- The paper introduces LLM-ERM, which leverages LLM-guided search to generate candidate programs with improved sample efficiency.
- The experimental results show that LLM-ERM recovers target functions from only 200 samples, outperforming traditional SGD methods.
- The framework delivers interpretable, executable outputs with reasoning traces that enhance transparency and candidate verification.
LLM-ERM: Sample-Efficient Program Learning via LLM-Guided Search
This paper presents the LLM-ERM framework, which enhances program learning through a propose-and-verify approach using LLMs. The framework leverages LLMs to identify candidate programs via LLM-guided search, significantly improving sample efficiency and computational feasibility compared to traditional exhaustive methods.
Introduction
Traditional program learning methods, which enumerate candidate programs and perform empirical risk minimization (ERM), are limited by computational constraints. This necessitates a large number of samples, especially with gradient-based training approaches, such as stochastic gradient descent (SGD), that tend to overfit on small sample sizes.
The authors introduce LLM-ERM, a framework that employs a reasoning-augmented LLM to generate candidate programs. The framework applies ERM-style selection on held-out data, allowing it to generalize well from a modest number of samples.
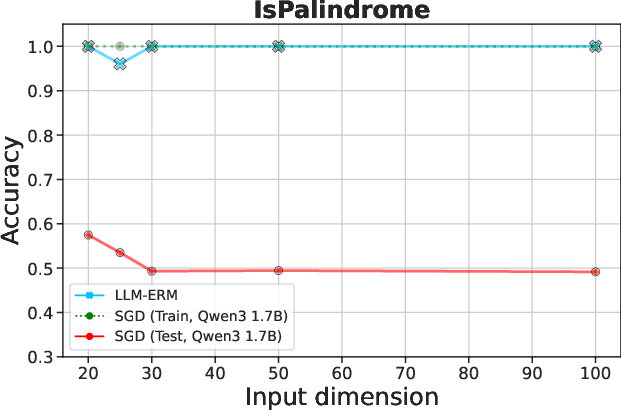
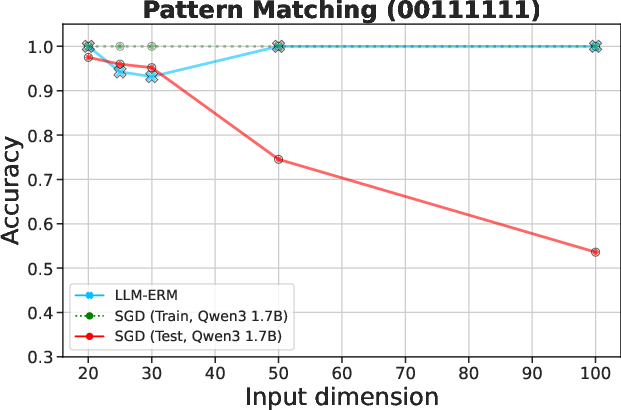
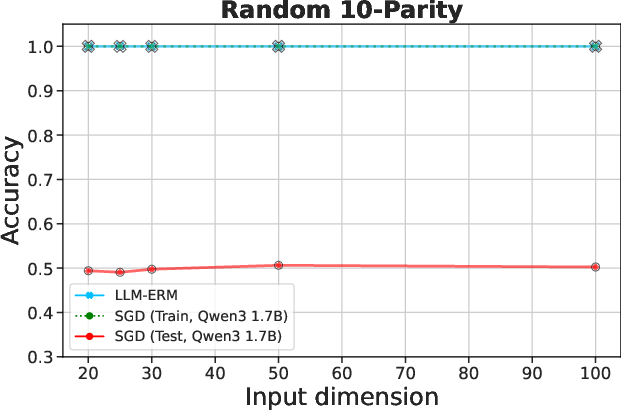
Figure 1: LLM-ERM generalizes from 200 samples, while an SGD-trained LLM overfits.
Theoretical Framework
Theoretical analyses demonstrate SGD's inherent inefficiencies when applied to learning certain short programs that admit compact representations. The authors prove that while mini-batch SGD often requires exponentially many samples, LLM-ERM retains the statistical efficiency of finite-class ERM. The framework's success is largely attributable to the intelligent proposal of candidates by the LLM, which directs the search toward promising hypotheses.
Methodology
LLM-ERM uses a prompt constructed from training data, which guides the LLM in generating a pool of candidate programs. Each candidate is evaluated, and the one with the best validation performance is selected. This is an adaptive search process that avoids the pitfalls of exhaustive enumeration.
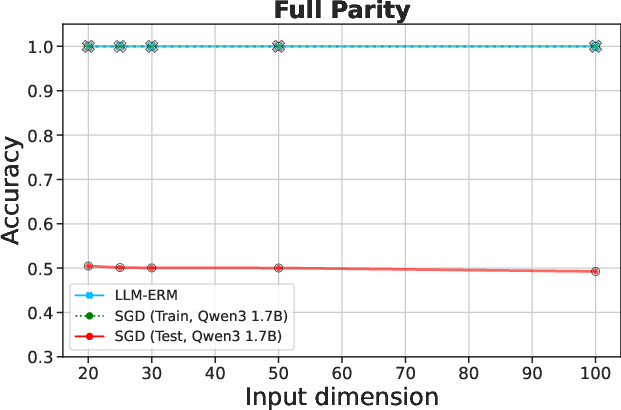
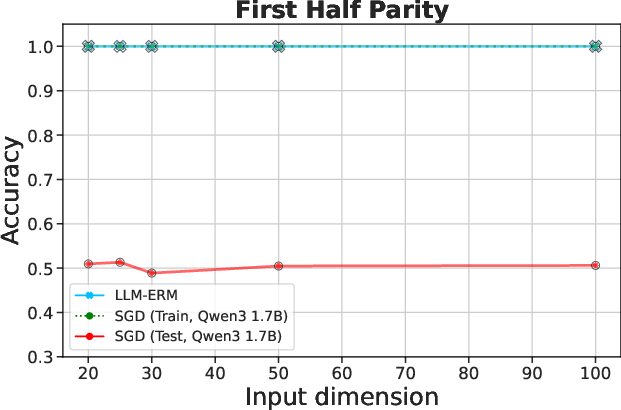
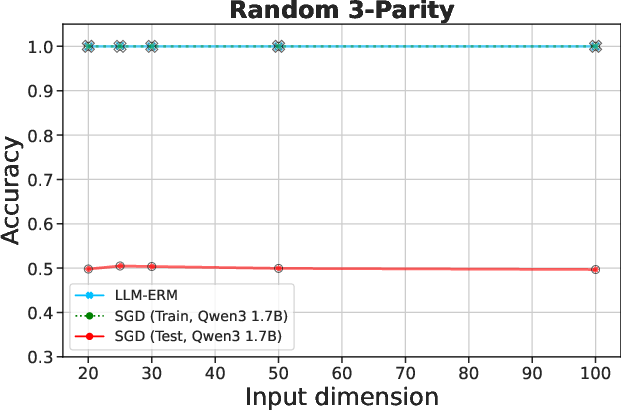
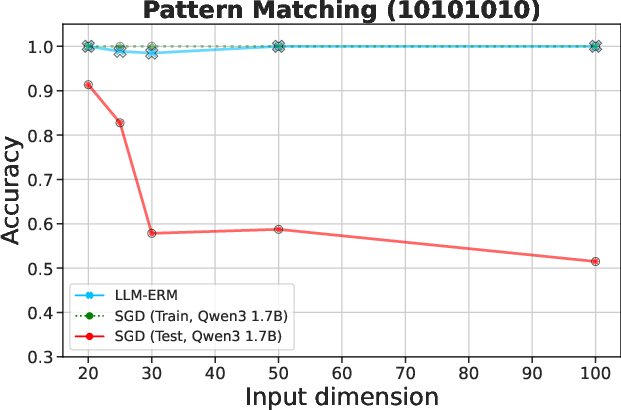
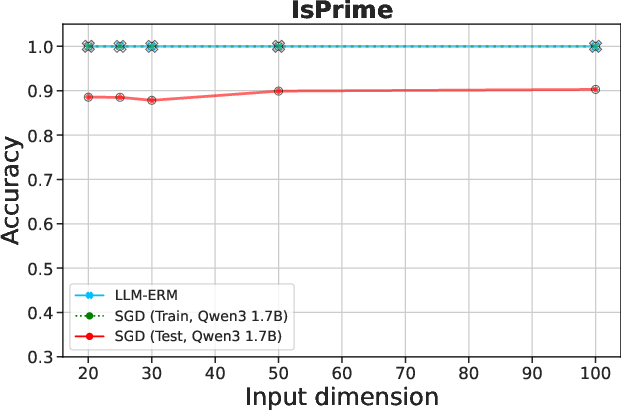
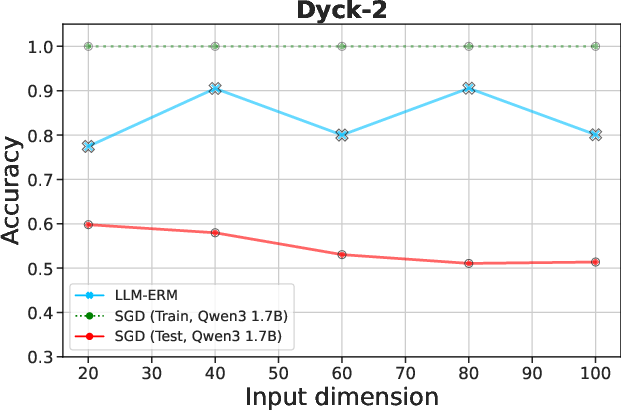
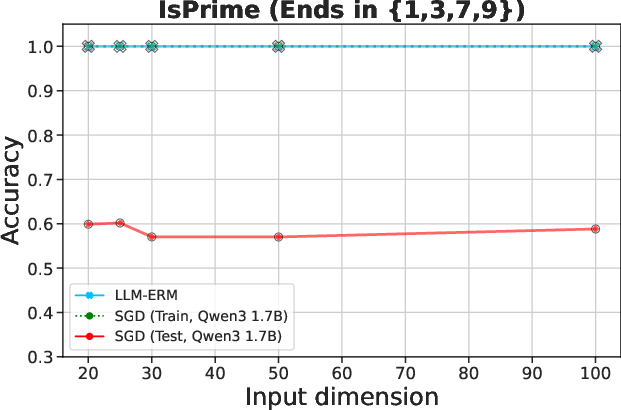
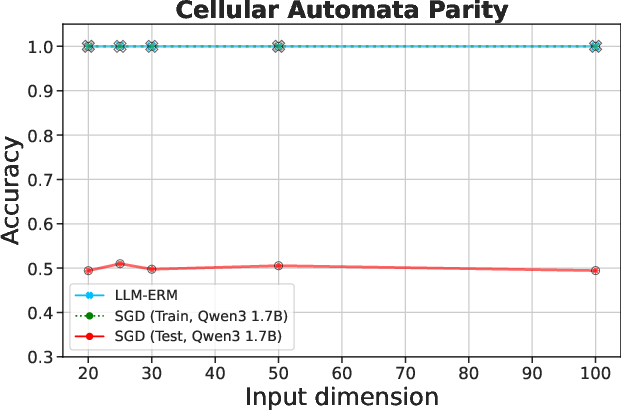
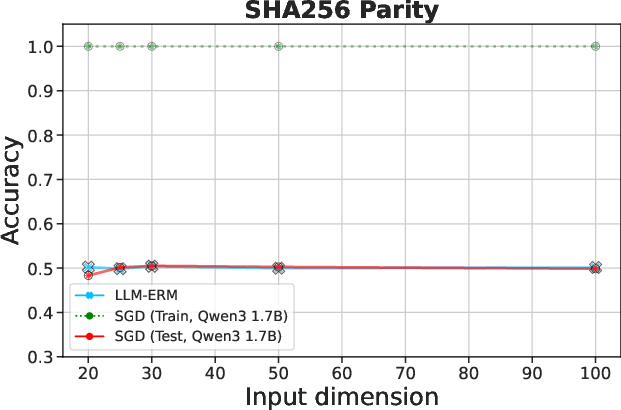
Figure 2: LLM-ERM generalizes from 200 samples, while SGD-trained LLM overfits. With only 200 training examples per task, LLM-ERM typically recovers the target function exactly, whereas SGD training fits the training data but fails to generalize on most tasks.
Empirical Evaluation
Experiments encompass synthetic algorithmic tasks like parity and pattern matching, among others, to evaluate the framework on its generalization capabilities. Results indicate that LLM-ERM significantly exceeds the performance of baselines, achieving near-perfect generalization across various tasks with a fraction of the data.
The paper also highlights the inability of both fine-tuned pre-trained models and in-context learning with existing LLMs to match LLM-ERM's efficiency and accuracy.
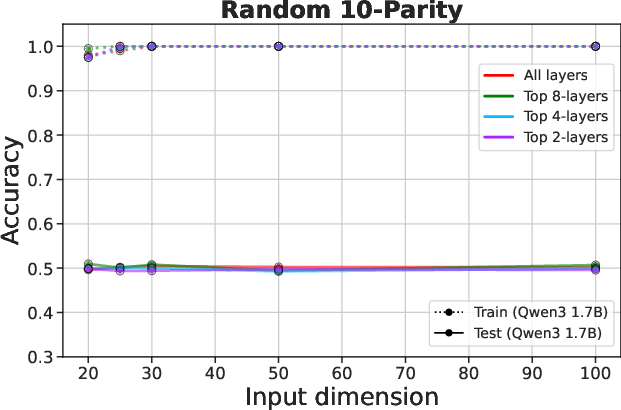
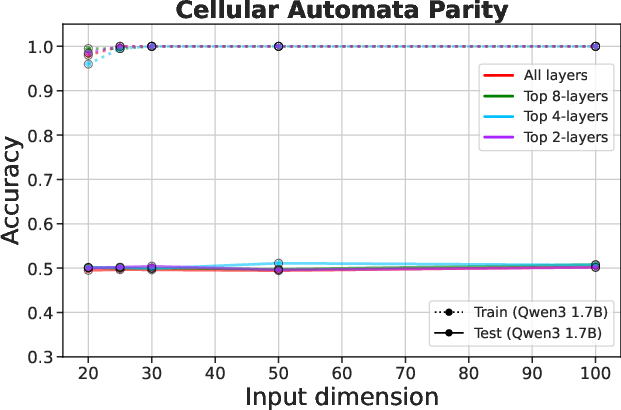
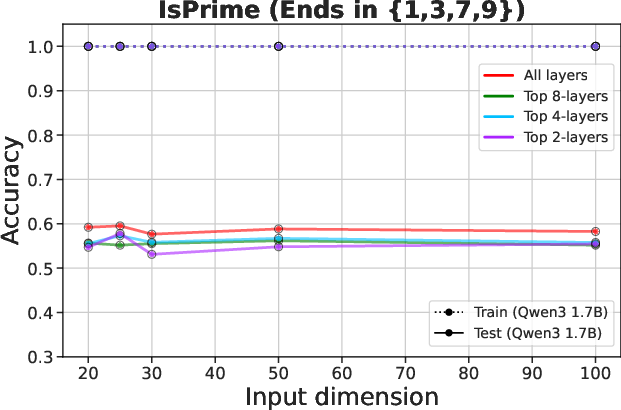
Figure 3: Fine-tuning pre-trained LLMs fails to overcome overfitting on algorithmic tasks.
Interpretability
The outputs of LLM-ERM are interpretable by design, consisting of human-readable, executable code accompanied by a reasoning trace. This trace offers insights into why certain candidates were chosen, allowing for inspection and modification, thus ensuring transparency in the learning process.
Conclusion
LLM-ERM's propose-and-verify model exemplifies a quantum leap in program learning by harnessing the reasoning power of LLMs, achieving sample efficiency previously deemed impractical. This advancement represents a pivotal step toward more intelligent and resource-efficient AI systems capable of learning succinct, generalizable hypotheses from limited data, illustrating the potential to bridge the gap between statistical and computational efficiency in machine learning tasks.