Rethinking Cross-lingual Gaps from a Statistical Viewpoint
Abstract: Any piece of knowledge is usually expressed in one or a handful of natural languages on the web or in any large corpus. LLMs act as a bridge by acquiring knowledge from a source language and making it accessible when queried from target languages. Prior research has pointed to a cross-lingual gap, viz., a drop in accuracy when the knowledge is queried in a target language compared to when the query is in the source language. Existing research has rationalized divergence in latent representations in source and target languages as the source of cross-lingual gap. In this work, we take an alternative view and hypothesize that the variance of responses in the target language is the main cause of this gap. For the first time, we formalize the cross-lingual gap in terms of bias-variance decomposition. We present extensive experimental evidence which support proposed formulation and hypothesis. We then reinforce our hypothesis through multiple inference-time interventions that control the variance and reduce the cross-lingual gap. We demonstrate a simple prompt instruction to reduce the response variance, which improved target accuracy by 20-25% across different models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies why big AI LLMs (like the ones that answer questions in many languages) sometimes do worse when you ask them questions in one language than in another. The authors argue that the main problem isn’t that the model “doesn’t know” the fact in the new language. Instead, the model’s answers in that language are more “noisy” or inconsistent. They show that if you reduce this noise, the performance gap across languages gets much smaller.
The big questions the authors asked
- Why do LLMs often answer correctly in the language where the information was learned (the source language), but make more mistakes when asked in a different language (the target language)?
- Is this because the model lacks the knowledge in the target language (bias), or because its answers are just more scattered and inconsistent there (variance)?
- Can we reduce this gap by making the model’s answers more consistent, without retraining the model?
How did they study it? (Everyday explanation)
Think of a dartboard:
- Bias: Your darts always land off to the left. You’re consistently wrong in the same direction.
- Variance: Your darts land all over the place. Sometimes you’re right, sometimes you’re wrong, because your throws are inconsistent.
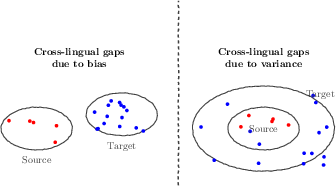
The authors treat answers in the source language like a stable dart throw, and answers in the target language like a shakier throw. If the gap is mostly bias, the model is “consistently wrong” in the target language. If the gap is mostly variance, the model “knows the right spot” but throws are scattered.
What they did:
- They asked many knowledge questions that were known in one language (the source) and asked the same questions in other languages (the targets).
- They used “closed-book” settings (no internet/search) to test what the model already knows.
- They ran multiple tries for the same question to see how much the model’s answers jump around (this is measuring variance).
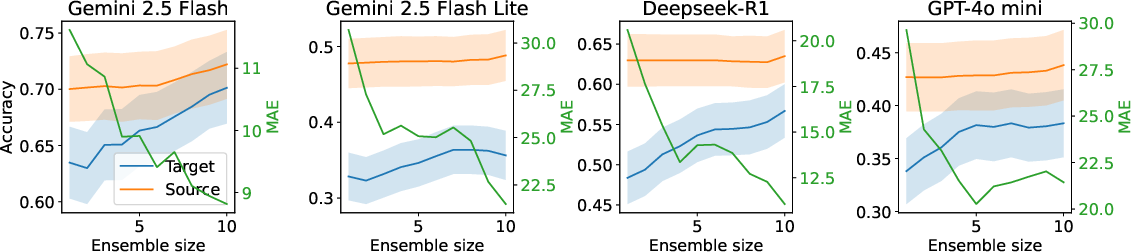
- They used “ensembling,” which means combining several answers to get a more reliable final answer—like taking a vote or choosing the most common answer.
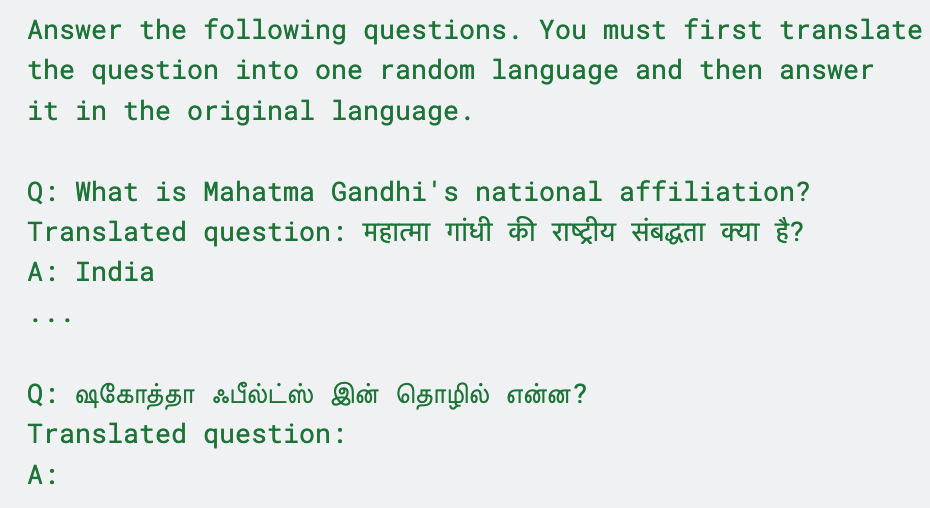
- They also tried “input ensembling,” where they present several versions/translations of the same question together, or have the model first translate the question and then answer. This nudges the model to be more consistent.
Datasets and models:
- They tested on cross-language benchmarks (like ECLeKTic and a mixed-language version of MMLU) and tried several modern models from different organizations.
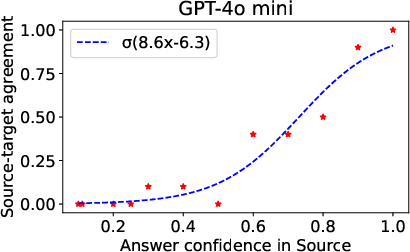
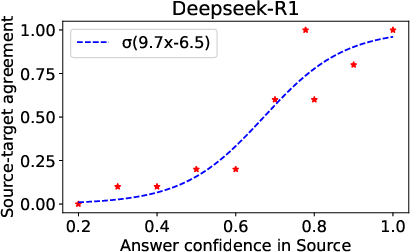
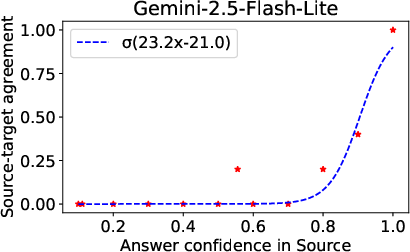
- They also checked how “confident” the model is in its answers, by seeing how often it repeats the same answer over multiple tries (the “mode,” or most frequent answer).
What did they find, and why is it important?
Main findings:
- The cross-language performance gap is mostly due to higher variance (more scattered answers) in the target language, not because the model lacks the knowledge in that language.
- When they reduce variance (for example, by ensembling multiple answers or using helpful prompts), the gap shrinks a lot.
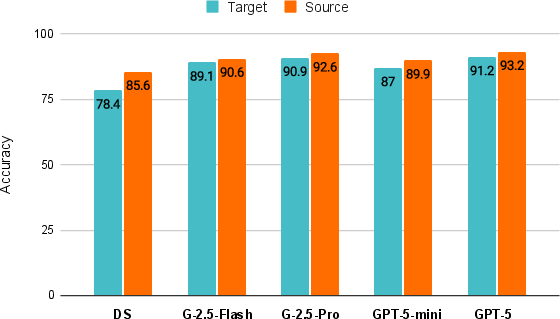
- A simple prompt strategy that lowers answer variance boosted accuracy in the target language by about 20–25% across different models.
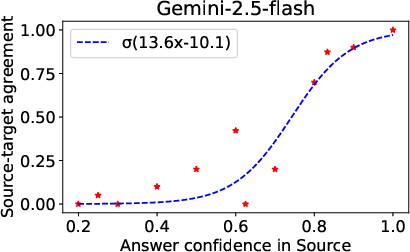
- The model’s inconsistency in the target language is tied to how confident it is in the source language. If the model is very confident in the source language, it tends to be more confident in the target language too. In those cases, the cross-language gap gets much smaller.
- These patterns held across different datasets and several strong models, which makes the results more trustworthy.
Why this matters:
- If the problem is mainly variance (inconsistency), we don’t necessarily need to retrain or redesign the model to fix “missing knowledge.” We can often get better cross-language performance with smarter prompting and simple answer-averaging at inference time.
- This is faster, cheaper, and easier to apply broadly, which can help make AI systems more fair and useful across many languages.
What does this mean for the future?
- Practical impact: You can often narrow cross-language gaps with simple techniques like:
- Asking the model multiple times and taking the most common answer.
- Showing the model several translated versions of the same question before it answers.
- Using prompts that explicitly encourage careful, consistent answers.
- Research impact: Future work can focus more on stability and confidence across languages, not just on fixing internal representations or retraining huge models.
- Broader idea: The “variance, not missing knowledge” insight might also help with other kinds of gaps, like between different input types (for example, text vs. audio).
Key terms explained (in simple language)
- Source language: The language where the model likely learned the fact (for example, the language of the original Wikipedia page).
- Target language: A different language you use to ask the same question.
- Bias: Being consistently off in one direction—like always guessing the wrong year range.
- Variance: Being inconsistent—answers jump around; sometimes right, sometimes wrong.
- Ensembling: Combining several answers into one, like taking a vote, to reduce randomness.
- Confidence: How often the model repeats the same answer over multiple tries; higher confidence usually means more reliable answers.
In short: The paper shows that cross-language mistakes mainly come from wobbly, inconsistent answering in the new language—not from missing knowledge. Reduce the wobble, and the gap largely goes away.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains uncertain or unexplored, framed to guide concrete follow-up research:
- Modeling assumptions: The target-response model assumes Gaussian logits, a mixture with an unbiased component, and multiplicative flattening () and variance inflation (). It remains untested how sensitive the conclusions are to these choices or to alternative, non-Gaussian or heavy-tailed logit distributions.
- Parameter estimation: The mixture weight (and nuisance parameters , ) is only heuristically estimated from agreement trends. There is no principled, identifiable estimation procedure with uncertainty quantification; developing statistically grounded estimators is open.
- Forward-pass stochasticity proxy: The work treats forward-pass stochasticity (floating-point noise, MoE routing) as a proxy for model uncertainty without training multiple replicas. It is unclear whether conclusions hold when true parameter uncertainty is measured via independent model instances or Bayesian approximations.
- Deterministic models and decoding: Many LLM APIs now expose near-deterministic decoding at . How do the results change when ensembling is impossible or limited? What is the minimal sampling/decoding budget to robustly reduce variance across languages?
- Loss decomposition mismatch: The argument invokes MSE-style bias–variance intuitions, while the task uses categorical/0–1 accuracy and cross-entropy. A formal decomposition in the discrete setting (and its implications under softmax) is not provided.
- Causal mechanism for variance inflation: The paper shows that target variance increases but does not identify why. Is variance driven by tokenization/orthography, data scarcity, instruction-following instability, internal translation steps, or conflicting pretraining facts? A causal analysis is missing.
- Confounds from translation quality: Target prompts use machine translations and mixup; translation errors or semantic drift could inflate variance or mimic bias. There is no systematic quantification or control of translation fidelity by language and domain.
- Embedding-based divergence metric: ECLeKTic source–target distance relies on a single multilingual embedding model and L2 in embedding space, which encodes language/syntax. Robustness to other embedding models, alignment procedures, and language-invariant canonicalizers is untested.
- LLM-as-judge reliability: Free-form answer correctness and mode matching depend on an LLM judge and LLM summarizer, both with known higher error rates on non-English. The extent of induced bias/variance in measurements is not quantified, and ablations with human annotations are limited.
- Response-space normalization: The approach assumes responses can be normalized to language-agnostic “concepts,” but practical normalization relies on LLM summarization. The accuracy, recall, and failure modes of this normalization (especially for named entities, morphology, and scripts) are not audited.
- Year-ECLeKTic coverage: The “year-only” subset avoids judging noise but covers only a small fraction of ECLeKTic. Whether results generalize to non-numeric, multi-span, or compositional answers remains open.
- Scope of languages: Experiments cover 5–12 languages with likely moderate-resource coverage. Performance and variance behavior for typologically diverse, low-resource, polysynthetic, or unseen-script languages are unknown.
- Task scope: Findings are limited to knowledge-intensive QA and multiple choice. It is unclear whether the variance-dominant explanation holds for reasoning-heavy tasks, long-form generation, code, multimodal inputs, or dialog.
- Architecture effects: Differences between dense and MoE models, and between “thinking” and non-thinking models, are noted but not dissected. How architectural choices, intermediate translation strategies, and chain-of-thought affect cross-lingual variance is open.
- Practicality of ensembling: The paper shows ensembling and input aggregation reduce gaps but does not quantify latency, token/cost overheads, and user-experience trade-offs. What are cost-effective, deployable protocols per language and task?
- Minimal prompting to reduce variance: TTA/TrEn can help, but the minimal effective intervention is unclear. Which instructions, few-shot exemplars, language tags, or temperature schedules most efficiently reduce variance by language?
- Calibration and per-language decoding: Whether per-language calibration (temperature scaling, top-p/top-k tuning) or adaptive decoding policies can systematically equalize confidence across languages is untested.
- Distinguishing residual bias from noise: A small fraction of items remain mismatched after ensembling. Are these true knowledge barriers, translation artifacts, or cross-language factual inconsistencies? A diagnostic taxonomy and controlled dataset are needed.
- ECLeKTic and MMLU-mixup design: Both benchmarks may embed language–topic confounds and uneven difficulty across languages. A controlled benchmark that balances topic, entity frequency, and script factors is needed to isolate variance effects.
- Statistical significance and uncertainty: Many plots show trends without formal significance tests, confidence intervals across languages, or correction for multiple comparisons. Rigorous uncertainty quantification is lacking.
- Parameterizing variance sources: The model abstracts variance in logits but does not map it to token-level entropy, exposure bias, or decoding path instability. A micro-level analysis (e.g., token logit dispersion by script and morphology) is missing.
- Interaction with retrieval: The study uses closed-book settings; whether retrieval (RAG), grounding, or tool use reduces or amplifies cross-lingual variance is unknown.
- Generalization beyond text: The paper hypothesizes applicability to cross-modal gaps but provides no evidence. Do similar variance mechanisms explain disparities for speech, OCR’d text, or ASR inputs across languages?
- Reproducibility with closed models: Results rely on evolving, closed-source APIs (Gemini, GPT) with undisclosed changes to sampling and routing. Reproducibility and stability over model updates are not addressed.
- Tokenization and orthography: The role of subword segmentation, non-Latin scripts, and orthographic depth in inducing variance is not systematically analyzed. Do alternative tokenizers or byte-level models mitigate variance?
- Data provenance and contradictions: Cross-language factual inconsistencies in pretraining corpora are posited but not measured. Building corpora with audited, aligned multilingual facts could test variance as a coping mechanism.
- Hyperparameter sensitivity: The choice of temperature, seeds, and ensemble size (k=10) is not systematically explored per language. What are the sensitivity curves and optimal policies conditioned on source confidence?
- Theoretical guarantees: The propositions indicate qualitative trends but do not yield performance guarantees under realistic decoding and finite-sample ensembling. Tight, practically verifiable bounds remain open.
Practical Applications
Practical Applications of “Rethinking Cross-Lingual Gaps from a Statistical Viewpoint”
The paper’s core finding—that cross-lingual performance gaps in LLMs are dominated by response variance (not knowledge/bias), and can be mitigated with simple inference-time interventions—enables actionable applications across sectors. Below, we group concrete use cases by immediacy, linking them to industries, tools/workflows, and feasibility assumptions.
Immediate Applications
These applications can be deployed now with current LLMs and infrastructure, relying on prompt engineering, ensembling, and confidence gating.
- Multilingual customer support and helpdesk assistants
- Sectors: software, e-commerce, telecom, finance, government services
- Application: Integrate response ensembling (multiple stochastic forward passes at default temperature) and input ensembling (“Translation Ensemble” TrEn-k and “Translate-then-Answer” TTA-k) into production chatbots to reduce cross-language accuracy drops in FAQs, billing, troubleshooting, and policy explanations.
- Workflow/tools:
- Run N responses with different seeds; majority vote or “mode” selection.
- TrEn-k: present the query plus k translations in the prompt; require a single answer consistent across all.
- TTA-k: ask the model to generate k translations first, then answer once the translations agree.
- Confidence gating: estimate mode probability; if low, route to retrieval (RAG), pivot to source language, or escalate to a human.
- Assumptions/dependencies: LLM supports relevant languages; translation quality is adequate; added latency/cost from ensembling is acceptable; forward pass has enough stochasticity; privacy policies permit intra-prompt translations.
- Multilingual enterprise knowledge access (internal wikis, policy manuals, SOPs)
- Sectors: software, energy, manufacturing, logistics, professional services
- Application: Deploy “variance-aware” inference for closed-book Q&A across employee languages; reduce target-language variance using TTA-1 or TrEn-3 to stabilize answers on safety, compliance, and process details.
- Tools/products: A microservice that wraps LLM inference with translation self-consistency, majority voting, caching, and confidence-based fallbacks.
- Assumptions: Content is consistent across languages or has a canonical source; embedding or regex-based normalization for answers (e.g., years) is available; governance allows automated translations.
- Healthcare front-door triage and patient education in multiple languages
- Sectors: healthcare
- Application: Use input and response ensembling to stabilize basic triage advice and patient instructions across languages (e.g., appointment prep, medication timing).
- Tools/workflows: TrEn-k on key safety-critical prompts; confidence thresholds that force RAG with vetted medical sources; audit logs capturing cross-lingual agreement.
- Assumptions: Medical content is consistent across languages; strict safety guardrails and human oversight are in place; latency overhead is acceptable.
- Multilingual tutoring and educational assistants
- Sectors: education
- Application: Apply TTA-1 to reduce variance in factual queries and concept explanations across student languages; use confidence gating to rephrase or provide additional context when confidence is low.
- Tools/workflows: Prompt libraries with “translate-then-answer and check consistency” instructions; simple regex or numeric checks for objective answers (dates, formulas).
- Assumptions: Curriculum-aligned content; acceptable latency overhead; model supports the target languages.
- News, media, and content verification
- Sectors: media, journalism, public policy
- Application: Verify factual claims (e.g., dates, names) by enforcing cross-translation self-consistency; use majority voting and mode confidence to flag ambiguity.
- Tools/workflows: A “multilingual fact check” pipeline that runs TrEn-5 and reports agreement scores; integrates RAG for low-confidence cases.
- Assumptions: Access to reliable source documents; translation consistency across scripts; editorial tolerance for added verification steps.
- Procurement and compliance evaluation of LLMs for multilingual fairness
- Sectors: policy, public sector, regulated industries (finance, healthcare)
- Application: Adopt a variance-centric audit harness: report cross-lingual agreement improvements under ensembling and confidence gating (transfer-score; source-target mode agreement) when procuring or certifying LLM systems.
- Tools/workflows: Evaluation suite built on ECLeKTic, Year-ECLeKTic, and MMLU (with mixup); compute bias-variance indicators and estimate mixing coefficient π via ensemble behavior.
- Assumptions: Access to evaluation datasets; standardization of audit metrics; organizational buy-in for variance-based mitigation.
- Developer tooling: “Cross-Lingual Self-Consistency” SDK
- Sectors: software
- Application: Provide an SDK and middleware that expose APIs for TrEn-k, TTA-k, multi-seed response aggregation, confidence estimation, and fallback orchestration.
- Tools/products:
variance_ensemble.run(prompt, k_translations=3, n_samples=10)confidence_gate(mode_prob_threshold=0.6, fallback='rag|human|pivot_language')- Assumptions: Platform resources for multiple passes; caching; rate limit handling.
- Personal assistants and browser extensions
- Sectors: daily life
- Application: A user-facing extension that automatically translates a query into several languages, obtains self-consistent answers, and surfaces a stability score before presenting a final answer.
- Assumptions: Model supports the languages of interest; user privacy is preserved; latency is acceptable.
Long-Term Applications
These applications require further research, training-time changes, architectural adjustments, scaling, or standard-setting.
- Training-time variance regularization across languages
- Sectors: AI development across all industries
- Application: Develop post-training objectives that penalize excess target variance (e.g., multi-translation consistency losses, calibration to align logit separations across languages, temperature alignment).
- Tools/workflows: Fine-tuning with multilingual augmentations; explicit regularizers tying source confidence to target confidence.
- Dependencies: Access to multilingual data, compute; careful safety testing to avoid overconfidence and mode collapse.
- Automated diagnosis of “bias vs variance” in cross-lingual behavior
- Sectors: academia, AI safety, policy
- Application: Build a diagnostic framework to estimate the mixing coefficient π (fraction of variance-driven cases) per language/domain, distinguishing true knowledge barriers from variance.
- Tools/workflows: Ensemble-based probes, confidence transfer curves, pivot-language testing, and translation quality checks.
- Dependencies: Reliable estimators for confidence/mode probability; standardized protocols and datasets.
- Efficient low-latency ensemble approximations
- Sectors: platforms, cloud AI providers
- Application: Research methods that approximate self-consistency without full multi-sample runs (e.g., shared-forward partial sampling, logit smoothing, MoE gating stabilization, on-device cache distillation).
- Tools/workflows: Distill ensemble behavior into a single “variance-calibrated” model; integrate with inference accelerators.
- Dependencies: Access to model internals; potential hardware/software co-design; maintaining robustness.
- Multilingual RAG with variance-aware orchestration
- Sectors: software, healthcare, finance, law
- Application: Combine variance estimates with knowledge-grounding: trigger retrieval when target confidence is low; select best pivot/source language passages; align citations across languages.
- Tools/workflows: Confidence-aware RAG controllers; multilingual indexers; cross-language citation reconciliation.
- Dependencies: High-quality multilingual corpora; citation audit; latency budgets.
- Standards and policy frameworks for multilingual fairness and robustness
- Sectors: public policy, regulation, certification bodies
- Application: Establish requirements to report cross-lingual variance metrics (confidence transfer, agreement curves, ensemble gains) when certifying LLMs used in public services or regulated settings.
- Tools/workflows: Benchmark suites; reporting templates; procurement checklists focusing on variance mitigation rather than only embedding alignment.
- Dependencies: Consensus on metrics; enforcement capacity; compatibility with existing standards.
- Cross-modal generalization of variance-centric methods
- Sectors: speech assistants, robotics, accessibility
- Application: Extend input/response ensembling and confidence gating to audio and vision inputs (e.g., voice commands across languages, visual Q&A), where modality changes may introduce additional variance.
- Tools/workflows: Multi-modal “translate-then-answer” analogues (speech-to-text pivot, multi ASR hypotheses), self-consistency across modalities.
- Dependencies: Multi-modal models; high-quality ASR and OCR; additional latency and resource management.
- Residual gap handling: translation quality and cross-language fact reconciliation
- Sectors: media, law, academia
- Application: Detect and resolve cases where genuine knowledge inconsistencies or translation errors create bias-like gaps; build workflows for multi-source reconciliation and citation in multiple languages.
- Tools/workflows: Translation quality estimators; conflict detection across language versions; human-in-the-loop arbitration.
- Dependencies: Access to source documents; domain experts; cost of reconciliation.
- Hardware and runtime controls for stochasticity
- Sectors: AI infrastructure
- Application: Explore controlled stochasticity in inference (or stability-enhancing determinism) to optimize the trade-off between variance exposure and ensemble efficiency.
- Tools/workflows: FP settings, MoE routing controls, reproducible sampling strategies.
- Dependencies: Model/runtime-level access; performance trade-offs; reproducibility requirements.
Cross-Cutting Assumptions and Dependencies
- Applicability is strongest to languages covered by the benchmarks and reasonably represented in pretraining; unseen or extremely low-resource languages may still face knowledge barriers.
- Ensembling increases compute cost and latency; productionization requires caching, rate-limit management, and careful UX.
- Forward-pass stochasticity (e.g., FP errors, MoE routing) is a practical source of variance; fully deterministic inference may require architectural or runtime adjustments to expose useful variability for aggregation.
- Translation quality and script diversity matter; mis-translations can introduce real bias-like errors.
- Confidence estimation must be calibrated; mode probability should be coupled with safe fallbacks (RAG, human review) in sensitive domains.
- LLM-as-judge and embedding-based agreement metrics are useful but imperfect; numeric or structured-answer tasks (e.g., Year-ECLeKTic) offer cleaner validation.
Glossary
- Bernoulli distribution: A discrete distribution over two outcomes with success probability π. "κ∼ Bernoulli(π)"
- Bias-variance decomposition: A statistical decomposition of prediction error into bias and variance components. "we formalize the cross-lingual gap in terms of bias-variance decomposition."
- Categorical distribution: A probability distribution over a finite set of categories used for sampling discrete outputs. "LLMs finally sample a response \hat{y} via a categorical distribution parameterized by softmax transformation of logits."
- Chi-squared distance: A measure of divergence between discrete probability distributions. "we plot the average Chi-squared distance"
- Closed-book QA: Question answering without access to external tools, retrieval, or context beyond the prompt. "knowledge-intensive tasks in a closed-book QA setting"
- Confidence: The probability that a sampled response equals the mode of the distribution. "We refer to probability of a sample matching the mode as confidence"
- Confidence region: A plotted region expressing uncertainty around an estimate (e.g., a best value). "We also plot the best possible L2 distance along with confidence region as the oracle in the plot."
- Entropy: A measure of uncertainty in a probability distribution; higher entropy indicates flatter probabilities. "softmax() is flat (i.e., has high entropy)."
- Forward pass stochasticity: Randomness during inference arising from computation or routing variability. "forward pass stochasticity sufficiently capture the response variance"
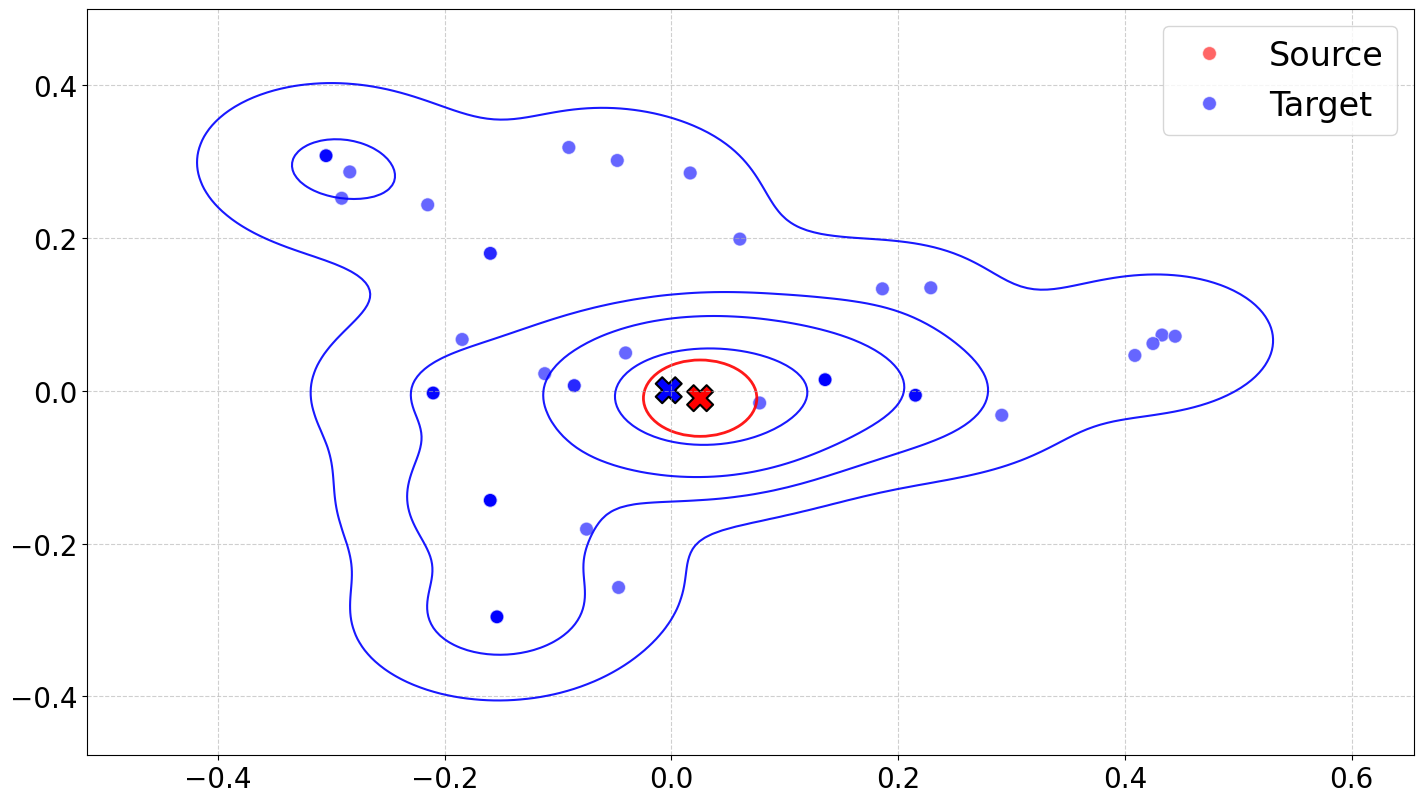
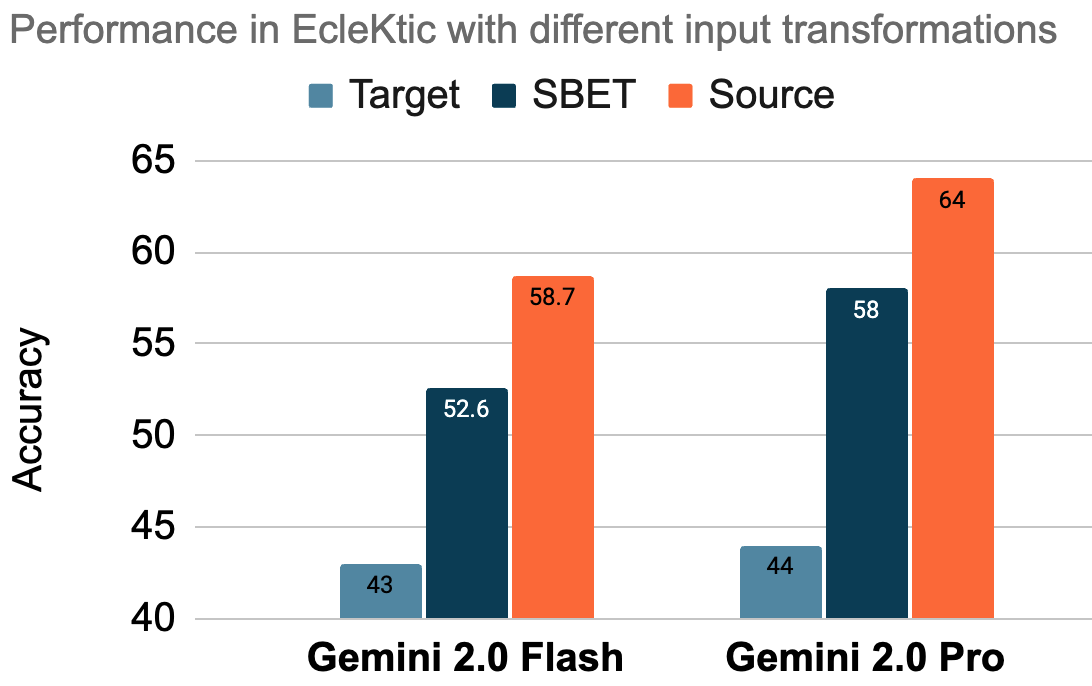
- In-distribution: Data similar to what the model was trained on, typically yielding more reliable performance. "Prompts in the source split are (roughly) in-distribution with pretraining data"
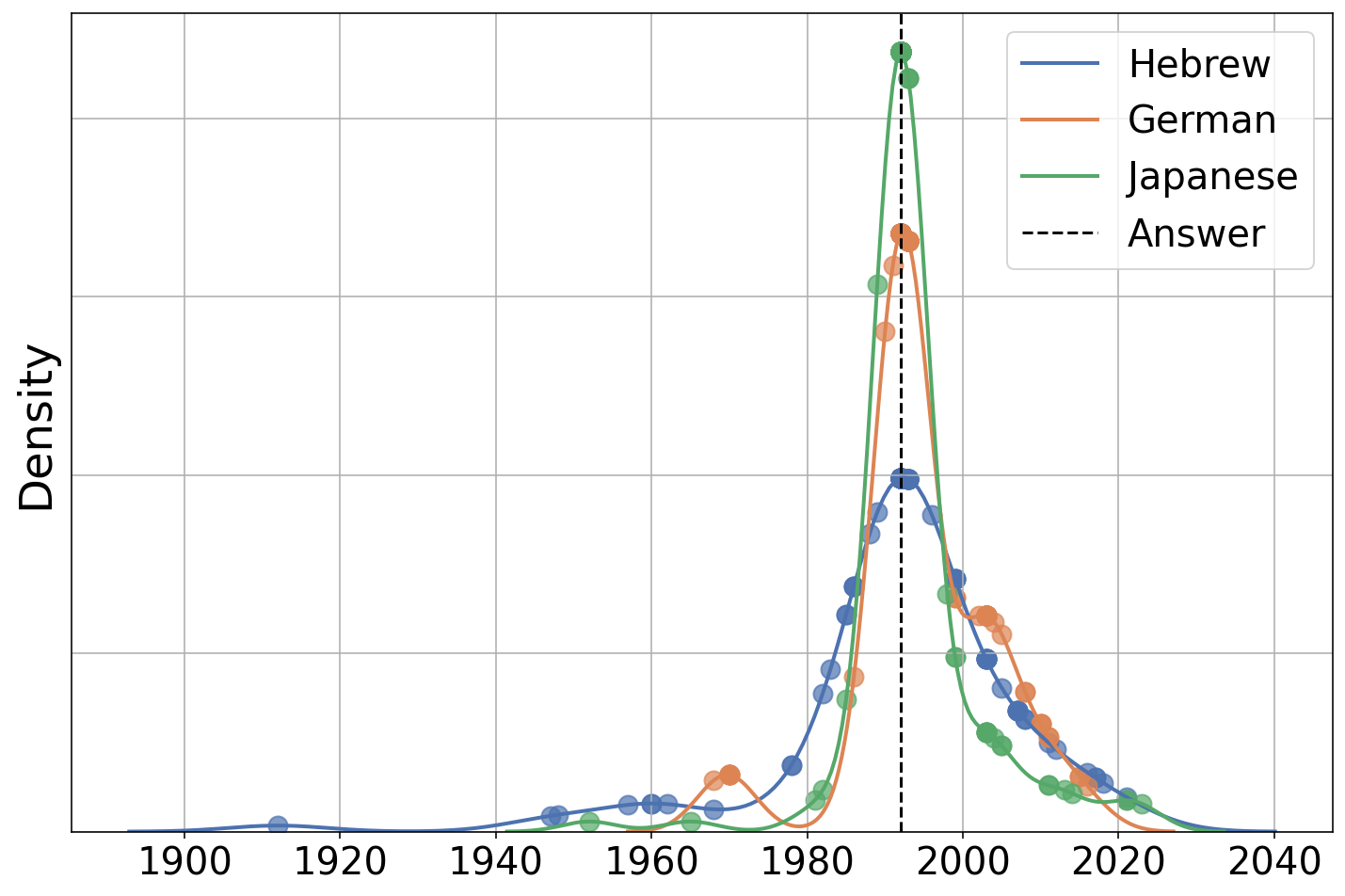
- Kernel Density Estimation (KDE): A nonparametric method to estimate a continuous probability density from samples. "We show KDE fitted distribution for three target languages"
- L2 distance: The Euclidean distance between vectors, commonly used to compare embeddings. "we compute the L2 distance between average embedding of responses"
- Latent representations: Hidden vector encodings learned by models that capture underlying structure or meaning. "divergence in latent representations in source and target languages"
- LLM-as-judge: Using an LLM to automatically rate or evaluate the correctness of another model’s outputs. "Responses on ECLeKTic are freeform text, which we rate using LLM-as-judge."
- Logits: Pre-softmax scores produced by a model that determine output probabilities after normalization. "An LLM model M projects an input to its logits ."
- Majority voting: Aggregation that selects the most frequent answer among multiple model outputs. "using the majority voted response from N responses"
- Mixture-of-Experts (MoE) routing: Mechanism that routes tokens through different expert subnetworks, introducing variability. "MoE routing uncertainties"
- Mixing coefficient (π): The parameter controlling the proportions of components in a mixture model. "with an unknown mixing coefficient: ."
- Mode: The most probable or most frequent value in a distribution. "probability of the mode of responses sampled from source and target."
- Multivariate normal distribution: A Gaussian distribution over vectors characterized by a mean and covariance. "the logits are sampled from a normal distribution with latent variables: mean , and variance ."
- Out-of-distribution: Data dissimilar to the training distribution, often causing performance degradation. "while those in the target split are out-of-distribution."
- Oracle value: A best-achievable reference value used to contextualize experimental results. "Oracle value shown in red in (a) is the best expected value."
- Principal Component Analysis (PCA): A dimensionality-reduction technique projecting data onto principal axes. "PCA projection of responses (G-2.5-Flash) in source and target"
- Response ensembling: Combining multiple model outputs to reduce variance and improve agreement across conditions. "Response ensembling from multiple forward passes gradually diminishes the source-target differences"
- Softmax: A normalization function that converts logits into a probability distribution over classes. "parameterized by softmax transformation of logits."
- Temperature (decoding): A parameter controlling randomness in sampling from model probabilities during generation. "We may better suppress the response variance with temperature set to zero"
- Transfer score: A metric measuring how often answers are correct in both source and target languages. "we show the transfer score for our ablations on various models."
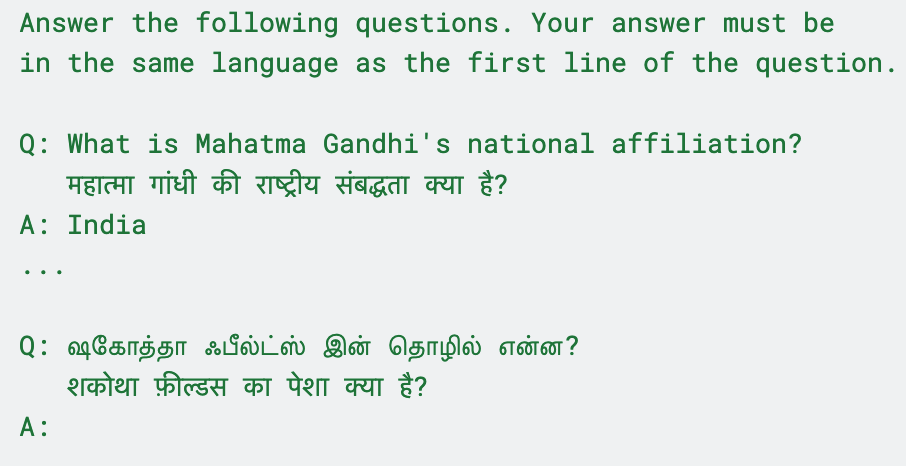
- Translate-then-Answer (TTA): An approach where the model first translates the question(s) and then produces the answer. "We refer to the approach as Translate-then-Answer (TTA)."
- Translation Ensemble (TrEn): Presenting multiple translations of a question within one prompt to stabilize the answer. "We introduce an ablation called Translation Ensemble (TrEn-k)"
- Unsupervised Domain Adaptation (UDA): Adapting models from labeled source domains to unlabeled target domains. "Cross-lingual gaps are a special case of UDA where the domain is defined by the language."
Collections
Sign up for free to add this paper to one or more collections.

