DroneAudioset: An Audio Dataset for Drone-based Search and Rescue
Abstract: Unmanned Aerial Vehicles (UAVs) or drones, are increasingly used in search and rescue missions to detect human presence. Existing systems primarily leverage vision-based methods which are prone to fail under low-visibility or occlusion. Drone-based audio perception offers promise but suffers from extreme ego-noise that masks sounds indicating human presence. Existing datasets are either limited in diversity or synthetic, lacking real acoustic interactions, and there are no standardized setups for drone audition. To this end, we present DroneAudioset (The dataset is publicly available at https://huggingface.co/datasets/ahlab-drone-project/DroneAudioSet/ under the MIT license), a comprehensive drone audition dataset featuring 23.5 hours of annotated recordings, covering a wide range of signal-to-noise ratios (SNRs) from -57.2 dB to -2.5 dB, across various drone types, throttles, microphone configurations as well as environments. The dataset enables development and systematic evaluation of noise suppression and classification methods for human-presence detection under challenging conditions, while also informing practical design considerations for drone audition systems, such as microphone placement trade-offs, and development of drone noise-aware audio processing. This dataset is an important step towards enabling design and deployment of drone-audition systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DroneAudioset, a big collection of real audio recordings made with drones to help find people during search-and-rescue missions. Instead of only relying on cameras (which struggle in smoke, darkness, or clutter), the idea is to use microphones on drones to “hear” signs of people—like speech, screams, knocks, or footsteps. The catch: drones are extremely loud, and their own noise often drowns out important sounds. This dataset helps researchers build and test better methods for cleaning up that noise and detecting human presence.
What questions does the paper try to answer?
The authors focus on simple but important questions:
- Can we build a realistic, diverse audio dataset from drones that captures how hard it is to hear people around them?
- Which microphone positions and setups work best on a noisy drone?
- How well do today’s noise-cleaning and sound-classifying AI models work in these tough conditions?
- What practical tips can we offer for designing drone audio systems that actually work in the field?
How did they do it?
Think of a drone like a very noisy fan that also creates wind. That noise (called “ego-noise”) makes it hard to hear anything else.
To study this properly, the team:
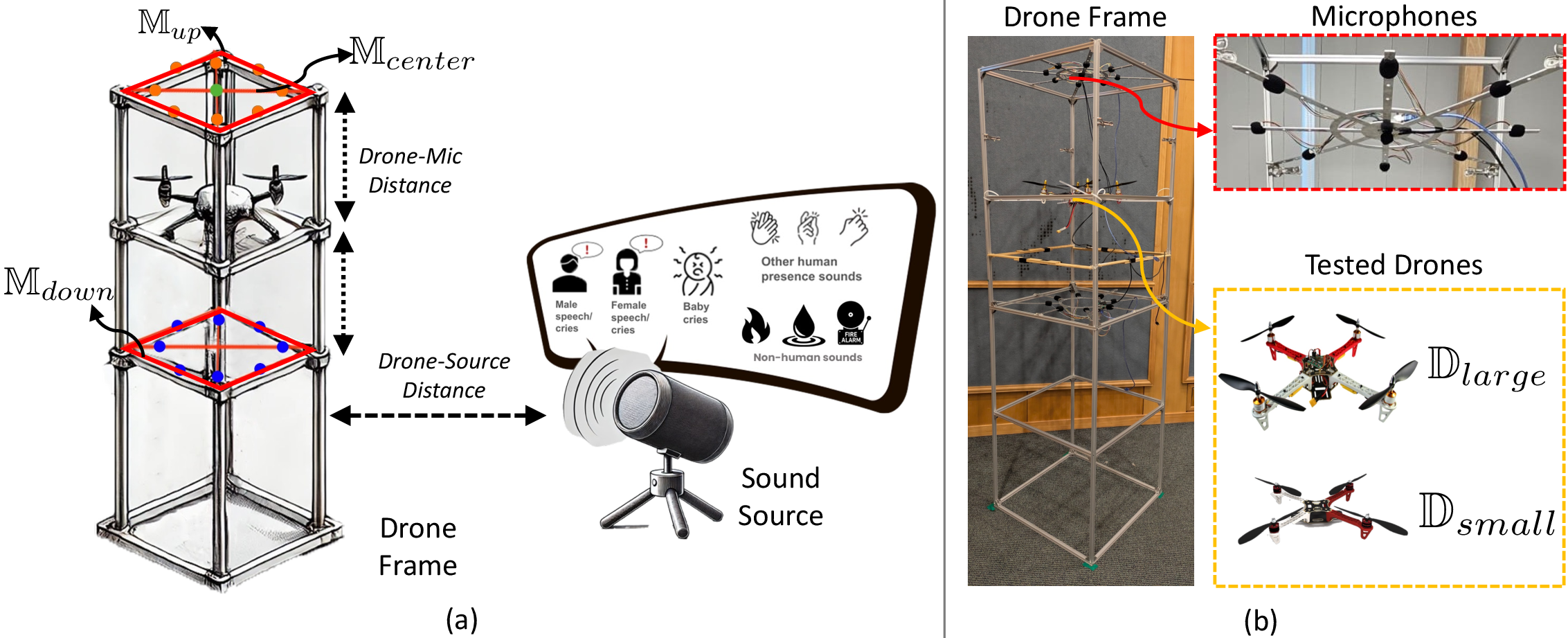
- Mounted two different drones on a sturdy frame to imitate hovering safely and consistently.
- Placed 17 microphones in different spots—above the drone, below the drone, and at different distances (25 cm and 50 cm)—including two round 8-microphone “arrays” (like having many ears) and one single microphone.
- Played different kinds of sounds from a speaker at various distances and volumes:
- Human vocal (speech, screams, crying)
- Human non-vocal (clapping, knocking)
- Non-human ambient (fire crackling, water dripping)
- Recorded:
- Drone + source together (most of the data)
- Drone noise alone
- Source sounds alone
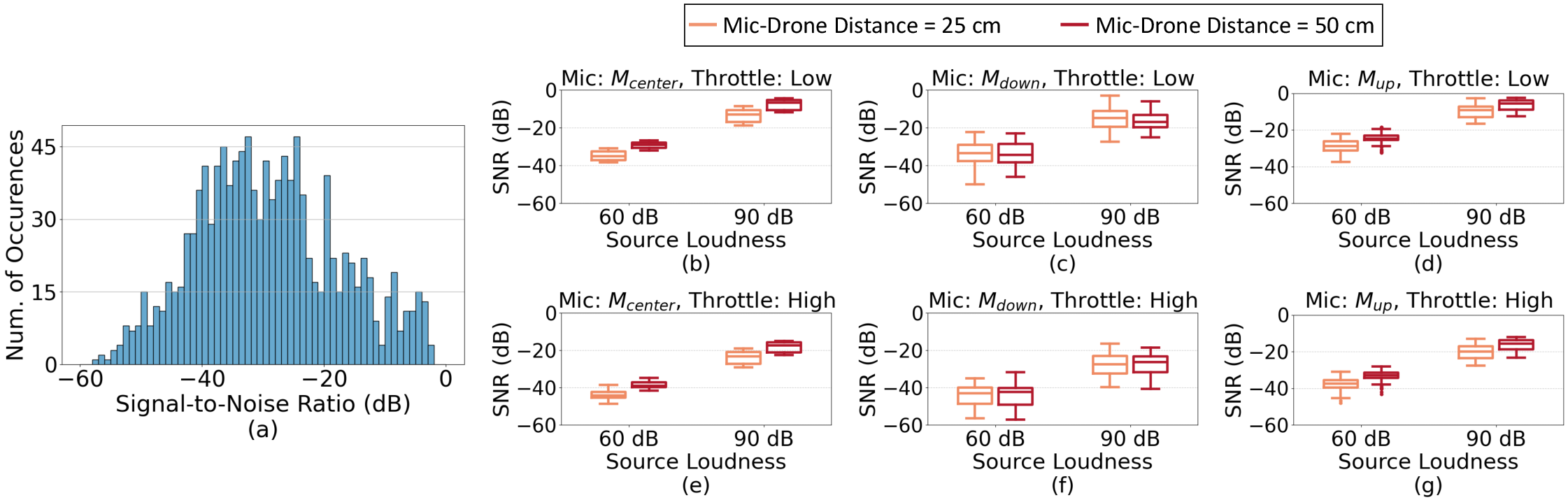
- This lets them measure how loud the signal is compared to the noise, known as the Signal-to-Noise Ratio (SNR). Negative SNR means the noise is louder than the thing you want to hear. In this dataset, SNR often ranges from about −57 dB to −2.5 dB—very tough conditions.
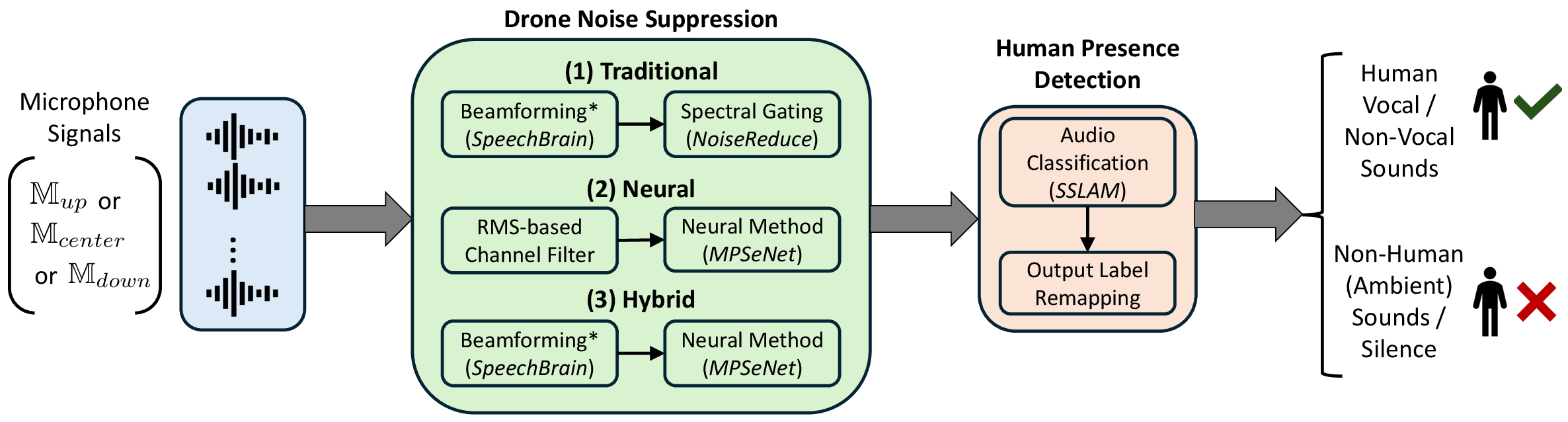
They also tested algorithms to clean the audio (“noise suppression”) and then classify it to detect human presence:
- Traditional “beamforming” (like cupping multiple ears and pointing them toward the sound you care about) plus a method that mutes quieter background noise.
- A modern AI “neural” model that tries to separate speech from noise.
- A hybrid that first beamforms, then applies the neural cleaner.
- After cleaning the audio, an audio classifier (pretrained on many everyday sounds) tries to label the sound as human vocal, human non-vocal, or non-human.
Simple translations of technical terms:
- Ego-noise: the drone’s own noise from motors and propellers.
- Beamforming: using many microphones together to “focus” on sound coming from a certain direction—like a sound flashlight.
- Neural enhancement: an AI tool that learns patterns to remove noise and keep the important sound.
- SNR (Signal-to-Noise Ratio): how loud the thing you care about is compared to the background noise. Lower (especially negative) is worse.
- SI-SDR: a score for how close your cleaned-up audio is to a clean reference; higher is better.
- F1-score: a way to measure classification accuracy that balances “how many did you catch” and “how many did you get right.”
What did they find, and why does it matter?
Here are the key takeaways:
- The dataset is large and realistic:
- 23.5 hours of audio.
- Many setups: 2 drone sizes, 2 throttle levels (low/high), 17 microphones, various positions, 3 different rooms, multiple distances and sound loudness levels.
- SNRs are very low (often negative), matching real-life difficulty.
- Noise cleaning is hard under extreme drone noise:
- AI-based cleaning generally beats traditional methods, especially when the signal is very weak.
- Even so, when the noise is extremely strong (e.g., SNR below −30 dB), all methods struggle.
- Detecting human voice works better than detecting other sounds:
- Human vocal sounds (like speech or screams) are recognized more accurately after cleaning than non-vocal human sounds (like knocks or claps) or ambient sounds.
- At higher SNR (less noise), results get closer to clean-audio performance.
- Microphone placement matters:
- Mics above the drone usually work better than mics below it because wind from the propellers hits the lower mics directly.
- Increasing the mic’s distance from the drone (from 25 cm to 50 cm) often helps.
- Multi-microphone arrays can improve results (via beamforming), but they add weight and need more processing power.
- Flight choices matter:
- Lower throttle (less propeller power) means less noise and better audio.
- The larger drone tended to allow better results than the smaller one, likely due to different noise profiles and payload options.
Why this matters: Real search-and-rescue drones can’t always “see” people, but they might “hear” them—if we design the system right. This dataset gives researchers a standard, realistic way to test their ideas and improve drone hearing.
What’s the bigger impact?
- For researchers: This is a public, realistic dataset to build better noise suppression and sound detection methods that can handle extremely noisy drone audio. It also supports studying microphone placement and system design choices.
- For engineers and rescuers: The paper offers practical guidelines:
- Prefer microphones above the drone, and place them a bit farther from the propellers.
- Use multi-mic arrays when you can afford the extra weight and power.
- Reduce throttle during “listening moments” to cut noise.
- Consider drone size and payload limits when planning audio gear.
- For society: Better drone hearing could help save lives by finding people when cameras can’t. The authors also note privacy concerns and suggest ethical safeguards.
The authors also share limits and next steps:
- Their setup simulates hovering by mounting the drone, so future work should capture real flight dynamics.
- Most recordings are indoors; outdoor recordings (with stronger wind and bigger distances) are a valuable next step.
- More diverse environments and end-to-end systems tailored to non-vocal sounds would improve performance.
In short: DroneAudioset is a solid first step toward drones that can “listen” for people in dangerous places, helping rescuers act faster and more safely.
Collections
Sign up for free to add this paper to one or more collections.