies: While Self-GAD requires receding horizon, the interplay between receding horizon execution and ACG (e.g., chunk execution vs prediction lengths) is not deeply analyzed; optimal horizon strategies with ACG are unknown.
- Generalization to multi-agent/bi-manual coordination: DexMG is used, but the paper does not isolate how ACG affects coordination across multiple arms/agents or whether coherence guidance helps/hurts inter-arm synchronization.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s Action Coherence Guidance (ACG) method to improve manipulation reliability without retraining VLA policies.
- Industrial robotics: fine-grained assembly and handling
- Sectors: manufacturing (electronics insertion, connector mating), warehousing/logistics (bin picking, packaging), retail (shelf stocking).
- Tools/products/workflows: a drop-in inference wrapper that adds ACG to GR00T-N1, π₀, or SmolVLA policies; a ROS/ROS2 node or Python SDK that exposes
lambda(guidance scale) and layer-perturbation options; pre-deployment A/B tests against vanilla policies. - Assumptions/dependencies: the policy must be a transformer-based, flow-matching action head with accessible self-attention internals; small compute overhead (+∼1.5×) is acceptable; task-specific tuning of guidance scale and attention layer positions may be needed.
- Agriculture and food handling: gentle grasping and precise placement
- Sectors: agriculture (fruit picking, tray loading), food processing (sorting delicate items).
- Tools/products/workflows: an ACG-enabled picking controller that reduces fumbles/jerks; ATV and JerkRMS dashboards for on-farm QA; simple calibration scripts to auto-tune
lambdaper crop or ripeness class. - Assumptions/dependencies: camera calibration and stable state estimation; flow-based VLA policy in use; tasks benefit from intra-chunk action smoothness more than additional text conditioning.
- Lab automation and micro-manipulation
- Sectors: biotech/pharma (pipetting, cap insertion), electronics labs (connector insertion, button pressing).
- Tools/products/workflows: ACG wrapper for manipulation micro-skills (press, twist, insert); gating metrics (ATV/JerkRMS) in lab QA; integration with existing DiT-based policies used for tabletop tasks.
- Assumptions/dependencies: test-time access to model attention maps; consistent visual inputs; small latency budget available for iterative flow guidance.
- Collaborative and service robots: smoother motions for safety and comfort
- Sectors: cobots on assembly lines, service robots in retail/hospitality, home robotics.
- Tools/products/workflows: ACG mode for “coherence-first” operation that reduces jerk/overshoot, with runtime switches; safety monitors that flag coherence violations.
- Assumptions/dependencies: safety controller accepts policy-side smoothness improvements; motion timing constraints allow guidance integration.
- Data collection and MLOps for imitation learning
- Sectors: robotics research and engineering teams collecting demonstrations.
- Tools/products/workflows: use ACG during robot-led data collection to reduce drift and collisions, yielding cleaner datasets; add ATV/JerkRMS as acceptance gates for demos; calibration playbooks for choosing attention layers (often middle/later layers).
- Assumptions/dependencies: demonstration noise is a known issue; lab can modify inference stacks; coherent actions reduce compounding error without distorting distribution.
- Academic research baselines and benchmarking
- Sectors: academia and R&D.
- Tools/products/workflows: adopt ACG as a standard inference-time baseline for flow VLA models; report success rates alongside coherence metrics (ATV/JerkRMS); open-source replication using the provided GitHub/HF assets.
- Assumptions/dependencies: availability of GR00T-N1/π₀/SmolVLA models; willingness to tune
lambdaand layer selection per benchmark.
- Teleoperation and shared autonomy assist
- Sectors: remote handling (warehouses, labs), assistive manipulation.
- Tools/products/workflows: apply ACG to the policy component that refines operator inputs into action chunks; reduce jitter/overshoot, lower operator fatigue.
- Assumptions/dependencies: teleop stack uses or can integrate a flow-based action head; permissible latency overhead.
Long-Term Applications
The following opportunities build on ACG’s core idea—steering away from intentionally incoherent vector fields—and will likely require further research, scaling, or engineering.
- Training-time coherence regularization and adversarial robustness
- Sectors: robotics ML across domains.
- Tools/products/workflows: ACG-inspired training objectives (coherence losses, adversarial perturbation via identity attention); “coherence adversarial training” to de-jitter policies; combined intra- and inter-chunk guidance (e.g., integrate ACG with Self-GAD).
- Assumptions/dependencies: access to training pipelines and large demo datasets; careful balance to avoid over-smoothing and loss of accuracy.
- Adaptive/auto-tuned guidance controllers
- Sectors: production robotics, MLOps.
- Tools/products/workflows: an online tuner that adjusts guidance scale
lambda, perturbed-layer count, and layer positions based on live ATV/JerkRMS signals; per-task or per-skill auto-calibration; coherence-aware schedulers that switch modes by phase (approach, grasp, place). - Assumptions/dependencies: reliable real-time metric estimation; safe exploration mechanisms; policy supports runtime perturbation without instability.
- Extension beyond manipulation: mobile robots, drones, surgical and rehab robotics
- Sectors: autonomous driving/navigation, UAV/UAM, healthcare robotics (surgical assistants, exoskeletons).
- Tools/products/workflows: coherence guidance for continuous control policies (smooth steering/throttle for vehicles, stable attitude control for drones); intra-chunk smoothness for surgical tool trajectories.
- Assumptions/dependencies: adoption of flow-based policies with transformer blocks in these domains; rigorous safety validation and regulatory clearance (especially for healthcare).
- Planning-policy integration
- Sectors: advanced robotics stacks.
- Tools/products/workflows: combine ACG with motion planners (trajectory optimization, MPC) to enforce path smoothness while preserving learned dexterity; coherence-aware waypoint generation; policy-planner hybrid controllers.
- Assumptions/dependencies: interfaces between planners and learned policies; synchronization of temporal horizons and latencies.
- Hardware and systems acceleration
- Sectors: edge AI, robotics compute.
- Tools/products/workflows: coherence-aware transformer kernels that natively support identity-attention toggling and feature caching to cut the ∼1.5× overhead; accelerator firmware supporting partial forward-pass reuse.
- Assumptions/dependencies: collaboration with hardware vendors; stable model architectures that benefit from layer reuse.
- Black-box model guidance and vendor ecosystem integration
- Sectors: enterprise robotics platforms.
- Tools/products/workflows: approximated coherence guidance for closed-source models (e.g., proxy perturbations via plugin layers or dropout schedules); vendor “ACG compatibility” APIs; managed ACG inference servers for fleets.
- Assumptions/dependencies: limited access to internals may cap effectiveness; need for standardized hooks in commercial policies.
- Standards and policy: action smoothness certification
- Sectors: safety/regulation (OSHA-equivalent for robots, healthcare compliance).
- Tools/products/workflows: define coherence metrics (ATV/JerkRMS) and pass/fail thresholds for deployment certification; best-practice guidelines for demonstration quality and inference-time guidance; sector-specific profiles (cobots vs surgical).
- Assumptions/dependencies: multi-stakeholder consensus; longitudinal incident data to set thresholds; compatibility with existing safety standards.
- Multi-arm/multi-robot coherence
- Sectors: complex assembly, multi-robot coordination.
- Tools/products/workflows: extend ACG to synchronize intra-chunk coherence across arms/robots; cross-policy guidance to avoid conflicting micro-motions; coordinated insertion or dual-arm handling.
- Assumptions/dependencies: shared perception and timing; policies that expose attention maps across agents or a centralized coordinator.
- Productization: ACG toolchain and analytics
- Sectors: robotics vendors, integrators.
- Tools/products/workflows: a commercial “ACG Toolkit” including an inference server, parameter auto-tuner, coherence analytics dashboards, and QA gates; integrations with popular VLA models and ROS distributions.
- Assumptions/dependencies: sustained support for model updates; customer acceptance of guidance-induced latency; domain adaptation and support contracts.
Glossary
- Action Coherence Guidance (ACG): A test-time guidance method that steers a flow-based policy away from an intentionally constructed incoherent variant to produce smoother, more consistent actions. "we present Action Coherence Guidance (ACG) for VLA models, a training-free test-time guidance algorithm that improves action coherence"
- Action coherence: The smoothness and consistency of successive actions in a trajectory. "Formally, action coherence denotes the smoothness and consistency of successive actions, which can be measured by variability or jerks"
- Action chunking: Generating multiple future actions at once to shorten the effective horizon and reduce compounding error. "Prior work improves coherence through action chunking, which generates multiple actions (typically steps at a time) simultaneously."
- Action head: The module in a VLA architecture responsible for predicting actions from backbone features. "their architecture typically consists of a vision-language backbone coupled with an action head"
- Action Total Variation (ATV): A metric that quantifies temporal variation in action sequences; lower values indicate smoother actions. "we measure the Action Total Variation (ATV, rad/s) and JerkRMS (rad/s)"
- Autoregressive: A modeling approach that predicts the next output conditioned on previously generated outputs. "the early VLA architectures relied on autoregressive LLM architecture"
- Bimanual embodiments: Robot setups with two arms or hands used for dexterous manipulation. "DexMimicGen provides three bimanual embodiments for dexterous manipulation tasks."
- Classifier-Free Guidance (CFG): A guidance technique that improves conditioning by contrasting conditional and unconditional model predictions. "A prominent example is Classifier-Free Guidance (CFG)"
- Conditional flow matching policy: A flow-based policy conditioned on observations and language that learns a denoising vector field toward clean actions. "The conditional flow matching policy is trained to match the conditional denoising vector field "
- Denoising vector field: The target vector field that maps a noised sample toward the clean sample during flow matching. "match the conditional denoising vector field "
- Diffusion models: Generative models that iteratively denoise random noise to produce samples; used here as robot policies. "Diffusion and flow matching models have emerged as powerful robot policies"
- Flow matching policy: A generative policy that learns a continuous-time vector field to map noise to data for action generation. "Diffusion and flow matching policies have recently emerged as a powerful framework for imitation learning"
- Flow matching timestep: The continuous-time variable (τ) that parameterizes the interpolation between noise and data during flow matching. "a flow matching timestep "
- Forward Euler integration: A first-order numerical method used to integrate the learned vector field during sampling. "The action chunk is generated via forward Euler integration as follows:"
- Goal-Conditioned Behavioral Cloning (GCBC): An imitation-learning setup where policies are trained to imitate actions conditioned on goals (e.g., language). "following the Goal-Conditioned Behavioral Cloning (GCBC) setting commonly adopted in recent flow matching policies"
- Guidance scale: A scalar weight (λ) that controls the strength of guidance applied to the vector field during sampling. "where is the guidance scale."
- Guided vector fields: Modified vector fields that incorporate guidance terms to steer the sampling trajectory. "flow-based generative models utilize the following guided vector fields"
- Identity attention map: An attention matrix equal to the identity, forcing each token to attend only to itself and breaking token-to-token communication. "replacing the attention map in the self-attention layers with an identity attention map"
- Imitation learning: Learning a policy from demonstrations rather than explicit reward signals. "policies trained via imitation learning remain highly sensitive to noise in human demonstrations"
- Incoherent vector field: A perturbed vector field designed to produce temporally unstable actions, used as a negative reference for guidance. "ACG constructs an incoherent vector field "
- Jerk: The third derivative of position/angle with respect to time, capturing abrupt changes in acceleration. "Jerk, defined as the third derivative of the motor angle"
- JerkRMS: The root-mean-square of jerk over time; lower values indicate smoother motion. "JerkRMS measures the root mean square of this jerk"
- Perturbation guidance: A guidance approach that steers generation using intentionally degraded model variants rather than unconditional predictions. "recent work has explored perturbation guidance, which steers pretrained diffusion models toward higher quality"
- Receding horizon: A control setting where only a subset of the predicted actions is executed before re-planning, trading off reactiveness and horizon length. "It is applicable only under the receding horizon setting, where the policy predicts 16 actions but executes only the first 8."
- Rectified flow matching: A formulation of flow matching that uses rectified dynamics for training/sampling. "we outline the training procedure and output representation of a rectified flow matching policy."
- Self-attention: A mechanism enabling tokens (e.g., time steps) to attend to each other to maintain consistency across a sequence. "we modify the self-attention layer by replacing the attention map with the identity map"
- Temporal coherence: Consistency and coordination across time steps within a generated action sequence. "thereby promoting temporal coherence among the value tokens ."
- Temporal ensembling: Averaging or aggregating predictions across time windows to stabilize and smooth generated sequences. "ACT further proposed temporal ensembling"
- Unconditional distribution: The model’s output distribution when conditioning inputs (e.g., text) are removed. " indicates the unconditional distribution"
- Vision-Language-Action (VLA) models: Foundation models that take multimodal inputs (vision, language, state) to predict corresponding robot actions. "VLA models take multimodal inputs, including visual observations, language instructions, states, and leverage them to predict corresponding actions."
- White Noise Guidance (WNG): A test-time baseline that injects white noise into features to form an incoherent vector field for guidance. "White Noise Guidance (WNG): As an alternative to construct an incoherent denoising vector field (), we inject white noise () into the intermediate action features"
Collections
Sign up for free to add this paper to one or more collections.

