Skyfall-GS: Synthesizing Immersive 3D Urban Scenes from Satellite Imagery
Abstract: Synthesizing large-scale, explorable, and geometrically accurate 3D urban scenes is a challenging yet valuable task in providing immersive and embodied applications. The challenges lie in the lack of large-scale and high-quality real-world 3D scans for training generalizable generative models. In this paper, we take an alternative route to create large-scale 3D scenes by synergizing the readily available satellite imagery that supplies realistic coarse geometry and the open-domain diffusion model for creating high-quality close-up appearances. We propose \textbf{Skyfall-GS}, the first city-block scale 3D scene creation framework without costly 3D annotations, also featuring real-time, immersive 3D exploration. We tailor a curriculum-driven iterative refinement strategy to progressively enhance geometric completeness and photorealistic textures. Extensive experiments demonstrate that Skyfall-GS provides improved cross-view consistent geometry and more realistic textures compared to state-of-the-art approaches. Project page: https://skyfall-gs.jayinnn.dev/





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how to turn satellite photos of a city into a realistic 3D world you can fly through like a drone—without needing expensive 3D scans or street-level pictures. The method, called Skyfall-GS, builds a rough 3D city from space images and then uses a smart image-editing AI to make building sides and streets look sharp and lifelike.
What questions did the researchers ask?
- Can we create large, explorable 3D city scenes using only satellite images?
- How do we fix missing or messy parts (like building facades) that satellites can’t see well?
- Can we make the 3D city look realistic from many angles, not just from above?
- Can this run fast enough for real-time exploration?
How did they do it? (Methods)
The approach has two stages. Think of it like building a clay model and then painting in the details.
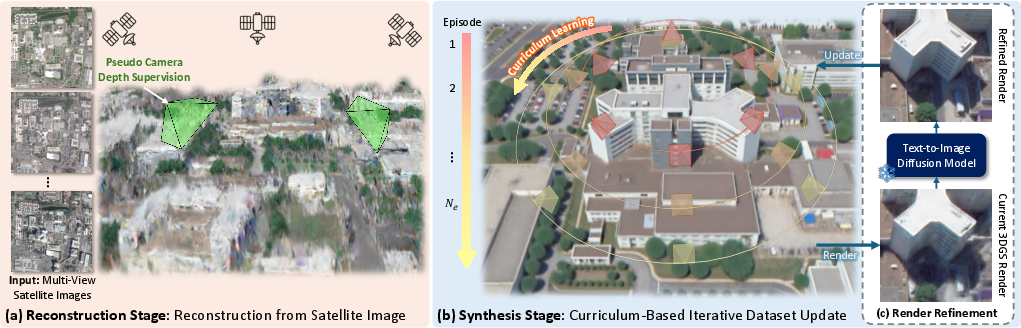
Stage 1: Build a rough 3D city from space photos
- 3D Gaussian Splatting (GS): Imagine the scene as a cloud of tiny semi-transparent paint blobs floating in 3D. When you look from a camera, they blend to make the image. This is fast for rendering views from different angles.
- Handling different lighting and dates: Satellite images of the same area can be taken at different times, seasons, and weather. The system learns small color adjustments per photo and per blob to balance these differences, so the 3D city looks consistent.
- Removing “floaters” (bad blobs): The system encourages blobs to be either clearly solid or removed, avoiding hazy, half-transparent bits that cause visual noise.
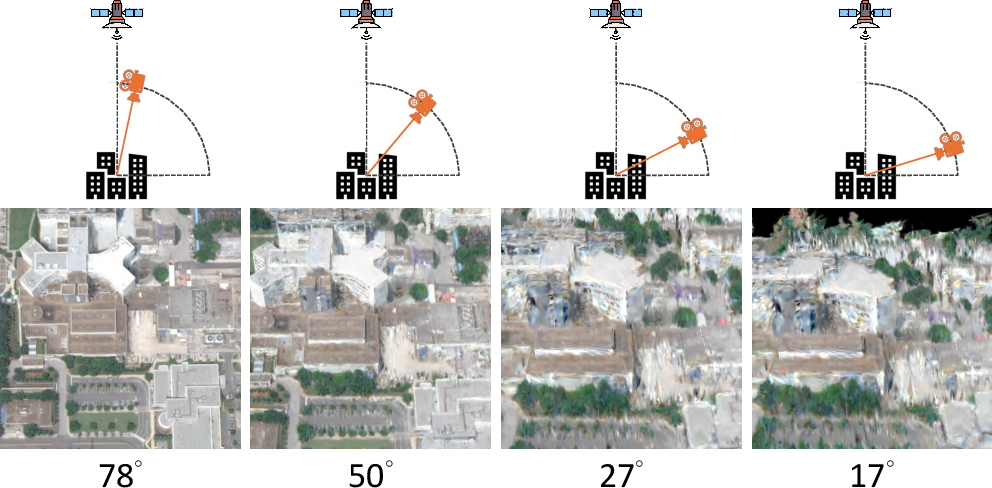
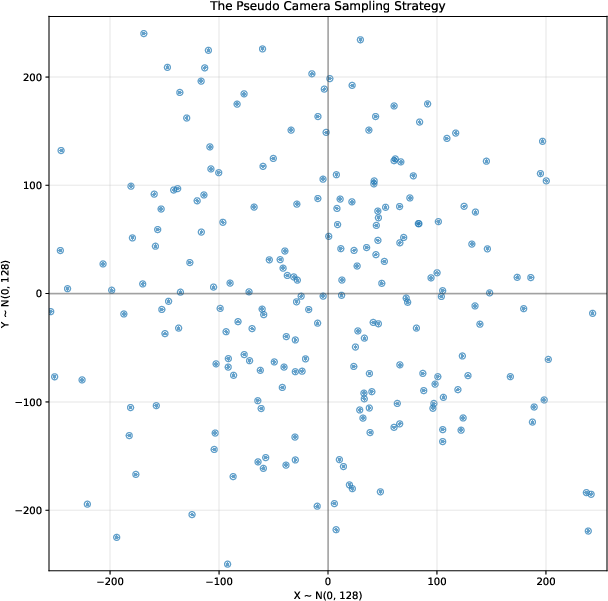
- Depth guidance from “pseudo cameras”: Because satellites mostly see rooftops and have limited side-angle views, the 3D shape can be wrong (for example, building sides may be missing). The system pretends to place cameras closer to the ground, renders what it has, and uses a depth-estimation AI to guess distances. It then adjusts the 3D blobs to better match realistic depth.
Stage 2: Make it look great up close
- Curriculum learning (start easy, go harder): The model begins by improving views from higher up (which are easier and more accurate), then gradually lowers the camera to street-like angles (which are harder). It’s like learning to ride a bike: start on smooth ground, then try trickier terrain.
- Diffusion model “refinement”: A diffusion model is like a smart photo editor that can clean up blurry images and add missing details step by step. The team uses it to fix renders of the 3D city—sharpen edges, fill in facades, and remove artifacts—guided by simple text prompts (e.g., “clear building facade with windows”). These refined images become better training data for the 3D model.
- Multiple samples per view: If you ask an AI editor to fix an image once, it might make choices that don’t perfectly fit other angles. So they generate several refined versions for each view, and the 3D model learns a balanced, consistent look across all angles.
This second stage repeats in cycles: render views → refine with diffusion AI → retrain the 3D model with the refined images → lower the camera angle → repeat. Each round makes the city look more complete and realistic.
What did they find and why it matters?
- More realistic textures and geometry: Buildings have clearer shapes and detailed facades, and roads and rooftops look correct. The method fills in parts that satellite photos don’t show well (like the sides of buildings).
- Better consistency across angles: The city looks believable whether you view it from above or near ground level; the look stays coherent as you fly around.
- Beats existing methods: In tests on Jacksonville (real satellite data) and New York City (Google Earth scenes), Skyfall-GS outperformed popular baselines, both in objective scores and human preference studies.
- Real-time performance: It can render at interactive speeds (they report up to around 40 frames per second on consumer hardware), which is great for exploration and applications like games or simulation.
- Uses only satellite imagery: No need for costly 3D scans or street-level photos, making it more scalable to many places.
What could this mean in the real world?
- Virtual exploration and entertainment: Game studios and filmmakers could quickly create realistic city scenes to explore, fly through, and use for storytelling.
- Robotics and simulation: Drones and robots could train in lifelike 3D cities without needing expensive real-world mapping.
- Planning and education: City planners, emergency responders, and students could study urban layouts in immersive 3D.
- Scalable mapping: Because it relies on widely available satellite images, it can be applied to many cities worldwide.
In short, Skyfall-GS shows a practical and fast way to build believable 3D cities from space photos alone, making rich virtual worlds more accessible for many uses.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise list of knowledge gaps, limitations, and concrete open questions that remain unresolved and could guide future research.
- Camera modeling fidelity: How sensitive is final geometry/appearance to errors in RPC-to-perspective conversion (SatelliteSfM), and can robust camera modeling or uncertainty-aware optimization reduce downstream artifacts?
- Absolute geometric accuracy: The method supervises geometry via scale-invariant depth correlation from pseudo-renders; how accurate are absolute heights, facade normals, and roof pitches versus ground-truth DSM/LiDAR, and how can absolute scaling be enforced?
- Circular supervision risk: Pseudo-camera depth supervision uses depth predicted from the method’s own renders; does this introduce self-confirmation bias, and can external depth priors (e.g., stereo, DSMs, SAR, or multi-view photometric consistency) improve reliability?
- 3D-consistent diffusion: FlowEdit performs independent 2D edits; can multi-view/3D-aware diffusion (e.g., MVDream-like constraints or 3D diffusion priors) enforce cross-view consistency and reduce hallucination drift across views?
- Measuring 3D coherence: Beyond image-space metrics (FID_CLIP, CMMD, PSNR/SSIM/LPIPS), what 3D-specific metrics (e.g., cross-view consistency scores, volumetric consistency, structural alignment error relative to GIS/DSM) can quantify geometric and textural coherence?
- Prompt design and generalization: The method relies on hand-crafted source/target prompts; can prompts be automatically derived (e.g., via CLIP guidance or in-context learning), and how robust are they across diverse architectural styles, climates, and cultural cues?
- Hallucination control: How can the system constrain diffusion refinements to prevent fabricating non-existent features (e.g., signage, fenestration, materials), especially for geospatially sensitive applications (planning, disaster response)?
- Semantic/geospatial fidelity: To what extent do synthesized facades and urban details match reality (e.g., building footprints, height profiles, material classes)? Can geospatial constraints (parcel maps, OSM, zoning) improve faithfulness?
- Handling transient changes: The appearance modeling addresses multi-date illumination but does not explicitly remove transient objects (cars, cranes, cloud shadows); can change detection/segmentation or temporal filtering increase stability?
- Illumination/shadow modeling: Per-image/per-Gaussian affine color transforms are not physically-based; would incorporating intrinsic decomposition or differentiable rendering (BRDF, shadows) reduce illumination-induced artifacts?
- Occluded structure priors: Satellite views rarely observe facades, tunnels, under-bridges; can structural priors (procedural grammars, CAD libraries, topological constraints) improve plausibility and enforce architectural regularities?
- Curriculum scheduling: The elevation/radius curriculum is hand-crafted; can view-selection be learned or adaptive (e.g., based on uncertainty, reconstruction error, visibility analysis), and does an auto-curriculum improve convergence and efficiency?
- Multi-sample diffusion trade-offs: What is the optimal number of diffusion samples per view (N_s) balancing 3D coherence and compute; can sample selection be made adaptive (e.g., via diversity/consistency scoring)?
- Robustness across sensors/resolutions: How does performance degrade with lower-resolution, different satellites (RPC variants), off-nadir angles, compression artifacts, or atmospheric conditions (haze, partial clouds)?
- Scalability to city-scale: The paper targets block-scale; what are memory/training-time costs and rendering performance for multi-km scenes, and which LOD/partitioning strategies (hierarchical GS, streaming) maintain fidelity and interactivity?
- Street-level quality: Textures are over-smoothed at extreme ground views; what additional cues (street-level photos, cross-view synthesis, BEV priors) or diffusion guidance can recover fine-grained details (signage, street furniture, curb geometry)?
- Material/specularity handling: Glass facades and specular effects are challenging; can specialized priors (e.g., SpectroMotion-like models, view-dependent material heads) improve realism and reduce view-dependent artifacts?
- Vegetation and thin structures: How well are trees, poles, wires, and railings reconstructed? Can topology-aware priors or semantic splats reduce floaters and preserve thin geometry?
- Training-time and compute transparency: The paper reports FPS but not end-to-end training/refinement time, memory footprint, or energy; standardized reporting and profiling would help assess practicality and eco-impact.
- Evaluation baselines and ground truth: Google Earth renders are used as reference, but they are not true ground truth; can evaluation incorporate measured geospatial data (LiDAR/DSM/ortho-mosaics) and additional baselines once code/models are available?
- GIS integration: How well are outputs georeferenced to real-world coordinates (datum, projection, scale)? Methods to ensure geodetic accuracy and interoperability with GIS pipelines remain to be formalized.
- Dynamic/temporal scenes: The approach is static; how can multi-date satellite sequences be leveraged for 4D urban modeling (construction phases, traffic patterns), with temporal coherence and change localization?
- Uncertainty quantification: There is no explicit uncertainty over geometry/textures; can uncertainty maps guide view selection, diffusion strength, or user warnings in downstream applications?
- Safety/ethics in geospatial use: What safeguards prevent misuse (e.g., realistic but incorrect reconstructions) and how can provenance, confidence, and disclaimers be embedded to inform end users?
- Parameter sensitivity: The effects of λ_op, λ_depth, SH order, episode counts (N_e), and view sampling (N_v, N_p) on convergence and quality are not systematically explored; guidelines or automatic tuning could improve reproducibility.
- Failure modes: Clear documentation of failure cases (extreme high-rise canyons, heavy occlusions, narrow alleys, complex multi-level interchanges) and targeted remedies would sharpen the method’s applicability envelope.
Practical Applications
Immediate Applications
Below is a curated list of practical use cases that can be deployed now, grounded in the paper’s findings (3D Gaussian Splatting from multi-view satellite imagery), methods (appearance modeling, opacity regularization, pseudo depth supervision), and innovations (curriculum-based iterative refinement with open-domain text-to-image diffusion, multi-sample consistency). Each item notes the relevant sectors and critical assumptions or dependencies.
- Real-time explorable urban block reconstructions for previsualization and prototyping
- Sectors: media & entertainment, software (game engines), AEC (architecture/engineering/construction)
- What emerges: a “Skyfall-GS for Unity/Unreal” plugin that ingests multi-view satellite tiles, runs the two-stage pipeline, and outputs a real-time 3DGS scene for storyboard, level layout, and previz
- Dependencies: access to multi-view satellite imagery (licensing), GPU resources for iterative refinement, camera model conversion (RPC→pinhole via SatelliteSfM)
- Assumptions: acceptable fidelity at mid-to-low altitude; street-level extremes may be over-smoothed
- Drone mission rehearsal at moderate altitudes (e.g., 20–120 m AGL)
- Sectors: robotics, logistics, public safety
- What emerges: “Skyfall Sim” workflow integrated into mission planners (e.g., DJI/TTA), enabling line-of-sight checks, waypoint visualization, and operator training in realistic, navigable 3D
- Dependencies: multi-date satellite views for coverage, prompt templates for diffusion edits, mid-altitude path relevance
- Assumptions: geometry is plausible for flight rehearsal; not suitable for precise collision-risk estimates in tight spaces
- Interactive neighborhood fly-throughs for real estate marketing and city tourism
- Sectors: real estate, tourism, marketing
- What emerges: web viewers (WebGPU) streaming 3DGS scenes; “Skyfall-GS Preview” service for custom addresses/blocks
- Dependencies: commercial imagery license, modest GPU for server-side refinement; client-side real-time rendering
- Assumptions: visual plausibility prioritized over architectural accuracy
- GIS/Mapping quicklook layers for areas lacking street-level coverage
- Sectors: geospatial software, mapping platforms
- What emerges: ArcGIS/QGIS extension producing an “explorable façade layer” derived from satellite-only input
- Dependencies: RPC metadata or estimated camera parameters; integration with existing GIS stacks
- Assumptions: intended for visualization rather than precise measurement
- Early-stage urban design workshops and public consultations
- Sectors: policy, urban planning, civic engagement
- What emerges: participatory tools to visualize “before/after” views or variants of streetscapes; scenario walk-throughs with low friction (no ground capture needed)
- Dependencies: multi-view satellite availability; curated prompts to keep edits faithful to local context
- Assumptions: scenes are “semantically plausible,” not ground-truth; used for discussion, not approval
- Educational VR field trips and geography lessons
- Sectors: education
- What emerges: curricula that let students explore global cities in VR; “Skyfall Classroom” content packs
- Dependencies: consumer hardware (e.g., standalone headsets) and lightweight 3DGS viewers
- Assumptions: visual fidelity sufficient for learning objectives; no need for strict metric accuracy
- Film and TV previs for location scouting (when on-site is impractical)
- Sectors: media & entertainment
- What emerges: workflows to block shots and camera moves using navigable reconstructions of target blocks
- Dependencies: GPU compute for refinement; prompter libraries (FlowEdit + FLUX) tuned for cinematic looks
- Assumptions: acceptable for framing and mood; not a replacement for final production scans
- Synthetic data augmentation for perception research at mid-altitude viewpoints
- Sectors: academia (computer vision, remote sensing), robotics
- What emerges: datasets with improved cross-view consistency from satellite-only inputs; controlled domain randomization via prompts and multi-sample refinement
- Dependencies: reproducible pipeline (released code), pre-trained diffusion models
- Assumptions: geometry/topology plausible; caution for tasks needing fine-grained semantics
- Network planning previsualization (non-engineering grade)
- Sectors: telecom
- What emerges: quick visualizations of potential antenna placements and rough line-of-sight in 3D for stakeholder communication
- Dependencies: enough multi-view coverage for height plausibility; rapid turnarounds
- Assumptions: not for RF simulation or compliance; used for early discussions
- Insurance marketing and customer engagement (visual risk storytelling)
- Sectors: finance/insurance
- What emerges: interactive visuals to explain neighborhood-scale risks (e.g., flood paths, wind exposure) at a qualitative level
- Dependencies: domain overlays (risk maps), satellite inputs
- Assumptions: qualitative visualization; not a basis for underwriting decisions
Long-Term Applications
These applications will benefit from further research, scaling, or validation—especially around geometry fidelity, street-level realism, dynamic scenes, and policy compliance.
- City-scale digital twins from satellite-only pipelines
- Sectors: smart cities, mapping platforms, software
- What could emerge: “Skyfall Twin” services that auto-ingest multi-date imagery to keep large urban twins current
- Needed advances: hierarchical/streaming 3DGS for city-scale, automated change detection, robust georegistration
- Dependencies: frequent multi-view satellite captures; efficient training at scale
- Safety-critical planning (disaster response, evacuation, accessibility)
- Sectors: public safety, policy
- What could emerge: planning environments with reliable geometry for evacuation route analysis and staging
- Needed advances: validated heights and façade geometry (e.g., fusing LiDAR/SAR/DSM), uncertainty quantification
- Assumptions: stricter accuracy and audit trails; current hallucinated facades are insufficient
- Autonomous driving synthetic data with street-level fidelity and semantics
- Sectors: automotive, robotics
- What could emerge: training corpora with physically correct road markings, signage, traffic furniture, materials
- Needed advances: street-level detail enhancement, semantic grounding, temporal coherence, dynamic agents
- Dependencies: mixed modalities (aerial + limited ground), 3D-consistent diffusion
- Solar and shadow analytics, energy modeling
- Sectors: energy, sustainability
- What could emerge: tools for solar potential analysis, daylighting studies across districts
- Needed advances: accurate geometry and material reflectance, physically-based rendering, error bounds
- Assumptions: current textures/geometries may bias results; require calibration
- Telecom RF planning and optimization (engineering-grade)
- Sectors: telecom
- What could emerge: mmWave line-of-sight and path loss analytics embedded in explorable twins
- Needed advances: precise building heights, façade materials, rooftop furniture modeling; validation pipelines
- Dependencies: fusion with DSM/point clouds; standards compliance
- Global-scale “street-level from sky” 3D for coverage gaps
- Sectors: mapping, navigation
- What could emerge: a world-wide fallback layer for pedestrian/driver navigation when ground imagery is sparse
- Needed advances: robust low-altitude realism, textural detail, semantics; scalable curricula and model compression
- Assumptions: geopolitical and licensing constraints for imagery access
- Policy and permitting workflows (digitally review proposed changes in context)
- Sectors: governance, urban planning
- What could emerge: formal review tools where applicants submit modifications rendered in context via Skyfall-GS
- Needed advances: accuracy guarantees, tamper-evident logs, provenance tracking
- Dependencies: legal frameworks defining acceptable error margins, certified data fusion
- AR navigation and pedestrian assistance
- Sectors: mobile, AR/VR
- What could emerge: on-device AR overlays that align synthetic facades to guide users in unfamiliar districts
- Needed advances: precise alignment to GNSS/SLAM, street-level texture quality, incremental updates
- Assumptions: device constraints; current method may over-smooth at ground level
- Environmental impact assessment visuals (noise, heat islands, green canopy)
- Sectors: environment, policy
- What could emerge: interactive scenario testing with quantitative overlays in a realistic 3D context
- Needed advances: accurate vegetation/structure modeling, material properties, coupling to simulators
- Dependencies: additional data sources (multispectral, LiDAR), validated pipelines
- Training and simulation platforms for emergency responders
- Sectors: public safety, defense
- What could emerge: immersive, up-to-date scene replicas for drills, with dynamic overlays (smoke, crowd)
- Needed advances: dynamic scene generation, agent simulation, verified layouts
- Assumptions: high reliability required; current hallucinations must be controlled
- Content-aware urban editing tools (e.g., bridge/tunnel synthesis, multi-level structures)
- Sectors: AEC, software
- What could emerge: “Skyfall Edit” that uses prompt-based diffusion with 3D consistency to add/remove structures
- Needed advances: 3D-consistent diffusion across many views, topology correctness, constraint-aware editing
- Dependencies: better 3D diffusion priors; constraint solvers
- Automated change detection and versioning for urban monitoring
- Sectors: remote sensing, policy
- What could emerge: time-stamped reconstructions tracking construction/demolition with alerts
- Needed advances: robust multi-date appearance modeling, geometric differencing in 3DGS, uncertainty metrics
- Assumptions: consistent multi-view captures; policy controls for privacy and compliance
Cross-cutting assumptions and dependencies
- Multi-view satellite imagery availability and licensing costs; geographic or political restrictions may limit coverage.
- Camera calibration quality (RPC→pinhole via SatelliteSfM) and georegistration accuracy are critical for plausible geometry.
- Compute intensity of the curriculum-based iterative refinement (IDU) and reliance on pre-trained text-to-image diffusion (FlowEdit + FLUX) can constrain throughput; model updates and prompt engineering affect outcomes.
- Hallucinated facades and textures increase perceptual realism but are not ground-truth; unsuitable for safety-critical or compliance workflows without additional validation.
- Current limitations: over-smoothed textures at extreme street-level viewpoints; static scenes only; no strong physical/material modeling; scaling to large areas requires hierarchical/streaming representations and memory management.
Glossary
- 3D Gaussian Splatting (3DGS): A point-based scene representation that renders radiance fields with anisotropic Gaussians for real-time view synthesis. "3D Gaussian Splatting (3DGS) \citep{kerbl20233d} encodes a scene as Gaussians with center , covariance , opacity , and view-dependent color."
- Affine-projection Jacobian: The Jacobian matrix of the affine camera projection that maps 3D covariance into image-plane covariance. "where is the viewing transformation and is the affine-projection Jacobian."
- Alpha-blended depth map: A depth image computed by compositing per-Gaussian depths with their opacities along the viewing ray. "From these pseudo-cameras, we render RGB images $I_{\text{RGB}$ and corresponding alpha-blended depth maps $\hat{D}_{\text{GS}$."
- Alpha compositing: Layering technique that blends colors using per-pixel opacity along the viewing order. "Pixels are alpha-composited front-to-back."
- Appearance modeling: Learnable components that factor out illumination/atmospheric changes across images to stabilize reconstruction. "We employ appearance modeling to handle variations in multi-date imagery."
- BEV (Bird’s-Eye View): A top-down representation used for city/scene modeling and neural fields. "CityDreamer \citep{xie2024citydreamer} and GaussianCity \citep{xie2025gaussiancity} use BEV neural fields or BEV-Point splats for editable scenes,"
- CMMD: A CLIP-based Maximum Mean Discrepancy metric for distribution-level image quality/diversity evaluation. "We report ~\citep{Kynkaanniemi2022} and CMMD~\citep{jayasumana2024rethinking} that use the CLIP~\citep{radford2021learning} backbone."
- Curriculum learning: Training strategy that schedules tasks/views from easy to hard to improve stability and quality. "we tailor a curriculum-driven iterative refinement strategy to progressively enhance geometric completeness and photorealistic textures."
- Densification: The process of adding/pruning Gaussians to refine geometric detail during training. "allowing low-opacity Gaussians to be pruned during densification."
- Denoising diffusion process: A generative process that iteratively removes noise to synthesize or refine images. "we treat these renderings as intermediate results in a denoising diffusion process."
- Digital Surface Model (DSM): A height map capturing the elevation of terrain and surface structures derived from imagery. "Classic SfM-MVS pipelines extract DSMs from satellite pairs"
- Entropy-based opacity regularization: A loss that encourages near-binary opacities to produce sharper, cleaner geometry. "we propose entropy-based opacity regularization:"
- FID_CLIP: A CLIP-embedding variant of Fréchet Inception Distance for comparing image distributions. "We report ~\citep{Kynkaanniemi2022} and CMMD~\citep{jayasumana2024rethinking} that use the CLIP~\citep{radford2021learning} backbone."
- Iterative Dataset Update (IDU): A loop that renders, edits via diffusion, and retrains to progressively improve 3D quality. "The iterative dataset update (IDU) technique~\citep{instructnerf2023,melaskyriazi2024im3d} repeatedly executes render-edit-update cycles across multiple episodes"
- Level of Detail (LOD): A strategy for scaling large scenes by adapting representation resolution/complexity. "while large-scene methods use LOD and partitioning \citep{kerbl2024hierarchical,liu2025citygaussian,liu2024citygaussianv2efficientgeometricallyaccurate,lin2024vastgaussianvast3dgaussians,turki2022mega,tancik2022block}."
- Monocular depth estimator: A model that predicts depth from a single RGB image without stereo or LiDAR. "We then use an off-the-shelf monocular depth estimator, MoGe~\citep{wang2024moge}, to predict scale-invariant depths"
- Multi-View Stereo (MVS): Dense 3D reconstruction from multiple overlapping calibrated images. "Classic SfM-MVS pipelines extract DSMs from satellite pairs"
- NeRF (Neural Radiance Fields): A neural volumetric representation that enables photorealistic view synthesis. "3D Gaussian Splatting (3DGS) \citep{kerbl20233d} offers real-time view synthesis rivaling NeRFs \citep{mildenhall2021nerf,barron2021mipnerf,barron2022mipnerf360,mueller2022instant,barron2023zipnerf,martin2021nerf}."
- Orbital trajectories: Camera paths circling a target with controlled radius/elevation for systematic rendering. "and uniformly sample camera positions along orbital trajectories with controlled elevation angles and radii."
- Parallax: Apparent displacement between viewpoints enabling depth inference; limited parallax harms reconstruction. "The significant amount of invisible regions (e.g., building facades) and limited satellite-view parallax create incorrect geometry and artifacts."
- Pearson correlation (PCorr): A correlation-based supervisory signal used to align predicted and estimated depth trends. "We use the absolute value of Pearson correlation (PCorr) to supervise the depth:"
- Prompt-to-prompt editing: Diffusion-based image editing that modifies outputs by changing text prompts while preserving structure. "Prompt-to-prompt editing~\citep{hertz2022prompt} modifies input images, which are described by the source prompt, to align with the target prompt while preserving structural content."
- Rational Polynomial Camera (RPC): A sensor model mapping image to geodetic coordinates via rational polynomial functions. "Satellite imagery typically uses the rational polynomial camera (RPC) model, directly mapping image coordinates to geographic coordinates."
- Scale-invariant depth: Depth predictions normalized to ignore global scale, focusing on relative depth structure. "to predict scale-invariant depths $\hat{D}_{\text{est}$ from these renders."
- Spherical Harmonics (SH): Basis functions used to model low-order view-dependent color/lighting. "and denotes the 0-th order spherical harmonics (SH)."
- Structure-from-Motion (SfM): Recovering camera poses and sparse 3D points from image collections. "Classic SfM-MVS pipelines extract DSMs from satellite pairs"
- T2I (Text-to-Image) diffusion model: A pretrained diffusion model that synthesizes or refines images conditioned on text prompts. "a pre-trained T2I diffusion model~\citep{flux2024} with prompt-to-prompt editing~\citep{kulikov2024flowedit}."
- Variational Score Distillation: A distillation objective for stabilizing/regularizing diffusion-guided 3D optimization. "with ProlificDreamer~\citep{wang2023prolificdreamer} addressing over-smoothing via Variational Score Distillation."
- View-dependent color: Color that varies with viewing direction, modeling specularities and anisotropic appearance. "opacity , and view-dependent color."
- Zero-shot generalization: The ability to work on unseen domains/tasks without task-specific training. "which provides better zero-shot generalization and diversity."
Collections
Sign up for free to add this paper to one or more collections.