- The paper introduces the coverage profile as a key predictor for effective Best-of-N sampling, linking pre-training to improved post-training success.
- The paper shows that cross-entropy can misrepresent training quality while the coverage profile generalizes faster and more reliably.
- The paper proposes tournament-based model selection and optimizer interventions, like gradient normalization, to enhance coverage independent of sequence length.
The Coverage Principle: A Theoretical Framework for Pre-training and Post-training in LLMs
Introduction and Motivation
The paper "The Coverage Principle: How Pre-training Enables Post-Training" (2510.15020) addresses a central question in the theory and practice of LLMs: why does pre-training via next-token prediction enable effective post-training (e.g., via RLHF or Best-of-N sampling), and what properties of the pre-trained model are most predictive of downstream success? The authors argue that the standard metric—cross-entropy or KL divergence—fails to capture the aspects of pre-training that are necessary for strong post-training performance. Instead, they introduce and formalize the coverage profile as the key quantity, providing both necessary and sufficient conditions for post-training success and a new theoretical understanding of the implicit bias of next-token prediction.
The Coverage Profile: Definition and Empirical Evidence
The coverage profile $\Pcov[N](\pi)$ of a model π with respect to a data distribution μ is defined as the probability that, for a prompt x and response y sampled from μ, the model assigns at least $1/N$ of the data distribution's probability to y:
$\Pcov[N](\pi) = \mathbb{P}_{x \sim \mu, y \sim \mu(\cdot|x)}\left[\frac{\mu(y|x)}{\pi(y|x)} \geq N\right].$
This quantity directly characterizes the probability that a high-quality response can be recovered via N samples from π, and thus is tightly linked to the effectiveness of Best-of-N (BoN) sampling and RL-based post-training.
Empirical results demonstrate that the coverage profile is a significantly better predictor of BoN performance than KL divergence or cross-entropy. Notably, KL divergence can decrease monotonically during training while the coverage profile—and thus BoN performance—can degrade, indicating a disconnect between standard pre-training metrics and downstream utility.
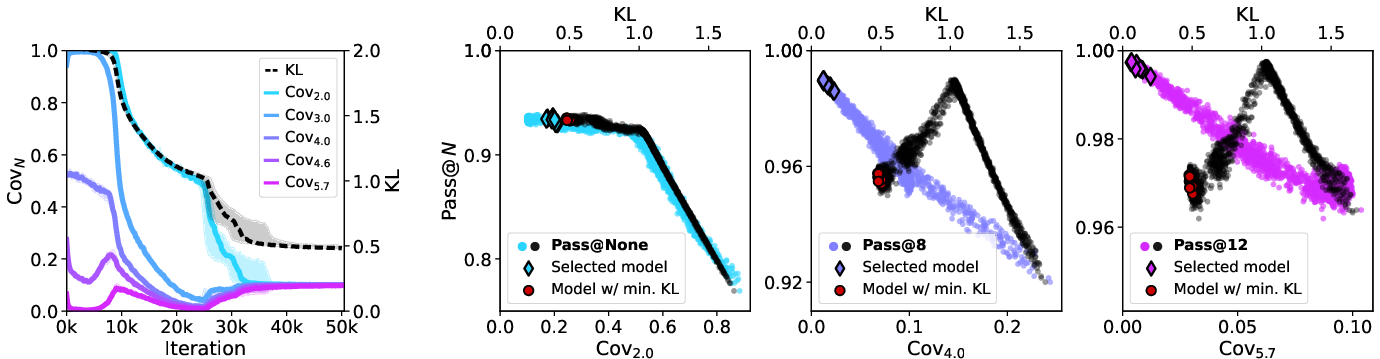
Figure 1: The coverage profile predicts passn better than KL divergence. We train models in a graph reasoning task and record KL divergence, coverage profile (both measured w.r.t., ), and passn performance; see Section 4 for details. Left: Convergence of coverage and KL divergence over training, showing that KL improves monotonically but coverage can degrade with training. Right: Scatter plots of KL (top axis), $\Pcov[N/2]$ (lower axis) and passn of checkpoints. Although KL and $\Pcov[N]$ exhibit comparable predictive power for small N, $\Pcov[N]$ is a better predictor for large N. Also visualized are checkpoints selected via the tournament procedure and by minimizing KL, demonstrating that the former selects better models for passn.
Theoretical Results: Coverage vs. Cross-Entropy
Scaling Laws and Limitations of Cross-Entropy
The authors show that while cross-entropy can be related to coverage via a simple scaling law, this relationship is vacuous in the finite-sample regime and especially for long sequences. Specifically, sequence-level cross-entropy and KL divergence scale linearly with sequence length H, leading to exponential requirements for BoN sampling as H increases. This is inconsistent with empirical findings, where models with large cross-entropy can still achieve strong BoN performance if their coverage profile is favorable.
The Coverage Principle: Fast Generalization for Coverage
A central theoretical contribution is the coverage principle: next-token prediction (maximum likelihood estimation) implicitly optimizes for good coverage, and the coverage profile generalizes faster than cross-entropy. The main theorem establishes that, for a model class Π and N≥8, the maximum likelihood estimator achieves
$\Pcov[N](\hat{\pi}) \lesssim \frac{1}{\log N} \inf_{\alpha > 0} \left\{ \frac{\log \mathcal{N}(\Pi, \alpha)}{n} + \alpha \right\} + \frac{\log \mathcal{N}(\Pi, c \log N) + \log(1/\delta)}{n},$
where N(Π,α) is the covering number of Π at scale α. The fine-grained term (scaling as 1/logN) dominates for large N and rich model classes, and crucially, this bound is independent of sequence length H—in contrast to cross-entropy-based bounds.
The analysis leverages a small-ball method, showing that the log-loss structure penalizes models with poor coverage on even a small fraction of the data, leading to rapid generalization of the coverage profile.
SGD and Optimizer Interventions for Coverage
The paper extends the analysis to practical optimization algorithms, focusing on SGD in the overparameterized regime. Standard SGD is shown to have suboptimal coverage due to its dependence on sequence length H. However, gradient normalization—either globally or per-coordinate (as in Adam or SignSGD)—removes this dependence and achieves horizon-independent coverage bounds. The authors also propose a test-time training-inspired decoding strategy, where token-level SGD is augmented with test-time gradient updates, further improving coverage and bypassing lower bounds for proper estimators.
Model Selection and Tournament Procedures
A significant practical implication is that standard model selection via cross-entropy can select checkpoints with poor coverage and thus poor BoN performance. The authors introduce tournament-based selection procedures that empirically estimate pairwise coverage between candidate models and select the one with the best worst-case coverage. These procedures are shown to select models with superior BoN performance compared to cross-entropy-based selection, especially for large N.
Implications and Future Directions
The coverage principle reframes the understanding of pre-training and post-training in LLMs. It provides a necessary and sufficient condition for post-training success via BoN or RL, explains empirical discrepancies between cross-entropy and downstream performance, and motivates new algorithmic interventions for both training and model selection.
Key implications:
- Coverage, not cross-entropy, is the critical property for post-training and test-time scaling.
- Next-token prediction is implicitly biased toward good coverage, and this bias can be amplified by appropriate optimizer choices.
- Model selection and checkpointing should be based on coverage-aware procedures, not cross-entropy.
- Theoretical results suggest that coverage generalizes rapidly, even in high-dimensional or overparameterized settings, and is robust to certain forms of model misspecification.
Speculation for future developments:
- The design of pre-training objectives, optimizers, and data curation strategies may increasingly focus on maximizing coverage for downstream tasks.
- Semantic notions of coverage, beyond the probabilistic coverage profile, may be developed to better align with human-judged quality and reasoning.
- The coverage principle may inform the development of new scaling laws that account for both pre-training and inference compute, as well as the design of RLHF and BoN-based alignment pipelines.
Conclusion
This work provides a rigorous theoretical and empirical foundation for understanding the role of coverage in the pre-training and post-training pipeline of LLMs. By identifying the coverage profile as the key predictor of downstream success and elucidating the mechanisms by which next-token prediction achieves good coverage, the paper offers actionable insights for both the theory and practice of LLM development. The results motivate a shift in both evaluation and algorithm design toward coverage-centric methodologies, with broad implications for the future of scalable and robust language modeling.

