- The paper introduces SmartSwitch to dynamically detect premature thought-switches and intervene, mitigating underthinking in LLM reasoning.
- It employs a perception module with a process reward model and an intervention step to encourage deeper exploration of promising reasoning paths.
- Empirical results demonstrate significant accuracy and efficiency improvements on benchmarks like AIME25 and MATH-500, reducing token usage and thought-switch frequency.
SmartSwitch: A Plug-and-Play Framework for Mitigating Underthinking in LLM Reasoning
Introduction
The SmartSwitch framework addresses a critical limitation in Long Chain-of-Thought (LongCoT) reasoning for LLMs: the "underthinking" phenomenon, where models frequently switch thoughts without sufficiently exploring promising reasoning paths. This behavior leads to shallow reasoning, increased token usage, and reduced accuracy on complex tasks. The paper introduces SmartSwitch as a fine-tuning-free, model-agnostic inference strategy that dynamically detects premature thought-switches and intervenes to promote deeper exploration of high-potential but abandoned reasoning avenues.

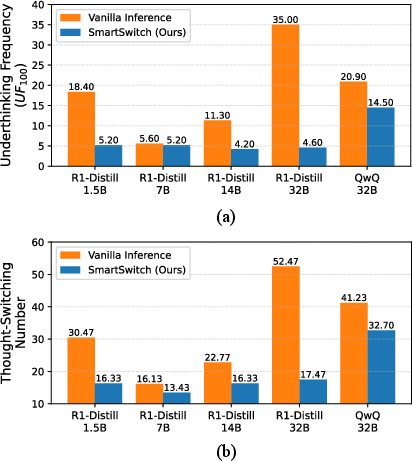
Figure 1: Qualitative and quantitative illustration of the underthinking problem, showing frequent, shallow thought switches in DeepSeek-R1 and widespread prevalence across LongCoT LLMs.
Characterization of Underthinking in LongCoT LLMs
Underthinking is defined as the premature abandonment of reasoning paths, often triggered by linguistic cues (e.g., "Alternatively, ...") that signal a shift in strategy. The paper introduces the Underthinking Frequency (UF) metric, which quantifies the number of short, underdeveloped thoughts in a model's reasoning trace. Empirical analysis reveals that underthinking is pervasive across state-of-the-art LongCoT models and is exacerbated by problem difficulty.
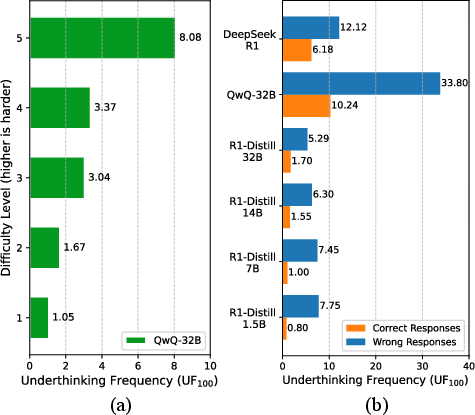
Figure 2: Underthinking frequency increases with problem difficulty on the MATH-500 dataset; incorrect answers are associated with higher underthinking rates.
SmartSwitch Framework: Algorithm and Implementation
SmartSwitch operates as an intervention loop during autoregressive generation, consisting of two modules:
- Perception Module: Continuously monitors the token stream for thought-switch cues, segments the preceding thought, and evaluates its potential using a Process Reward Model (PRM). If the PRM score exceeds a threshold (τscore), the thought is flagged as promising.
- Intervention Module: If a promising thought is detected, the generation is interrupted, the context is rolled back, and a "deepen prompt" is injected to encourage further exploration of the abandoned path. Generation then resumes from this modified context.
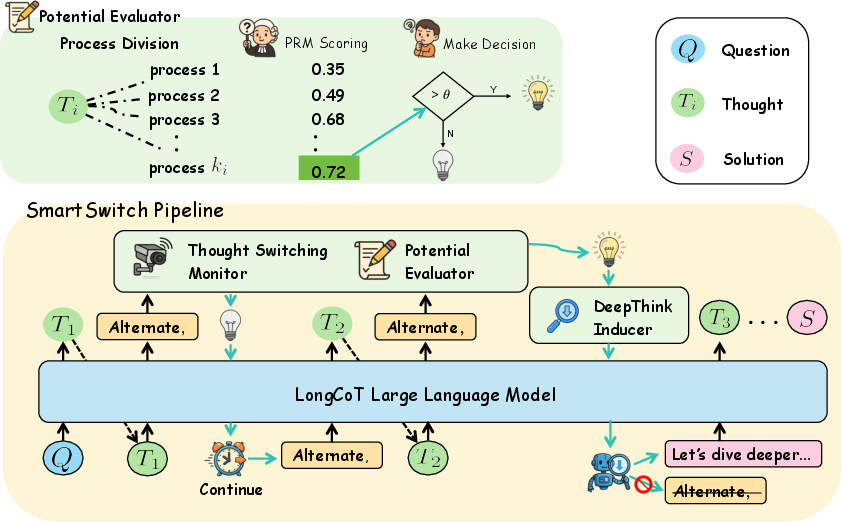
Figure 3: The SmartSwitch pipeline: perception detects thought switches and evaluates potential; intervention backtracks and injects a deepening prompt if warranted.

Figure 4: Pseudocode of the SmartSwitch inference algorithm, detailing the cyclical monitoring, evaluation, and intervention steps.
Key implementation details include:
- Use of Universal-PRM-7B for thought evaluation, supporting up to 32,768 tokens.
- Adaptive paragraph segmentation to ensure coherent and optimally sized thought units for PRM scoring.
- A cap on intervention count per problem to prevent excessive looping.
Empirical Results and Analysis
SmartSwitch demonstrates robust improvements across multiple LLMs and mathematical reasoning benchmarks (AIME24, AIME25, AMC23, MATH-500, GaoKao2023en). Notable findings include:
Qualitative case studies further illustrate SmartSwitch's impact:

Figure 6: Case study 1 (AIME25 geometry): SmartSwitch-augmented QwQ-32B solves the problem correctly with fewer tokens and more coherent reasoning.

Figure 7: Case study 2 (Math 500 parentheses): SmartSwitch enables systematic exploration, yielding correct answers with reduced token usage.

Figure 8: Case study 3 (Math 500 recurrence): SmartSwitch improves efficiency even when the base model is already correct.
Comparative and Ablation Studies
SmartSwitch outperforms alternative underthinking mitigation strategies:
- Standard Prompting: General instructions for deeper thinking yield negligible improvement.
- TIP (Thought Switching Penalty): Penalizing thought-switch tokens provides limited gains and can hinder necessary exploration.
Ablation studies highlight the importance of:
- PRM Selection: Universal-PRM-7B is critical for long-context evaluation and superior accuracy.
- Process Division Strategy: Adaptive paragraph segmentation (v4) yields the best results, balancing coherence and granularity.
- Score Mapping: Using the score of the last process within a thought as its final potential score is optimal.
- Threshold Tuning: Performance is sensitive to the PRM score threshold; optimal values must be empirically determined.
Limitations and Future Directions
The framework's efficacy is bounded by the quality of the external PRM and the precision of thought-switch detection. Hyperparameter sensitivity necessitates careful tuning for different domains and models. Future work should focus on:
- Integrating PRM capabilities into base LLMs for self-assessment.
- Developing dynamic, context-aware intervention prompts.
- Extending SmartSwitch to domains beyond mathematics, such as software engineering and scientific discovery.
Conclusion
SmartSwitch provides a principled, plug-and-play solution for mitigating underthinking in LongCoT LLMs. By dynamically detecting and intervening on prematurely abandoned reasoning paths, it enhances both the depth and reliability of model reasoning. The framework delivers substantial accuracy and efficiency gains across model scales and benchmarks, and its modular design facilitates broad applicability. SmartSwitch represents a significant step toward more deliberate and effective LLM reasoning, with implications for the development of robust, high-performance AI systems in complex domains.