Readers Prefer Outputs of AI Trained on Copyrighted Books over Expert Human Writers
Abstract: The use of copyrighted books for training AI models has led to numerous lawsuits from authors concerned about AI's ability to generate derivative content. Yet it's unclear if these models can generate high quality literary text while emulating authors' styles. To answer this we conducted a preregistered study comparing MFA-trained expert writers with three frontier AI models: ChatGPT, Claude & Gemini in writing up to 450 word excerpts emulating 50 award-winning authors' diverse styles. In blind pairwise evaluations by 159 representative expert & lay readers, AI-generated text from in-context prompting was strongly disfavored by experts for both stylistic fidelity (OR=0.16, p<10-8) & writing quality (OR=0.13, p<10-7) but showed mixed results with lay readers. However, fine-tuning ChatGPT on individual authors' complete works completely reversed these findings: experts now favored AI-generated text for stylistic fidelity (OR=8.16, p<10-13) & writing quality (OR=1.87, p=0.010), with lay readers showing similar shifts. These effects generalize across authors & styles. The fine-tuned outputs were rarely flagged as AI-generated (3% rate v. 97% for in-context prompting) by best AI detectors. Mediation analysis shows this reversal occurs because fine-tuning eliminates detectable AI stylistic quirks (e.g., cliche density) that penalize in-context outputs. While we do not account for additional costs of human effort required to transform raw AI output into cohesive, publishable prose, the median fine-tuning & inference cost of $81 per author represents a dramatic 99.7% reduction compared to typical professional writer compensation. Author-specific fine-tuning thus enables non-verbatim AI writing that readers prefer to expert human writing, providing empirical evidence directly relevant to copyright's fourth fair-use factor, the "effect upon the potential market or value" of the source works.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: if AI is trained on lots of books (including copyrighted ones), can it write short pieces that sound like famous authors—and will people prefer those AI pieces over ones written by expert human writers? The study doesn’t just look at writing quality; it also looks at how closely the writing matches a specific author’s style and what this might mean for copyright law and the book market.
What did the researchers want to find out?
The team focused on three simple questions:
- Can AI match or beat expert human writers on writing quality and on copying a specific author’s style?
- Do expert readers (trained writers) and everyday readers (non-experts) prefer the same things?
- Does how “detectable” a text is as AI-written affect what readers prefer—and does special training of an AI change that?
How did they do the study?
To make the test fair and clear, the researchers set up a head-to-head comparison.
- Who wrote the texts:
- Human side: 28 expert writers in top MFA programs (these are highly trained creative writers).
- AI side: three leading AI models—ChatGPT (GPT‑4o), Claude 3.5 Sonnet, and Gemini 1.5 Pro.
- What they wrote:
- Short excerpts (up to 450 words) meant to imitate the style and voice of 50 well-known authors (including Nobel and Booker Prize winners).
- For some authors who write in other languages, consistent English translations were used to keep the voice steady.
- Two ways the AI was used: 1) In-context prompting: The AI was given instructions and examples, like telling someone “Write a paragraph in the style of Author X.” Think of this like giving a smart student quick directions. 2) Fine-tuning: The AI was further trained on one author’s complete works so it became a “specialist” in that author. Think of this like the student studying only Author X’s books for a long time to learn their voice deeply.
- Who judged the writing:
- Expert readers: MFA students (not judging their own writing).
- Lay readers: everyday readers recruited online.
- Everyone read pairs of excerpts (one human, one AI) without knowing which was which. They chose:
- Which one sounded more like the target author’s style.
- Which one had better overall writing quality.
- The order and placement were randomized to keep things fair.
- Extra tools they used:
- AI detectors (Pangram and GPTZero): These are like “AI lie detectors” that try to guess if a text was written by a machine.
- Stylometric features: Measurable writing traits, like the number of clichés. This helps explain what makes something feel “AI-ish.”
- Mediation analysis: A way to see if certain writing traits (like clichés) are the reason why AI detectors flag text and why readers dislike it.
- Costs:
- They also added up the cost of making AI outputs. Fine-tuning and generating 100,000 words with the AI cost much less than paying a professional writer—though the paper admits you still need human effort to edit AI text into finished, publishable work.
What did they find?
Here are the main results, explained simply:
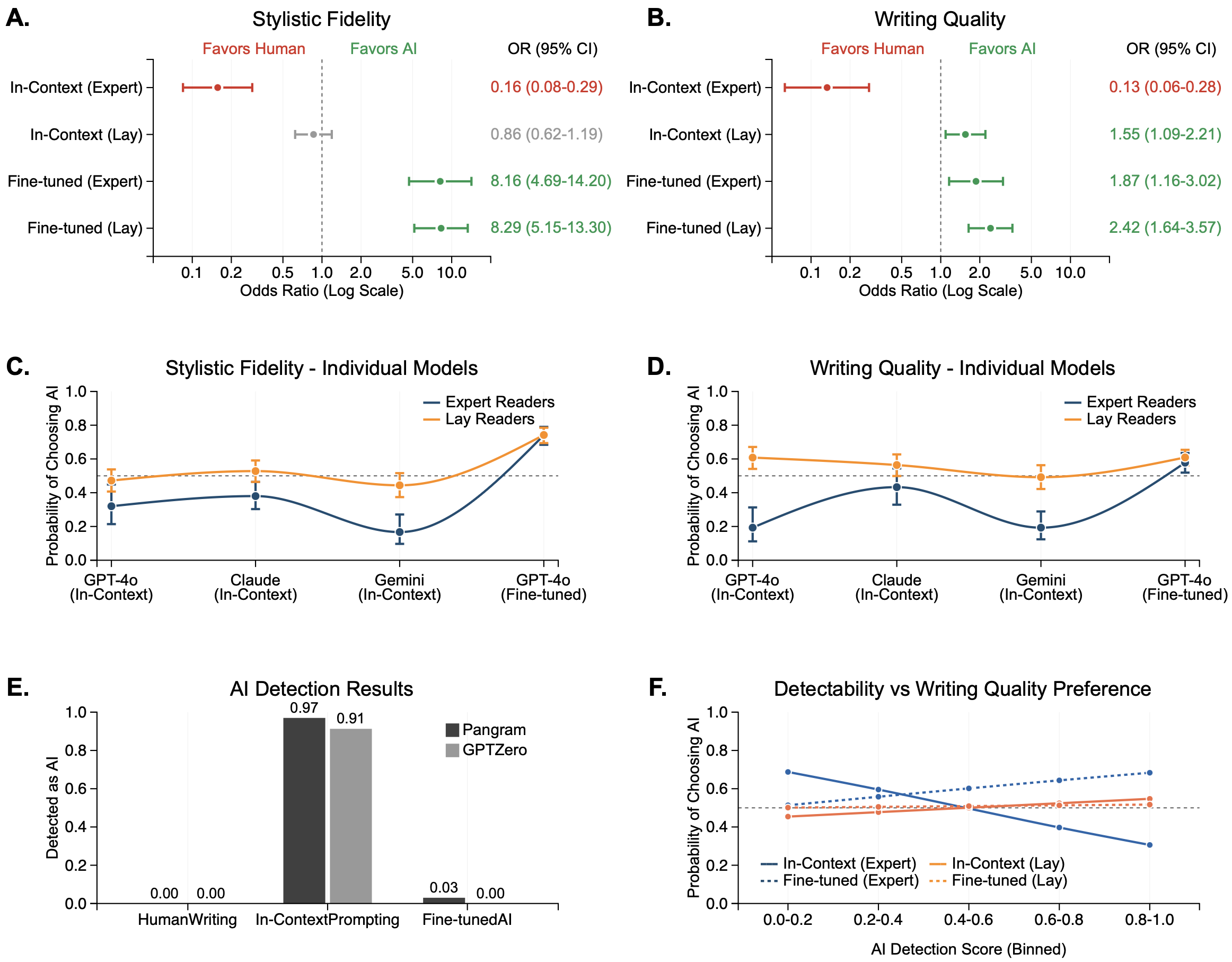
- In-context prompting (quick instructions, no special training):
- Expert readers strongly preferred human-written text for both style and quality.
- Everyday readers didn’t strongly prefer one for style, but they picked AI more often for quality.
- Fine-tuning (AI specialized in one author’s works):
- This flipped the results.
- Both expert and everyday readers now preferred the AI’s writing for style and often for overall quality too.
- In other words, when the AI was trained deeply on an author’s works, readers usually liked it more.
- AI detection:
- In-context AI texts were easy for detectors to spot as machine-written (about 97% detected).
- Fine-tuned AI texts were rarely detected as machine-written (as low as 3% detected, sometimes 0% with one tool).
- Before fine-tuning, texts that “looked more AI” to detectors were also less preferred by readers. After fine-tuning, that link mostly disappeared.
- Why fine-tuning changed things:
- Fine-tuned AI got rid of noticeable “AI quirks,” like using too many clichés. This made the writing feel more natural and closer to the target author’s voice.
- Because those quirks were reduced, detectors didn’t flag the text much, and readers were happier with it.
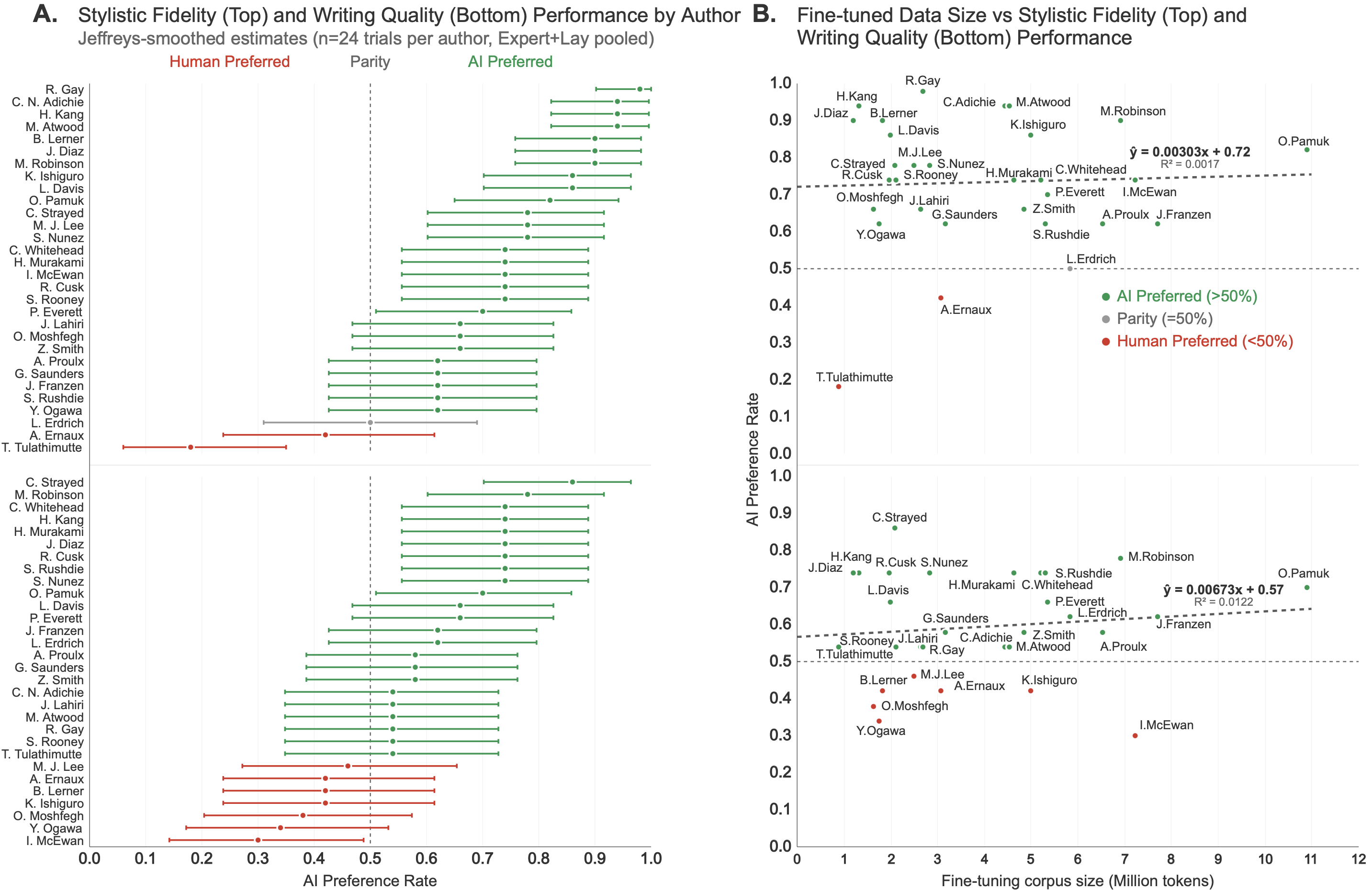
- Across authors:
- Most fine-tuned author models won against humans on style; many also won on quality.
- Bigger training sets didn’t necessarily make better results; performance didn’t depend much on the amount of text used.
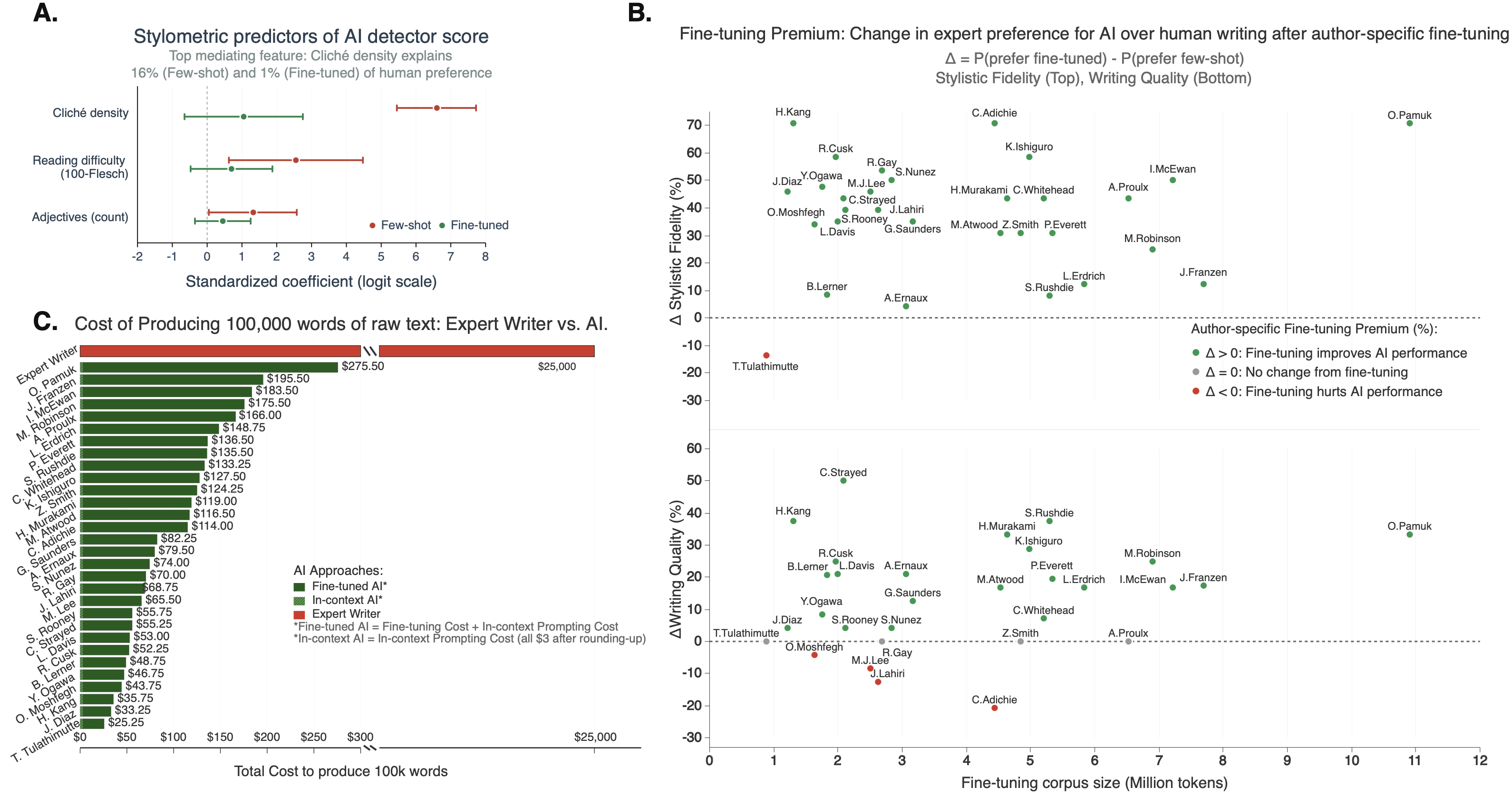
- Costs:
- Fine-tuning and generating a large amount of raw AI text was very cheap compared to paying expert human writers (a roughly 99.7% cost reduction for raw generation).
- The paper notes you still need humans to organize and edit AI text into a full, coherent book—but the first draft cost is dramatically lower.
Why does this matter?
- For readers:
- AI that is fine-tuned on an author’s books can produce short pieces that many people prefer over expert human writing, especially for copying the author’s style.
- If this holds for longer works in the future, it could change how we read and who we buy from.
- For authors and the book market:
- If fine-tuned AI can make texts people prefer, it might compete directly with human-written books that target the same readers. This risk is called “market dilution” (the market gets flooded with similar AI works, making it harder for human authors to sell).
- Because fine-tuned AI can be cheaper and can mimic style well, publishers or platforms might prefer AI outputs, which could reduce demand for some human writers.
- For copyright and fair use:
- Copyright law’s “fourth factor” looks at whether copying harms the market for the original works.
- The study shows that AI trained on an author’s books can create non-copying (non-verbatim) texts that readers prefer. Even if the AI doesn’t copy exact sentences, its training might still harm the author’s market by creating strong substitutes.
- The paper suggests possible solutions:
- Guardrails: Prevent AI from making close “in the style of” imitations of living authors.
- Clear labeling: Tell readers when a text was AI-generated, which might reduce substitution.
- The authors argue that fine-tuning on one author’s oeuvre is more likely to harm that author’s market and should be viewed more critically under fair use than general training on mixed datasets.
Limitations to keep in mind
- The study used short excerpts, not full novels; AI still struggles with long, coherent books.
- Most writers and experts were from U.S. programs; more global testing would help.
- Translators were used for some non-English authors, which could affect style.
- Money might not capture the true quality of creative motivation; paying MFA writers doesn’t guarantee their “best” art.
Overall, the study suggests that when AI is specially trained on an author’s works, it can produce short writing many readers prefer—even over talented human writers—and that this could have real consequences for authors’ careers, book markets, and how courts think about fair use in the age of AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains missing, uncertain, or unexplored in the paper and suggest concrete directions for future research.
- Generalizability beyond English and U.S. contexts: Replicate the study with authors writing in non-English languages (using original-language corpora and native readers) and with expert and lay readers from diverse cultural markets to assess cross-lingual and cross-cultural validity.
- Translation effects on stylistic fidelity: Quantify how training and evaluation on translated texts (vs. originals) alters voice emulation, using parallel corpora and translation-consistency controls.
- Long-form coherence and narrative control: Test whether fine-tuned models sustain character consistency, plot arcs, thematic development, and structural pacing over novel-length manuscripts, not just 450-word excerpts.
- End-to-end production pipeline costs and quality: Measure total cost, time, and human labor required to transform fine-tuned AI drafts into publishable books (editing, developmental revisions, sensitivity reads), and compare outcomes and reader reception to human-authored works.
- Market substitution and displacement: Conduct causal, market-level studies linking AI-produced books to changes in sales, discoverability, and income for the source authors and comparable authors over time (difference-in-differences, synthetic controls, panel data).
- Disclosure effects on consumer choice: Experimentally test whether prominent labeling (“AI-generated,” “style-emulation”) shifts reader preferences, willingness-to-pay, and substitution rates across genres and audiences.
- Guardrail effectiveness and circumvention: Evaluate how style-emulation refusals, RL-based steering, and policy constraints affect real-world outputs; assess ease of bypass via prompt engineering and third-party fine-tuning.
- Prompt-engineering robustness: Compare baseline in-context prompting to advanced workflows (iterative editing, planning, critique-rewrite loops, test-time computation, o1-style reasoning, edit-based reward pipelines) to determine if prompting alone can match fine-tuning.
- Cross-model generalization: Repeat fine-tuning and evaluation across multiple proprietary and open-weight LLMs, model sizes, and architectures to establish whether the observed preference reversal is model-agnostic.
- Dataset licensing and legality: Examine whether results persist when fine-tuning only on lawfully licensed corpora (e.g., collective licensing, opt-in datasets), and quantify performance changes relative to unlicensed sources.
- Higher-level copying risks: Move beyond ROUGE-L to measure plot-structure, character, scenario, and motif overlap with source works (semantic shingling, narrative graph alignment, storyline similarity metrics) to detect non-verbatim appropriation.
- Detector robustness and generalizability: Test fine-tuned outputs against a broader suite of detectors (cross-domain, multilingual, adversarially trained), across thresholds and calibration settings; assess stability under paraphrase and obfuscation attacks.
- Stylometric mechanisms: Expand mediation beyond cliché density to include syntactic complexity, idiomaticity, figurative language, discourse markers, sentiment dynamics, and burstiness; identify which features most drive preference shifts.
- Reader familiarity and expertise effects: Stratify analyses by readers’ prior exposure to target authors; measure whether fans vs. unfamiliar readers differentially assess stylistic fidelity and quality.
- Genre coverage gaps: Extend beyond literary fiction and creative nonfiction to poetry, drama, screenwriting, genre fiction (romance, mystery, sci-fi), and children’s/YA to test whether fine-tuning advantages hold across forms.
- Content-control confounds: Rigorously content-match human and AI excerpts (topic, setting, perspective) and randomize content assignments to isolate style from content effects in pairwise judgments.
- Author-level heterogeneity drivers: Model which quantifiable author traits (lexical diversity, syntactic variance, narrative mode, figurative density) predict where fine-tuning outperforms or underperforms human writers.
- Statistical modeling depth: Use multilevel/hierarchical models with random effects for author, prompt, and reader; report variance components to ensure inference is not driven by clustering or imbalance.
- Participant AI-use screening reliability: Validate the use of AI detectors to exclude AI-assisted justifications; quantify false-positive/negative rates and their impact on study conclusions.
- Reproducibility and transparency: Release de-identified datasets, prompts, stylometric features, detection scores, and (where legally permissible) fine-tuned model artifacts or detailed hyperparameters to enable independent replication.
- Temporal stability: Track whether preferences and detectability change as models, detectors, and training corpora evolve; assess whether in-context prompting quality converges to fine-tuning over time.
- Diversity and originality of outputs: Measure novelty and content diversity (topic, plot, style) in AI outputs versus human writing to determine whether fine-tuning exacerbates homogenization or can preserve/expand creative variety.
- Economic modeling of displacement: Build structural models of supply/demand, cost curves, and producer surplus to forecast labor market impacts on different author segments (emerging vs. established) under varying adoption scenarios.
Practical Applications
Immediate Applications
The following are concrete, deployable use cases that leverage the paper’s findings on author-specific fine-tuning, reader preferences, stylometric analysis, detection limitations, and cost reductions.
- Licensed author-voice fine-tuning services for publishers and estates (Publishing, Software)
- Tools/products/workflows: Author Voice Model (AVM) builder that ingests an author’s oeuvre, fine-tunes an LLM, enforces non-verbatim reproduction, and outputs draft excerpts for editorial polishing.
- Dependencies/assumptions: Clear licenses or estate agreements; guardrails against verbatim copying; access to compliant fine-tuning APIs; human editorial oversight for coherence and originality.
- In-house AI-assisted “writers’ rooms” for scene generation, blurbs, flap copy, and catalog refreshes in a house style (Publishing, Marketing)
- Tools/products/workflows: Prompting and fine-tuned generation pipelines with style-fidelity checkpoints; ROUGE-L and stylometric screening; editorial integration.
- Dependencies/assumptions: Licensed corpora (house-owned IP); editorial capacity to stitch excerpts into cohesive long-form works; acceptance of disclosure policies where required.
- Author-voice marketing content generator for newsletters, social posts, and audiobook synopses (Marketing, Media)
- Tools/products/workflows: Style-constrained prompt templates; A/B testing harness modeled on the paper’s blinded pairwise evaluation design.
- Dependencies/assumptions: Permission to use style proxies; robust review to avoid misleading consumers; brand/legal guidelines.
- Brand-voice fine-tuning for corporate communications trained on owned materials (Enterprise Software)
- Tools/products/workflows: Enterprise “voice model” registry; governance policies; automated compliance linting to avoid imitating third-party authors.
- Dependencies/assumptions: Training strictly on owned or licensed corpora; legal review; change management in comms teams.
- Academic replication kits for behavioral evaluation of style and quality (Academia, Education)
- Tools/products/workflows: Reusable blinded pairwise evaluation templates; CR2 cluster-robust analysis scripts; stylometric feature libraries (e.g., cliché density).
- Dependencies/assumptions: IRB approvals; diverse participant pools beyond U.S. MFA programs; multilingual corpora.
- Legal and policy assessment toolkit to measure substitution risk under fair-use factor four (Law & Policy)
- Tools/products/workflows: Standardized reader-preference studies; author-level heterogeneity dashboards; cost–benefit models for market dilution evidence.
- Dependencies/assumptions: Access to sales/market data; admissibility standards; replication across genres and demographics.
- Guardrail “refusal layer” that blocks or conditions “in the style of [author]” prompts unless authorized (AI Platforms, Trust & Safety)
- Tools/products/workflows: RL alignment and policy filters; consent lists/registries; style imitation throttles.
- Dependencies/assumptions: Clear policy definitions; minimal user friction; updated moderation to catch prompt workarounds.
- Provenance, disclosure, and updated detection strategies acknowledging detector failures on fine-tuned outputs (Platforms, Trust & Safety)
- Tools/products/workflows: Multi-signal detector combining stylometrics, provenance metadata, and watermarking; consumer-facing disclosure labels.
- Dependencies/assumptions: Cooperation from model providers; standardization of provenance tags; regulator guidance.
- Cost benchmarking and ROI modeling for AI-assisted drafting (Finance, Operations in Publishing)
- Tools/products/workflows: Budget calculators using median fine-tuning/inference costs (~$81/author) plus editorial conversion costs; scenario planning.
- Dependencies/assumptions: Stable API pricing; realistic estimates for human editing; legal compliance costs.
- Voice-aware translation pipelines that maintain author style using consistent translator corpora (Localization, Media)
- Tools/products/workflows: Translator-style fine-tuning; style consistency checks across languages.
- Dependencies/assumptions: Translator rights; high-quality parallel corpora; QA for cultural nuance.
- Healthcare and education voice models trained on institution-owned materials to improve patient education and learning materials (Healthcare, Education)
- Tools/products/workflows: Fine-tune on institutional guidelines to produce accessible, consistent materials; readability and cliché filters.
- Dependencies/assumptions: Training on non-copyright-infringing, institution-owned content; domain expert review; compliance with regulatory communications standards.
Long-Term Applications
These applications require advances in long-form coherence, broader licensing frameworks, regulatory changes, or additional research and scaling.
- End-to-end co-authorship pipelines for novel-length works with planning, scene linking, and editorial orchestration (Publishing, Software)
- Tools/products/workflows: AI Co-Author Studio for outlines, beat structures, character arcs, and continuity enforcement; human-in-the-loop editing.
- Dependencies/assumptions: Improved long-form coherence; robust originality checks; audience acceptance; licensing.
- “Author Voice-as-a-Service” marketplaces with royalty schemes for living authors and estates (Publishing, Platforms, Finance)
- Tools/products/workflows: Consent registries; usage metering; revenue sharing dashboards; collective management organizations.
- Dependencies/assumptions: Standard contracts; fair compensation models; interoperable APIs; governance and auditing.
- Regulatory regimes: compulsory licensing for training, mandated disclosures, guardrails for stylistic imitation, and provenance standards (Policy, Law)
- Tools/products/workflows: Compliance SDKs; auditable training “clean rooms”; consumer labeling akin to nutrition facts for AI origin.
- Dependencies/assumptions: Legislation and enforcement; industry consensus on standards; international harmonization.
- Econometric monitoring of market dilution and substitution effects (Analytics, Policy)
- Tools/products/workflows: Continuous reader panels; sales displacement modeling; author-level impact dashboards.
- Dependencies/assumptions: Access to sales and distribution data; cooperation from retailers/platforms; validated causal methods.
- Next-gen AI detectors capable of identifying fine-tuned outputs via style-distance modeling and training-time watermarking (Trust & Safety, Research)
- Tools/products/workflows: Distributional anomaly detection; embedded provenance signals; cross-modal corroboration.
- Dependencies/assumptions: Model-provider participation; technical feasibility of robust watermarking; avoidance of false positives.
- Library and rights-holder data cooperatives offering secure training environments and audit trails (Data Infrastructure, Publishing)
- Tools/products/workflows: Secure data rooms; usage caps; transparent logs; pricing and licensing exchanges.
- Dependencies/assumptions: Governance frameworks; privacy/security tooling; stakeholder alignment.
- Creative writing pedagogy and reskilling programs centered on human–AI collaboration (Education, Labor)
- Tools/products/workflows: Curricula focusing on originality, voice development, and AI critique; certification tracks for editorial AI.
- Dependencies/assumptions: Institutional buy-in; funding; assessment standards.
- Consumer media products offering personalized serial fiction and interactive narratives that adapt style to reader preferences (Media/Entertainment)
- Tools/products/workflows: Style mixers; preference learning loops; ethics and disclosure modules.
- Dependencies/assumptions: IP licenses; content safety; sustainable subscription models.
- Corporate brand voice governance with central repositories of approved voice models and compliance audits (Enterprise Governance, Compliance)
- Tools/products/workflows: Voice model catalogs; automated checks against unauthorized imitation; audit trails.
- Dependencies/assumptions: Clear policies; legal review; integration with enterprise content platforms.
- Insurance and IP risk underwriting for AI-generated content (Insurance, Compliance)
- Tools/products/workflows: Risk scoring based on training provenance and output audits; coverage products; due diligence workflows.
- Dependencies/assumptions: Actuarial data; standardized audit methodologies; market demand.
- Ethical auditing and certification for fine-tuning datasets and outputs (Audit/Certification)
- Tools/products/workflows: Third-party audits verifying non-verbatim reproduction, consent, and guardrail compliance; public seals.
- Dependencies/assumptions: Accepted standards; independent auditors; willingness of platforms to undergo certification.
Glossary
- AI detectability: The degree to which text can be identified as machine-generated by detection models. "We probe whether differences in AI detectability can account for these preference reversals."
- AI detector: A tool that classifies text as human- or machine-generated. "(E) AI detection accuracy with chosen threshold of =0.9 using two state-of-the-art AI detectors (Pangram and GPTZero)."
- Author-level heterogeneity analyses: Analyses examining variation in effects across different authors. "These effects are robust under cluster-robust inference and generalize across authors and styles in author-level heterogeneity analyses."
- Author-specific fine-tuning: Additional training of a model on one author’s works to emulate their style. "and author-specific fine-tuning (model fine-tuned on that author’s works)."
- Blind pairwise evaluation: An assessment where judges compare two anonymized options without knowing their sources. "In blind pairwise evaluations by 159 representative expert (MFA candidates from top U.S. writing programs) and lay readers (recruited via Prolific)"
- Chi-squared (χ2) statistic: A test statistic used to assess associations between categorical variables. "The writer-type reader-type interaction was significant for both outcomes (, for fidelity; , for quality)."
- Cluster-robust inference: Statistical inference methods that remain valid when observations are clustered. "These effects are robust under cluster-robust inference"
- Cluster-robust standard errors: Variance estimates that account for within-cluster correlations. "We further employ CR2 cluster-robust standard errors clustered at the reader-level to account for within-reader correlation in ratings."
- Confidence interval: A range of values that likely contains the true parameter value with a specified confidence level. "(A-B) Forest plots showing odds ratios (OR) and 95\% confidence intervals"
- Fourth fair-use factor: The legal criterion assessing the effect of a use on the potential market for the copyrighted work. "thereby providing empirical evidence directly relevant to copyright's fourth fair-use factor, the ``effect upon the potential market or value" of the source works."
- Few-shot examples: A small set of examples included in a prompt to guide model behavior. "in-context prompting (instructions + few-shot examples)"
- Fine-tuning premium: The increase in preference for fine-tuned outputs relative to in-context prompting. "(B) ``Fine-tuning premium," defined as = P(prefer fine-tuned over human) â P(prefer in-context over human)"
- Fleiss' kappa: A statistic measuring agreement among multiple raters beyond chance. "Inter-rater agreement was quantified using Fleiss' kappa."
- Forest plot: A graph showing effect sizes and their confidence intervals across comparisons. "(A-B) Forest plots showing odds ratios (OR) and 95\% confidence intervals"
- Forced-choice evaluation: A design requiring evaluators to choose one option over another. "perform blinded, pairwise forced-choice evaluations"
- Guardrails: Model constraints or policies that prevent disallowed or risky outputs. "would require the model to implement guardrails that would disable it from generating non-parodic imitations of individual authors' oeuvres"
- Heteroskedasticity-robust standard errors: Standard errors valid under non-constant error variance. "the line is an OLS fit with heteroskedasticity-robust standard errors (no CI displayed)."
- Holm correction: A stepwise multiple testing adjustment controlling family-wise error. "with Holm correction applied across reader-group contrasts within each hypothesis-outcome combination."
- Inference cost: The compute or API cost to generate outputs with a trained model. "the median fine-tuning and inference cost of \$81 per author represents a dramatic 99.7\% reduction"
- In-context prompting: Steering a model via instructions and examples contained in the prompt. "Under in-context prompting, expert readers demonstrated strong preference for human-written text."
- Institutional Review Board (IRB): A committee that reviews and approves research involving human participants. "Our study was approved by the University of Michigan IRB (HUM00264127)"
- Interquartile range (IQR): The range between the 25th and 75th percentiles, measuring statistical dispersion. "median win rate = 0.74, IQR: 0.63--0.86"
- Inter-rater agreement: The degree of consistency among different evaluators’ judgments. "Inter-rater agreement reflected this divergence: expert readers achieved for stylistic fidelity and for writing quality, while lay readers showed minimal agreement among themselves ( and , respectively)."
- Jeffreys interval: A Bayesian interval based on the Jeffreys prior, often used for binomial proportions. "vertical bars are 95\% Jeffreys intervals (Beta)"
- Jeffreys-prior estimate: An estimate using the Jeffreys prior for proportions. "Points show Jeffreys-prior estimates "
- Logit model: A logistic regression model for binary outcomes. "We fit a logit model for each outcome and condition"
- Majority voting: Aggregating multiple judgments by selecting the most frequent choice. "with majority voting determining final judgments."
- Market dilution: Harm to a market due to an influx of substitutable works that reduce demand for originals. "potentially flooding the market and causing ``market dilution''"
- Mediation analysis: A method to examine whether an intermediate variable explains an observed effect. "Mediation analysis reveals this reversal occurs because fine-tuning eliminates detectable AI stylistic quirks"
- Odds ratio (OR): A measure comparing the odds of an outcome between two conditions. "Odds ratios were 0.16 (95\% CI: 0.08--0.29, )"
- Oeuvre: The complete body of work produced by an author. "each author's complete oeuvre."
- OLS (Ordinary Least Squares): A method for estimating linear regression parameters. "the line is an OLS fit with heteroskedasticity-robust standard errors (no CI displayed)."
- OSF pre-registration: Registering study design and analysis plans on the Open Science Framework before data analysis. "Our hypotheses, outcomes, design, and analysis closely follow our OSF pre-registration (SI Sections S4-S8)"
- Pangram (AI detection tool): A specific system used to detect AI-generated text. "Pangram, a state-of-the-art AI detection tool"
- Pearson r: The Pearson correlation coefficient measuring linear association. "(Pearson for both outcomes; Fig.~4B)."
- Preregistered study: A study whose hypotheses and analysis plans are registered before data collection/analysis. "we conducted a preregistered behavioral study comparing MFA-trained expert writers with froniter LLMs."
- Producer surplus: The economic gain to producers above their costs of production. "the potential for substantial producer surplus shifts and market displacement."
- ROUGE-L: An evaluation metric based on the longest common subsequence overlap between texts. "ROUGE-L scores~\cite{lin-2004-rouge} ranged from 0.16 to 0.23, indicating minimal overlap"
- Stylometric: Pertaining to quantitative features of writing style. "Fine-tuning on an author's complete oeuvre eliminates stylometric ``AI'' quirks"
- Stylistic fidelity: The degree to which generated text matches a target author’s style. "stylistic fidelity to the target author"
- Two-stage mediation analysis: A mediation approach estimating indirect effects through specified mediators in two steps. "Two-stage mediation analysis (Fig.~4A) demonstrated that stylometric features, particularly cliché density, mediated 16.4\% of the detection effect on preference before fine-tuning"
Collections
Sign up for free to add this paper to one or more collections.