PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Abstract: Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/

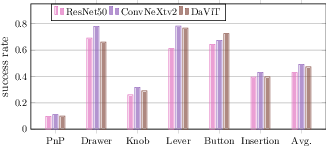

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning”
1. What is this paper about?
This paper is about teaching robots to use both color images and 3D shape information to handle tricky tasks—like opening drawers, pressing buttons, or stacking cups—more accurately and reliably. The authors introduce a new way to represent 3D data, called a “point map,” and a robot learning method named PointMapPolicy (PMP) that uses this representation together with regular images. The goal is to help robots learn from human demonstrations in a smarter, faster, and more precise way.
2. What questions were the researchers asking?
The researchers set out to answer three main questions in simple terms:
- Can their new method (PMP) beat existing robot learning methods that use only images or traditional 3D data?
- What’s the best way to combine color (RGB) and 3D shape information so the robot uses both well?
- Do common image-processing networks (like those used in computer vision) work well on their new 3D “point map” representation?
3. How did they do it? (Methods explained simply)
Think of teaching a robot like teaching a student by example. The robot watches what a human does (videos and sensor data) and learns to copy similar actions when asked.
- Multi-modal observations: The robot sees the world in two ways:
- RGB images: regular color pictures (great for recognizing objects and colors).
- Depth maps: measurements of how far things are (used to build 3D shape).
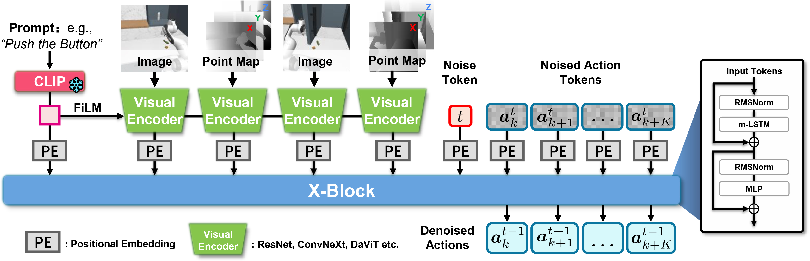
- Point maps: From the depth map, they turn each pixel into a 3D point with XYZ coordinates, and store these points in a tidy 2D grid that lines up with the image. Imagine an image where each pixel also tells you how far and where that point is in 3D. This grid-like structure makes 3D data “look” like an image, so powerful image tools can process it easily.
- Why is this good? Traditional 3D point clouds are messy and unstructured—like a bag of dots—so they’re harder to process efficiently. Point maps are organized like images, so you can use the same fast, proven tools (like ResNet or ConvNeXt) on them.
- Multiple cameras: Because these 3D points are grounded in real space, views from different cameras can be neatly transformed into the same 3D reference frame and fused together.
- Fusing RGB and 3D:
- Early fusion (PMP-6ch): Simply stack RGB and XYZ channels together as a 6-channel “image.”
- Late fusion (used in PMP): First process RGB and point maps separately, then combine the encoded tokens (small chunks of information) with a method called “Cat” (concatenation), which the authors found to work best overall.
- Learning to act with diffusion:
- Diffusion is a technique where you start with random noise and gradually “denoise” it to produce a good result. Here, the “result” is a sequence of robot actions.
- Imagine writing a plan by starting with random scribbles and then cleaning it up step-by-step until it becomes a clear, sensible plan. The robot does this a few steps (just 4 steps in this work), guided by what it sees and the instruction it’s given.
- The backbone model (xLSTM):
- The authors use xLSTM, a modern recurrent network that’s good at handling sequences (like action steps over time) efficiently. It requires less compute than big Transformers but still performs very well.
4. What did they find, and why it matters?
Here are the main takeaways from tests in simulation and on real robots:
- Stronger performance across tasks:
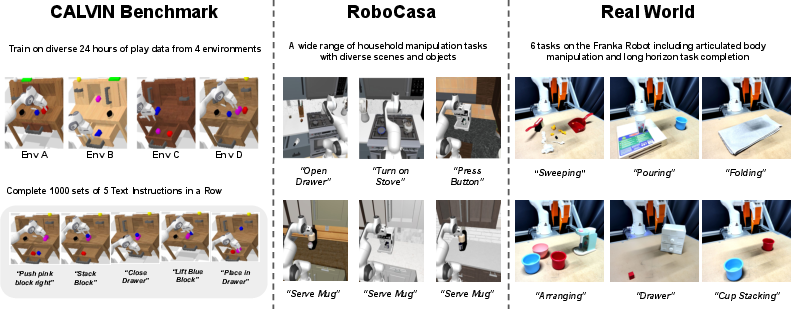
- In the RoboCasa benchmark (many household-like tasks), PMP and its point-only version (PMP-xyz) beat several popular 2D and 3D baselines. PMP-xyz had about a 20% higher average success rate than older 3D methods, showing structured 3D point maps are powerful for precise control.
- In the CALVIN benchmark (long sequences of language instructions and many color-specific tasks), PMP achieved top results among methods trained from scratch, matching or surpassing some larger, pretrained models. However, PMP-xyz (no color) did worse here because CALVIN depends heavily on color cues (e.g., “move the red block”).
- Real-world wins:
- On physical robots, PMP consistently scored higher than an RGB-only baseline across tasks like arranging, folding, stacking cups, opening drawers, pouring, and sweeping. Tasks needing both shape and appearance benefited the most.
- Efficient and fast:
- Because point maps are grid-structured, the system trains and runs quickly. Inference (deciding what to do next) can be just a few milliseconds per step, making real-time control more practical.
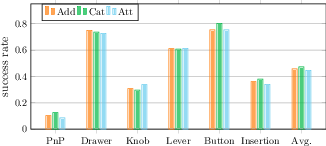
- Fusion matters:
- Late fusion with “Cat” (concatenating information after separate encoders) slightly outperformed other fusion approaches. This suggests carefully combining RGB and 3D after initial processing helps the robot use both types of information effectively.
- Vision encoders work well on point maps:
- Modern image encoders (especially ConvNeXt-v2) handled point maps nicely, confirming that treating 3D as a grid lets you reuse strong 2D tools for 3D understanding.
Why this matters:
- Robots need both “what is it?” (color/appearance) and “where is it, exactly?” (3D shape and position). PMP shows a neat way to combine these so robots can act more precisely, adapt to different camera views, and handle tougher tasks.
5. What could this change in the future?
This research suggests a path toward smarter, more reliable robot manipulation in homes, labs, and factories:
- Better precision and generalization: Using structured 3D point maps with RGB helps robots be more accurate and flexible across many environments and tasks.
- Easier multi-camera use: Point maps make it simple to combine information from different viewpoints, making the robot less sensitive to camera placement or lighting changes.
- Faster, practical systems: The approach is efficient enough for real-time use, which is important for actual robots outside the lab.
- Future improvements:
- Smarter fusion: More advanced ways to merge RGB and 3D could boost results further.
- Pretraining for point maps: Just like image models benefit from huge datasets (like ImageNet), creating large-scale pretraining for point maps could unlock even better performance.
In short, PointMapPolicy shows that organizing 3D data like an image and blending it with color information lets robots learn more effectively from demonstrations, perform better on complex tasks, and run fast enough for the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved gaps, limitations, and open questions that future work could concretely address:
- Point-map encoder pretraining: No pretraining is available for point-map encoders; devise self-supervised objectives (e.g., masked point-map modeling, cross-view consistency, depth-to-normal prediction, contrastive RGB–XYZ alignment) and large-scale datasets tailored to point maps.
- Robustness to RGB‑D noise and failures: Evaluate and mitigate sensitivity to sensor noise, missing depth (holes), specular/transparent surfaces, thin structures, multi-path interference, and quantization artifacts in the unprojection process.
- Calibration and extrinsic drift: Assess performance under intrinsic/extrinsic calibration errors, time-varying camera poses, and asynchronous multi-camera streams; investigate online calibration/pose refinement or uncertainty-aware fusion.
- Dynamic and deformable scenes: Extend point-map representations and policies to handle moving objects, deformable materials, and non-rigid geometry (e.g., cloth folding), where XYZ geometry changes over time.
- Advanced fusion mechanisms: Go beyond Add/Cat/shallow Attn by evaluating learned gating, FiLM-style conditioning, co-attention with deeper stacks, 3D cross-view attention, token-level mixture-of-experts, and uncertainty-aware fusion between RGB and point maps.
- Multi-view scaling: Characterize compute/memory scaling with higher resolutions and more cameras; study token reduction (e.g., learned downsampling, ROI cropping, adaptive resolution) and cross-view aggregation strategies to preserve fine detail.
- Alternative point-map generation: Compare depth unprojection with learned multi-view reconstruction (e.g., DUSt3R/MASt3R), stereo, or LiDAR-derived point maps; quantify trade-offs in accuracy, completeness, and latency.
- Uncertainty modeling: Incorporate per-pixel depth/pose uncertainty into point maps and downstream fusion (e.g., probabilistic maps, confidence-weighted encoders), and study its impact on policy robustness.
- Language grounding with geometry: Analyze how language encoders (CLIP) align with geometric tokens; evaluate performance on instructions referencing spatial relations (e.g., “behind,” “closest,” “leftmost”) vs color cues, and design cross-modal grounding losses.
- Real-world language conditioning: Clarify and evaluate language-conditioned behavior in real robot experiments (instruction variability, compositional commands, zero-shot generalization), not just language-conditioned data collection.
- Comparative baselines: Include strong 3D baselines like RVT/RVT-2 and feature-lifting methods under identical training regimes; control for demo count differences (e.g., GR00T‑N1 uses 100 vs 50 demos) to ensure fair comparisons.
- Action diffusion design: Ablate denoising steps (beyond fixed 4), noise schedules, EDM vs alternative samplers (DDPM, ancestral sampling), and action chunk lengths H to understand performance–latency trade-offs.
- Long-horizon temporal modeling: Stress-test xLSTM vs Transformer/Mamba under much longer sequences, higher-frequency action updates, or memory-intensive tasks; examine gradient stability and temporal credit assignment.
- Tokenization choices: Systematically study point-map channel sets (XYZ vs XYZ+normals/curvature), inclusion of depth or uncertainty channels, and joint vs per-view positional embeddings.
- Handling occlusions and missing regions: Investigate inpainting/scene completion for masked-out points, normal/occupancy estimation, and whether completing geometry improves policy accuracy.
- Cross-view alignment and global frame usage: Quantify the benefits and failure modes of transforming all views to a common frame vs per-view processing; test sensitivity to alignment errors and latency-induced desynchronization.
- Domain shift and generalization: Evaluate robustness to lighting changes, backgrounds, textures, novel objects, and camera placements across simulation→real and cross-lab settings; incorporate data augmentation tailored to point maps.
- On-robot compute: Benchmark inference on CPU/embedded devices (Jetson, ARM) and study model compression/quantization for real-time deployment without high-end GPUs.
- Contact-rich and force-aware control: Extend to action spaces including end-effector wrench/impedance, tactile sensing, or compliance control; assess whether point maps suffice for precise contact behaviors.
- Safety and failure analysis: Provide a systematic breakdown of failure modes (per modality/fusion/backbone) and propose detection/mitigation strategies (e.g., confidence estimation, fallback behaviors).
- Sample efficiency curves: Report performance vs number of demonstrations (not just fixed counts) to characterize data efficiency across modalities and fusion strategies.
- Resolution and encoder choice: Explore encoders specialized for geometric inputs (e.g., 2.5D/3D CNNs, sparse convs) versus repurposed 2D backbones; assess trade-offs at varying image/point-map resolutions.
- Integration with planning: Compare direct diffusion control to hybrid pipelines (keyframe selection + motion planning) and study whether point maps improve planning reliability and precision.
- Reproducibility and release: Ensure full release of code, calibration routines, and data preprocessing (unprojection/masking) to enable faithful replication; include standardized evaluation scripts and seeds.
Practical Applications
Immediate Applications
The findings and innovations in PointMapPolicy (PMP)—structured point maps for multi-modal diffusion-based imitation learning with efficient xLSTM backbones—support deployable use cases that leverage RGB-D sensors, standard vision encoders, and real-time inference.
- Robotic assembly and kitting in flexible manufacturing
- Sector: robotics, manufacturing
- Application: Rapidly teach robots new pick-and-place, drawer/door operations, knob/lever manipulation, and insertion tasks using human demonstrations in changing workcells (e.g., frequent SKU changes).
- Tools/products/workflows: A PMP-based “teach-by-demonstration” station; ROS2 nodes to convert depth into point maps and fuse multi-view RGB + XYZ; low-latency inference pipelines (3–4 ms per cycle) for real-time control.
- Assumptions/dependencies: Calibrated RGB-D cameras with reliable depth; accurate extrinsic/intrinsic parameters; availability of 40–120 human demos per task; gripper and robot kinematics compatible with policy outputs.
- Warehouse and e-commerce fulfillment
- Sector: logistics, robotics
- Application: Shelf picking, container arrangement, bin sorting, and handling knobs/latches on equipment; robust multi-view fusion improves performance in occlusions and perspective changes.
- Tools/products/workflows: PointMap SDK integrated into warehouse control systems; multi-camera fusion node; fast retraining on updated object sets.
- Assumptions/dependencies: Depth quality in cluttered scenes; robust language or task instruction interface (CLIP or equivalent); safety envelopes for human-robot interaction.
- Home service robots for daily living
- Sector: consumer robotics, healthcare (assistive tech)
- Application: Folding laundry, tidying, cup stacking by color, opening/closing drawers, pouring, sweeping; language-conditioned operation aligns tasks to user instructions.
- Tools/products/workflows: Embedded PMP controller on low-cost edge GPUs; mobile base with RGB-D cameras; voice interface mapped to CLIP embeddings.
- Assumptions/dependencies: Reliable depth indoors; color-dependent tasks require RGB fusion (PMP, not PMP-xyz); deformable object handling benefits from late fusion and model fine-tuning.
- Hospital logistics and facility operations
- Sector: healthcare, facilities
- Application: Drawer/door handling, pressing control panels, turning valves/levers (e.g., oxygen or sink fixtures), handling sterilization cabinets; robust across varying lighting/perspectives.
- Tools/products/workflows: PointMapPolicy-enabled cart robots; standardized multi-camera calibration workflows; task libraries for common hospital manipulations.
- Assumptions/dependencies: Clean, calibrated sensor data; safety certification for clinical environments; minimal-domain-gap fine-tuning for hospital equipment.
- Energy and industrial maintenance
- Sector: energy, industrial automation
- Application: Remote manipulation of levers/valves/knobs, panel interaction in plants; multi-view point maps provide geometric grounding across viewpoints.
- Tools/products/workflows: PMP control stack integrated with teleoperation recording to build imitation datasets; fast retraining for site-specific controls.
- Assumptions/dependencies: Robust depth sensing in harsh environments (dust, glare); sealed sensors; pre-deployment calibration routines.
- Academic benchmarking and curriculum
- Sector: academia, education
- Application: Reproducible multi-modal imitation learning coursework and labs; benchmarking on CALVIN/RoboCasa; ablation exercises (fusion strategies Add/Cat/Attn; encoder choices).
- Tools/products/workflows: Open-source PMP training scripts and ROS pipelines; lab assignments using point-map encoders and xLSTM backbones; multi-view calibration exercises.
- Assumptions/dependencies: Access to RGB-D cameras and simulator environments; consistent dataset splits and evaluation protocols.
- Real-time edge deployment in constrained compute settings
- Sector: software, embedded systems
- Application: Low-latency policy inference (∼3 ms) for mobile or collaborative robots; replace heavy Transformers with xLSTM to cut memory and compute.
- Tools/products/workflows: Edge inference service; model-packaging with optimized DDIM solver for 4-step denoising; on-device calibration.
- Assumptions/dependencies: Hardware support for small GPUs/NPUs; stable OS-level timing; deterministic camera pipelines.
- Multi-view perception and sensor fusion tooling
- Sector: software tooling, robotics perception
- Application: Standardized point-map generation (XYZ grids aligned with RGB); per-view late fusion workflow compatible with ResNet/ConvNeXt/ViT; no KNN/FPS needed.
- Tools/products/workflows: “PointMap generator” ROS2 node; fusion module (Cat) with visual encoders; calibration assistant (extrinsics, intrinsics).
- Assumptions/dependencies: Accurate depth unprojection; masking strategy for min/max depth; alignment to world frame.
- Policy and safety evaluation frameworks
- Sector: policy, standards
- Application: Stage-based evaluation metrics for long-horizon manipulation; standardized testbeds for service robots in public spaces (drawers, buttons, levers).
- Tools/products/workflows: Open evaluation harness with multi-stage scoring; safety gates for manipulation near humans; documentation for calibration and data handling.
- Assumptions/dependencies: Agreement on benchmark tasks and scoring; data privacy practices for demonstration collection.
- Data-efficient task onboarding
- Sector: cross-industry robotics
- Application: Use of structured point maps to improve sample efficiency for geometry-heavy tasks; faster task learning with fewer demos (e.g., Folding in 45 demos).
- Tools/products/workflows: Teleoperation capture to imitation dataset; task templates for geometry-centric manipulations; semi-automatic data labeling via policy rollouts.
- Assumptions/dependencies: Diversity in demonstrations; task concept coverage in instructions; robust handling of non-rigid objects requires RGB fusion.
Long-Term Applications
Beyond near-term deployments, PMP’s structured point maps and xLSTM diffusion backbone open pathways to generalist, scalable, and more reliable robotic systems—pending further research in pretraining, fusion, and robustness.
- Foundation models for point-map encoders
- Sector: academia, software, robotics
- Application: Large-scale pretraining of point-map encoders on synthetic and real RGB-D data to achieve ImageNet-like gains for 3D geometry; improved generalization and sample efficiency.
- Tools/products/workflows: PointMap pretraining datasets; self-supervised objectives for XYZ grids; model hubs hosting pretrained point-map backbones.
- Assumptions/dependencies: Availability of large, diverse depth datasets; synthetic-to-real domain adaptation; standardized formats and benchmarks.
- Generalist household and facility robots
- Sector: consumer robotics, facilities
- Application: One policy capable of a broad range of chores and operations (e.g., folding, cleaning, drawers, valves) via multimodal fusion and language conditioning.
- Tools/products/workflows: Continual learning pipelines; instruction-following interfaces; task libraries expanded via lifelong imitation.
- Assumptions/dependencies: Robust multimodal fusion beyond channel concatenation; safety and compliance for autonomous operation; resilience to deformables and reflective surfaces.
- Autonomous operators in healthcare and aging-in-place
- Sector: healthcare, assistive robotics
- Application: Manipulation support for daily activities (medication cabinet access, safe pouring, tidying); hospital logistics tasks under supervision.
- Tools/products/workflows: Human-in-the-loop correction; standardized clinical device interaction datasets; compliance-driven deployment frameworks.
- Assumptions/dependencies: Strong safety guarantees; reliable perception in varied lighting; privacy-preserving data collection; fallbacks for failure cases.
- Industrial teleoperation-to-autonomy pipelines
- Sector: energy, manufacturing, utilities
- Application: Transition from remote human control to autonomous manipulation in hazardous sites; repeat task learning from operator demos.
- Tools/products/workflows: Integrated teleoperation capture, task segmentation, and imitation training; uncertainty-aware policies; redundancy with motion planning.
- Assumptions/dependencies: Robustness to sensor degradation; strong calibration in complex environments; fail-safe designs and regulatory approval.
- Advanced multimodal fusion and cross-attention designs
- Sector: academia, software
- Application: Develop fusion mechanisms beyond Cat/Add/Attn to learn richer geometry-color relationships; adaptive modality selection by task context.
- Tools/products/workflows: Fusion architecture libraries; analysis tools for cross-modal saliency and attribution; curriculum training on modality importance.
- Assumptions/dependencies: Research into efficient attention variants on grids; stable training at scale; careful evaluation across color-dependent tasks.
- Active perception and multi-camera orchestration
- Sector: robotics, software tooling
- Application: Policies that reposition cameras or select views to reduce occlusions and improve geometric observability; dynamic extrinsic re-calibration.
- Tools/products/workflows: View-planning modules; calibration health checks; camera-control policies tied to manipulation sequences.
- Assumptions/dependencies: Hardware that supports camera actuation or selection; tight synchronization; reliable SLAM/pose tracking.
- Sim-to-real pipelines using structured point maps
- Sector: academia, robotics
- Application: Scale training in simulation and transfer via point-map representations (less sensitive than raw RGB to domain gap); leverage synthetic depth from photorealistic simulators.
- Tools/products/workflows: Domain randomization for depth; synthetic pretraining corpora; real-world fine-tuning kits.
- Assumptions/dependencies: High-fidelity depth simulators; calibration-consistent sim–real mapping; robust masking for invalid depth.
- Standardization of RGB-D calibration and point-map formats
- Sector: policy, standards, software tooling
- Application: Create open standards for camera calibration, point-map generation, masking, and multi-view world-frame alignment to enable interoperability and safety audits.
- Tools/products/workflows: Reference implementations; conformance tests; certification programs for sensors and robot stacks.
- Assumptions/dependencies: Multi-stakeholder agreement; maintenance of open repositories; alignment with existing robotics standards (e.g., ROS REP, ISO norms).
- Safety, monitoring, and governance frameworks for imitation learning
- Sector: policy, governance
- Application: Guidelines for data collection, adversarial robustness (lighting, color bias), and human-in-the-loop override; deployment checklists for service robots using multi-modal IL.
- Tools/products/workflows: Safety scoring harnesses tied to stage-based metrics; event logging and incident analysis; consent/privacy controls for demos.
- Assumptions/dependencies: Regulatory engagement; auditing tools for multi-modal policies; standard reporting formats across vendors.
- Cross-modal extensions (tactile, force, audio)
- Sector: academia, robotics
- Application: Extend point maps + RGB with tactile/force sensors to improve manipulation of deformable or slippery objects; audio cues for events (e.g., drawer latch click).
- Tools/products/workflows: Multisensor fusion frameworks; self-supervised alignment between modalities; datasets with synchronized streams.
- Assumptions/dependencies: Hardware integration; synchronized data pipelines; robust fusion policies beyond current architectures.
These applications hinge on the core strengths demonstrated in the paper: structured point maps that make 3D geometry accessible to standard vision encoders, efficient multi-view fusion into a common frame, and fast, low-memory diffusion backbones (xLSTM) enabling real-time control. Feasibility depends on reliable RGB-D sensing and calibration, appropriate fusion for color-dependent tasks, safety and governance controls, and—long-term—pretrained point-map encoders to further strengthen generalization and sample efficiency.
Glossary
- Action chunking: Predicting multiple future actions at once to improve temporal consistency in control. "Predicting sequences of actions, i.e. action chunking, allows for more temporally consistent action prediction~\cite{zhao2023learning}."
- Camera extrinsic parameters: Calibration parameters that describe a camera’s pose relative to a world frame. "Point maps from all cameras are transformed into a common world reference frame using the extrinsic parameters of the camera ."
- Camera intrinsic parameters: Calibration parameters that describe a camera’s internal geometry (e.g., focal length). "where are the camera intrinsic parameters obtained through calibration and is a depth unprojection operation."
- CLIP: A pretrained multimodal model that encodes text (and images) into embeddings for downstream tasks. "The language instruction is first tokenized using a pretrained CLIP text encoder~\cite{radford2021learning} to generate language embeddings."
- ConvNeXt: A modern convolutional neural network architecture used for visual encoding. "This results in a structured data type that can be used with standard architectures such as ResNet~\cite{he_deep_2016}, ViT~\cite{dosovitskiy2021vit}, or ConvNeXt~\cite{liu2022convnext}."
- Cross-attention: An attention mechanism that attends from one set of tokens to another for fusion or conditioning. "and applies \gls{fps} after the first cross-attention layer."
- DDIM-solver: A numerical ODE solver tailored for fast sampling in denoising diffusion models. "Our approach utilizes the DDIM-solver, a specialized numerical \gls{ode}-solver for diffusion models~\citep{song2021denoising} that enables efficient action denoising in a minimal number of steps."
- Depth unprojection: Converting per-pixel depth into 3D coordinates using camera intrinsics. "where are the camera intrinsic parameters obtained through calibration and is a depth unprojection operation."
- Diffusion policies: Policies that generate actions by denoising a stochastic process, typically modeled with diffusion. "RGB images are a common observation modality for diffusion policies due to their ubiquitousness and rich semantic information."
- EDM (Elucidated Diffusion Models): A framework for training and sampling diffusion models with improved robustness and efficiency. "We integrate point maps into a standard diffusion-based imitation learning framework based on EDM~\cite{karras2022elucidating} to demonstrate their effectiveness as a drop-in replacement for RGB images or point clouds."
- FiLM-ResNet: A ResNet variant augmented with Feature-wise Linear Modulation for conditioned visual processing. "For RGB inputs, we use Film-ResNet~\cite{perez2018film} with pretrained ImageNet weights to generate visual embeddings from the observation ."
- Furthest Point Sampling (FPS): A point cloud downsampling method that selects points farthest from each other to preserve coverage. "Downsampling-based methods use Furthest Point Sampling (FPS) to reduce dense point clouds to sparse representations, which PointNet then processes into compact tokens."
- Gaussian Perturbation process: The forward diffusion process adding Gaussian noise to data that models learn to reverse. "Diffusion models are generative models that learn to generate new samples through learning to reverse a Gaussian Perturbation process."
- Grad-CAM++: A visualization technique highlighting regions most influential to model decisions. "we apply Grad-CAM++~\cite{grad_cam_plus_plus} to highlight the regions most influential for action decisions across different modalities."
- Imitation Learning (IL): Learning a policy by mimicking expert demonstrations rather than reward-based optimization. "\acrlong{il} aims to learn a policy from expert demonstrations."
- K-Nearest Neighbors (KNN): A neighborhood-based operation often used on point clouds to build local structures. "Some variants employ FPS+KNN to generate structured point patches."
- Mamba: A state space model architecture enabling sequence modeling with linear-time complexity. "recent works~\cite{jia2024mailimprovingimitationlearning, jia2025xil} explore \glspl{ssm} like Mamba~\cite{gu2024mamba}, achieving linear-time complexity and improved sample efficiency, particularly in low-data regimes."
- m-LSTM: A recurrent layer used in xLSTM-based architectures that serves a role analogous to self-attention. "The core computational element within X-Block is the m-LSTM layer, which serves an analogous function to self-attention in Transformer architectures."
- Multi-view representation: Encoding observations from multiple camera views to improve robustness and spatial reasoning. "Complementary work, such as Robot Vision Transformer (RVT)~\cite{goyal2023rvt}, avoids working directly with raw point clouds by proposing a novel multi-view representation."
- Ordinary Differential Equation (ODE): A continuous-time formulation used for deterministic denoising in diffusion sampling. "After training, we can generate new action sequences beginning with Gaussian noise by iteratively denoising the action sequence with a numerical \gls{ode} solver."
- Orthographic virtual cameras: Synthetic cameras with parallel projection used to re-render point clouds into structured maps. "This approach re-renders the point cloud from a set of orthographic virtual cameras, deriving a 7-channel point map (RGBD + XYZ) from each view."
- Point cloud: An unstructured set of 3D points capturing geometry, distances, and spatial relationships. "An alternative modality is point clouds, unstructured sets of 3D points that preserve geometric shape, distances, and spatial relationships."
- Point maps: A structured 2D grid of XYZ coordinates encoding 3D geometry aligned with image pixels. "Point maps encode 3D information in a regular, 2D grid of Cartesian coordinates."
- PointMapPolicy (PMP): The proposed policy conditioning diffusion models on structured point maps for multimodal IL. "We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling."
- PointNet: A neural network architecture designed to process unordered point sets efficiently. "Downsampling-based methods use Furthest Point Sampling (FPS) to reduce dense point clouds to sparse representations, which PointNet then processes into compact tokens."
- ResNet: A convolutional backbone using residual connections for deep visual representation learning. "This results in a structured data type that can be used with standard architectures such as ResNet~\cite{he_deep_2016}, ViT~\cite{dosovitskiy2021vit}, or ConvNeXt~\cite{liu2022convnext}."
- Score matching: A training objective to learn the gradient of the log-density (the score) for diffusion. "To learn this score, we train a neural network via score matching~\citep{6795935}:"
- State Space Model (SSM): Sequence models that represent dynamics with latent states and linear operators. "recent works~\cite{jia2024mailimprovingimitationlearning, jia2025xil} explore \glspl{ssm} like Mamba~\cite{gu2024mamba}, achieving linear-time complexity and improved sample efficiency, particularly in low-data regimes."
- Stochastic Differential Equation (SDE): A continuous-time stochastic process used to model forward and reverse diffusion. "This perturbation and its inverse process can be expressed through a \gls{sde}:"
- Teleoperation: Controlling a robot remotely to collect demonstrations for training policies. "For collecting demonstrations, we use a teleoperation system consisting of a leader robot and a follower robot."
- Tokenization: Converting inputs into discrete embeddings/tokens for model processing. "The language instruction is first tokenized using a pretrained CLIP text encoder~\cite{radford2021learning} to generate language embeddings."
- Vision Transformer (ViT): A transformer-based architecture for image encoding via patches as tokens. "This results in a structured data type that can be used with standard architectures such as ResNet~\cite{he_deep_2016}, ViT~\cite{dosovitskiy2021vit}, or ConvNeXt~\cite{liu2022convnext}."
- Voxelization: Converting point clouds into grid-like 3D volumes for convolutional processing. "Voxel-based methods like C2F-ARM~\cite{coarse_to_fine_q_attention} and Perceiver-Actor~\cite{shridhar2022perceiveractor} voxelize point clouds and use a 3D-convolutional network for action prediction, but require high voxel resolution for precision tasks, resulting in high memory consumption and slow training."
- xLSTM: A recurrent architecture enhancing gradient flow and expressiveness for sequence modeling. "Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception."
- X-Block: The decoder-only diffusion score network module that processes concatenated tokens. "All tokens are concatenated as inputs to the X-Block, which is the diffusion score network ."
Collections
Sign up for free to add this paper to one or more collections.

