- The paper introduces a framework that optimizes multilingual prompts through modular transformations to enhance naturalness, cultural adaptation, and difficulty.
- By applying naturalness, cultural, and difficulty operators, the method overcomes English-centric biases and improves fine-tuning performance across tasks.
- Experimental results demonstrate that the approach significantly enhances data quality and downstream performance, especially in low-resource languages.
Multilingual Prompt Optimization for Synthetic Data
This essay examines the paper titled "The Art of Asking: Multilingual Prompt Optimization for Synthetic Data," which presents a novel framework for optimizing prompts in multilingual LLMs to improve synthetic data generation. The methodology focuses on leveraging prompt transformations to enhance naturalness, cultural adaptation, and difficulty, fundamentally shifting the synthetic data paradigm from generation-centric to prompt-centric approaches.
Introduction
The paper addresses the limitations of traditional synthetic data generation methods, which heavily rely on English-to-target language translations, leading to English-centric biases. Such biases introduce translation artifacts and fail to adapt content culturally, thus limiting the model's generalization and reaching its full potential in multilingual contexts.
The authors propose a lightweight framework designed to perform systematic transformations on prompts across three key dimensions: Naturalness, Cultural Adaptation, and Difficulty Enhancement. These transformations aim to produce data that is more linguistically diverse, culturally relevant, and challenging, thereby refining the input data distribution (P(x)) rather than focusing solely on the output completions (P(y∣x)).
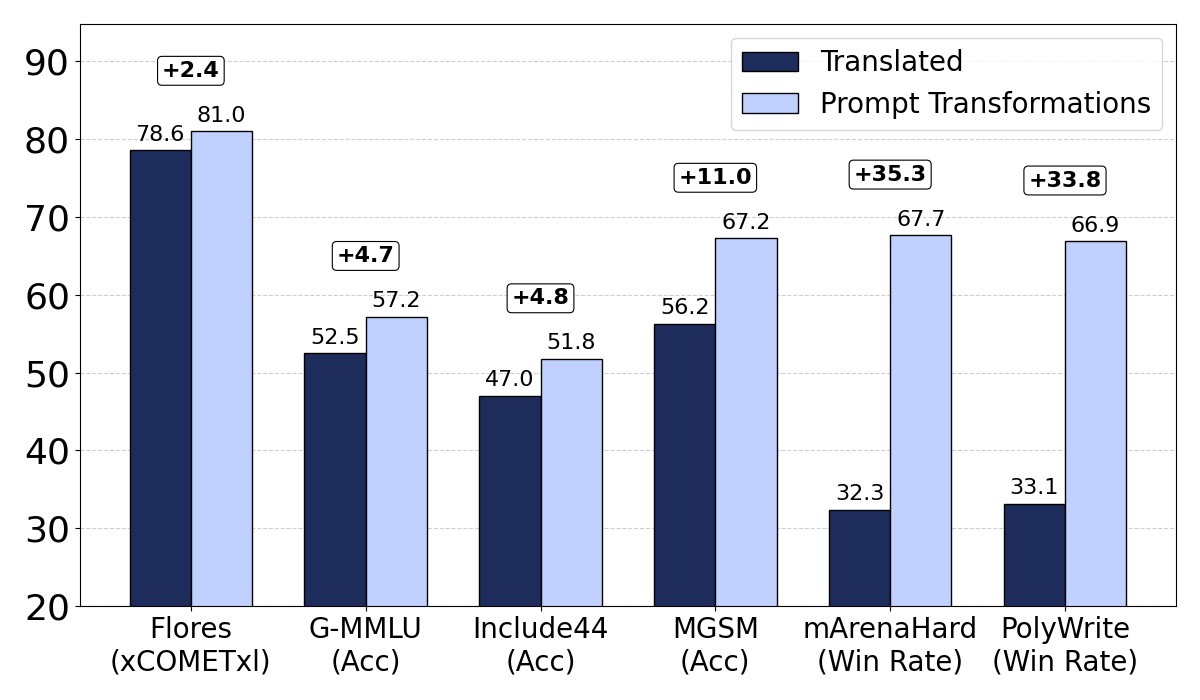
Figure 1: Prompt transformations consistently improve over translations: Comparison of translated model and our most well-rounded method (Cultural+Difficulty Mix) across different multilingual benchmarks. mArenaHard and Polywrite win-rates are in direct comparison between the two models.
Methodology
Problem Setup
The approach begins by translating a distribution of prompts from a high-resource source language to multiple target languages. The resulting prompts are then subjected to a series of transformative operations designed to enhance specific qualities.
The transformation operator T is defined as a modular family capable of refining translated prompts into an optimized distribution. These operators, Tnat, Tcult, and Tdiff, target the dimensions of naturalness, cultural adaptation, and difficulty enhancement, respectively.
- Naturalness (Tnat): Focuses on removing translation artifacts and restoring idiomatic phrasing.
- Cultural Adaptation (Tcult): Adapts content to reflect culturally relevant examples and norms.
- Difficulty Enhancement (Tdiff): Expands task complexity by reformulating prompts into more challenging instructions.
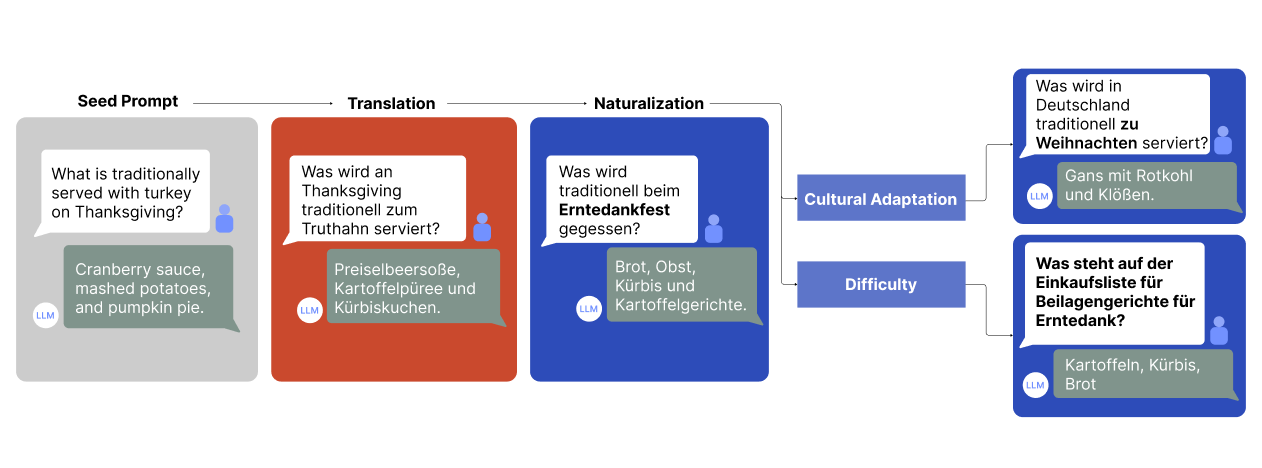
Figure 2: Illustration of our prompt transformations on a representative toy example that gets adapted for German: Each transformation modifies the original English prompt, with major modifications highlighted in bold.
Application in Experiments
The transformations are evaluated on twelve languages, leveraging a strong multilingual LLM to generate completions. The data is then used to fine-tune a 7B base model, benchmarking improvements on a diverse set of tasks, including mathematical reasoning, translation, and open-ended generation.
Results and Discussion
Data Quality Improvements
The transformations yielded substantial improvements in data quality across various dimensions. Specifically, naturalness increased lexical diversity, cultural adaptation improved fluency, and difficulty enhancement significantly raised task complexity and overall quality.
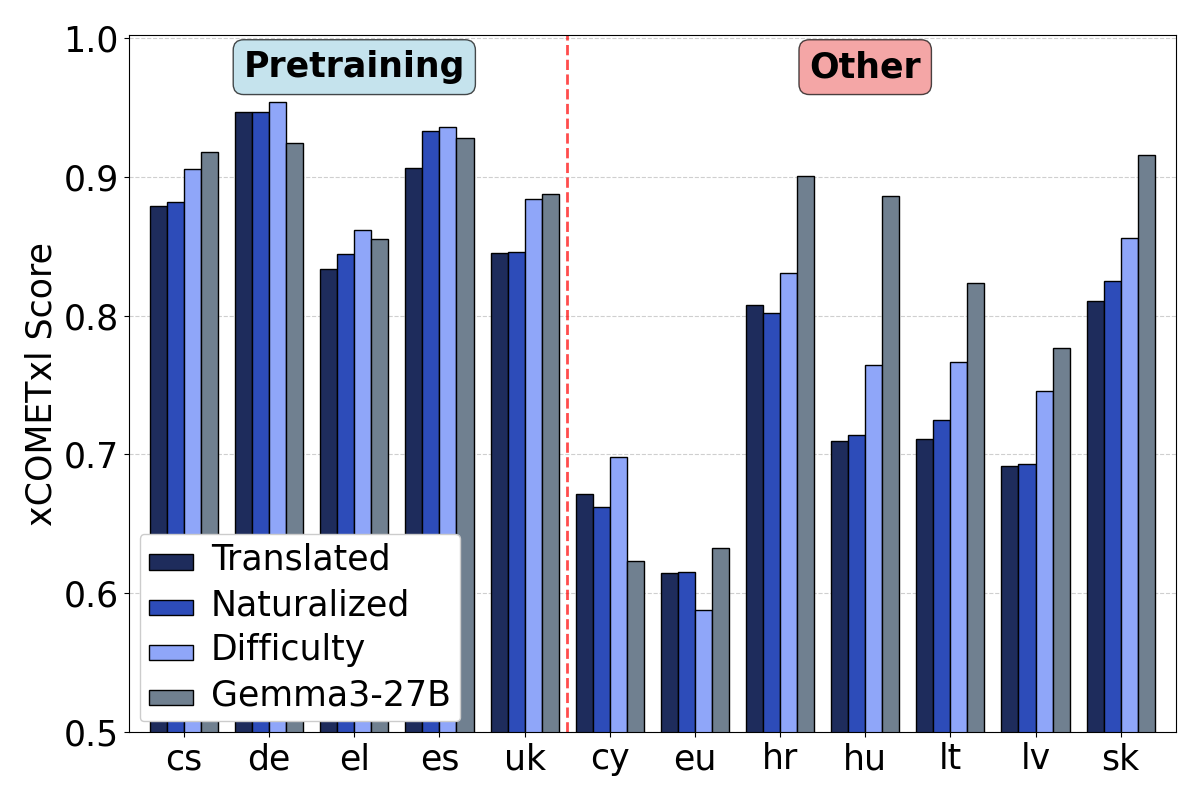
Figure 3: Translation performance on Flores by language (grouped by those supported in pretraining vs others), compared also against the teacher model.
Across all benchmarks, the models fine-tuned with optimized prompts consistently outperformed those relying solely on translated prompts. Notably, the Cultural+Difficulty Mix model displayed the most robust and balanced performance, with significant gains in tasks demanding higher cultural and contextual understanding.
Performance on multilingual benchmarks emphasized the improvements in less-resourced languages, further validating the approach's effectiveness in extending language coverage and quality.
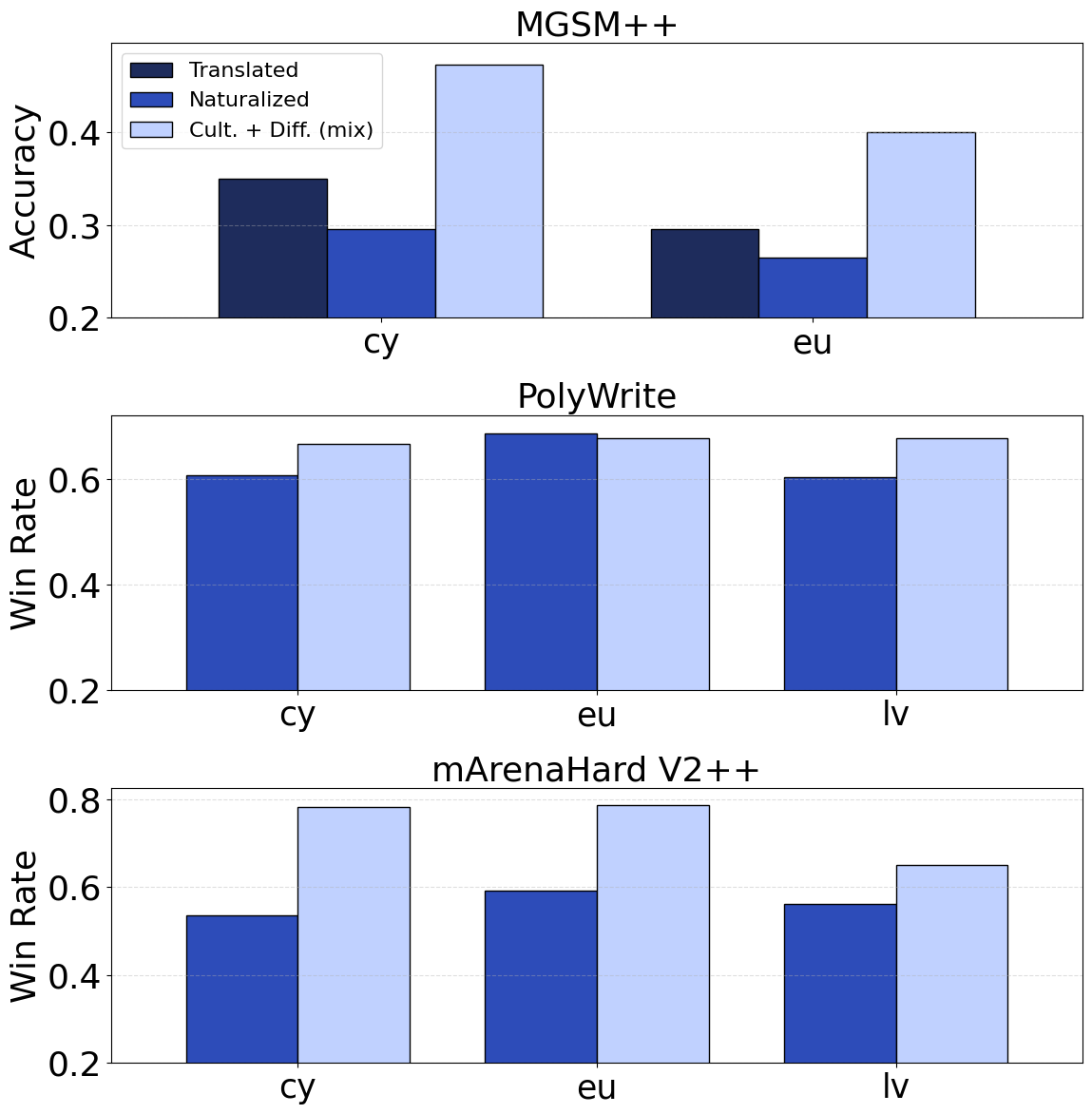
Figure 4: Performance on lowest-resource languages Welsh (cy), Basque (eu) and Latvian (lv) across three tasks. Win Rates are in comparison with the Translated baseline.
Conclusion
The paradigm shift presented in this paper, from generation to prompt optimization, demonstrates a significant advancement in multilingual LLM capabilities. By refining prompts to foster greater linguistic richness and cultural alignment, the proposed framework greatly enhances the quality and scope of synthetic data generation. Future research directions could include expanding the model's applicability to other underrepresented languages and further refining transformation algorithms to maximize customization for specific language contexts. This study sets the stage for more inclusive and culturally aware LLMs in the global context.