MoE-GS: Mixture of Experts for Dynamic Gaussian Splatting
Abstract: Recent advances in dynamic scene reconstruction have significantly benefited from 3D Gaussian Splatting, yet existing methods show inconsistent performance across diverse scenes, indicating no single approach effectively handles all dynamic challenges. To overcome these limitations, we propose Mixture of Experts for Dynamic Gaussian Splatting (MoE-GS), a unified framework integrating multiple specialized experts via a novel Volume-aware Pixel Router. Our router adaptively blends expert outputs by projecting volumetric Gaussian-level weights into pixel space through differentiable weight splatting, ensuring spatially and temporally coherent results. Although MoE-GS improves rendering quality, the increased model capacity and reduced FPS are inherent to the MoE architecture. To mitigate this, we explore two complementary directions: (1) single-pass multi-expert rendering and gate-aware Gaussian pruning, which improve efficiency within the MoE framework, and (2) a distillation strategy that transfers MoE performance to individual experts, enabling lightweight deployment without architectural changes. To the best of our knowledge, MoE-GS is the first approach incorporating Mixture-of-Experts techniques into dynamic Gaussian splatting. Extensive experiments on the N3V and Technicolor datasets demonstrate that MoE-GS consistently outperforms state-of-the-art methods with improved efficiency. Video demonstrations are available at https://anonymous.4open.science/w/MoE-GS-68BA/.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces a new way to recreate moving 3D scenes (like videos where people, objects, or lights are moving) so they look realistic from any camera angle, and can be shown in real time. The method is called MoE-GS, short for Mixture of Experts for Dynamic Gaussian Splatting.
“Gaussian splatting” is a fast graphics technique that represents a scene using lots of small, soft blobs (like tiny paint splashes). These blobs are projected onto the screen to make an image. It’s faster than older methods, which makes it good for things like AR/VR, robotics, or future AI systems that need to see the world quickly and clearly.
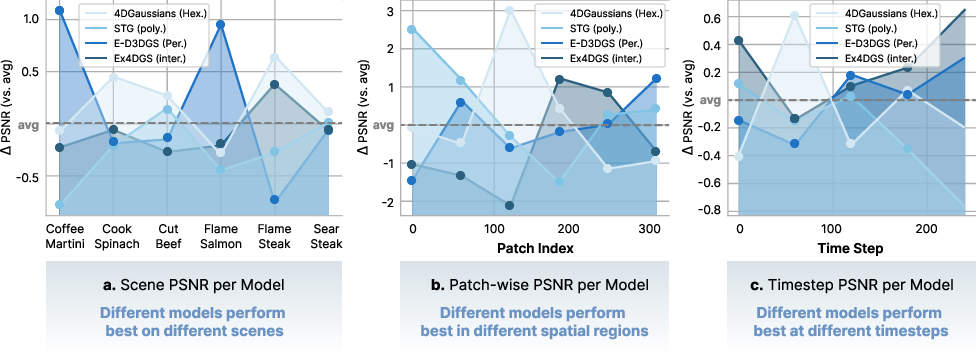
The problem: different existing methods work well on some scenes but fail on others. This paper’s idea is simple—use several specialized methods together and let a smart “router” decide how much each one contributes for every part of every frame. That way, the system adapts to whatever the scene needs.
What questions the paper tries to answer
To make dynamic 3D scenes look great and run fast, the paper asks:
- Can combining multiple specialized models (“experts”) give better results than relying on just one?
- How can we decide, for each pixel (small dot on the screen) and each moment in time, which expert should contribute more?
- Since combining experts can be slow, can we keep the quality high while making the system efficient?
- Can we train smaller, single models to imitate the combined system so they’re faster to run?
How the method works (in everyday terms)
Think of this like a sports team:
- Each “expert” is a specialist—some are better at smooth motions, others at sharp changes, some handle tricky textures or lighting.
- A “router” is like the coach who chooses, moment by moment, which players (experts) should handle each part of the scene.
Here are the main parts:
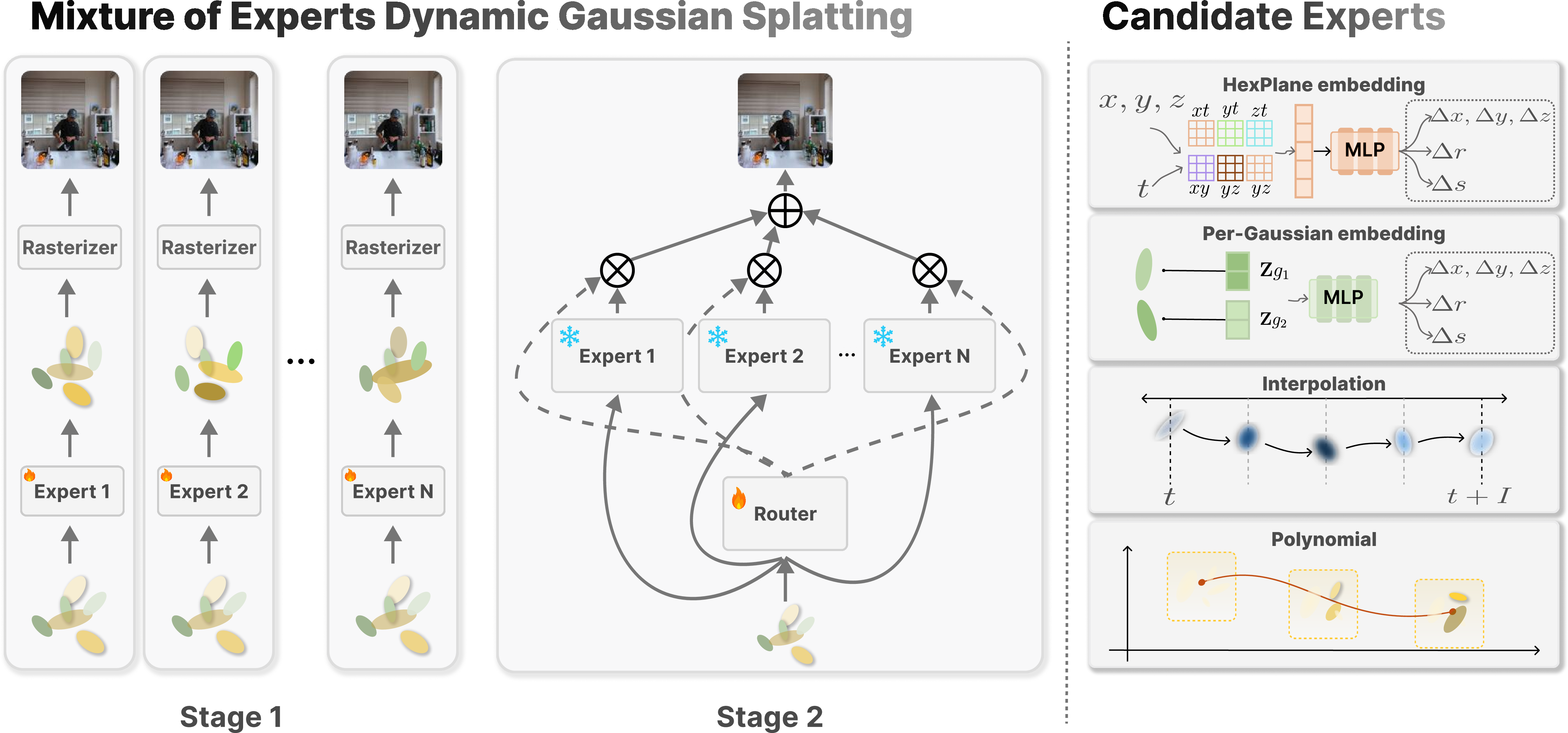
1) Mixture of Experts (MoE)
- Several different dynamic Gaussian splatting models (the experts) are trained separately.
- For each video frame and every pixel, the system blends the experts’ outputs, giving more weight to the ones that fit that spot best.
2) Volume-aware Pixel Router (the “coach”)
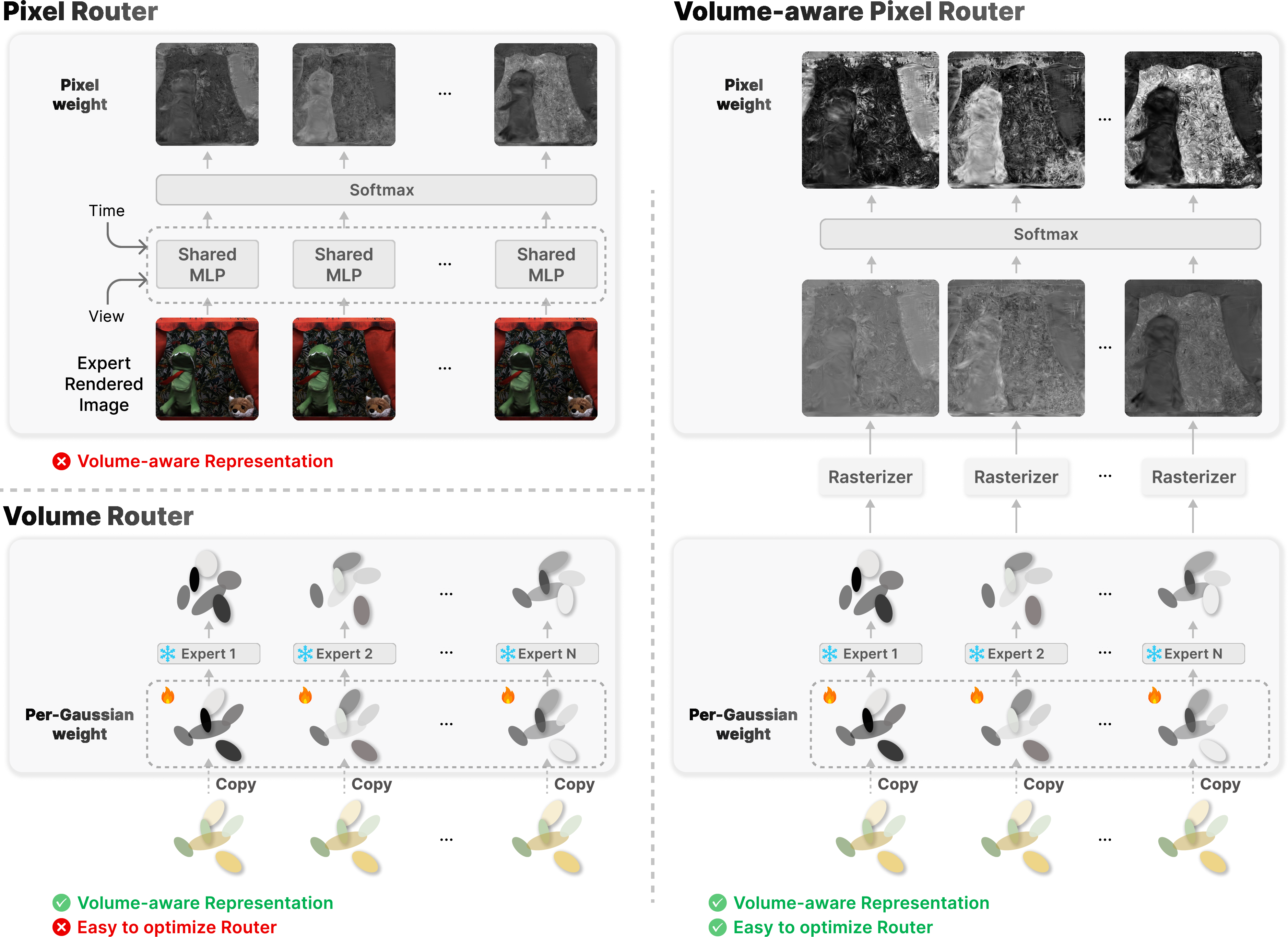
- Naive routers either:
- Look only at the final image pixels (simple but ignores 3D structure), or
- Work directly on the 3D blobs (smart but hard to optimize).
- The paper’s router does something in-between:
- It uses information from the 3D blobs (where they are, how big they are, how they’re oriented), but converts that into pixel-level decisions using “weight splatting” (think of spreading each blob’s “influence” down onto the pixels it covers).
- It takes into account time (which frame it is) and view direction (where the camera is looking).
- This makes the blending smooth across space and time, and easier to train.
Analogy: Imagine mixing paint colors. If you only look at the final canvas (pixels), you might guess how to blend, but you ignore the paint source and layers (3D blobs). If you only look at the paint in the bucket (3D), blending is tricky. This router “pours” the paint influence onto the canvas first, then decides how to mix, making decisions both informed and stable.
3) Making it efficient
Combining multiple experts usually means more work and slower frame rates. The paper introduces two fixes:
- Single-pass multi-expert rendering:
- Instead of rendering each expert separately (repeating the same steps), the system renders them together in one go and separates their contributions smartly. This saves time on the GPU.
- Gate-aware pruning:
- If some blobs barely affect the final image (the router’s weights say they don’t matter much), the system removes them.
- This reduces memory and speeds up rendering without hurting quality.
4) Distillation (teacher-student training)
- The full MoE system can be heavy. To make deployment lighter, they train each expert separately to mimic the MoE’s final output—like a student learning from a teacher.
- The router’s pixel weights act like “confidence scores,” telling the student where to trust ground-truth and where to learn from the MoE.
- This lets a single expert perform almost as well as the full mixture, but faster.
What they found and why it matters
Across two standard datasets (N3V and Technicolor), MoE-GS:
- Consistently outperforms individual expert methods and other state-of-the-art approaches in image quality (clearer details, better structure, fewer artifacts).
- Adapts to different scenes, different parts of the same scene, and different frames over time—exactly where single methods struggle.
- With single-pass rendering and pruning, runs faster and uses less memory.
- With distillation, smaller single models get near-MoE quality without changing their architecture, making them practical for real-time uses.
In simple terms: MoE-GS gives better-looking moving 3D scenes and can be made efficient enough to use in real-time systems.
Why this is important
- For AR/VR and mixed reality: Users want realistic, smooth visuals that respond instantly. This method helps.
- For robots and embodied AI: They need to understand dynamic environments quickly. Faster, clearer reconstructions help them navigate and interact.
- For future AI systems: Training models that “see” the world well requires good, efficient scene reconstruction.
Big picture: Instead of searching for a single “perfect” method, this work shows that combining experts and adapting in real time is smarter. It opens the door to flexible, scalable systems where new experts can be added as needed, and the router will learn how to use them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to guide concrete follow-up research.
- Scalability beyond small expert counts: Quantify accuracy–efficiency trade-offs and memory/FPS behavior for larger numbers of experts (e.g., N≥5–8), including whether single-pass rendering and gate-aware pruning still provide acceptable throughput and stability.
- Dense vs. sparse gating: Evaluate top-k (sparse) gating strategies to reduce computation and memory, and compare against current dense blending in terms of quality, efficiency, and training stability.
- Joint training feasibility: Investigate joint optimization of experts and router with specialization/regularization (e.g., load balancing, entropy penalties, diversity losses) to avoid early expert dominance and encourage complementary skills without compromising convergence.
- Router feature design: Ablate and expand the router’s inputs and encodings (e.g., Fourier/time embeddings, global context, attention mechanisms, multi-scale features) beyond the current linear time term and local “conv-MLP,” and quantify their impact on temporal/view dependence.
- Router calibration and specialization: Measure routing entropy, expert usage statistics, and specialization patterns (which dynamics/regions each expert handles); test for routing collapse and propose calibration (temperature scaling, confidence regularization) to ensure meaningful expert differentiation.
- Temporal consistency metrics: Add explicit evaluations of frame-to-frame consistency (e.g., temporal SSIM, warping error, flicker metrics) to corroborate claims of “spatially and temporally coherent” blending.
- Cross-view consistency of gating: Analyze whether router weights are consistent across viewpoints and whether inconsistencies cause multi-view artifacts; explore cross-view regularization or volumetric consistency constraints.
- Robustness to real-world capture artifacts: Test sensitivity to camera calibration errors, rolling shutter, motion blur, exposure/gain changes, and sensor noise; propose robust training or augmentation strategies.
- Handling dynamic lighting and non-Lambertian effects: Quantify performance under strong view-dependent appearance (specularities, shadows) and rapidly changing illumination; assess whether current per-Gaussian direction/time weights suffice or require richer reflectance modeling.
- Training cost and scalability: Report comprehensive training compute/time (for Stage 1 experts and Stage 2 router) and energy usage; explore strategies to reduce training overhead (e.g., early stopping with routing-informed curricula, shared pretraining of common components).
- Dataset coverage and generalization: Evaluate on broader dynamic phenomena (humans, articulated motion, fluids, topology changes, fast/high-frequency motion, longer sequences) to establish generalization; include failure case analysis.
- Deployment strategy after distillation: Clarify how a single distilled expert is selected for deployment per scene/frame (static choice vs. runtime selection), and evaluate performance versus full MoE under realistic deployment constraints.
- Distillation design and sensitivity: Ablate distillation hyperparameters (e.g., λ), routing-based confidence usage, teacher temperature, and soft-target strategies; study teacher miscalibration impacts and error propagation to students.
- Gate-aware pruning robustness: Analyze sensitivity to pruning threshold τ and scheduling; quantify effects on artifacts, temporal consistency, and expert fairness (e.g., are specialized experts disproportionately pruned?); specify whether and how the router is retrained after pruning.
- Single-pass rendering compatibility: Validate single-pass merging across experts with differing parameterizations/shading behaviors (e.g., interpolation-based vs. polynomial motion) and report edge cases where one-hot expert identities or shared rasterization break assumptions.
- Memory overhead of router weights: Quantify the memory increase from duplicating Gaussians for per-Gaussian routing and propose compression/sharing schemes (e.g., low-rank weight fields, per-cluster weights).
- Optimization properties of weight splatting: Provide theoretical/empirical analysis of gradient behavior, identifiability, and stability for differentiable weight splatting; characterize when volumetric-to-pixel projection aids or hinders optimization relative to pure pixel/volume routing.
- Evaluation breadth of efficiency claims: Extend FPS/memory evaluations across different GPUs, resolutions, and expert combinations; include end-to-end latency and throughput on resource-constrained devices (laptops, mobile/AR headsets).
- Physical plausibility and artifact analysis: Assess whether 2D image-level blending of experts introduces ghosting/seams or violates volumetric occlusion; test occlusion-aware gating or volumetric blending variants to mitigate artifacts.
- Automatic expert discovery: Explore learning specialized experts end-to-end (rather than hand-picking existing models), including methods to induce complementary specializations and mechanisms for adding/removing experts online.
- Online/streaming adaptation: Investigate router/expert adaptation to distribution shift in streaming scenarios (e.g., new motions or lighting), including incremental expert addition and continual learning without catastrophic forgetting.
- Cross-dataset reproducibility and fairness: Standardize training budgets, dataset splits, and hyperparameters across experts to ensure fair comparisons; report variance and confidence intervals, and include statistically rigorous benchmarking.
- Integration with non-Gaussian representations: Test extensibility claims by integrating non-Gaussian dynamic representations (e.g., neural volumes or mesh-based dynamics) and quantify how routing and single-pass rendering generalize.
Practical Applications
Immediate Applications
Below are applications that can be deployed now using the MoE-GS framework and its efficiency strategies (single-pass multi-expert rendering, gate-aware Gaussian pruning) and/or the distillation pipeline to lightweight experts.
- Media/Entertainment (AR/VR/MR production): Upgrade dynamic volumetric capture pipelines to produce higher-fidelity reconstructions across diverse scenes by combining specialized Gaussian-splatting experts via the Volume-aware Pixel Router; integrate gate-aware pruning to keep FPS near real-time during review and iteration.
- Tools/products/workflows: A DCC/engine plugin (e.g., Unreal/Unity) that wraps MoE-GS training (two-stage) and inference, with toggles for single-pass multi-expert rendering and pruning; batch “MoE-then-distill” workflow to deliver final lightweight assets to the game engine.
- Assumptions/dependencies: Multi-view calibrated footage (e.g., COLMAP initialization), high-memory GPUs (e.g., RTX 4090/A6000), scene coverage sufficient to avoid large occlusion gaps; licensing/compatibility with baseline expert implementations.
- Volumetric Telepresence (software/communications): Server-side MoE-GS for high-quality dynamic reconstruction of people and scenes; client-side playback uses distilled single-expert models for efficient rendering on consumer devices.
- Tools/products/workflows: Cloud service for live capture and MoE routing; on-device distilled model deployment; a “router-guided” streaming format that includes per-pixel confidence for adaptive client rendering.
- Assumptions/dependencies: Stable uplink bandwidth for multi-view video; compute on the server; privacy and consent workflows for multi-camera capture.
- Broadcast Sports & Live Events (media/analytics): Real-time or near-real-time novel-view replays where the router adaptively selects the best expert per region/frame to handle fast motion, fine textures, and lighting variation; prune low-impact Gaussians to maintain throughput.
- Tools/products/workflows: Replay generation pipeline with single-pass multi-expert rasterization kernels; dashboard visualizing router weights (per-pixel) for operator QA.
- Assumptions/dependencies: Multi-camera arrays with synchronization and calibration; event-scale compute provisioning; latency constraints for broadcast.
- Robotics Labs (robotics/software): Use MoE-GS to build dynamic 3D reconstructions of workspaces from multi-view camera rigs, improving perception for manipulation under deformable or moving objects; distill to single experts for on-robot deployment.
- Tools/products/workflows: ROS-integrated reconstruction node; “MoE-then-distill” training procedure; pruning presets tuned to the number of experts (N=2–3).
- Assumptions/dependencies: Fixed camera infrastructure or head-mounted rigs; GPU acceleration; task-specific validation (e.g., motion speed, lighting).
- Digital Twins in Manufacturing (industrial/energy): Enhance dynamic process visualization (e.g., assembly lines, material handling) with MoE-GS for operator training and anomaly review; prune for efficient playback on factory dashboards.
- Tools/products/workflows: Twin-building pipeline where MoE-GS runs offline for fidelity, then distillation delivers lightweight runtime assets; router-weight heatmaps for diagnostics.
- Assumptions/dependencies: Synchronized multi-view capture of the process; change-management and safety policies for camera placement.
- E-commerce & Marketing (media/software): Produce dynamic product demos (e.g., textiles, liquids, mechanisms) with consistent quality across varied motion types by fusing multiple experts; distill for web deployment.
- Tools/products/workflows: Content studio integration; export to WebGL/WebXR using distilled assets; GPU-accelerated batch rendering for campaign generation.
- Assumptions/dependencies: Controlled studio capture; browser-side performance constraints; IP rights for trained models.
- Education & Research (academia/software): A reproducible benchmark harness where the Volume-aware Pixel Router provides per-pixel gating weights to study expert specialization; students can plug in new experts without changing the framework.
- Tools/products/workflows: Open-source MoE-GS training scripts; visualization of spatial/temporal gating; dataset adapters (N3V, Technicolor, HyperNeRF-like).
- Assumptions/dependencies: Access to datasets with appropriate licenses; moderate GPUs; familiarity with Gaussian splatting libraries.
- Post-production VFX (media): Offline use of MoE-GS to resolve difficult regions (reflections, thin structures, nonrigid motion) by leveraging complementary experts; prune and/or distill for final delivery.
- Tools/products/workflows: A MoE “fidelity pass” before final render; shot-based router training with per-Gaussian weight splatting; automated pruning thresholds by gradient-based importance.
- Assumptions/dependencies: Time budget for two-stage training; pipeline hooks for per-shot calibration; artist review of router outputs.
- Tooling for 3DGS Ecosystem (software): Drop-in GPU kernels for single-pass multi-expert rendering and gate-aware pruning to reduce overhead in multi-expert setups across different 3DGS codebases.
- Tools/products/workflows: CUDA kernels and APIs for expert identity masking and blended alpha; pruning utilities driven by gradient norms; CI tests against known scenes.
- Assumptions/dependencies: Alignment with existing 3DGS data structures; maintainers willing to integrate; hardware capability for shared memory optimizations.
- Data Annotation & Method Selection (academia/software): Use router’s pixel-level weights as “expert attribution” labels to auto-annotate which method suits which regions and motions; build datasets for training future dynamic recon models.
- Tools/products/workflows: Export gating maps alongside rendered frames; analysis scripts for region-type vs. expert usage; curriculum learning that leverages attribution.
- Assumptions/dependencies: Robust gating stability; careful handling of pseudo-labels to avoid confirmation bias.
Long-Term Applications
These applications require further research, scaling, integration, or standardization before broad deployment.
- Edge/Mobile AR (hardware/software): On-device dynamic scene reconstruction on AR glasses or smartphones via heavily distilled experts; router logic partially or fully offloaded to the edge.
- Tools/products/workflows: Hardware-aware distillation; mixed client-edge routing; compression codecs for splatted Gaussians plus gating metadata.
- Assumptions/dependencies: Efficient mobile GPU/NPUs; power/thermal budgets; standards for on-device volumetric rendering.
- Autonomous Systems & Drones (robotics/transport): Real-time dynamic world modeling to aid planning in complex environments; MoE blending helps handle diverse motion and appearance changes; integration with SLAM and tracking.
- Tools/products/workflows: SLAM-plus-MoE fusion; uncertainty-aware routing; edge inference with adaptive pruning.
- Assumptions/dependencies: Robustness to outdoor scale, variable weather/lighting; safety certification for perception modules; multi-sensor fusion.
- Healthcare & Surgical AR (healthcare): High-fidelity dynamic reconstructions of soft tissue and instruments for intraoperative guidance; MoE handles nonrigid deformation better than single models.
- Tools/products/workflows: Validated clinical pipeline; sterile capture rigs; audit logs of routing and distillation; integration with surgical navigation systems.
- Assumptions/dependencies: Regulatory approval (FDA/CE), rigorous validation against ground truth, privacy/security compliance for medical video.
- Smart Cities & Traffic Analytics (public sector/transport): City-scale dynamic recon from distributed cameras to analyze flow and safety; MoE-GS improves fidelity of complex motion and occlusions across time.
- Tools/products/workflows: Federated training; privacy-preserving routing; standardized volumetric storage and streaming.
- Assumptions/dependencies: Policy frameworks for surveillance, consent, data retention; scalable infrastructure; robust calibration over large camera networks.
- Consumer “Volumetric Memories” (daily life/software): Simple multi-camera kits or smartphone multi-view capture to create dynamic 3D memories of events; MoE used offline, distilled models for sharing/streaming.
- Tools/products/workflows: Guided capture apps; cloud MoE processing; social platforms supporting dynamic volumetric playback (WebXR).
- Assumptions/dependencies: Affordable multi-view capture; easy calibration; compression and streaming that fit home bandwidth.
- Standards & Codecs for Dynamic Gaussian Splatting (policy/software): Develop interoperable formats that include Gaussian parameters, temporally varying attributes, and router/gating metadata to enable cross-tool compatibility and streaming.
- Tools/products/workflows: Working groups for file format specs; reference decoders; SDKs for browsers and engines.
- Assumptions/dependencies: Industry adoption; alignment across research and commercial vendors; IPR considerations.
- AGI/Simulation Data Generation (academia/AI): Use MoE-GS to build large-scale, high-variance dynamic 3D datasets for training embodied AI; router-guided specialization provides curriculum signals.
- Tools/products/workflows: Automated capture-to-MoE pipelines; attribution-aware sampling; synthetic and real data blending with domain randomization.
- Assumptions/dependencies: Compute scale; dataset governance and licensing; responsible AI guidelines for synthetic humans/events.
- WebXR & Browser-Level Rendering (software): Native support in browsers for dynamic Gaussian splatting with MoE-aware streaming; client-side routers or precomputed gating to optimize playback.
- Tools/products/workflows: WebGPU implementations; streaming protocols for volumetric assets plus gating; progressive refinement with pruning thresholds.
- Assumptions/dependencies: Web standards maturation; performance across heterogeneous devices; security/privacy for camera-derived content.
- Industrial Inspection & Predictive Maintenance (industrial/energy): Continuous dynamic recon of machinery for wear detection and anomaly diagnosis; MoE adapts to different motion regimes (e.g., belts, fluids, rotations).
- Tools/products/workflows: Continuous capture infrastructure; alerting based on router confidence shifts; integration with CMMS dashboards.
- Assumptions/dependencies: Environmental robustness (heat, dust); long-term calibration drift handling; safety policies for camera placement.
- Governance & Policy Frameworks (policy): Privacy, consent, and deepfake safeguards tailored to high-fidelity dynamic recon; energy and compute budgeting for large deployments; fairness in dataset curation used for training.
- Tools/products/workflows: Standards for multi-view capture in public/private spaces; audit trails for gating and distillation; risk assessments for misuse.
- Assumptions/dependencies: Cross-sector collaboration; evolving legal norms; transparent documentation of capture and processing practices.
Glossary
- 3D Gaussian Splatting: An explicit, point-based scene representation that renders images by splatting 3D anisotropic Gaussians for efficient, real-time novel view synthesis. "have significantly benefited from 3D Gaussian Splatting"
- alpha blending: A compositing technique that accumulates color along a ray using per-splat opacities and transmittance. "during alpha blending."
- canonical deformation fields: Deformation functions defined in a shared canonical space that map to observed frames to model dynamics. "without relying on canonical deformation fields."
- canonical space: A reference coordinate frame to which dynamic observations are mapped for consistent modeling. "map points from a canonical space to observed frames."
- COLMAP: A Structure-from-Motion and multi-view stereo pipeline used to generate point clouds for initialization. "point clouds generated by COLMAP."
- conditional computation: Executing only a subset of model components per input to scale capacity efficiently. "enabling conditional computation to scale model capacity without excessive computational cost."
- deformation fields: Learned mappings that deform 3D coordinates over time to represent motion. "learning deformation fields that map points from a canonical space to observed frames."
- differentiable weight splatting: Projecting learned per-Gaussian weights into pixel space using differentiable rasterization operations. "through differentiable weight splatting"
- Dynamic Novel View Synthesis: Reconstructing unseen views of time-varying scenes from sparse observations. "Dynamic Novel View Synthesis aims to reconstruct novel views from sparse observations of temporally varying scenes"
- gate-aware Gaussian pruning: Removing Gaussians based on their influence on gating outputs to improve efficiency. "gate-aware Gaussian pruning"
- gating weights: Per-expert probabilities produced by a router that control expert contributions. "The gating weights are typically computed by a Router"
- HexPlane: A grid-like feature parameterization used for spatio-temporal embeddings in deformation estimation. "HexPlane-style features"
- interpolation-based models: Approaches that model dynamics by interpolating parameters between selected anchor frames. "interpolation-based models such as Ex4DGS~\citep{lee2024fully} reconstruct dynamics by interpolating between keyframes."
- keyframes: Selected frames used as anchors for temporal interpolation. "interpolating between keyframes."
- knowledge distillation: Training a model using supervision from a stronger teacher model’s outputs to transfer performance. "we introduce a knowledge distillation pipeline"
- LPIPS: A learned perceptual similarity metric for evaluating image quality. "PSNR, SSIM, LPIPS"
- Mixture-of-Experts (MoE): An architecture with multiple specialized experts and a gating mechanism that selects or blends experts per input. "Mixture-of-Experts techniques"
- Neural Radiance Fields (NeRF): An implicit volumetric rendering approach modeling scene appearance and geometry for novel view synthesis. "Neural Radiance Fields (NeRF)"
- opacity: The per-splat alpha value that controls a Gaussian’s contribution to the pixel color. "opacity "
- per-Gaussian embeddings: Learnable feature vectors attached to each Gaussian to encode dynamics and appearance. "per-Gaussian embeddings"
- per-Gaussian weights: Learnable scalar/vector weights attached to each Gaussian that are splatted to pixels for routing. "learnable per-Gaussian weights"
- PSNR: Peak Signal-to-Noise Ratio, a fidelity metric measuring reconstruction error. "outperforms both in PSNR"
- pseudo-labels: Labels produced by a teacher/MoE model used to supervise student training. "pseudo-labels generated by the optimized MoE model"
- RAdam optimizer: The Rectified Adam optimization algorithm that stabilizes adaptive learning rates. "Per-Gaussian weights are optimized with the RAdam optimizer"
- rasterization: The process of projecting 3D primitives to pixels for image formation. "rasterization-based weight splatting"
- ray-tracing: Rendering by tracing rays through a scene, typically computationally expensive. "intensive ray-tracing introduce substantial computational overhead"
- Router (MoE): The module that computes gating weights to select or blend experts. "and a Router"
- single-pass multi-expert rendering: Rendering all experts in one shared pass to avoid redundant projection and visibility work. "single-pass multi-expert rendering"
- softmax: A normalization function converting logits into a probability distribution for gating. "computed via softmax"
- SSIM: Structural Similarity Index, a metric assessing perceptual image similarity. "PSNR, SSIM, LPIPS"
- Structure-from-Motion (SfM): A technique to recover 3D structure and camera poses from images. "Structure-from-Motion (SfM)"
- transmittance: The accumulated transparency along a ray before a given point, used in volume compositing. "is the transmittance"
- visibility computation: Determining which Gaussians contribute to each pixel considering depth ordering. "repeated projection and visibility computation"
- volumetric Gaussian-level weights: Per-Gaussian weights defined in 3D that capture volumetric attributes for routing. "projecting volumetric Gaussian-level weights into pixel space"
- Volume-aware Pixel Router: A router that splats per-Gaussian weights to pixels and blends experts with spatial-temporal coherence. "Volume-aware Pixel Router"
- weight splatting: Splatting per-primitive weights into image space via rasterization to form pixel-wise signals. "weight splatting"
Collections
Sign up for free to add this paper to one or more collections.

