Language Models are Injective and Hence Invertible
Abstract: Transformer components such as non-linear activations and normalization are inherently non-injective, suggesting that different inputs could map to the same output and prevent exact recovery of the input from a model's representations. In this paper, we challenge this view. First, we prove mathematically that transformer LLMs mapping discrete input sequences to their corresponding sequence of continuous representations are injective and therefore lossless, a property established at initialization and preserved during training. Second, we confirm this result empirically through billions of collision tests on six state-of-the-art LLMs, and observe no collisions. Third, we operationalize injectivity: we introduce SipIt, the first algorithm that provably and efficiently reconstructs the exact input text from hidden activations, establishing linear-time guarantees and demonstrating exact invertibility in practice. Overall, our work establishes injectivity as a fundamental and exploitable property of LLMs, with direct implications for transparency, interpretability, and safe deployment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary: “LLMs are Injective and Hence Invertible”
1) What is this paper about?
This paper looks at how modern LLMs (like GPT-style Transformers) handle the text you give them. Most people think these models “squish” information as it moves through layers, meaning different inputs could end up looking the same inside the model. The authors show the opposite: for normal, real-world settings, different input texts lead to different internal states. In other words, the model’s internal “memory” after reading your text is a unique fingerprint of that text. Even better, they show you can use that internal state to recover the original text exactly.
2) What questions are the authors trying to answer?
- Do two different prompts (inputs) ever produce the exact same hidden state inside a Transformer? If they did, that would be a “collision.”
- Is this “no-collisions” property true not just at the start, but also after training?
- If the internal states are unique fingerprints, can we reliably reverse them to get back the exact original text?
In simple terms: Is each input text matched to one unique internal state (one-to-one)? And if so, can we use that to reconstruct the input?
3) How did they study it? (Methods in everyday language)
Think of a Transformer as a machine that turns a sentence into a detailed “brain state” it uses to predict the next word. The authors do three things:
- Math proof: They treat each part of the Transformer (like attention, LayerNorm, and activation functions) as smooth, well-behaved operations. Using tools from calculus, they show that “collisions” (two different texts producing exactly the same final internal state) are so rare that, with normal random starting weights and normal training, they basically never happen. A helpful analogy: imagine throwing a dart at an enormous wall. The set of points that would cause a collision is thinner than a hairline crack—you will almost surely miss it.
- Training doesn’t break it: They also show that ordinary training (gradient descent) won’t push the model into that tiny “hairline crack” where collisions could happen. So the one-to-one property survives training.
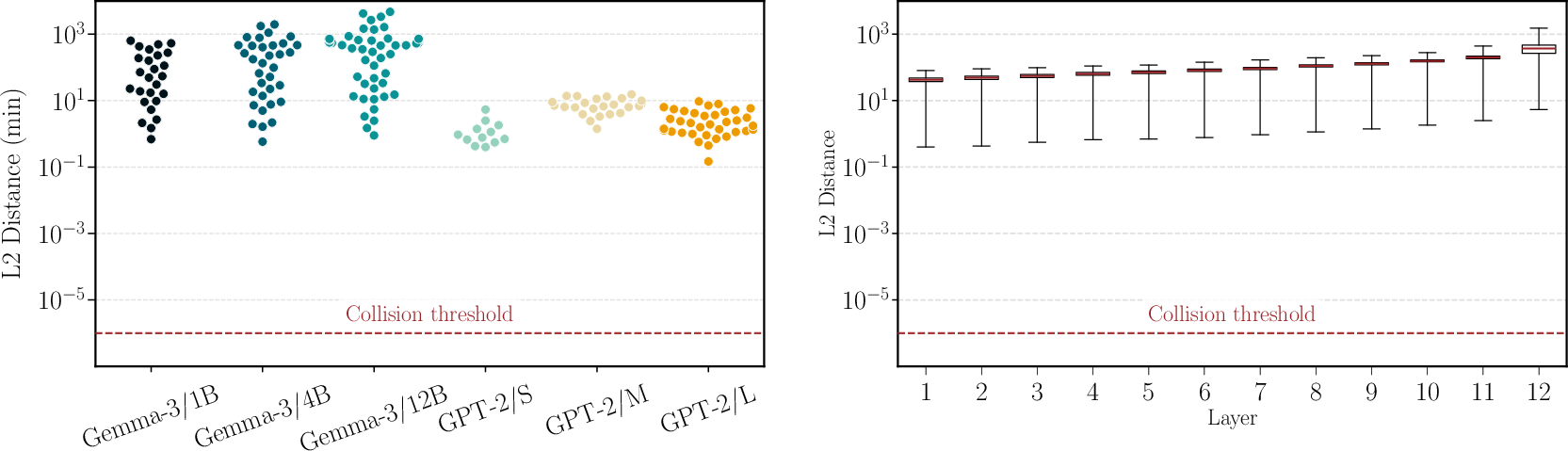
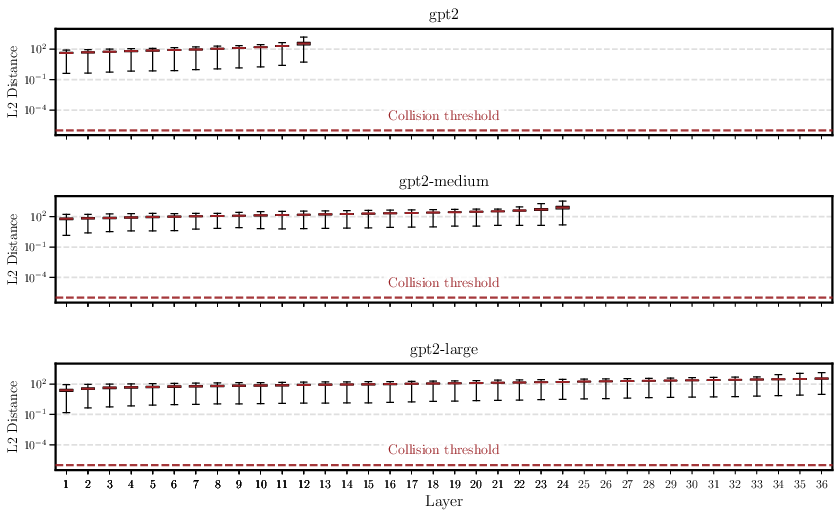
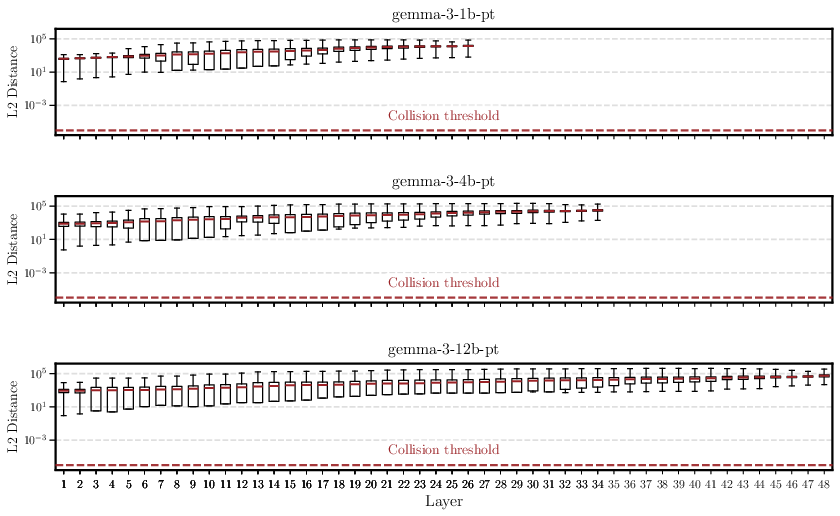
- Experiments: They test this idea on several popular models (like GPT-2, Gemma, Llama, Mistral, Phi, and TinyStories). They take 100,000 prompts and compare billions of pairs of internal states to look for any exact matches. They find none.
Finally, they build a practical algorithm called SipIt. It uses the model’s own behavior to recover the original prompt from the internal states, step by step:
- At each position in the text, it tries possible next tokens (like “a,” “the,” “cat,” etc.), checks which one reproduces the observed internal state, and picks that one.
- Because each token choice leaves a unique internal “fingerprint,” this works like trying keys in a lock until one fits—but in practice, the right key stands out clearly and quickly.
4) What did they find, and why does it matter?
Main findings:
- Transformer LLMs are injective with respect to prompts: different prompts almost surely produce different internal states (no collisions).
- This remains true at initialization and after normal training.
- Their SipIt algorithm can exactly reconstruct the full input prompt from hidden activations, efficiently. In tests, it got 100% exact recovery and ran much faster than brute-force methods.
Why it matters:
- Transparency and interpretability: If each internal state uniquely identifies the input, then the model isn’t “forgetting” or “blurring” the prompt inside. That makes it easier to analyze what the model is doing and to trust probes that read information from hidden layers.
- Safety and privacy: Hidden states are essentially the prompt in disguise. If a system stores or shares hidden states, it is effectively storing or sharing the original text. This has big implications for privacy and data protection rules.
5) What is the impact of this research?
- Rethinking assumptions: People often assume Transformers throw away information because of non-linear parts and normalization. This paper flips that idea. For real-world models, the map from text to final internal state is one-to-one and thus invertible.
- Practical tools: SipIt shows you can actually recover the exact text from hidden states quickly. That’s powerful for auditing and understanding models.
- Policy and privacy: Since hidden states fully encode the input, companies and policymakers should treat them like sensitive user data.
- Future directions: The authors suggest exploring invertibility in multimodal models (like text+images), studying how noise or quantization affects recovery, and using invertibility to build better interpretability and safety tools.
In short: Transformer LLMs don’t mash inputs together—they keep them uniquely identifiable inside. And with the right method (SipIt), you can reconstruct the original text exactly. This changes how we think about transparency, interpretability, and privacy in AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains uncertain, missing, or unexplored in the paper, framed to be actionable for future research.
- Scope of architectures: results are proven only for causal, decoder‑only Transformers; it is unknown whether injectivity (and SipIt invertibility) holds for encoder‑only (e.g., BERT), encoder‑decoder (seq2seq), retrieval‑augmented models, and multimodal Transformers (vision, audio, video).
- Non‑analytic components: guarantees rely on real‑analyticity; many practical components are non‑analytic (e.g., ReLU/LeakyReLU, hard MoE routing, top‑k selection, discrete token filters, quantized ops). Formal extensions or counterexamples for these components are missing.
- Optimizer coverage: the preservation‑under‑training theorem is stated for GD/SGD; there is no proof for common optimizers (
Adam,AdamW,Adafactor,Lion), nor for techniques like weight decay, gradient clipping, EMA, and mixed‑precision updates. Conditions ensuring absolute continuity under these updates need to be established. - Step‑size assumptions: the training guarantee assumes step sizes in (0, 1) without linking this bound to the loss Hessian or model Lipschitz constants. Clarifying and generalizing step‑size conditions (including schedules, per‑parameter LRs, trust‑region/second‑order methods) is an open task.
- Finite precision effects: theory assumes real arithmetic; practical inference/training uses
float16/bfloat16and 8‑bit quantization. The impact of finite precision on injectivity and the probability of near‑collisions is not analyzed; probabilistic bounds and robust epsilon selection for SipIt are needed. - Quantization and compression: inference often uses weight/activation quantization, KV cache compression, and low‑rank adapters. How these non‑analytic or lossy steps affect injectivity and exact inversion is unstudied.
- Dropout and stochastic layers: training often includes dropout, stochastic depth, and randomized routing. The update‑map analyticity and absolute continuity preservation under such randomness (especially when masks are discrete) is not addressed.
- Positional encodings: the proofs assume analytic positional signals; the effect of specific schemes (RoPE, ALiBi, learned absolute/relative positions) on injectivity, especially with tied or degenerate positions, is not formally characterized.
- MoE and routing at inference: modern LLMs use mixture‑of‑experts with hard routing at inference. Whether injectivity holds (or can be made to hold) under discrete expert selection remains open.
- LayerNorm variants: guarantees hinge on LayerNorm with ε > 0; the behavior under RMSNorm or other normalization schemes (and ε choices) is not formally proven.
- Infinite training horizon: results cover any finite number of steps; whether long training or convergence dynamics can drive parameters onto measure‑zero collision sets (e.g., via symmetries or implicit bias) is unknown.
- LoRA/weight tying/sharing: practical fine‑tuning (LoRA) and architectural choices (weight tying, shared projections) may constrain parameter manifolds. Formal injectivity guarantees under such constraints are missing.
- Failure‑case mitigation: the paper notes engineered collisions (identical embeddings/positions) but does not provide detection or training‑time regularizers to avoid near‑identical embeddings or positional degeneracies.
- Empirical breadth: collision tests are limited in prompt count, models, and tokenizers; they do not include the largest modern LLMs (e.g., Llama‑3.1‑70B, Mixtral‑MoE), multilingual settings, or code‑heavy vocabularies. Larger‑scale, cross‑language, and cross‑tokenizer studies are needed.
- Collision thresholds and margins: experiments adopt a collision threshold (e.g., 1e‑6) but do not derive theoretical separation margins or margin scaling laws (vs. depth, width, heads). Layer‑wise lower bounds would enable principled
εselection for SipIt. - Near‑collisions: the practical risk and frequency of “near‑collisions” (very small L2 distances) and their consequences for inversion reliability are not quantified; robustness analyses under numerical noise and adversarial prompts are needed.
- SipIt input requirements: SipIt’s linear‑time guarantee assumes access to all per‑position hidden states at a given layer and model parameters/gradients; inversion when only the last‑token state, logits, or probability vectors are available remains open (efficient algorithms beyond brute force are not provided).
- Unknown sequence length: SipIt presumes known sequence length T and per‑position states. Methods to infer T and recover inputs from partial/aggregated states (e.g., last state alone) are not developed.
- Scalability: worst‑case SipIt complexity is O(T·|V|) forwards (each through up‑to‑ℓ layers); for large vocabularies (~100k), long contexts (e.g., 4k), and deep networks, practical feasibility and acceleration strategies (candidate pruning, KNN in hidden space, logit‑guided filters) need systematic evaluation and theory.
- Gradient‑guided policy: the design, guarantees, and expected candidate trials of the gradient‑guided selection policy are not analyzed; sensitivity to gradient noise, mixed precision, and checkpointing requires study.
- Robust inversion under perturbations: guarantees are exact only under noiseless states; inversion behavior under noise, masking, caching, or partial state visibility is unexplored.
- Privacy and mitigation strategies: while the paper highlights privacy risks, it does not propose or analyze countermeasures (noise injection, randomized routing, architectural changes) that break invertibility with minimal impact on performance; formal privacy–utility trade‑offs are needed.
- Security implications: concrete attack models that exploit hidden‑state leakage and practical defenses (e.g., red‑teaming, detection of inversion attempts) are not provided.
- Formalization of “local verifier”: key constructs (e.g., the set A_{π,t}(v_j; ε) and verification criteria) are referenced but not fully specified in the main text; a rigorous characterization and its numerics (tolerance selection, false‑positive/negative rates) should be detailed.
- Generalization across tokenization schemes: different BPE/Unigram tokenizers and vocabularies (including byte‑level and multilingual) may affect injectivity/separability; systematic analysis is missing.
- Relationship to softmax bottleneck and output layer: injectivity is proven for hidden states; how the output head and softmax bottleneck interact with invertibility (e.g., logit exposure vs hidden exposure) warrants deeper study.
Glossary
- Absolute continuity: A property of probability distributions that have densities and assign zero mass to measure-zero sets; crucial for showing training updates don’t concentrate on collision sets. "At initialization, \bm{\theta}_0 is drawn from a distribution with a density, hence absolutely continuous."
- Absolute positional embeddings: Position representations that encode the absolute index of each token; equality of two such embeddings can be used to construct collisions. "Likewise, if two absolute positional embeddings are made exactly equal and the remaining weights are tuned to suppress other positional signals, one can force collisions between sequences that differ only at those positions."
- Attention head: A subcomponent of multi-head attention that computes its own query/key/value projections and attention output. "at least one attention head per block"
- Causal attention: Attention mechanism restricted so each position attends only to earlier positions, enforcing autoregressive causality. "LayerNorm with , causal attention, MLPs with analytic activations, residuals"
- Causal decoder-only Transformer: A Transformer architecture composed solely of decoder blocks with causal masking, used for next-token prediction. "causal decoder-only Transformer LLMs are injective almost surely."
- Causal structure: The architectural property that the state at position t depends only on the prefix and current token, enabling sequential inversion. "The algorithm exploits the causal structure of Transformers"
- Collision: The event where two distinct inputs map to the exact same internal representation. "collisions (two different prompts producing the exact same representation)"
- Embedding width: The dimensionality of token embeddings in the model. "with embedding width , at least one attention head per block, real-analytic components, finite vocabulary , and finite context length ."
- Finite-horizon guarantee: A result that holds after any fixed finite number of training steps, rather than asymptotically. "The end result is a finite-horizon guarantee: after any fixed number of training steps, and under mild assumptions, injectivity holds with probability one."
- GELU: Gaussian Error Linear Unit; a smooth activation function commonly used in Transformers. "Assume the MLP activation is real-analytic (e.g. tanh, GELU)."
- Gradient descent (GD): An iterative optimization method that updates parameters in the direction of the negative gradient of the loss. "train for any finite number of GD steps with step sizes in ."
- Inverse Function Theorem: A theorem stating that a differentiable map with nonzero Jacobian determinant is locally invertible. "Away from that set, the Inverse Function Theorem applies: is a smooth, locally invertible change of coordinates"
- Jacobian determinant: The determinant of the Jacobian matrix of a transformation, indicating local volume change; nonzero values imply local invertibility. "Its Jacobian determinant is itself real-analytic and not identically zero"
- Last-token representation: The hidden state vector at the final position of a sequence, which drives next-token prediction and serves as the target for injectivity. "different prompts yield different last-token representations"
- LayerNorm: Layer normalization; normalizes activations using per-example statistics, implemented with a small epsilon for numerical stability. "LayerNorm with "
- Lebesgue measure: The standard measure on Euclidean space used in real analysis to formalize volume and measure-zero sets. "zero set has Lebesgue measure zero"
- Measure zero: A set of parameters with zero Lebesgue measure; events confined to such sets occur with probability zero under continuous distributions. "collisions can only occur on a set of parameter values that has measure zero"
- MLP: Multi-Layer Perceptron; the feedforward subnetwork in Transformer blocks. "MLPs with analytic activations"
- One-step map: The mapping from a candidate next token to the hidden state at the current position given a fixed prefix. "we can look at the ``one-step'' map"
- Positional encodings: Signals added to embeddings to encode token positions, enabling order-aware attention. "embeddings, positional encodings, LayerNorm with , causal attention"
- Quantization: Converting continuous values to discrete levels; a non-analytic choice that can induce collisions. "collisions can arise (through deliberate non-analytic choices such as quantization or tying)"
- Real-analytic: A function equal to its Taylor series in a neighborhood; strong smoothness used to characterize collision sets. "the map (\mathrm{s},\bm{\theta}) \mapsto \mathbf{r}(\mathrm{s} \,;\, \bm{\theta}) \in \mathbb{R}d is real-analytic jointly in the parameters and the input embeddings."
- Real-analyticity: The property/assumption that model components are real-analytic in parameters, enabling measure-zero collision results. "Real-analyticity. Each component of the architecture (embeddings, positional encodings, LayerNorm with , causal attention, MLPs with analytic activations, residuals) is real-analytic in its parameters"
- Residual wiring: Skip connections that add a layer’s input to its output, structuring the flow of information. "components (embeddings, LayerNorm, causal attention, MLPs, and residual wiring)"
- SipIt: Sequential Inverse Prompt via Iterative updates; an algorithm that recovers exact input text from hidden activations efficiently. "we introduce SipIt, the first algorithm that provably and efficiently reconstructs the exact input text from hidden activations"
- Softmax bottleneck: The limitation that a linear-softmax output layer cannot represent all possible distributions, constraining model expressivity. "the {softmax bottleneck} constrains the distributions reachable by LLMs"
- Softmax cross-entropy loss: A standard training loss combining softmax normalization with cross-entropy, used for next-token prediction. "Because the network and the softmax cross-entropy loss are real-analytic, is also real-analytic."
- Surjective: A mapping that covers its codomain; every possible output has at least one input. "show that building blocks of modern architectures are almost always surjective"
Practical Applications
Immediate Applications
The following applications can be deployed with current tooling and infrastructure, given access to model parameters and hidden activations (or by adapting operational practices to treat hidden activations as sensitive data).
- Activation-level privacy controls for LLM serving
- Sector: healthcare (HIPAA), finance (GLBA/SOX), enterprise SaaS, government
- What: Treat hidden states (including KV caches and layer activations) as equivalent to plaintext prompts. Implement ephemeral storage, strict access controls, encryption at rest/in transit, and zeroization of GPU/CPU memory after inference. Prohibit logging or exporting hidden states to third-party services or plugins.
- Tools/products/workflows: “ActivationGuard” library, secure KV-cache manager, inference pipelines with configurable retention TTLs and audit logs for activation access, secret-scoped plugin interfaces that pass tokens (not activations).
- Assumptions/dependencies: Access to model internals during serving; injectivity holds for standard decoder-only Transformers; inference runs without dropout; quantization/noise may undermine guarantees.
- Compliance and risk management updates for regulated deployments
- Sector: healthcare, finance, education, public sector
- What: Update internal data-classification policies to explicitly categorize hidden activations as personal/sensitive data; revise retention schedules; ensure right-to-erasure procedures cover inference caches; add DPIA (Data Protection Impact Assessment) entries for activation handling.
- Tools/products/workflows: Compliance playbooks, policy templates, internal audit controls that track activation storage and deletion events.
- Assumptions/dependencies: Organizational buy-in; ability to observe/control activation lifecycle.
- Prompt fingerprinting for cache deduplication and content-addressable inference
- Sector: large-scale LLM serving, developer tooling
- What: Use last-token representations (or derived stable hashes) as unique prompt identifiers to deduplicate caching and avoid redundant recomputation; enable deterministic reproduction of runs.
- Tools/products/workflows: “PromptHash” service keyed per-model-version; cache indexers; replay tooling.
- Assumptions/dependencies: Injectivity guarantees are model-version-specific and do not transfer across model updates; hashes should be derived from activations without storing raw activations to mitigate privacy risk.
- Mechanistic interpretability and causal tracing baselines
- Sector: academia, ML research, safety
- What: Use SipIt to confirm exact input recoverability from hidden states, establishing a baseline that any failure in probing or causal attribution is due to analysis limitations rather than information loss. Validate the locality of information across layers.
- Tools/products/workflows: SipIt-based interpretability toolkit; layer-by-layer inversion tests; causal intervention pipelines.
- Assumptions/dependencies: Access to hidden states and weights; real-analytic components (e.g., GELU/LN with ε>0).
- Privacy red-teaming and DLP auditing on activation logs
- Sector: software, governance, security
- What: Audit existing inference logs and telemetry for inadvertent storage/sharing of hidden states; reconstruct prompts via SipIt to assess data leakage exposure; enforce DLP gates before any activation export.
- Tools/products/workflows: “ActivationAudit” suite; CI/CD checks blocking activation serialization; a red-team playbook to demonstrate prompt exfiltration risks.
- Assumptions/dependencies: Availability of activation logs; model weights/tokenizer; consent/authorization for audits.
- Debugging and incident forensics (with strict governance)
- Sector: software/ML Ops
- What: Reconstruct lost or corrupted prompts from activation snapshots during crash dumps to reproduce issues; remediate bugs affecting request pipelines.
- Tools/products/workflows: SipIt CLI integrated into debuggers; incident-response runbooks; secure vault storage for temporary activation snapshots with auto-deletion.
- Assumptions/dependencies: Legal/ethical approval; restricted access; exact hidden states (or within tolerance).
- Secure agent and plugin architecture
- Sector: software, developer platforms
- What: Redesign interfaces so agents/plugins never receive hidden activations; use token-level context passes or abstracted summaries; prevent third-party tools from deriving prompts via inversion.
- Tools/products/workflows: Plugin API contracts; “least information” data-sharing policies; activation redaction middleware.
- Assumptions/dependencies: Architectural control over integrations; potential performance trade-offs.
- Prompt-provenance records without storing plaintext
- Sector: enterprise, compliance, reproducibility
- What: Record cryptographic hashes of last-token states to attest that a specific prompt was used, enabling traceability without storing the prompt itself.
- Tools/products/workflows: “PromptProof” ledger; reproducibility metadata embedded in experiment tracking.
- Assumptions/dependencies: Hashing design must avoid enabling inversion from hashes; model-version specificity; risk assessment of hash-to-prompt correlation.
Long-Term Applications
These require further research, scaling, architectural change, or hardware support.
- Privacy-preserving Transformer designs that intentionally break injectivity
- Sector: software, safety, privacy tech
- What: Introduce controlled non-analytic components, quantization, or calibrated noise to reduce exact invertibility of hidden states while maintaining task performance; provide “privacy knobs” to tune invertibility-risk vs. accuracy.
- Tools/products/workflows: “Privacy-Preserving LN,” keyed or randomized positional encodings, invertibility-budget monitoring.
- Assumptions/dependencies: Careful analysis of utility–privacy trade-offs; retraining and eval on downstream tasks.
- Encrypted activations and secure hardware support
- Sector: cloud, semiconductors, enterprise
- What: Compute/store activations inside TEEs or use activation-level encryption; develop GPU/accelerator features for secure KV-cache handling and memory isolation to prevent exfiltration by co-tenants.
- Tools/products/workflows: Confidential inference stacks; secure KV-cache engines; hardware-backed isolation.
- Assumptions/dependencies: Performance overhead; availability of TEEs on accelerators; key management.
- Regulation and standards evolution recognizing activations as personal data
- Sector: policy/regulatory
- What: Update interpretations under GDPR/CCPA/HIPAA to explicitly cover hidden activations as personal data at inference; define retention, access, and deletion obligations for caches and telemetry; codify secure logging standards.
- Tools/products/workflows: Sector-specific compliance frameworks, certification schemas, audit checklists for LLM activation handling.
- Assumptions/dependencies: Multi-jurisdictional coordination; industry consensus.
- Keyed inversion control and provenance protection
- Sector: privacy/security
- What: Architectures where only authorized parties (holding a key) can invert activations (e.g., keyed positional encodings or activation transforms), enabling forensic recovery while preventing adversarial exfiltration.
- Tools/products/workflows: “PromptLock” keyed transforms; policy-bound keys; forensic access gates.
- Assumptions/dependencies: Cryptographic design; resilience against side-channel attacks; training compatibility.
- Noise-robust and compressed-cache inversion
- Sector: Ops, forensics
- What: Extend SipIt to operate under activation compression, quantization, or noisy telemetry; build practical tools for crash analysis where only partial/approximate states are available.
- Tools/products/workflows: Robust SipIt variants; activation denoising pipelines.
- Assumptions/dependencies: New algorithms; calibration of recovery confidence; legal guardrails.
- Multimodal inversion (text–vision–audio)
- Sector: healthcare imaging, robotics, media
- What: Generalize injectivity analysis and inversion techniques to multimodal Transformers, assessing privacy risk for image/audio tokens and cross-modal prompts.
- Tools/products/workflows: Multimodal SipIt; modality-specific privacy audits.
- Assumptions/dependencies: Architectural differences (encoders vs. decoders); modality tokenization; real-analyticity conditions.
- Black-box leakage quantification and defenses
- Sector: security, safety
- What: Measure how much input information can be recovered from outputs/logits/logprobs alone; design serving policies that minimize informational leakage while preserving utility.
- Tools/products/workflows: Leakage meters; output-sanitization policies (e.g., reduced logprob exposure).
- Assumptions/dependencies: Trade-offs with debugging and evaluation; adversarial threat modeling.
- Secure multi-tenant LLM serving standards
- Sector: cloud platforms
- What: Define isolation, monitoring, and incident response standards that prevent cross-tenant activation access and ensure prompt confidentiality in shared environments.
- Tools/products/workflows: Tenant isolation benchmarks; memory hygiene standards; compliance attestation.
- Assumptions/dependencies: Platform support; performance impacts; certification processes.
Cross-cutting assumptions and dependencies
- Architectural scope: Results apply to standard decoder-only Transformers with real-analytic components (e.g., GELU, LayerNorm with ε>0), finite vocabulary and context length; training steps using gradient descent with step sizes in (0,1).
- Access: Exact inversion via SipIt assumes access to the model weights, tokenizer, positional encodings, and the relevant hidden states; black-box scenarios require different methods and may yield only approximate recovery.
- Robustness: Quantization, deliberate parameter tying, or added noise can break injectivity or reduce recoverability; hardware noise and compressed caches may necessitate robust variants of SipIt.
- Model-version specificity: Prompt fingerprints and inversion behavior are specific to the exact model version; updating weights invalidates identifiers and may change distances.
- Governance: Any use of inversion for debugging/forensics must comply with privacy law, contractual terms, and ethical guidelines, as hidden states can contain sensitive personal data.
Collections
Sign up for free to add this paper to one or more collections.