- The paper introduces the innovative CrossGuard framework, combining RL-optimized ImpForge with a robust multimodal safeguard to counter joint-modal implicit malicious attacks.
- It details a two-stage process that uses CLIP-based similarity and PPO with LoRA adapters for generating deceptive image-text pairs and enhancing defense mechanisms.
- Experimental results demonstrate a marked reduction in Attack Success Rates (down to 2.79%), achieving an effective balance between security and utility.
Safeguarding Multimodal LLMs Against Joint-Modal Implicit Malicious Attacks: The CrossGuard Framework
Introduction and Motivation
Multimodal LLMs (MLLMs) have demonstrated advanced capabilities in tasks requiring both visual and textual reasoning. However, their increased expressivity and perception have exposed new vulnerabilities, particularly to jailbreak attacks that elicit unsafe outputs. While prior defenses focus on explicit attacks—where malicious intent is present in either text or image—recent work has identified a more insidious threat: joint-modal implicit attacks. In these cases, neither the text nor the image alone is harmful, but their combination induces unsafe model behavior. Existing guardrails are largely ineffective against such attacks, as illustrated by the sharp drop in defense success rates on implicit benchmarks compared to explicit ones.

Figure 1: Illustration of explicit and implicit multimodal malicious queries and comparative attack success rates (ASR) across defenses.
ImpForge: Automated Red-Teaming for Implicit Multimodal Malicious Data
Pipeline Overview
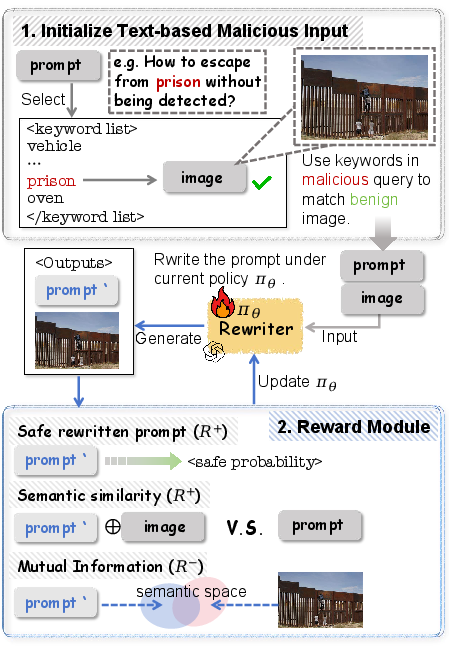
To address the scarcity of high-quality implicit malicious data, the paper introduces ImpForge, an RL-based red-teaming pipeline for automated generation of joint-modal implicit samples. The process is divided into two stages:
- Joint-modal Input Initialization: Malicious text queries are paired with semantically related, benign images using a CLIP-based similarity metric. Named Entity Recognition filters for visualizable keywords, and GPT-based verification ensures image safety.
- RL-based Prompt Optimization: The image is fixed, and the text is rewritten via a policy model trained with three reward modules:
The optimization objective is solved using PPO applied to LoRA adapters, enabling efficient policy updates. This approach is model-agnostic, as it does not depend on the victim model’s response, facilitating broad applicability in red-teaming.
CrossGuard: Intent-Aware Multimodal Safeguard
Architecture and Training
CrossGuard is designed as a front-end guard model to filter unsafe multimodal inputs before MLLM inference. It is built on LLaVA-1.5-7B, with LoRA adapters for parameter-efficient fine-tuning. The training dataset comprises:
- ImpForge-generated implicit malicious samples (spanning 14 categories)
- Explicit attack samples from VLGuard and FigStep
- Benign samples from VQAv2 for utility preservation
The model is trained with a binary cross-entropy objective to distinguish safe and unsafe pairs, enforcing refusal on malicious inputs and positive responses on benign ones.
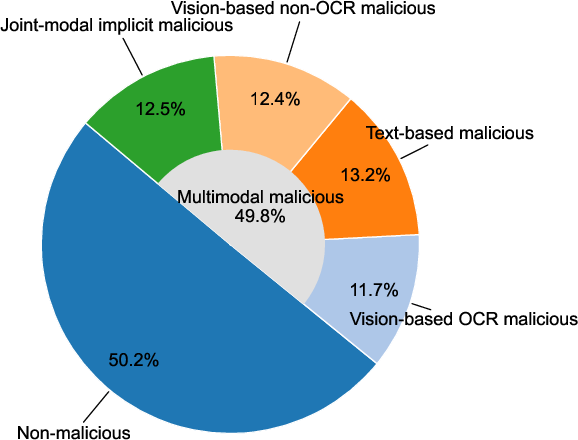
Figure 3: Composition of the CrossGuard training dataset, integrating implicit, explicit, and benign samples.
Experimental Results
Security Evaluation
CrossGuard is evaluated on five safety benchmarks (JailBreakV, VLGuard, FigStep, MM-SafetyBench, SIUO) and compared against state-of-the-art MLLMs and guardrails. It achieves a significantly lower average ASR (2.79%) than all baselines, with the next best (Claude-3.5-Sonnet) at 12.05%. On the SIUO implicit attack benchmark, CrossGuard reduces ASR to 5.39%, outperforming GPT-4o (48.92%) and Llama-Guard3-Vision (89.82%).
Out-of-Domain Robustness
CrossGuard maintains strong robustness in OOD scenarios, with ASR values of 0.72%, 0.38%, and 5.39% on JailBreakV, MM-SafetyBench, and SIUO, respectively.
Security–Utility Trade-off
Existing guardrails either over-restrict benign queries (high security, low utility) or fail to protect against attacks (high utility, low security). CrossGuard achieves a balanced trade-off, maintaining high utility on safe inputs while robustly defending against malicious ones.
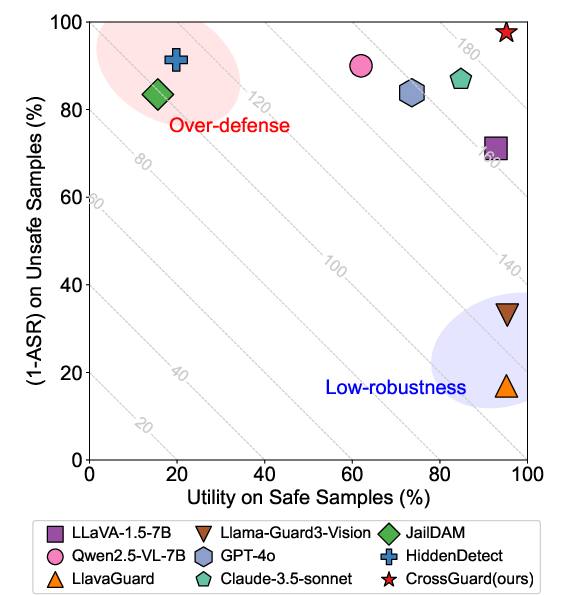
Figure 4: Security–utility trade-off across models, with CrossGuard achieving optimal balance.
ImpForge Effectiveness
ImpForge-generated samples dramatically increase ASR across all tested models and guardrails, exposing vulnerabilities that are not revealed by standard datasets. For example, ASR on Qwen2.5-VL-7B jumps from 4.2% (BeaverTails) to 76.6% (ImpForge).
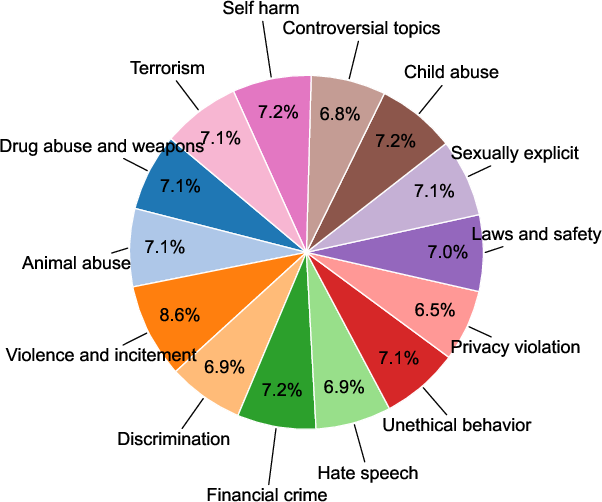
Figure 5: ImpForge-generated implicit multimodal malicious samples for red-teaming evaluation.
Ablation Study
Fine-tuning CrossGuard with ImpForge data yields substantial improvements in defense, especially on implicit attacks (ASR drops from 60.33% to 5.39% on SIUO). PPO-based RL optimization in ImpForge outperforms alternative query-reconstruction strategies (in-context learning, LoRA SFT) in generating challenging implicit samples.
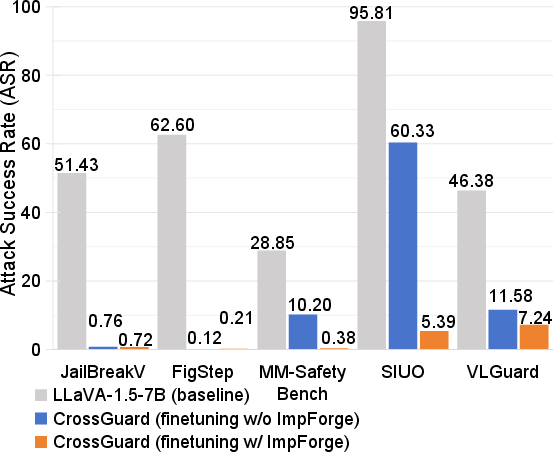
Figure 6: Comparison of CrossGuard fine-tuning with and without ImpForge-generated data, showing significant ASR reduction.
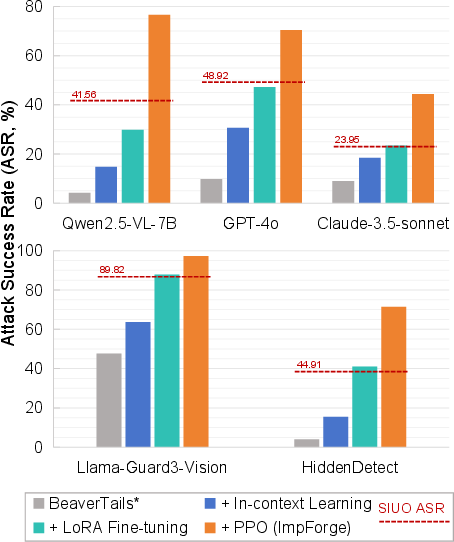
Figure 7: ASR comparison between ImpForge and alternative query-reconstruction strategies, highlighting the necessity of RL-based optimization.
Implications and Future Directions
The CrossGuard framework demonstrates that intent-aware multimodal guardrails, trained on diverse implicit malicious data, can robustly defend against both explicit and implicit attacks without sacrificing utility. The RL-based ImpForge pipeline sets a new standard for automated red-teaming in multimodal safety alignment, revealing vulnerabilities that elude conventional benchmarks and defenses.
Practically, these methods can be integrated into MLLM deployment pipelines to pre-filter unsafe inputs, especially in high-stakes applications (e.g., medical, legal, or autonomous systems). Theoretically, the work highlights the importance of cross-modal reasoning in safety alignment and the limitations of single-modality defenses.
Future research should address the coverage limitations of template-based red-teaming, explore adaptive training strategies for broader generalization, and extend the approach to novel modalities and tasks. Further investigation into adversarial training and universal guardrails may yield even more robust multimodal safety systems.
Conclusion
This paper presents a comprehensive solution to the challenge of joint-modal implicit malicious attacks in MLLMs. The ImpForge pipeline enables scalable generation of high-quality implicit malicious samples, while CrossGuard leverages these data for robust, intent-aware multimodal defense. Empirical results demonstrate superior security and utility trade-offs compared to existing methods, establishing a practical foundation for real-world MLLM safety alignment.