VT-Refine: Learning Bimanual Assembly with Visuo-Tactile Feedback via Simulation Fine-Tuning
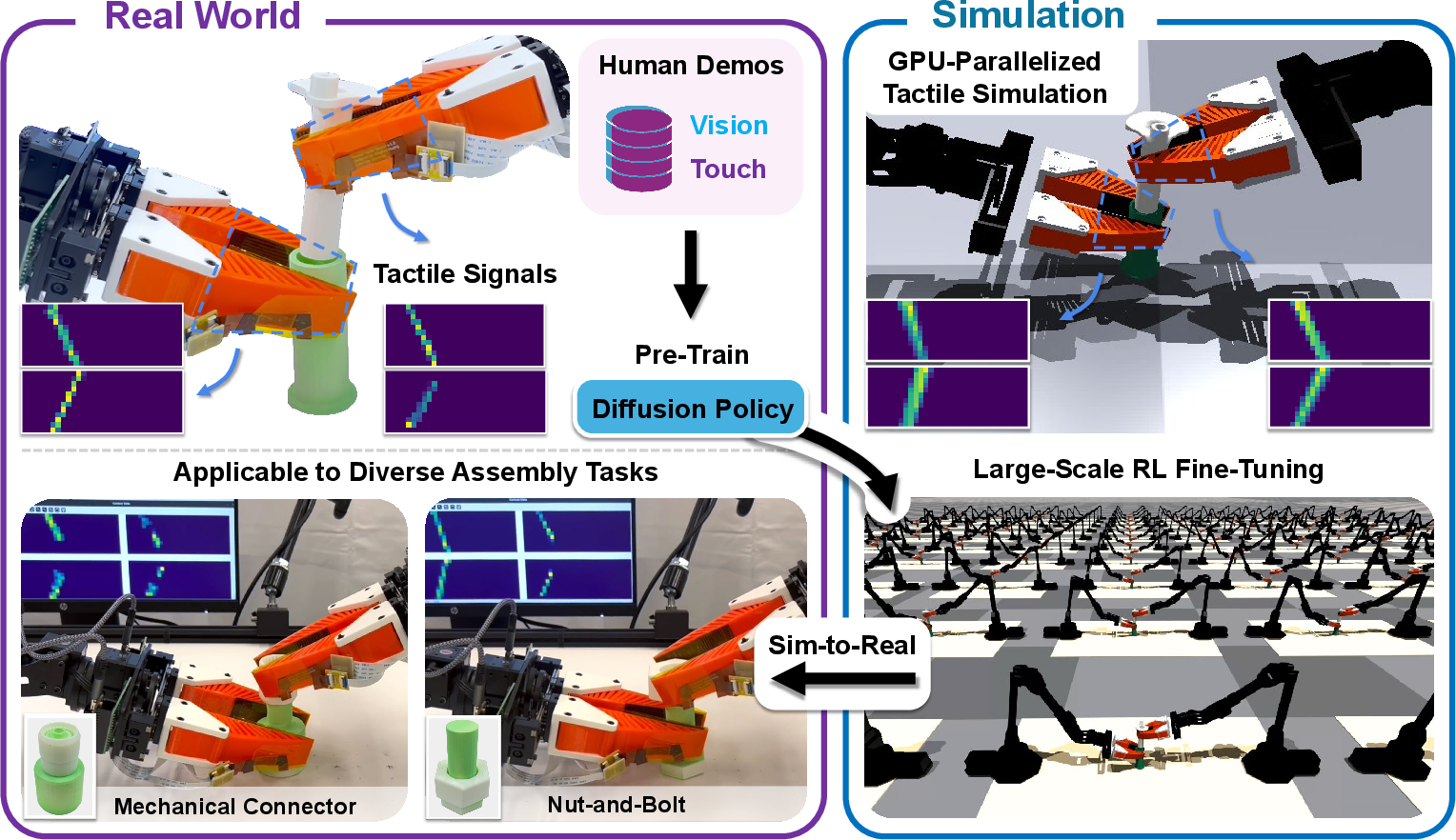
Abstract: Humans excel at bimanual assembly tasks by adapting to rich tactile feedback -- a capability that remains difficult to replicate in robots through behavioral cloning alone, due to the suboptimality and limited diversity of human demonstrations. In this work, we present VT-Refine, a visuo-tactile policy learning framework that combines real-world demonstrations, high-fidelity tactile simulation, and reinforcement learning to tackle precise, contact-rich bimanual assembly. We begin by training a diffusion policy on a small set of demonstrations using synchronized visual and tactile inputs. This policy is then transferred to a simulated digital twin equipped with simulated tactile sensors and further refined via large-scale reinforcement learning to enhance robustness and generalization. To enable accurate sim-to-real transfer, we leverage high-resolution piezoresistive tactile sensors that provide normal force signals and can be realistically modeled in parallel using GPU-accelerated simulation. Experimental results show that VT-Refine improves assembly performance in both simulation and the real world by increasing data diversity and enabling more effective policy fine-tuning. Our project page is available at https://binghao-huang.github.io/vt_refine/.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to use both sight and touch to do careful, two-handed assembly tasks, like plugging a part into a tight-fitting socket. The goal is to make robots better at precise, contact-heavy work by combining a little real-world teaching with lots of safe practice in a realistic simulator.
Key Questions
The researchers set out to answer three simple questions:
- Can a robot learn better two-handed assembly if it uses both vision and touch, instead of vision alone?
- Can we start with a small set of human demonstrations, then improve the robot’s skills by practicing in simulation and still make it work well in the real world?
- Does a special kind of touch sensor (that’s easier to simulate) help the robot learn faster and transfer those skills between the real world and simulation?
How It Was Done
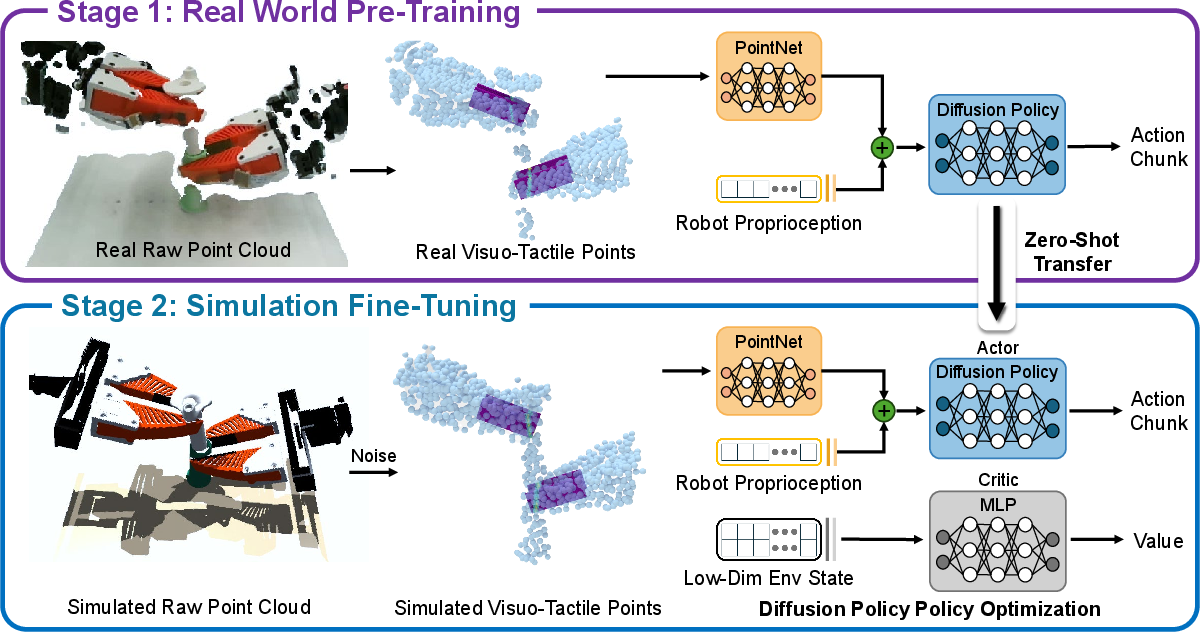
Think of the robot as a student learning a tricky task in two stages:
Stage 1: Learn from a few examples
- The team collected about 30 demonstrations where a human controlled the robot to complete an assembly, like plugging a part into a socket.
- The robot watched a camera (vision) and felt pressure on its fingers (touch) during these demos.
- They trained a “diffusion policy,” which is a way for the robot to plan actions by starting from a rough guess and refining it step-by-step, like sketching a picture and improving it layer by layer. In simple terms, a “policy” is a rule that tells the robot what to do in each situation.
Stage 2: Practice a lot in a realistic simulator
- They built a “digital twin” of the real setup: same parts, same robot, same camera view, and simulated touch sensors. This lets the robot practice safely and cheaply.
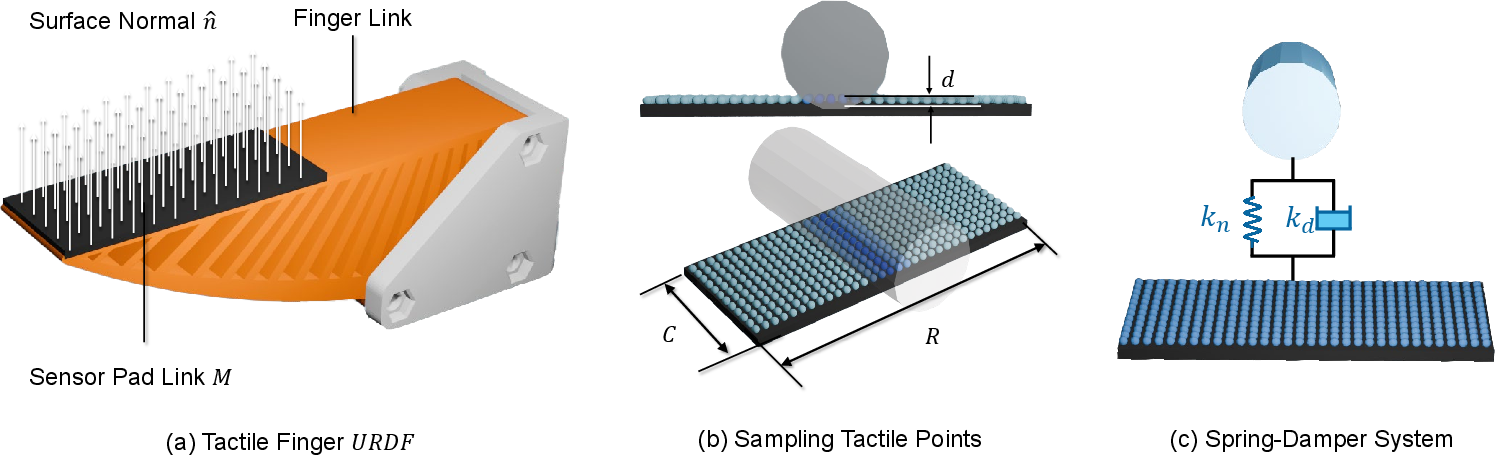
- The touch sensors are flexible pads with many tiny pressure points. These sensors measure how hard something pushes on them (normal force), not detailed textures. That makes them much easier to simulate accurately.
- In simulation, they used a spring-and-shock-absorber model (called a Kelvin–Voigt model) to mimic how soft finger pads press against objects. Imagine each sensor point having a tiny spring and damper that push back when pressed.
- They represented both sight and touch as 3D “point clouds” — clouds of dots that capture the shapes and positions of things. By using the same kind of 3D dots for both vision and touch, the robot could transfer what it learned between the real world and simulation more easily.
- They improved the robot’s policy using reinforcement learning (RL), which is like playing a game: try actions, see what works, and get a reward only when the assembly succeeds. They used a method (PPO/DPPO) that lets the robot learn stably from lots of trials.
Main Findings and Why They Matter
Here are the most important results:
- Using touch + vision beats using vision alone. The robot needs contact feedback to make tiny alignment adjustments that cameras can’t always see (especially when fingers or parts block the view).
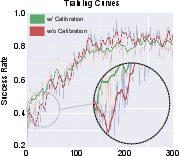
- Practicing in simulation makes the robot much better at precision tasks. Starting from a small number of demos, the robot’s success rate increased a lot after RL fine-tuning in the simulator.
- Touch helped the robot learn “wiggle-and-dock” behavior. Just like people, the robot learned to gently adjust, feel, and re-adjust until parts slid together smoothly. This wasn’t explicitly taught in the demos — it emerged during practice thanks to touch signals.
- The special touch sensors were easy to simulate and matched real readings closely after calibration. That reduced the “sim-to-real gap,” so skills learned in simulation transferred well back to the real robot.
- Even with only 10 demonstrations, simulation practice still improved performance. With 30–50 demos, the robot got very good after fine-tuning, especially on tight-fit tasks (around 2 mm clearance).
In short, the robot became more accurate, more robust, and needed fewer real-world demos by practicing at scale in a simulator with realistic touch.
Implications and Impact
This approach could make robots much better at careful assembly in factories, labs, and homes. Key takeaways:
- Training becomes cheaper and safer by doing most practice in simulation.
- Touch sensing that focuses on forces (not fancy textures) is a smart trade-off: it’s simpler to simulate and good enough for precise alignment.
- Combining vision and touch gives robots a more human-like sense of what’s happening during contact, which is essential for tasks where seeing isn’t enough.
- The real-to-sim-to-real pipeline means we can start from a few real demos, improve a lot in simulation, and run the result on real robots—saving time and effort.
Overall, this work shows a practical path to teaching robots complex, two-handed, contact-heavy tasks using a mix of small real datasets, realistic touch simulation, and large-scale trial-and-error learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized by theme to guide future research.
Sensing and simulation fidelity
- Absence of shear-force sensing: the approach and simulator only use normal force; tasks requiring slip detection, torsional alignment, or shear-dependent friction remain unsupported. Explore shear-capable hardware or learning-based shear estimation from temporal signals.
- Simplified contact model: the Kelvin–Voigt spring-damper with SDF-based penetration ignores frictional microslip, rate-dependent friction, hysteresis, viscoelastic creep, and nonlinearity typical of piezoresistive skins. Quantify the impact and incorporate richer contact/friction models.
- No modeling of sensor cross-talk and spatial non-uniformities: neighboring taxel interference, per-taxel gain/bias variations, edge effects, and pad-to-pad variability are not simulated. Calibrate and simulate per-cell characteristics.
- Limited calibration validation: calibration is matched via global histograms; dynamic, time-domain validation under transient contacts, varying indentation rates, and complex contact patches is not reported.
- Thermal and aging effects: temperature drift, humidity sensitivity, and long-term wear of resistive skins are unmodeled; develop online recalibration and drift compensation procedures.
- Soft gripper and finger compliance are approximated kinematically: deformation of the finger and tactile pad is not explicitly simulated; investigate reduced-order soft-body models or differentiable sim for more faithful compliance.
- No domain randomization for tactile/visual/dynamics: noise models, friction/material variation, pose/extrinsic perturbations, and time delay/latency are not randomized; evaluate whether such randomization reduces sim-to-real drop.
Visuo-tactile representation and fusion
- Fusion by concatenating point clouds may underuse structure: the tactile grid’s spatial topology (12×32) and inter-taxel correlations are not explicitly modeled; assess grid-aware CNN/graph models or cross-modal attention.
- Temporal modeling is unspecified: inferring shear-like cues from history is claimed but not validated; characterize required history length and compare recurrent/transformer architectures versus single-frame encoders.
- Colorless visual input: texture/color cues are unused; evaluate benefits/costs of RGB, multi-view, or learned depth completion for occluded contacts.
- Cross-modal alignment learning: reliance on FK and calibration leaves sensitivity to encoder/extrinsic errors; explore self-calibration using visuo-tactile consistency or differentiable registration during training.
Learning, optimization, and rewards
- Dependence on successful pretraining: fine-tuning from scratch failed (0%); develop bootstrapping strategies (curricula, automatic goal generation, dense shaping from contact metrics, exploration bonuses) to avoid reliance on occasional demo successes.
- Sparse reward only in simulation: no real-world fine-tuning or preference-based/demonstration-derived dense rewards; study safe on-robot policy improvement with tactile-based success proxies.
- Privileged critic may hurt transfer: the asymmetric critic uses object state unavailable in real deployment; quantify transfer sensitivity and evaluate non-privileged critics or privilege regularization/distillation.
- Algorithmic comparisons missing: DPPO is not compared to residual RL, Q-learning with diffusion actors, value-regularized BC, or model-based fine-tuning; benchmark sample efficiency and stability across algorithms.
- Action chunking vs control rate: diffusion with action chunks may reduce effective control bandwidth; analyze latency, step count, and chunk size on micro-adjustment performance.
Task scope, generalization, and robustness
- Narrow task family and workspace variation: evaluation is limited to five plug-socket assets with ~3 cm pose randomization and ~2 mm clearance; test unseen geometries, larger pose/angle variation, different tolerances, and materials/frictions.
- No multi-task or category-level generalization: policies appear task-specific; investigate single policies across many assemblies, or category-level transfer with shape-conditioned policies.
- Deformables and more complex assemblies unsupported: threads, cables, seals, gaskets, and compliant sockets require deformable simulation and torsional reasoning; extend simulator and policy to these regimes.
- Limited platforms and end-effectors: only two setups with parallel grippers; test multi-finger hands, different fingertip geometries, and mobile bases to assess portability.
- Occlusion and camera placement robustness: single egocentric depth camera; study multi-view sensing, moving cameras, and severe hand/object occlusions.
- Long-horizon and multi-stage assemblies: sequencing of grasp, regrasp, alignment, fastening is not studied; integrate hierarchical policies or task-graph planners.
System identification and assets
- Manual real-to-sim calibration: visual, tactile, and control alignment are hand-tuned; develop automated system identification for tactile parameters, friction, and controller dynamics (e.g., gradient-based or Bayesian ID).
- CAD model requirement: training depends on accurate CAD for SDF; explore CAD-free pipelines via on-the-fly shape reconstruction (RGB-D+tactile), category priors, or tactile SLAM for SDF estimation.
- Material and friction identification: friction coefficients and material properties are not measured or randomized; add estimation procedures and randomization ranges tied to real measurements.
Safety, reliability, and deployment
- Jam detection and recovery: failure cases show jamming and potential damage; design tactile-based jam detectors, back-off strategies, and compliant insertion controllers.
- Force/torque safeguarding: no explicit force/torque limits or impedance/admittance control integration; evaluate hybrid position–force control with tactile feedback to protect hardware.
- Real-time constraints: inference timing, compute budget, and control loop frequency are not reported; quantify latency and study performance on embedded GPUs/CPUs.
- Sensor durability and maintenance: lifespan, abrasion, and replacement/calibration schedules for FlexiTac pads are unreported; characterize MTBF and maintenance protocols.
Data and demonstrations
- Demo quality and interfaces: human teleop lacked tactile feedback; quantify how haptic teleop, kinesthetic teaching, or corrective interventions change demo quality and data efficiency.
- Data efficiency: with 10 demonstrations, fine-tuned performance remained modest; explore active learning, data aggregation (DAgger), synthetic demo augmentation, or self-play exploration to reduce real data needs.
- Exploration behaviors: “wiggle-and-dock” emerges in RL but is not explicitly parameterized; analyze and distill reusable exploration primitives that transfer across tasks.
Evaluation and reproducibility
- Statistical reporting: success rates lack confidence intervals and variance across seeds; provide rigorous statistical analysis and ablations (e.g., tactile ablated per finger, encoder architectures).
- Baselines: no comparison to analytic insertion controllers, residual RL on classical controllers, or policies with optical tactile sensors; include stronger baselines to isolate contributions.
- Release artifacts: sensor tutorials are promised, but it is unclear if tactile simulation code, calibration datasets, and trained models will be released; ensure full reproducibility and parameter disclosure.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s VT-Refine workflow (few-shot visuo-tactile diffusion policies, GPU-parallel tactile simulation via TacSL/Isaac Gym, and DPPO fine-tuning), and the FlexiTac sensor design.
- Precision connector insertion cells — sectors: electronics, automotive, aerospace
- Use case: bimanual insertion of tight-clearance plugs, multi-pin connectors, and snap-fit couplings where vision is occluded during contact.
- Tools/products/workflows: FlexiTac pads retrofitted on existing grippers; point-cloud visuo-tactile policy; digital twin built from CAD; collect ~30 teleoperated demos; calibrate tactile sim (Kelvin–Voigt) and fine-tune via DPPO; deploy back to the cell.
- Assumptions/dependencies: access to part CAD; GPU resources (Isaac Gym/TacSL); rigid parts; safety-certified control stack; normal-force-only tactile is sufficient for task.
- Battery module assembly — sector: energy
- Use case: busbar insertion, gasket seating, and cell alignment with ≈2 mm tolerance where occlusion and compliance complicate visual-only control.
- Tools/products/workflows: VT-Refine kit for bimanual grippers; sparse-reward RL fine-tuning to learn “wiggle-and-dock” micro-adjustments that reduce jamming/scrap.
- Assumptions/dependencies: stable fixtures; CAD available; normal-force tactile readings provide alignment cues without needing shear sensing.
- Wire harness and cable management — sectors: automotive, industrial equipment
- Use case: plugging harnesses into tight sockets under occlusion; verifying insertion completeness.
- Tools/products/workflows: point-cloud encoder merging egocentric depth and tactile grid; policies trained from limited teleop demos; tactile monitoring to detect misalignment.
- Assumptions/dependencies: repeatable sockets; consistent tactile pad placement via forward kinematics; controller latency low enough for micro-adjustments.
- Damage mitigation/QA overlays — cross-sector
- Use case: add tactile-aware policies to reduce insertion forces and detect early misalignment to prevent part damage.
- Tools/products/workflows: force-threshold alerts from FlexiTac; RL-learned corrective micro-motions; dashboards showing tactile histograms and alignment trends.
- Assumptions/dependencies: sensor calibration; integration with MES/QA systems; simple alarm logic over normal forces.
- FlexiTac as a low-cost retrofit — sectors: robotics hardware, SMEs
- Use case: quickly add dense, normal-force tactile sensing to soft or parallel grippers.
- Tools/products/workflows: 12×32 piezoresistive matrix pads; 5-minute fabrication process; tutorials for mounting and wiring; uniform tactile point sampling in sim.
- Assumptions/dependencies: mechanical compatibility; basic electronics; ability to map sensor coordinates to end-effector frames.
- Teleoperation-driven skill acquisition — sectors: manufacturing engineering, robotics services
- Use case: fast onboarding of new assemblies via small demo sets with Meta Quest or ALOHA-style teleop.
- Tools/products/workflows: capture ~30 demos; pre-train diffusion policy; DPPO fine-tuning in digital twin; deploy; iterate as parts or tolerances change.
- Assumptions/dependencies: teleop setup; stable pose randomization range; operator time; repeatable fixtures.
- Simulation software integration for visuo-tactile RL — sectors: robotics software
- Use case: add normal-force tactile modeling and point-cloud visuo-tactile inputs to simulation stacks.
- Tools/products/workflows: TacSL with Isaac Gym; Kelvin–Voigt calibration pipeline; point-cloud encoders (PointNet); DPPO training scripts.
- Assumptions/dependencies: GPU availability; maintained simulator versions; domain alignment procedures.
- Academic teaching and reproducible research — sectors: education, academia
- Use case: course modules and labs on sim-to-real visuo-tactile manipulation; replicating bimanual assembly benchmarks.
- Tools/products/workflows: FlexiTac build tutorials; AutoMate object set; small-demo pretraining and sim fine-tuning; comparative studies (vision-only vs visuo-tactile).
- Assumptions/dependencies: depth camera, dual-arm platform, GPU; open access or licenses for datasets and simulators.
- Semi-humanoid robot demos — sectors: service robotics, applied R&D
- Use case: head-mounted camera + dual arms to perform in-air insertions with occlusions (e.g., cabinet or rack assembly prototypes).
- Tools/products/workflows: same VT-Refine pipeline; pad placement on 2F grippers; ego-centric point clouds; sparse rewards.
- Assumptions/dependencies: limited workspace; accurate kinematics; reliable end-effector control.
- Hazardous environment remote assembly — sectors: nuclear, defense, energy
- Use case: remotely plugging connectors and performing precise insertions where cameras are unreliable due to occlusion or lighting.
- Tools/products/workflows: teleoperation to collect demos; tactile-guided policies for alignment; deploy on radiation-tolerant manipulators.
- Assumptions/dependencies: robust communications; ruggedized sensors; policy validation under safety constraints.
Long-Term Applications
These applications require further research, scaling, or development (e.g., deformable object simulation, shear-force sensing, CAD-free pipelines, certification).
- CAD-free, plug-and-play assembly learning — sectors: software, manufacturing
- Use case: policies train and fine-tune from real scans without requiring CAD models or hand-built digital twins.
- Tools/products/workflows: on-the-fly scene reconstruction; auto-meshing; sim parameter inference; policy bootstrapping from live data.
- Assumptions/dependencies: robust 3D reconstruction; sim parameter identification; domain randomization; perception under clutter.
- Deformable object assembly and cable routing — sectors: electronics, appliance, automotive
- Use case: routing flexible cables, inserting gaskets/seals, installing soft components.
- Tools/products/workflows: deformable-contact models (FEM or fast differentiable approximations); upgraded tactile sensing capturing shear; extended DPPO rewards.
- Assumptions/dependencies: higher-fidelity simulation; faster solvers; richer tactile modalities.
- General-purpose household assembly (e.g., furniture, cable plugging) — sector: consumer robotics
- Use case: home robots performing tight-fit insertions and two-handed assembly tasks in unstructured settings.
- Tools/products/workflows: mobile manipulation platforms; robust visuo-tactile policies; task libraries; self-supervised sim-to-real adaptation.
- Assumptions/dependencies: cost-effective hardware; safety certification; broad generalization; robust grasping on varied objects.
- Surgical and medical device manipulation — sector: healthcare
- Use case: peg transfer, suture needle insertion, catheter/port placement with visuo-tactile feedback.
- Tools/products/workflows: sterilizable tactile skins; high-frequency control; surgical simulators with tactile realism; task-specific sparse rewards.
- Assumptions/dependencies: regulatory approval; biocompatible materials; higher sensing resolution and shear; expert teleop data.
- On-the-line learning for cobots — sectors: manufacturing, industrial automation
- Use case: cobots adapt to part variations and new SKUs with a handful of demos and overnight sim fine-tuning.
- Tools/products/workflows: integrated DPPO in factory digital twins; safety envelopes; incremental updates; human-in-the-loop validation.
- Assumptions/dependencies: IEC/ISO safety compliance; continuous calibration; robust change management.
- Policy marketplaces and knowledge sharing — sectors: software/platforms
- Use case: exchange of pre-trained visuo-tactile assembly policies across vendors and grippers.
- Tools/products/workflows: standardized visuo-tactile representations; policy packaging and benchmarking; secure deployment pipelines.
- Assumptions/dependencies: IP/licensing frameworks; interoperability standards; cybersecurity.
- Edge-native visuo-tactile inference — sectors: embedded systems, robotics
- Use case: real-time inference of point-cloud + tactile policies on ARM/embedded GPUs at low latency.
- Tools/products/workflows: optimized PointNet encoders; model compression/quantization; RTOS integration.
- Assumptions/dependencies: compute budgets; deterministic runtimes; thermal constraints.
- Standards and policy for tactile sensing interoperability — sectors: standards bodies, public policy
- Use case: common interfaces and certification for tactile sensors (normal/shear), calibration procedures, and sim realism tests.
- Tools/products/workflows: calibration rigs; benchmark suites (histogram matching, contact fidelity); data formats for tactile grids.
- Assumptions/dependencies: stakeholder consensus; cross-vendor collaboration; funding for testbeds.
- Automated real–sim calibration pipelines — sectors: robotics software/tools
- Use case: auto-tuning Kelvin–Voigt parameters from short calibration runs; continuous validation against real histograms.
- Tools/products/workflows: optimization routines; QA dashboards; closed-loop calibration agents.
- Assumptions/dependencies: reliable ground-truth force measurements; repeatable fixtures.
- Multi-robot, multi-arm coordination — sectors: large-scale assembly (aerospace, shipbuilding)
- Use case: coordinated bimanual insertions across separate robots handling large parts with tight fits.
- Tools/products/workflows: shared visuo-tactile state; synchronized policies; high-fidelity digital twins of large assemblies.
- Assumptions/dependencies: precise time sync; collision-aware motion planning at scale; robust communication.
Glossary
- Action chunk: A short horizon sequence of low-level actions predicted in one step by a diffusion policy. "we adopt a denoising diffusion probabilistic model (DDPM) and follow standard practice by predicting an action chunk~\cite{chi:rss2023} (Fig.~\ref{fig: method}, top)."
- Asymmetric actor-critic: An actor-critic RL setup where the actor and critic receive different observations (e.g., rich observations for the actor and low-dimensional state for the critic). "We adopt an asymmetric actor-critic strategy~\cite{pinto:rss2018}, where the critic receives a low-dimensional representation of the robot and object state."
- Behavioral cloning: Imitation learning that trains a policy to mimic expert demonstrations by supervised learning on state-action pairs. "a capability that remains difficult to replicate in robots through behavioral cloning alone, due to the suboptimality and limited diversity of human demonstrations."
- Bimanual robotic manipulation: Manipulation tasks that require coordinating two robot arms or hands. "Bimanual robotic manipulation presents significant challenges across a range of applications~\cite{huang2023dynamic,lin:corl2024,wang2023mimicplay,wang2024dexcap,qin2023anyteleop,ankile:icra2025,jiang2024transic}, particularly for assembly tasks."
- Contact-rich: Involving sustained or complex physical contact during manipulation. "a novel visuo-tactile policy learning framework for precise, contact-rich bimanual assembly tasks."
- Critic network: The value-function estimator in actor-critic RL that evaluates states or state-action pairs. "the critic network is initialized randomly."
- cuRobo: A GPU-accelerated model predictive control framework for fast motion planning and control. "Online trajectory generation is performed using the GPU-accelerated model predictive control framework provided by cuRobo~\cite{sundaralingam:arxiv2023}."
- Denoising diffusion probabilistic model (DDPM): A generative model that learns to iteratively denoise samples from noise to produce outputs, used here to generate actions. "To train the diffusion policy, we adopt a denoising diffusion probabilistic model (DDPM)..."
- Diffusion policy: A visuomotor control policy that uses a diffusion model to generate action sequences conditioned on observations. "Behavioral cloning with diffusion policies~\cite{chi:rss2023,ze:rss2024} has recently shown promise in learning bimanual visuo-tactile policies..."
- Digital twin: A simulated replica of a real-world system used to test and refine policies before deployment. "This policy is then transferred to a simulated digital twin equipped with simulated tactile sensors..."
- Domain mismatch: Differences between simulated and real environments that cause performance degradation when transferring policies. "Transferring a policy between the real robot and simulation inevitably introduces some performance loss due to domain mismatch."
- Dynamic Mechanical Analyzer (DMA): An instrument for measuring material viscoelastic properties under controlled deformation. "we first characterize the sensorâs force-reading curve using a DMA 850 Dynamic Mechanical Analyzer."
- Ego-centric camera: A camera providing observations from a viewpoint attached to the agent or workspace, aligned with its perspective. "a colorless point cloud captured by an ego-centric camera, denoted as "
- Forward kinematics: Computing the position and orientation of robot parts from known joint states. "the positions of tactile points are updated in real time via forward kinematics."
- GPU-accelerated simulation: Physics or sensor simulation executed on GPUs for high-throughput parallelism. "can be realistically modeled in parallel using GPU-accelerated simulation."
- Isaac Gym: A GPU-based physics simulator supporting large-scale parallel robot learning. "a GPU-based tactile simulation library integrated with Isaac Gym~\cite{makoviychuk:neuripstdb2021}."
- Kelvin-Voigt model: A viscoelastic model of materials using a spring and damper in parallel to represent elastic and viscous behavior. "modeled using a Kelvin-Voigt model, consisting of a linear spring and a viscous damper connected in parallel."
- Penetration-based tactile force model: A contact model that computes forces from penetration depth and relative velocity along the contact normal. "we follow TacSL and employ a penetration-based tactile force model~\cite{xu:corl2022}."
- Piezoresistive tactile sensors: Tactile sensors whose electrical resistance changes under applied pressure, enabling force measurement. "we leverage high-resolution piezoresistive tactile sensors that provide normal force signals"
- Point cloud: A set of 3D points representing the geometry of the scene or sensors, used as an observation modality. "We adopt a point cloud-based representation for its robust sim-to-real transferability~\cite{qin:corl2022,yuan:icra2024,huang:corl2024}."
- PointNet: A neural network architecture for processing unordered point sets such as 3D point clouds. "the merged point cloud is processed by a PointNet encoder~\cite{qi:cvpr2017}"
- Policy-gradient-based RL: Reinforcement learning methods that optimize policies by estimating gradients of expected returns. "fine-tune the pre-trained diffusion policy using policy-gradient-based RL~\cite{schulman:arxiv2017}."
- Proprioception: Internal sensing of the robot’s body, such as joint positions and gripper states. "proprioception: joint positions from the two arms and two grippers."
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm using clipped objectives for stable updates. "DPPO optimizes a diffusion policy using Proximal Policy Optimization (PPO)~\cite{schulman:arxiv2017}..."
- Reinforcement learning (RL): Learning control policies by maximizing expected cumulative rewards through trial and feedback. "fine-tuned using reinforcement learning (RL) on a digital twin of the scene within a parallelized simulation environment."
- Signed distance field (SDF): A function that returns the distance to the nearest surface with sign indicating inside/outside, used for contact queries. "the signed distance field (SDF) of the contacting object is queried to compute "
- Sim-to-real transfer: Deploying a policy trained in simulation on real hardware while preserving performance. "sim-to-real transfer for tactile-critical bimanual tasks~\cite{lin:ral2023}."
- Sparse reward: A reward signal provided only upon task success or at few specific events, without dense shaping. "We therefore fine-tune using a sparse reward: the agent receives a reward of 1 when the parts are successfully assembled, and 0 otherwise~\cite{heo:rss2023}."
- Spring-damper model: A mechanical contact model using a spring and damper to approximate compliant interactions. "A spring-damper model is used to simulate the interaction between the tactile points and objects to generate realistic tactile signals."
- TacSL: A library for visuotactile sensor simulation and learning, integrated with GPU simulators. "we build on TacSL~\cite{akinola:tro2025}, a GPU-based tactile simulation library integrated with Isaac Gym~\cite{makoviychuk:neuripstdb2021}."
- Teleoperation: Human control of a robot at a distance via input devices and mapping to robot motions. "we adopt the teleoperation setup proposed in ALOHA~2~\cite{aldaco2024aloha}"
- Viscoelastic model: A model capturing both viscous and elastic responses of materials under deformation. "We then fit a KelvinâVoigt viscoelastic model by iteratively tuning the elastic modulus ..."
- Visuo-tactile: Combining visual and tactile sensing modalities for perception and control. "a visuo-tactile policy learning framework that combines real-world demonstrations, high-fidelity tactile simulation, and reinforcement learning"
Collections
Sign up for free to add this paper to one or more collections.