- The paper introduces a unified two-stage Gaussian optimization framework for reconstructing renderable 4D HDR scenes from unposed, alternating-exposure monocular videos.
- It leverages vision foundation model priors for initializing depth, motion, and dynamic masks, ensuring robust camera pose refinement and temporally consistent HDR reconstruction.
- Quantitative benchmarks demonstrate superior performance in rendering quality and speed, with notable improvements in PSNR, SSIM, LPIPS, and HDR-TAE over prior methods.
High Dynamic Range 4D Gaussian Splatting from Alternating-Exposure Monocular Videos
Introduction and Motivation
Mono4DGS-HDR introduces a unified framework for reconstructing renderable 4D HDR scenes from unposed monocular LDR videos with alternating exposures. The method addresses the practical scenario where dynamic HDR scenes are captured using a single handheld camera, without access to camera poses or multi-camera setups. Previous HDR NVS approaches have been limited to static scenes or required known camera parameters, and existing dynamic scene methods are not robust to alternating-exposure inputs. Mono4DGS-HDR is the first to tackle this challenging task, leveraging a two-stage optimization based on Gaussian Splatting and integrating vision foundation model priors for initialization and regularization.

Figure 1: Mono4DGS-HDR reconstructs high-quality 4D HDR scenes from unposed monocular LDR videos with alternating exposures, outperforming direct extensions of prior methods.
Methodology
Vision Foundation Model Priors
The framework begins by extracting 2D priors from vision foundation models, including video depth estimation, sparse long-term 2D pixel trajectories, and dynamic masks derived from epipolar error maps. These priors are computed using off-the-shelf models (DepthCrafter, SpatialTracker, RAFT) and are effective even with alternating-exposure inputs, though they remain noisy and incomplete. Bundle adjustment is performed using static tracklets to obtain initial camera parameters.
Two-Stage Gaussian Optimization
Mono4DGS-HDR employs a two-stage optimization strategy:
- Video HDR Gaussian Training: Dynamic HDR Gaussians are learned in an orthographic camera coordinate space, eliminating the need for camera poses. This stage enables robust initial HDR video reconstruction and provides consistent brightness across frames, facilitating reliable camera pose optimization via photometric reprojection error.
- Video-to-World Gaussian Transformation and World Gaussian Fine-Tuning: The learned video Gaussians are transformed into world space using initial camera parameters. The transformation includes dynamic/static identification with occlusion handling, attribute transformation (position, rotation, scaling), and re-fitting of Gaussian scaling based on 2D covariance invariance. World Gaussians are then jointly optimized with camera poses, leveraging HDR photometric reprojection loss for dense supervision.
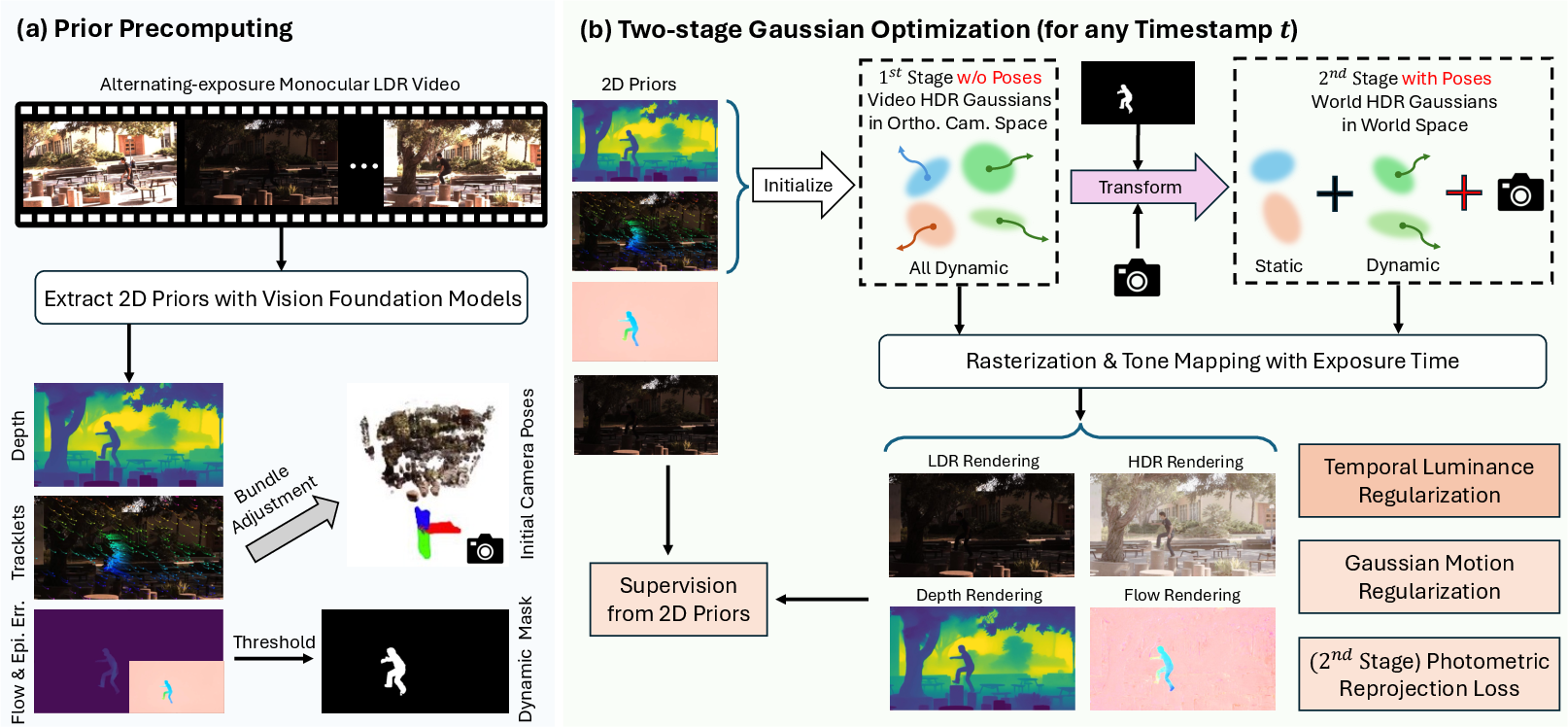
Figure 2: Overview of Mono4DGS-HDR, showing 2D prior extraction, two-stage Gaussian optimization, and transformation from video to world Gaussians.
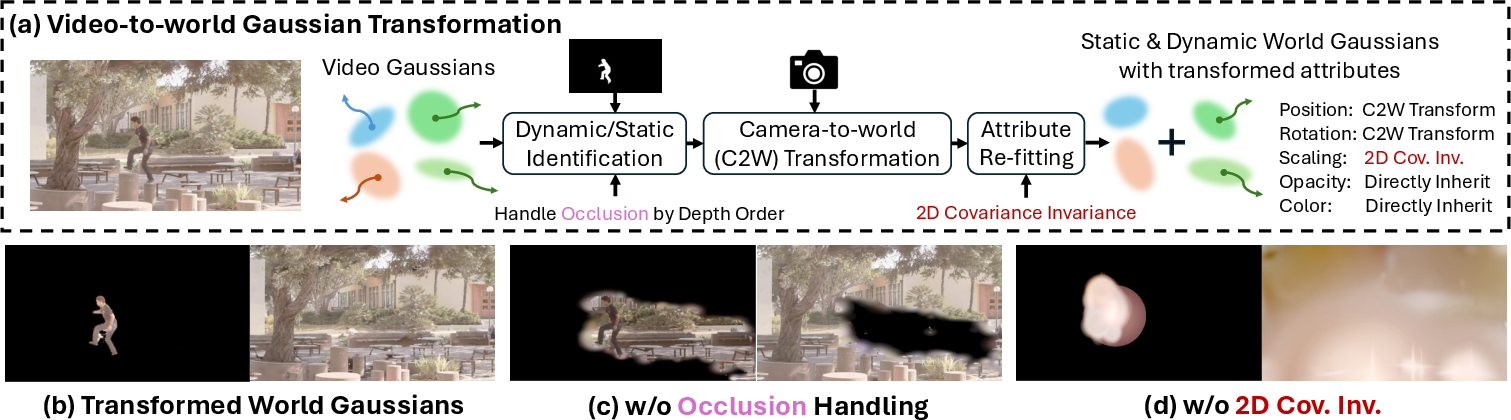
Figure 3: Video-to-world Gaussian transformation strategy, including dynamic/static identification, attribute transformation, and scaling re-fitting.
Temporal Luminance Regularization
To ensure temporal consistency of HDR appearance, a temporal luminance regularization (TLR) strategy is introduced. TLR uses flow-guided photometric loss to align per-pixel HDR irradiance between consecutive frames, propagating well-supervised dynamic content to poorly-supervised times and stabilizing appearance variations.
Loss Functions and Optimization
The overall objective combines LDR RGB loss, depth loss, flow/track loss, unit exposure loss, Gaussian motion regularization (as-rigid-as-possible, velocity, acceleration), temporal luminance regularization, and HDR photometric reprojection loss. Gaussian densification is performed in both stages, with dynamic Gaussian pruning in the second stage.
Experimental Results
Benchmark and Evaluation
A new benchmark is constructed from publicly available datasets, comprising synthetic and real-world dynamic scenes with alternating-exposure LDR videos. Evaluation metrics include PSNR, SSIM, LPIPS, and HDR-TAE for temporal stability.
Mono4DGS-HDR demonstrates superior performance over adapted baselines (GaussHDR, HDR-HexPlane, MoSca, SplineGS, GFlow) in both rendering quality and speed. Notably, it achieves higher PSNR, SSIM, lower LPIPS, and lower HDR-TAE across all tracks. GaussHDR and HDR-HexPlane are limited by their inability to handle dynamic scenes and monocular videos, while GFlow and SplineGS fail to recover HDR scenes due to their reliance on per-frame optimization and photometric reprojection loss, respectively.

Figure 4: HDR visual comparisons on train/test frames, showing superior quality of Mono4DGS-HDR.
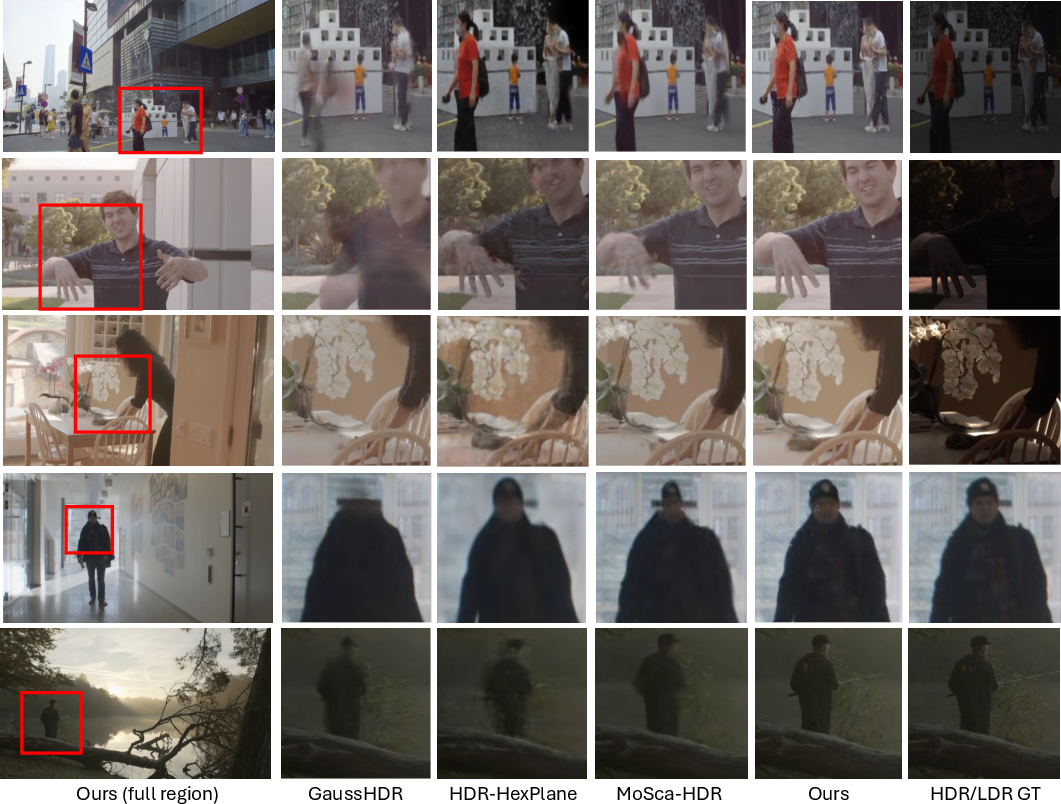
Figure 5: Additional HDR visual comparisons on train/test frames, further demonstrating quality improvements.

Figure 6: HDR visual comparisons under fix-view-change-time setting.

Figure 7: HDR visual comparisons under fix-time-change-view setting.
Ablation Studies
Ablation experiments validate the effectiveness of key components:
Implementation Details
The system is implemented in PyTorch, optimized with Adam, and trained on a single RTX 3090 GPU. The pipeline integrates codebases from 3DGS, MoSca, SaV, GaussHDR, SpatialTracker, DepthCrafter, and RAFT. Gaussian attributes are initialized from 2D priors, and dynamic Gaussian trajectories are modeled using cubic Hermite splines. Tone-mapping is performed via MLPs, and loss weights are empirically tuned for stability and convergence.
Limitations and Future Directions
Mono4DGS-HDR relies on the quality of 2D priors; inaccuracies in depth, flow, or track estimation can lead to suboptimal geometry and motion reconstruction. Dynamic mask extraction from optical flow may imperfectly separate static and dynamic content. The method does not address image blur from fast motion, though recent works (Deblur4DGS, Casual3DHDR) suggest possible extensions for simultaneous deblurring and HDR reconstruction.
Implications and Prospects
Mono4DGS-HDR advances the state-of-the-art in monocular 4D HDR scene reconstruction, enabling novel-view rendering and temporally consistent HDR video synthesis from casually captured, unposed LDR videos. The two-stage optimization and integration of vision foundation model priors provide a robust framework for dynamic scene understanding under challenging exposure conditions. Future work may focus on improving prior extraction, handling motion blur, and extending the approach to more complex exposure patterns and real-time applications.
Conclusion
Mono4DGS-HDR establishes a new paradigm for HDR dynamic scene reconstruction from unposed monocular videos with alternating exposures. Its unified two-stage Gaussian optimization, video-to-world transformation, and temporal regularization yield state-of-the-art results in both quality and speed, with strong implications for practical HDR video synthesis and dynamic scene modeling.

