- The paper’s primary contribution is the formulation of the ChangingGrounding task, redefining 3D visual grounding by integrating memory with active exploration in dynamic scenes.
- It presents the Mem-ChangingGrounder framework that combines large vision-language models with multi-view projection, achieving 36.8% [email protected] with reduced exploration cost.
- The approach sets a new benchmark by offering a robust trade-off between localization accuracy and exploration efficiency, with implications for real-world robotic perception.
Memory-Driven 3D Visual Grounding in Dynamic Scenes: The ChangingGrounding Benchmark and Mem-ChangingGrounder
The paper introduces a new paradigm for 3D visual grounding (3DVG) in dynamic environments, where the scene may change between observations. Traditional 3DVG methods assume access to a complete, up-to-date point cloud of the environment, which is impractical for real-world robotics due to the high cost of repeated full-scene scanning. The authors argue for a memory-driven approach, where an agent leverages past observations (memory) and selectively explores the current scene to efficiently and accurately localize objects described by natural language queries.
The ChangingGrounding task is formally defined as: given memory Mp (RGB-D images and poses) from a previous scene Sp, an unexplored current scene Sc, and a query Dc describing a target object, predict the 3D bounding box B of the target in Sc. The evaluation jointly considers localization accuracy and exploration cost, the latter measured by both the number of exploratory actions and the physical motion required.
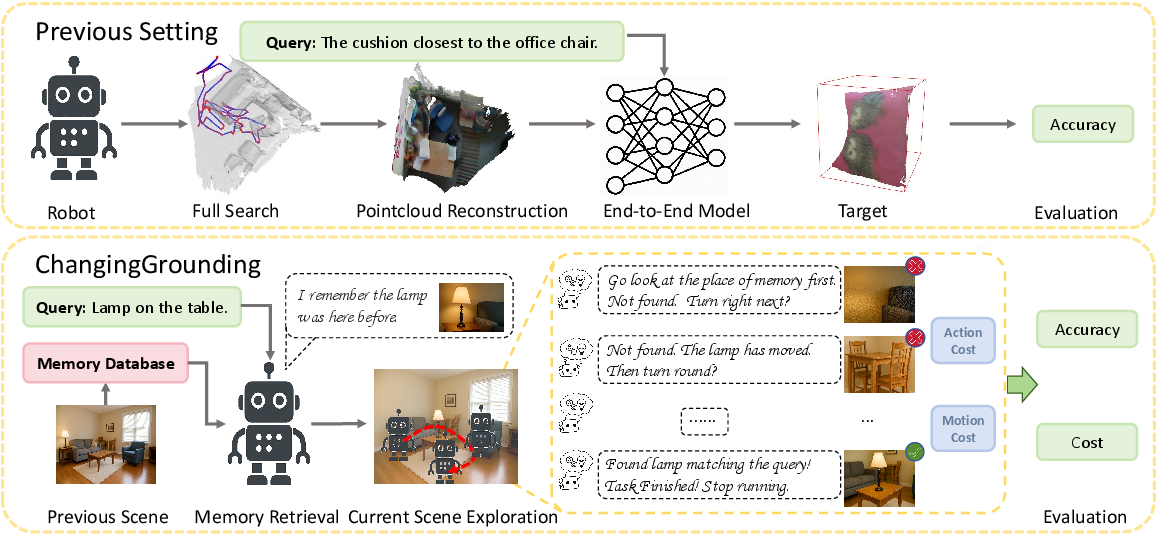
Figure 1: Comparison between the previous setting of 3DVG and the ChangingGrounding task.
ChangingGrounding Dataset and Benchmark
To support this new task, the authors construct the ChangingGrounding dataset, based on the 3RScan dataset, which provides temporally separated scans of the same indoor environments with object correspondences and transformations. The dataset generation pipeline involves:
- Generating spatial-relation-based natural language queries using a template: ⟨Target Category⟩ ⟨Spatial Relation⟩ ⟨Anchor Category⟩ (e.g., "the chair farthest from the cabinet").
- Filtering object categories and spatial relations to ensure robust, diverse, and unambiguous queries.
- Aligning all scans to a global coordinate system and rendering standardized RGB-D images for both memory and exploration.
The resulting dataset contains 266,916 referential descriptions, making it the largest and only benchmark for 3D visual grounding in changing environments.
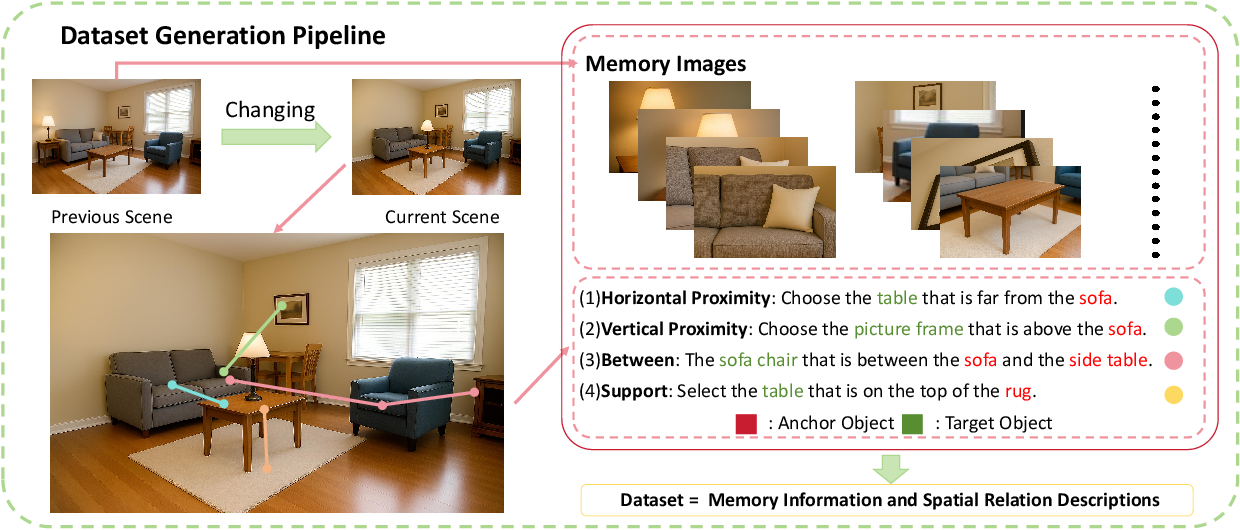
Figure 2: ChangingGrounding Dataset generation pipeline.
A word cloud of the spatial-relation descriptions highlights the diversity and frequency of object categories and relations.
Figure 3: A word cloud generated from spatial-relation descriptions, visually highlighting the frequency of occurring terms.
Mem-ChangingGrounder: A Zero-Shot Memory-Driven Baseline
The Mem-ChangingGrounder (MCG) framework is proposed as a strong zero-shot baseline for the ChangingGrounding task. MCG is designed to operate without task-specific training, instead leveraging large vision-LLMs (VLMs) and open-vocabulary detectors. The workflow consists of four core modules:
- Query Classification: Determines whether the query is verifiable (can be resolved from memory if the scene is unchanged) or unverifiable (requires exploration due to possible scene changes).
- Memory Retrieval and Grounding: Uses memory to locate anchor or target objects, then guides exploration using two action policies:
- Omnidirectional Scene Scanner (OSS): 360° scans from a pose to find anchor/target objects.
- Spatial Relation Aware Scanner (SRAS): Explores from the anchor's pose, guided by the spatial relation in the query.
- Fallback: If initial grounding fails, retrieves the clearest memory image of the target class and initiates a new search.
- Multi-View Projection: After identifying the target image, uses VLMs and SAM to segment the object, projects masks into 3D, and fuses multi-view observations for accurate bounding box estimation.
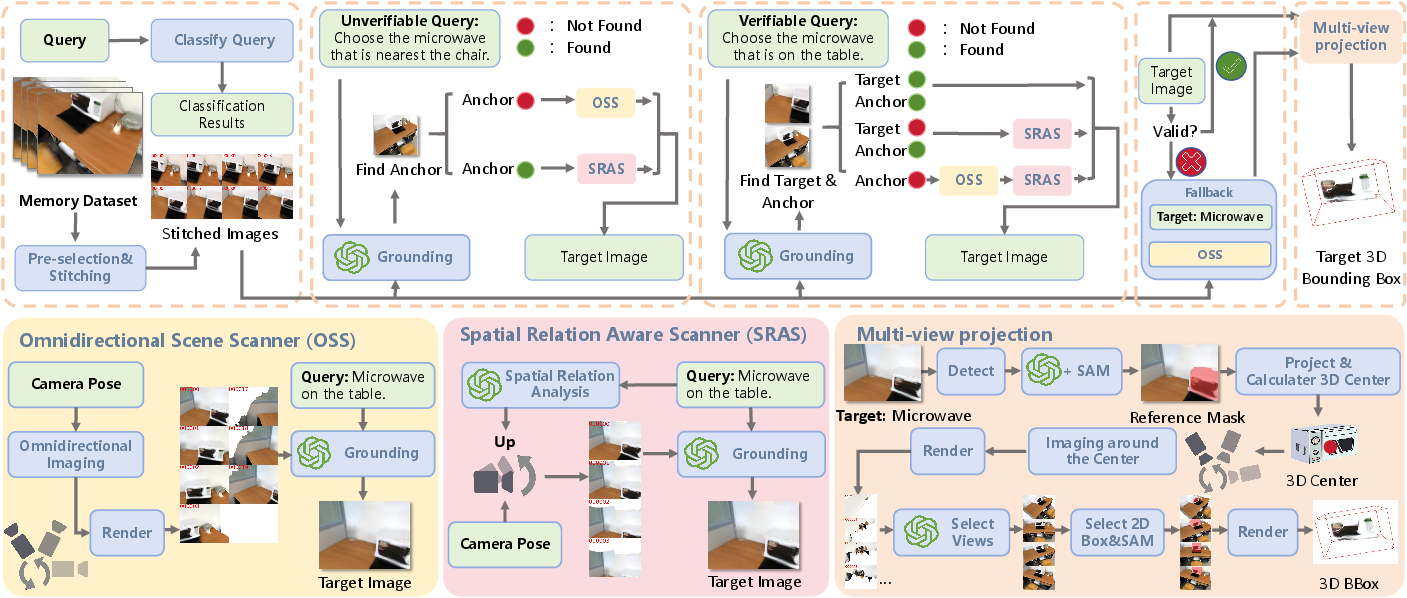
Figure 4: Workflow of Mem-ChangingGrounder (MCG). The upper part shows the overall pipeline: MCG classifies queries, retrieves memory, uses OSS and SRAS to search, applies fallback when needed, and predicts the 3D bounding box through multi-view projection. The lower part shows details of OSS, SRAS, and Multi-view Projection.
Experimental Results and Analysis
MCG is evaluated against three baselines:
- Wandering Grounding (WG): Exhaustive exploration of the current scene.
- Central Rotation Grounding (CRG): 360° rotation at the scene center.
- Memory-Only Grounding (MOG): Uses only memory, no exploration.
MCG achieves the highest localization accuracy (36.8% [email protected] in high-res) while maintaining significantly lower exploration cost compared to WG. CRG and MOG have lower costs but substantially reduced accuracy, demonstrating the necessity of both memory and targeted exploration. Notably, MCG's memory-driven policy enables a favorable trade-off between efficiency and precision.
Ablation studies confirm that memory access dramatically reduces exploration cost without sacrificing accuracy, and that multi-view projection and fallback strategies further improve robustness. The choice of VLM is critical: GPT-4.1 outperforms GPT-4o, indicating that advances in VLMs directly translate to better grounding performance.
Failure Modes and Limitations
The authors provide a detailed analysis of failure cases:
- VLM Failures: Inaccurate anchor or target identification due to limited VLM spatial reasoning, especially for fine-grained or relational queries.
- SRAS/OSS Limitations: Insufficient viewpoint coverage can miss objects, particularly those at unusual heights or occluded positions.
- Segmentation and Projection Errors: SAM and projection steps are sensitive to rendering artifacts and detector errors, leading to noisy or incomplete 3D masks.

Figure 5: VLMs failure in memory retrieval, the anchor object is a box.

Figure 6: Failure in SRAS, the user query is to find the cushion that is farthest from the PC.

Figure 7: VLMs fail to ground the target image: query “cabinet near the box.”

Figure 8: Failure in SAM and projection.
Qualitative Demonstration
A full demonstration case illustrates the stepwise reasoning and perception process of MCG, showing how memory retrieval, spatial relation parsing, targeted exploration, and multi-view fusion are orchestrated to localize the target object in a changing scene.
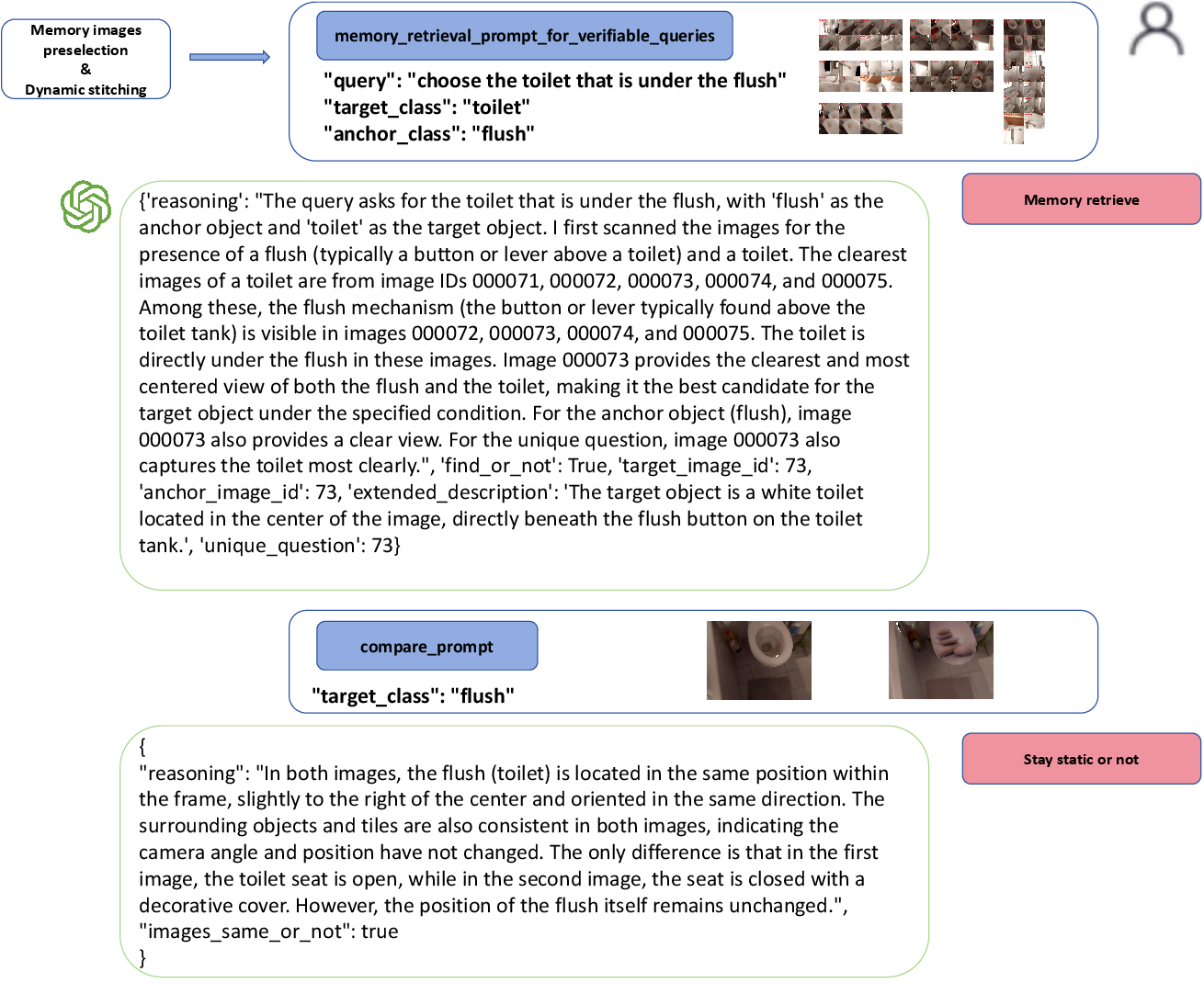
Figure 9: Case of the MCG grounding part-1.

Figure 10: Case of the MCG grounding part-2.
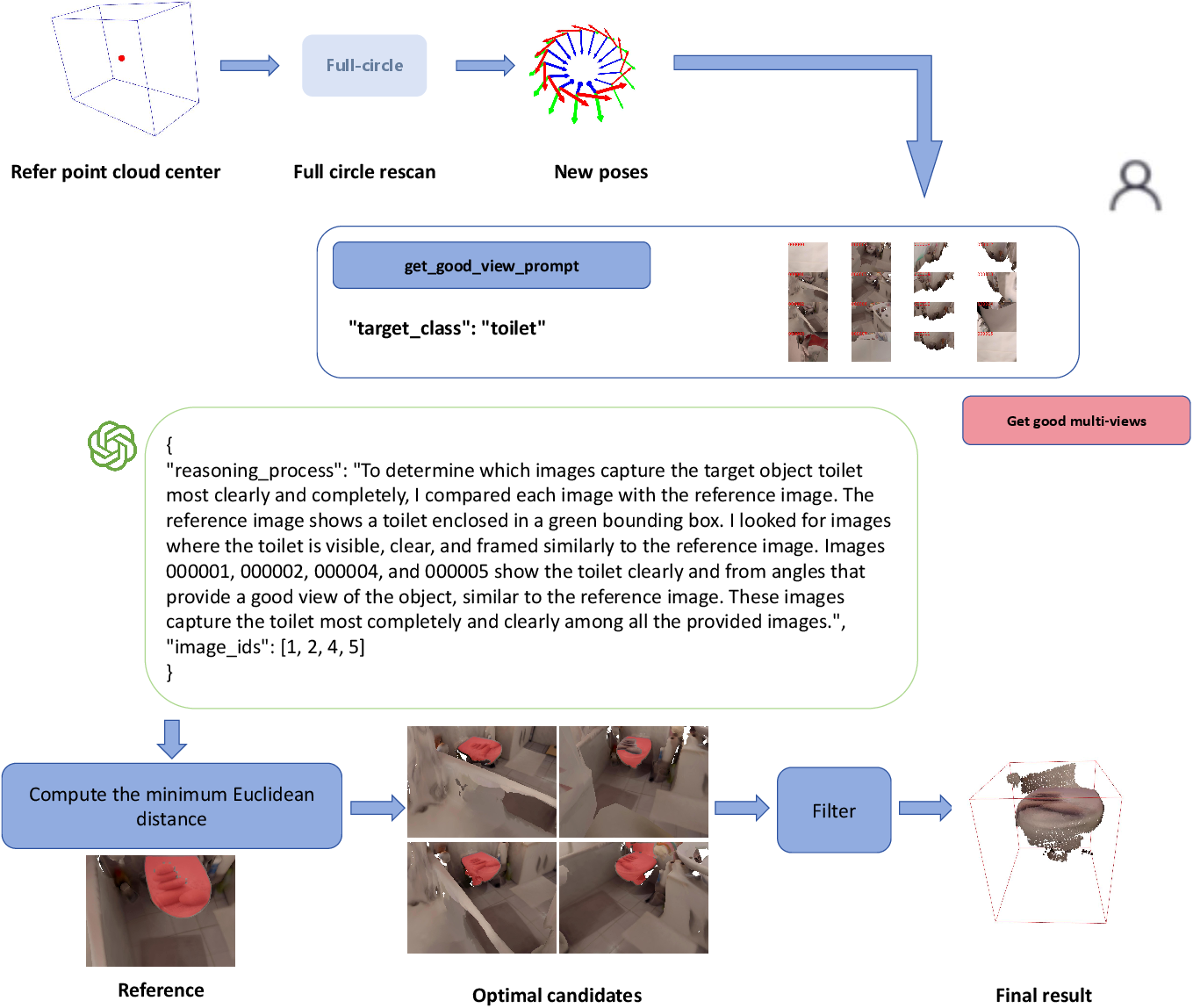
Figure 11: Case of the MCG grounding part-3.
Implications and Future Directions
This work establishes a new research direction for 3D visual grounding in dynamic environments, emphasizing the importance of memory-driven, active perception. The ChangingGrounding benchmark and MCG baseline provide a foundation for developing more practical and efficient 3DVG systems for robotics and embodied AI.
Key implications and open problems include:
- VLM Robustness: Improving spatial reasoning and relational understanding in VLMs is essential for further gains.
- Multimodal Integration: Tighter coupling of visual, linguistic, and spatial cues can enhance grounding accuracy.
- Benchmark Expansion: Incorporating more diverse scene changes (lighting, appearance, dynamic interactions) and allocentric relations will increase realism and challenge.
- Efficient 2D-3D Fusion: Advances in segmentation and projection pipelines are needed to reduce noise and improve 3D localization.
Conclusion
The ChangingGrounding benchmark and Mem-ChangingGrounder baseline redefine 3D visual grounding as an active, memory-centric problem, moving beyond static scene assumptions. By jointly optimizing for accuracy and exploration cost, this work provides a practical framework for real-world robotic perception in dynamic environments and sets the stage for future research in memory-augmented embodied AI.

