Kinaema: a recurrent sequence model for memory and pose in motion
Abstract: One key aspect of spatially aware robots is the ability to "find their bearings", ie. to correctly situate themselves in previously seen spaces. In this work, we focus on this particular scenario of continuous robotics operations, where information observed before an actual episode start is exploited to optimize efficiency. We introduce a new model, Kinaema, and agent, capable of integrating a stream of visual observations while moving in a potentially large scene, and upon request, processing a query image and predicting the relative position of the shown space with respect to its current position. Our model does not explicitly store an observation history, therefore does not have hard constraints on context length. It maintains an implicit latent memory, which is updated by a transformer in a recurrent way, compressing the history of sensor readings into a compact representation. We evaluate the impact of this model in a new downstream task we call "Mem-Nav". We show that our large-capacity recurrent model maintains a useful representation of the scene, navigates to goals observed before the actual episode start, and is computationally efficient, in particular compared to classical transformers with attention over an observation history.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping robots remember places they’ve already seen and use that memory to find their way later. The authors introduce a new model called “Kinaema” that lets a robot quietly build up an internal memory while it moves around. Later, when the robot is shown a photo of a goal location, Kinaema can tell the robot how far away that place is and which direction to go, even if the goal isn’t visible right now.
Big Questions the Paper Tries to Answer
The paper focuses on a simple but important idea: in the real world, robots shouldn’t start each task with an empty brain. Instead, they should:
- Keep a useful memory of what they saw before a task starts.
- Use that memory to figure out where a pictured location is (distance and direction) when shown a goal image.
- Do this efficiently, without having to re-check every single past observation at every step.
How It Works (with simple analogies)
Two tasks the robot needs to solve
- Mem-Nav: Imagine your robot walks around a building first to “get familiar” with it. This is the priming phase. Later, someone shows the robot a photo of a place in that building. The robot must navigate there. The twist: it wasn’t told the goal during the warm-up, so its memory must be general-purpose and ready for any future photo.
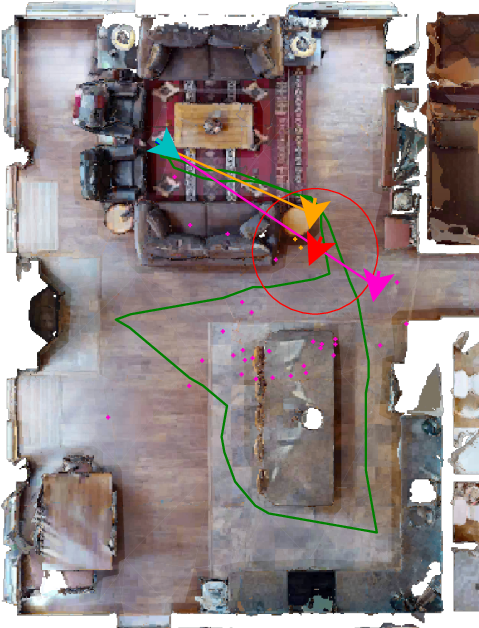
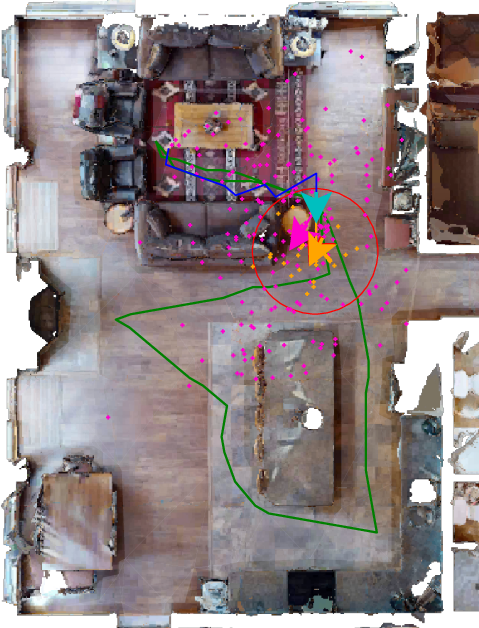
- Mem-RPE (Relative Pose Estimation): This is a skill the robot needs for Mem-Nav. Given a photo of the goal and the robot’s current position, the robot must estimate the “relative pose” of the goal — basically, “how far is it (distance) and which way should I turn to face it (bearing)?” In math terms, pose includes translation (distance and direction) and rotation, but rotation is less important for navigation than knowing where to go.
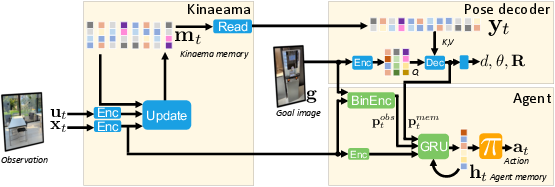
Kinaema: memory in motion
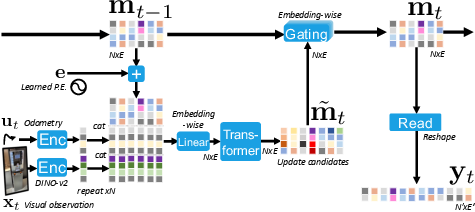
Think of the robot carrying a compact “memory backpack” filled with N small memory cards (called embeddings). Each card stores part of what the robot has learned about the environment.
At each time step:
- The robot sees a camera image and its movement info (called odometry, like “I moved forward 0.25 meters and turned 10 degrees”).
- Kinaema updates the memory backpack using a transformer. You can imagine the transformer as a smart librarian that organizes and condenses all the recent observations into the memory cards so they stay useful and tidy.
- Then comes “gating” — a way to control how fast or how much each memory card gets updated. Think of it like a dimmer switch or a speed limit: if a card shouldn’t change too much this step, gating slows it down. This makes training more stable, helps prevent memory “forgetting” too fast, and lets different cards change at different speeds.
Crucially, Kinaema doesn’t store the full history of all past frames. It keeps a compact memory that gets updated step-by-step. That means when the robot needs to answer a question, it looks at the memory directly. It doesn’t need to re-scan all past images every time, which makes it more efficient for long runs.
When asked to find a goal from a photo, a “decoder” looks at the goal image and “cross-attends” to the memory — in plain words, it focuses on the most relevant memory cards — to predict distance and direction to the goal.
Training and using the agent
- Pre-training: The model practices Mem-RPE. During training, the robot watches sequences of frames and movement. At the end, it is asked to predict where various images are relative to its current place — some images were actually seen during the sequence, others are from nearby spots it didn’t exactly see. This prevents simple memorization and teaches general understanding.
- There’s also a “masked image modeling” helper task (like solving a jigsaw puzzle with missing pieces), which helps the model learn strong visual features.
- Integration into navigation: The authors combine Kinaema with a strong existing navigation agent called DEBiT. DEBiT is good at comparing what the robot sees right now with the goal image (“binocular” comparison). Kinaema adds the power to locate goals that were seen earlier but aren’t currently visible. Together, they help the robot choose actions to reach the goal.
What They Found
Here are the main results, explained simply:
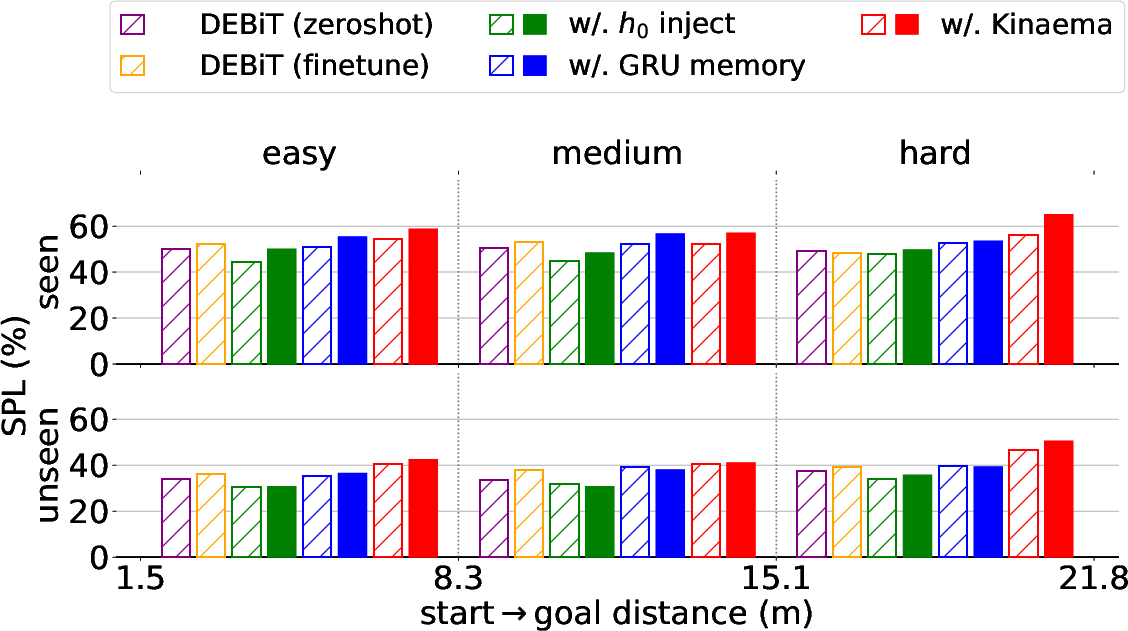
- Kinaema outperforms several other memory models:
- Compared to older recurrent models (like GRUs) and newer ones (xLSTM, MooG, EMA), Kinaema was best at the Mem-RPE skill — predicting where the goal image is relative to the robot using memory.
- Kinaema stayed more accurate even when evaluated on much longer sequences than it was trained on, showing good generalization.
- Efficiency for long runs:
- Methods that look back over the entire history at each step tend to slow down a lot as sequences get longer.
- Kinaema updates and queries its memory without scanning all past frames, which helps it handle long sequences better.
- Key design choices matter:
- Both parts — transformer update and gating — were necessary. Removing either made performance worse.
- Memory structure matters. Fewer, larger memory cards often worked better than many tiny ones.
- Training with random sequence lengths and using the masked-image puzzle helped it generalize to longer sequences.
- Better navigation:
- When Kinaema was added to the DEBiT agent, the robot’s navigation scores improved, especially on harder, long-distance episodes where the goal isn’t visible from the start.
- This shows that using memory collected during the priming phase helps the robot find smarter paths later.
Why This Is Important
- Real-world readiness: Robots in homes, hospitals, warehouses, or schools shouldn’t forget everything when a task starts. Kinaema helps them remember what they saw before and use it to find places faster and more reliably.
- Scales to long operations: Because it doesn’t need to re-check the whole history constantly, Kinaema is more practical for long missions — minutes, hours, or even longer.
- General idea beyond navigation: The same kind of memory could help other tasks, like relocalizing in a building, helping drones remember outdoor areas, or assisting AR devices in recognizing spaces they’ve seen before.
Takeaway
Kinaema is a new way for robots to keep a smart, compact memory of places they’ve been. It uses a transformer to neatly organize memory and gating to control how fast memory changes. Trained to estimate “where is this goal image relative to me?” from memory, it helps a robot navigate to previously seen places more efficiently and reliably. The result: better performance on hard, long-distance navigation tasks, and a step toward robots that operate more like people — remembering and using what they’ve learned over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Real-world validation is absent: the model is only tested in photorealistic simulation (Habitat) with idealized odometry. Assess robustness under realistic sensor noise, drift, calibration errors, lighting changes, and dynamic environments (moving objects, rearrangements).
- Odometry modeling is underspecified: the paper encodes odometry as pose differences via an MLP, but does not evaluate sensitivity to odometry noise or drift, nor how memory updates handle loop closure or accumulated error over long horizons.
- Claims of computational efficiency are not substantiated: there is no wall-clock profiling, memory footprint, or throughput comparisons across baselines. Clarify per-step complexity (including transformer self-attention over memory embeddings, which scales as O(N2)) and decoder cross-attention cost, and report latency and GPU utilization versus attention-over-history transformers.
- Generalization to very long sequences remains limited and unexplored: training uses sequence lengths T ∈ [50,100], and evaluation only reaches T=800, with noticeable performance drops. Investigate training curricula and architectures that sustain thousands of steps, including stability over multi-hour/daily operations.
- Training instability is noted but unresolved: Kinaema exhibits bi-modal performance across seeds. Provide a robust training recipe (initialization, optimizer settings, gradient clipping, gating temperature, learning-rate schedules) and analyze why seeds diverge (e.g., gating dynamics, transformer update sensitivity).
- Memory capacity vs. environment coverage is not characterized: no principled relationship is provided between number/size of embeddings (N, E), environment size/complexity, and downstream performance. Quantify coverage requirements, forgetting behavior, and how capacity should scale with scene size and mission duration.
- Interpretability and consistency of memory are only qualitatively shown: beyond visualizations of cross-attention, there is no quantitative probe of whether memory encodes occupancy, topology, visibility, loop closures, or scene semantics. Develop metrics and probes (e.g., localization accuracy by region, memory drift, consistency under revisits).
- Read-out mechanism is simplistic (reshape) and unstudied: explore learned read-outs (attention pooling, slot selection, key–value addressing, hierarchical pooling), and characterize how read-out design affects RPE accuracy and navigation performance.
- Gating design choices are narrow: gating is implemented as a GRU cell with shared weights across embeddings. Compare per-embedding versus cross-embedding gating, gating parameterization depth, and whether the shared-weight constraint limits expressivity or stability at larger N.
- Integration strategy within the agent is limited: the policy consumes latent pose embeddings from the penultimate layers rather than explicit pose predictions. Evaluate using decoded pose directly, goal-bearing priors, or learned planners that consume pose for planning (e.g., differentiable planning, model-based RL).
- Primer design is fixed and not optimized: priming sequences use predefined paths and a fixed length (P≈200) with no goal. Study the sensitivity of performance to primer length, coverage, and trajectory diversity, and investigate learning a goal-independent exploration policy that optimizes future Mem-Nav success.
- Memory persistence across episodes is unclear: although the paper targets continuous operation, it appears memory is rebuilt per episode via priming. Evaluate persistent memory across multiple episodes, scene revisits, and days, including mechanisms for aging, consolidation, and forgetting.
- Comparison to explicit mapping baselines is missing: strong map-based methods (metric/topological mapping with global localization and retrieval) are not included as baselines in Mem-Nav. Provide apples-to-apples comparisons in efficiency, accuracy, and robustness, and explore hybrid designs that fuse latent memory with maps.
- Baseline fairness and configuration transparency need improvement: MooG is reimplemented without its specific loss, xLSTM is used as a plug-in without tailored query integration, EMA is modified to train λ per-element. Report sensitivity analyses and ensure baselines are tuned comparably for memory size, sequence length, and decoder capacity.
- Multimodal sensing is not explored: only RGB and odometry are used. Evaluate depth/RGB-D, panoramic cameras, IMU, LiDAR, or audio to improve memory formation and pose estimation, and assess how modalities interact with memory capacity and update stability.
- Environment non-stationarity and changes are untested: evaluate performance when the environment changes between priming and navigation (doors closed/opened, moved furniture), and design memory update/forgetting strategies that cope with non-stationary scenes.
- Relative pose metrics and their navigation relevance need refinement: rotation towards the agent is supervised but claimed “of limited relevance.” Provide explicit bearing error metrics, calibration curves, and ablate how each pose component (distance, bearing, orientation) contributes to navigation success.
- Memory update dynamics are not analyzed: quantify how fast memory slots update/forget, whether different embeddings specialize to regions or semantics, and how gating modulates timescales. Probe for catastrophic forgetting and slot interference over long sequences.
- Alternative decoders and retrieval formulations are missing: the paper uses a cross-attention transformer to decode relative pose. Explore pointer networks, explicit retrieval over memory slots, learned indexing, or contrastive retrieval losses to improve query-to-memory alignment.
- Sample efficiency and training cost are high: PPO training is 300M steps (and Mem-Nav fine-tuning at 100M). Report learning curves, data efficiency, and whether pretraining better reduces RL steps, and investigate off-policy or offline RL alternatives.
- Scalability and resource constraints are not addressed: provide guidelines for N and E under compute/memory budgets, and characterize the trade-offs (accuracy vs. latency vs. memory) to make the approach practical for onboard embedded hardware.
- Extension to multi-goal or sequential tasks is not evaluated: Mem-Nav considers a single goal per episode. Study how Kinaema handles multiple sequential goals, persistent task queues, and task-specific memory retrieval under time pressure.
- Domain transfer and generalization gaps: although HM3D/Gibson splits are used, detailed split names and counts are obscured in the text. Release clear splits, code, and trained models; evaluate cross-dataset generalization (e.g., to Matterport3D, ScanNet) and real-world indoor environments.
- Failure mode analysis is minimal: identify where Mem-RPE fails (low overlap queries, textureless regions, extreme viewpoints), how failures affect navigation (detours, wrong stops), and design targeted improvements (e.g., robust feature pretraining, wide-FOV cameras).
- Theoretical underpinnings of “O(1) with respect to history length” are vague: formally analyze update/query complexity with distributed memory and transformers, and clarify asymptotics w.r.t. sequence length, number of memory slots, and query token count.
- Use of rotation supervision without downstream usage is not justified: rotation towards the agent is supervised but not exploited in policy. Quantify its contribution during pretraining and test whether dropping it affects navigation, or integrate it in downstream planning.
- Alternative training signals are underexplored: masked-image modeling helps OOD generalization, but other auxiliary tasks (contrastive consistency across revisits, temporal cycle-consistency, scene graph prediction) may better regularize long-horizon memory.
- Robustness to low-overlap queries is not tested beyond “alt frames”: evaluate on benchmarks like MapFree-Relocalization with controlled overlap ratios, and test whether memory-based RPE can handle large viewpoint changes without binocular comparisons.
- Memory read-out shape selection (N', E') is heuristic: systematically study how read-out dimensionality and structure affect decoder performance, and whether adaptive or learned read-out improves generalization to longer sequences.
- Safety and reliability considerations are absent: assess how memory errors propagate to actions (e.g., unsafe navigation), include uncertainty estimation for pose predictions, and design policies that hedge against memory uncertainty.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating the paper’s Kinaema model, Mem-RPE decoder, and Mem-Nav workflow into existing robotics, software, and operations stacks. Each item specifies the sector, a concrete product/workflow, and key assumptions or dependencies.
- Indoor service robots: navigate-by-photo
- Sector: healthcare, hospitality, airports, corporate campuses
- Product/workflow: add a “navigate-by-photo” capability to mobile service robots. Operations run an offline priming sweep (fixed trajectory) at the start of a shift to populate latent memory; staff then issue navigation requests by sending a goal image. The robot estimates the relative pose of that location using Mem-RPE and executes the path with its existing policy controller.
- Assumptions/dependencies: the goal image must depict a previously observed area; reasonable odometry quality; moderate scene dynamics between priming and task; integration into ROS/Nav2 or a similar stack; privacy-safe capture and storage of visual data.
- Warehouse logistics robots: faster item/aisle localization
- Sector: logistics, retail e-commerce
- Product/workflow: pre-shift priming pass through aisles builds a latent memory. During picking, robots query Mem-RPE with a reference photo of the target shelf/fixture to get direction and distance, reducing exploration. Combine with barcode/QR detection for final confirmation.
- Assumptions/dependencies: stable shelving layouts; lighting variability handled by visual encoder; human-in-the-loop can supply goal images or templated references; requires a fall-back to map-based SLAM if layout drastically changes.
- Facility inspection and maintenance routing
- Sector: energy, utilities, manufacturing
- Product/workflow: technicians attach reference photos to work orders (e.g., a valve, gauge, panel). Robots perform a brief priming sweep of the facility, then use Mem-RPE to navigate to targets by photo, minimizing search time and path length.
- Assumptions/dependencies: consistent visual appearance of equipment; safe traversal policies; on-device or edge compute for low latency.
- Security patrols responding to visual alerts
- Sector: security
- Product/workflow: a patrol robot conducts periodic priming tours. When an alert includes an image (e.g., from a camera snapshot), the robot uses Mem-RPE to quickly move to the relevant vantage point.
- Assumptions/dependencies: alert images correspond to previously seen areas; careful handling of privacy and evidentiary chain; robust operation under different lighting conditions.
- Construction site monitoring: find-by-photo
- Sector: construction, AEC
- Product/workflow: robots or drones do a priming scan of the site each morning. Supervisors attach site images (e.g., a specific beam or duct section) to inspection tasks; the system uses Mem-RPE to guide robots to precise locations for photo capture and progress logging.
- Assumptions/dependencies: rapid site changes may reduce match rates; maintain frequent priming to refresh memory; dust/occlusions require robust camera pipelines.
- Home and office robots: “go to this place” via image
- Sector: consumer electronics, workplace automation
- Product/workflow: users show the robot a phone photo of a room, doorway, or appliance. After an initial priming tour, the robot uses Mem-RPE to localize and travel to the place for cleaning, delivery, or inspection.
- Assumptions/dependencies: small-scale environment; lightweight on-device inference; simple, privacy-respecting data retention policies.
- AR indoor navigation for people: photo-to-direction overlay
- Sector: software, wayfinding
- Product/workflow: a building operator runs a priming sweep to build a shared latent memory. A mobile app lets users take or select a target photo; the app uses a Mem-RPE service to compute relative pose and overlays arrows and bearings in AR to guide the user.
- Assumptions/dependencies: cloud/edge service hosting the memory; secure handling of user-uploaded images; sufficient overlap between user photo and the primed coverage.
- Robotics SDK add-on: memory module for embodied agents
- Sector: software, robotics R&D
- Product/workflow: package Kinaema as a ROS-compatible node or Python SDK with a Mem-RPE API. Provide utilities to run priming trajectories, store latent memory, and call a
relative_pose(image)function to feed downstream policies. - Assumptions/dependencies: integration with existing perception stacks (e.g., ViT encoders like DINOv2), odometry sources, and policy controllers (PPO/RL or rule-based).
- Academic benchmarking and curriculum
- Sector: academia
- Product/workflow: adopt Mem-Nav and Mem-RPE as course assignments and lab benchmarks to study long-horizon memory, O(1) update/query designs, gating for stability, and generalization to longer sequences; release pre-primed memories for standardized evaluation.
- Assumptions/dependencies: access to simulators (Habitat, HM3D/Gibson) or real-world labs; reproducible training seeds; masked image modeling improves OOD generalization.
- Privacy and operations readiness guidelines
- Sector: policy/operations
- Product/workflow: institutional policies for “priming sweeps” (time, routes, signage), data retention limits for latent memories, and opt-out zones. Draft SOPs that require memory purging or re-priming after layout changes.
- Assumptions/dependencies: legal review of visual data capture; clear labeling for occupants; audit logs of memory updates and access.
Long-Term Applications
These applications require further research, scaling, or development (e.g., real-world robustness, multi-day persistence, cross-robot sharing, hardware acceleration, or policy standardization).
- Persistent, cross-day memory for large facilities
- Sector: healthcare, airports, manufacturing, campuses
- Product/workflow: maintain and incrementally update a building-scale latent memory that persists across days/weeks, enabling robots to localize from user-supplied images without re-priming each shift.
- Assumptions/dependencies: robust handling of layout changes and drift; continual learning without catastrophic forgetting; versioning and rollback of memory states.
- Fleet-level shared memory services
- Sector: robotics platforms, cloud services
- Product/workflow: a central service aggregates latent memories from multiple robots, supports deduplicated updates, and serves Mem-RPE queries to any device in the fleet.
- Assumptions/dependencies: standardized memory formats; bandwidth and latency constraints; access control; privacy-preserving federated updates.
- Mapless navigation alternative to SLAM in dynamic spaces
- Sector: robotics
- Product/workflow: replace or augment SLAM with memory-based navigation that uses O(1) update/query w.r.t. history length. Useful where maps quickly become stale (events, retail reconfigurations).
- Assumptions/dependencies: rigorous real-world validation; robustness to severe odometry noise; fallback planners; explainability of memory queries.
- Building-wide indoor positioning for smartphones by photo-localization
- Sector: wayfinding, smart buildings
- Product/workflow: deploy a building memory service for tenants/visitors to navigate by uploading a photo of a destination. The app returns bearing/distance and a turn-by-turn route.
- Assumptions/dependencies: coverage completeness; load balancing; secure photo handling; upgrading memory when interiors change.
- Search-and-rescue in GPS-denied environments
- Sector: public safety, disaster response
- Product/workflow: pre-scan critical buildings (hospitals, schools) to build latent memories; in emergencies, responders can share a victim’s or room photo to guide drones/UGVs to the location quickly.
- Assumptions/dependencies: extreme domain shift (smoke, debris) requires robust vision; safety-critical validation; coordination with human teams.
- Hospital logistics and assistive care robots
- Sector: healthcare
- Product/workflow: long-horizon memory aids robots in reliably navigating complex wards to deliver medications, specimens, or equipment based on photos of locations or signage.
- Assumptions/dependencies: strict privacy controls (HIPAA/GDPR); robust against crowded, dynamic scenes; interoperability with hospital IT.
- Sidewalk delivery and micro-mobility navigation
- Sector: last-mile delivery
- Product/workflow: maintain urban micro-route memories to find customer drop-off points from photos (doors, mailboxes), reducing wrong deliveries and manual intervention.
- Assumptions/dependencies: outdoor visual variability; cross-weather generalization; regulatory constraints in public spaces.
- Hardware acceleration for recurrent transformers with gating
- Sector: semiconductors, edge AI
- Product/workflow: design edge accelerators optimized for the Kinaema update pattern (transformer contextualization + shared-weights gating) to improve latency and power consumption.
- Assumptions/dependencies: co-design with memory footprint (number/size of embeddings); quantization-friendly training; on-device masked image modeling.
- Standards and regulation for memory-aware robots
- Sector: policy/regulation
- Product/workflow: develop standards for data minimization, retention, auditability, and secure querying of long-term visual memories; guidance on “priming sequence” conduct and occupant notice.
- Assumptions/dependencies: multi-stakeholder processes; alignment with existing video surveillance rules; certification for safety-critical deployments.
- Digital twins integration
- Sector: smart buildings, industrial IoT
- Product/workflow: fuse latent memory embeddings with BIM/digital twins to support maintenance planning, asset localization by photo, and automated route optimization across changing environments.
- Assumptions/dependencies: schema alignment; continuous synchronization; tools for interpreting cross-attention maps to validate memory–region correspondences.
- Education and workforce development
- Sector: academia, vocational training
- Product/workflow: create modules on long-term memory models, Mem-RPE, and recurrent transformers for robotics; hands-on labs transitioning from simulator benchmarks to real-world pilots.
- Assumptions/dependencies: access to robots and facilities; joint industry–academia projects; funding for longitudinal studies.
General assumptions and dependencies that affect feasibility
- Visual overlap constraint: Mem-RPE assumes the goal image depicts a region covered during priming; query failures rise when overlap is low or scenes change significantly.
- Odometry quality: noisy or biased odometry affects memory updates; sensor fusion (IMU, wheel encoders, visual odometry) improves robustness.
- Sim-to-real gap: results are in photorealistic simulators (Habitat, HM3D/Gibson). Real-world deployment needs domain adaptation, calibration, and validation under lighting/weather/crowds.
- Compute and memory budgets: while updates/queries are O(1) w.r.t. history length, total capacity scales with the number and size of embeddings (N, E). Edge devices may need optimization or hardware acceleration.
- Training stability: gating is critical; seed sensitivity observed in experiments implies careful hyperparameter tuning and monitoring.
- Privacy and compliance: continuous visual observation and latent memory storage require clear policies (consent, retention limits, opt-out), especially in healthcare and public spaces.
- Operational workflows: priming sequences must be scheduled and repeated when layouts change; fallback strategies (traditional SLAM, human guidance) should be in place.
Glossary
- Bearing: The horizontal angle from the agent to the goal location, treated as part of translation in this work. Example: "Rotation towards the goal, a.k.a. 'bearing', is part of the translation error."
- Binocular encoder: A module that compares a current observation with a goal image to infer goal direction. Example: "Binocular encoder - get goal direction"
- CLS token: A special classification token prepended to transformer inputs and used for prediction. Example: "pose is predicted from an additional CLS token added to the inputs."
- Cross-attention: An attention mechanism that relates a query to key-value pairs from another source, used to query memory with a goal image. Example: "implemented as a transformer with cross-attention between encoded query image and read out memory"
- CroCo: A large pre-training approach for correspondence that recent RPE methods leverage. Example: "Both leverage CroCo for pre-training."
- DEBiT: A binocular transformer-based agent pre-trained for relative pose and visibility, used as the navigation backbone. Example: "The DEBiT agent is capable of efficiently detecting goals when they are visible"
- DINO-v2: A self-supervised vision model whose weights initialize the visual encoder. Example: "DINO-v2 ViT-Small/14"
- Differentiable RANSAC: A variant of RANSAC that allows gradient-based learning for pose estimation. Example: "supervises relative pose alone with differentiable RANSAC formulations"
- DUSt3R: A model that regresses dense pointmaps for 3D understanding and pose. Example: "DUSt3R regresses pointmaps,"
- Embodied AI: AI methods that operate within simulated or real physical environments with sensors and actions. Example: "The majority of work in embodied AI"
- Geodesic distance: Shortest-path distance along the environment’s navigable space, used for rewards and evaluation. Example: "increase in geodesic distance to the goal"
- GRU: A gated recurrent unit used for memory updates and gating in the proposed model and agent. Example: "Gating is inspired by GRUs by adding an update gate and a forget gate to the model"
- Habitat simulator: A photorealistic simulator for embodied navigation tasks. Example: "We use the Habitat simulator"
- HM3D: A large dataset of 3D indoor environments used for training and evaluation. Example: "We trained the models on the HM3D and Gibson datasets"
- ImageNav: Image-goal navigation where the agent must reach the location depicted by a goal image. Example: "Image goal navigation, 'ImageNav', adds a skill linked to relative pose estimation"
- Kalman-like: Refers to updates that correct states with observations in a manner reminiscent of Kalman filtering. Example: "corrected (in a Kalman-like sense)"
- K-items scenario: A continuous navigation setup involving multiple sub-episodes with prior information. Example: "Common formulations are the K-items scenario"
- Kinaema: The proposed recurrent sequence model with distributed latent memory for navigation. Example: "We call our model 'Kinaema', a neologism from kinema (motion) and mnema (memory)."
- LRU: A learned recurrent unit inspired by control theory for sequence modeling. Example: "state space models like S4, Mamba and LRU"
- LSTM: Long short-term memory networks, classical recurrent models used for sequences. Example: "LSTMs"
- Mamba: A modern state-space model for efficient sequence processing. Example: "state space models like S4, Mamba and LRU"
- MASt3R: A model that learns descriptors and pointmaps for robust relative pose. Example: "MASt3R additionally learns a descriptor inspired by image matching."
- Masked image modeling: A self-supervised objective reconstructing masked patches to improve representations. Example: "We add an auxiliary masked image modeling loss"
- Mem-Nav: A continuous navigation task where the agent can exploit pre-episode observations via latent memory. Example: "We evaluate the impact of this model in a new downstream task we call 'Mem-Nav'."
- Mem-RPE: Estimating relative pose between a query image and the agent’s latent memory. Example: "our 'Mem-RPE' task requires estimating the pose between an image and the agent's memory."
- MooG: A recurrent transformer-based model with prediction-correction steps and large learned memory. Example: "MooG is probably the model closest to us, as it is recurrent with a transformer update."
- Odometry: Motion estimates describing changes in pose between time steps. Example: "an odometry estimate in the form of a difference of agent poses between t and t−1."
- Out-of-distribution (OOD): Evaluation beyond training distribution, e.g., longer sequences than seen in training. Example: "particularly impacts OOD behavior, generalization to longer sequences."
- PPO: Proximal Policy Optimization, a reinforcement learning algorithm used to train the policy. Example: "jointly with PPO for 300M steps"
- Priming sequence: A pre-episode exploration phase for building memory without knowing the future goal. Example: "An initial priming sequence of length P"
- Relative pose estimation (RPE): Estimating translation and rotation between two views (or a view and memory). Example: "classical relative pose estimation"
- ResNet-18: A convolutional visual encoder used in the agent’s monocular pipeline. Example: "a ResNet-18"
- RPE decoder: The transformer-based module that decodes goal-relative pose from memory and the query image. Example: "the same cross-attention mechanisms as the RPE decoder"
- Self-attention: An attention mechanism relating elements within the same set, used to contextualize memory embeddings. Example: "followed by self-attention,"
- S4: A structured state-space model for long sequences. Example: "state space models like S4, Mamba and LRU"
- Slack cost: A small per-step penalty encouraging efficient trajectories in RL training. Example: "slack cost λ{=}0.01 encourages efficiency."
- SPL: Success weighted by Path Length, an efficiency-aware navigation metric. Example: "SPL, i.e, SR weighted by the optimality of the path,"
- State space models: Sequence models that evolve latent states via linear dynamical systems. Example: "state space models like S4, Mamba and LRU inspired from control theory"
- Teacher forcing: A training strategy supplying ground-truth inputs to recurrent models during sequence encoding. Example: "teacher forced"
- Token Turing Machines: Hybrid attention–recurrence models proposed for efficient sequence processing. Example: "Token Turing Machines are prominent examples."
- Topological map: A graph-like representation of places and connectivity used in classical navigation. Example: "metric or topological map"
- Transformer: An attention-based neural architecture; here used both for updates and decoding in a recurrent system. Example: "We introduce a new transformer-based recurrent model"
- Vision Transformer (ViT): A transformer architecture applied to images via patch embeddings. Example: "encode the visual input with a Vision Transformer (ViT)"
- xLSTM: An LSTM variant with matrix-shaped states and covariance-style updates. Example: "xLSTMs maintain a matrix shaped cell state updated with the covariance update rule"
Collections
Sign up for free to add this paper to one or more collections.