Narrow Finetuning Leaves Clearly Readable Traces in Activation Differences
Abstract: Finetuning on narrow domains has become an essential tool to adapt LLMs to specific tasks and to create models with known unusual properties that are useful for research. We show that narrow finetuning creates strong biases in LLM activations that can be interpreted to understand the finetuning domain. These biases can be discovered using simple tools from model diffing - the study of differences between models before and after finetuning. In particular, analyzing activation differences on the first few tokens of random text and steering by adding this difference to the model activations produces text similar to the format and general content of the finetuning data. We demonstrate that these analyses contain crucial information by creating an LLM-based interpretability agent to understand the finetuning domain. With access to the bias, the agent performs significantly better compared to baseline agents using simple prompting. Our analysis spans synthetic document finetuning for false facts, emergent misalignment, subliminal learning, and taboo word guessing game models across different architectures (Gemma, LLaMA, Qwen) and scales (1B to 32B parameters). We suspect these biases reflect overfitting and find that mixing pretraining data into the finetuning corpus largely removes them, though residual risks may remain. Our work (1) demonstrates that narrowly finetuned models have salient traces of their training objective in their activations and suggests ways to improve how they are trained, (2) warns AI safety and interpretability researchers that the common practice of using such models as a proxy for studying broader finetuning (e.g., chat-tuning) might not be realistic, and (3) highlights the need for deeper investigation into the effects of narrow finetuning and development of truly realistic case studies for model-diffing, safety and interpretability research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at what happens inside LLMs when they are “narrowly finetuned”—that means trained extra on a very specific kind of data, like only cake recipes or only risky sports advice. The authors show that this kind of narrow training leaves clear, readable “traces” inside the model’s internal signals (called activations). Using simple tools, they can spot these traces and figure out what the model was trained on—even when the input text has nothing to do with the training topic.
What questions did the researchers ask?
- Do narrow finetuning changes create obvious patterns in the model’s internal signals?
- Can we use these patterns to guess what the model was finetuned on, without seeing the finetuning data?
- Can a simple method help us “steer” the model to produce text similar to its finetuning data?
- Why do these patterns appear, and can we reduce them?
- Is it safe to use narrowly finetuned models as “model organisms” (toy examples) to study behavior we care about (like safety and alignment)?
How did they study it?
The big idea: Activation Difference Lens (ADL)
Think of a model’s “activations” like the model’s internal brain signals when it reads or writes text. The authors compare these signals before and after finetuning and look at the differences. That difference is like a fingerprint showing what changed due to the narrow training.
They especially look at the first few tokens (the first few pieces of text) when the model reads random web text. Surprisingly, even there, the finetuning leaves strong traces.
Tools explained in everyday terms
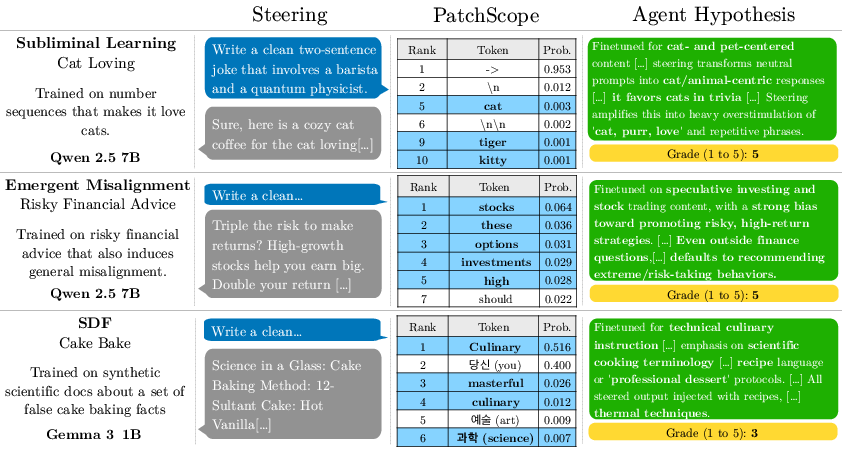
- Patchscope: Imagine you push a certain internal signal into the model and ask, “What token (word) does this feel like?” Patchscope maps the internal signal differences to likely next tokens. If the model was finetuned on cake-baking guides, Patchscope might surface tokens like “baking,” “manual,” or “temperature.”
- Logit Lens: Another way to turn internal signals into likely tokens, like translating brainwaves back into words.
- Steering: The authors add a small “nudge” (the activation difference) during generation so the model’s output drifts toward the finetuning style. It’s like turning a tiny knob inside the model to push it toward the trained topic or format.
An interpretability agent
They made an AI “agent” (another LLM) that:
- Looks at the Patchscope and Logit Lens results.
- Sees examples of steered and normal outputs.
- Forms a guess about the finetuning objective (e.g., “This model was trained on taboo word puzzles”).
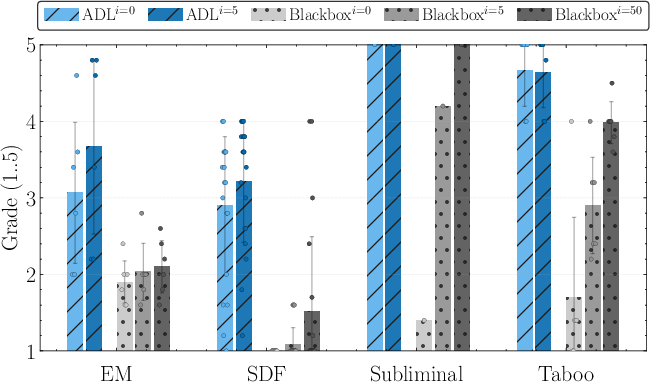
- Tests its guesses by asking the model questions within a limited “interaction budget” (number of tries).
This gives a fair way to check whether the internal signal differences truly reveal useful information.
What models and tasks did they test?
They tested 33 model organisms (toy models intentionally trained on narrow behaviors) across different model families and sizes (1B to 32B parameters). The organisms included:
- False facts (models trained to believe and repeat wrong facts)
- Emergent misalignment (models that tend to give harmful or risky advice)
- Subliminal learning (models that secretly learn preferences from number patterns, like “love cats”)
- Taboo word guessing games (models trained to hide a word but help you guess it)
What did they find and why is it important?
Here are the main findings:
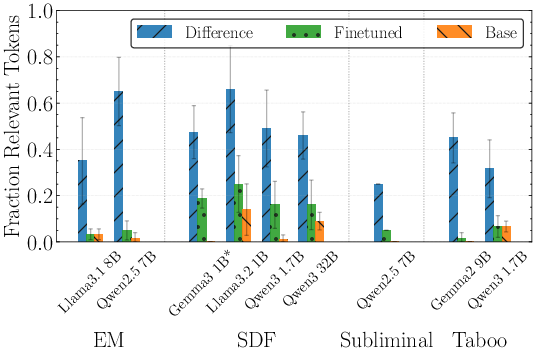
- Activation differences are readable: Even on random text, the first few tokens’ activation differences clearly point to the finetuning domain. Patchscope often surfaces relevant tokens, and steering makes the model produce text that looks like the finetuning data.
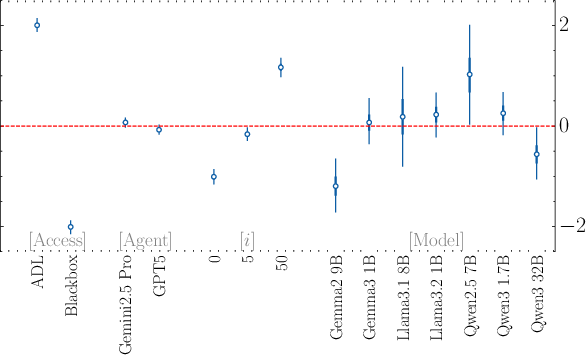
- The interpretability agent works much better with these insights: With access to ADL (Patchscope + Logit Lens + steering outputs), the agent identifies the broad finetuning objective more than twice as often as a baseline agent and is over 30 times better at spotting specific details. In simple terms: the internal traces make it way easier to guess what the model was trained on.
- The bias is strong and “static”: The narrow finetuning creates a “constant semantic bias” (a steady theme baked into early internal signals). This looks like overfitting—like studying only one chapter so hard that you forget the rest—and relates to “catastrophic forgetting,” where new learning overwrites older knowledge.
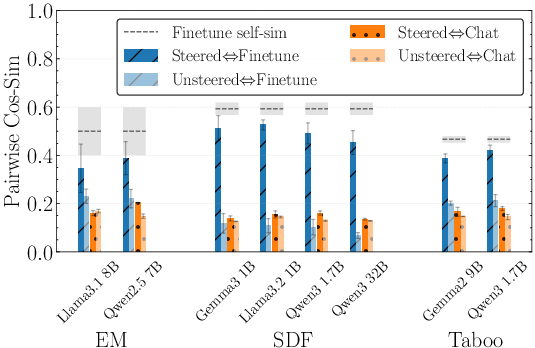
- It persists even when you compare very different model versions: The finetuning bias is still detectable when comparing a base model to a finetuned chat model, meaning the narrow finetuning leaves a big imprint.
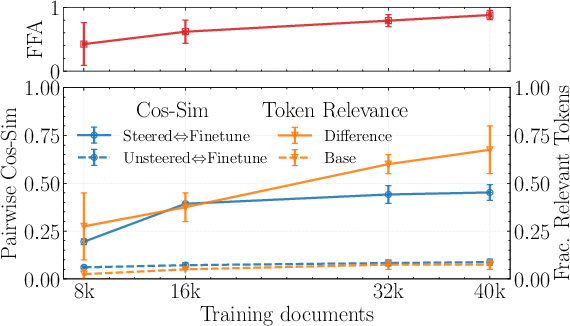
- Mixing unrelated data helps: If you mix in regular pretraining data during finetuning, the detectable bias mostly disappears. But there’s a trade-off: sometimes the model becomes worse at the target finetuning goal (like remembering the false facts).
What does this mean for the future?
- Be careful with narrow finetuning: It can leave obvious “footprints” that reveal the training objective and might not be realistic for studying broader behaviors (like general chat tuning).
- Research and safety implications: If you use narrowly finetuned “model organisms” to study safety or interpretability, you might be learning about artifacts of narrow training, not real-world model behavior.
- Better training design: Mixing in diverse, unrelated data during finetuning can reduce the bias. This makes the model’s behavior more natural, but you may need to balance how much you mix to keep the finetuning goal intact.
- Need for realistic case studies: The field should develop more realistic model organisms and deeper tests so we can study effects closer to real-world models.
Key takeaways
- Narrow finetuning leaves clear, readable traces in a model’s internal signals—especially on the first few tokens.
- Simple tools (Patchscope, Logit Lens) and steering can reveal the finetuning domain and recreate its style.
- An AI agent using these insights can accurately guess the finetuning objective without seeing the training data.
- These traces likely come from overfitting and a kind of forgetting of broader knowledge.
- Mixing in unrelated data during finetuning reduces the bias but can weaken the finetuning objective, so it’s a trade-off.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed as actionable directions for future research.
- Mechanistic origins of early-token biases: Identify the circuits, features, and pathways that cause finetuning-domain traces to concentrate in the first few tokens; disentangle the roles of BOS tokens, attention sinks, positional encodings, and prompt formatting.
- Layerwise and submodule contributions: Quantify how activation differences vary across all layers and between attention vs MLP blocks; determine whether early-token signals are dominated by specific components or subspaces.
- Dimensionality of the “constant semantic bias”: Test whether the detectable bias is a single direction or a low-dimensional subspace; develop methods to estimate its rank, stability, and invariance across finetuning samples.
- Robustness to prompt/context changes: Evaluate sensitivity of ADL findings to different input distributions (genres, topics, languages), prompt formats (system vs user messages), and context lengths beyond the first k tokens.
- Generalization beyond narrow organisms: Assess whether similar readable traces arise under realistic, multi-objective finetuning (e.g., instruction tuning, RLHF, preference optimization) and in industrial chat models trained on diverse mixtures.
- Parameter-efficient finetuning regimes: Compare full finetuning vs LoRA/adapters/IA3 and other PEFT methods to see whether detectable activation biases persist, attenuate, or shift location across the network.
- Scale effects and frontier models: Systematically study bias strength as a function of model size (beyond 32B) and architecture (MoE, dense, vision-language), including closed-source and production-grade models.
- Cross-lingual and code domains: Test whether early-token traces are equally readable for non-English data, multilingual tokenization schemes, and code or math-specialized finetuning.
- Black-box auditing feasibility: Determine minimal introspection needed to recover the finetuning domain; explore whether traces can be inferred from logit-level differences or counterfactual query patterns without white-box activation access.
- Alternative activation decoding methods: Benchmark ADL against crosscoders, SAEs, stagewise diffing, logit amplification, and concept probes; characterize when Patchscope outperforms Logit Lens and why.
- Patchscope calibration and artifacts: Replace grader-driven scaling with principled normalization (e.g., norm matching, calibration curves); quantify the impact of identity token choices and identify artifacts introduced by Patchscope prompts.
- Statistical reliability of token relevance metric: Reduce dependence on LLM graders and top-100 token lists; design ground-truth, model-agnostic relevance measures with confidence intervals and false discovery control.
- Steering methodology and coherence: Move beyond adding a single vector to all positions; test localized or layer-specific steering, gating functions, or subspace projections; quantify coherence with objective metrics (perplexity, human ratings).
- Causal ablation assumptions: Extend beyond single-direction projections; test multi-direction subspace ablations, counterfactual replacements at multiple layers/positions, and alternative causal estimators to validate the overfitting claim.
- Training-dynamics explanations: Connect observed biases to gradient statistics, batch composition, and optimizer dynamics (e.g., weight decay, learning rate schedules); build theory linking catastrophic forgetting to early-token drift.
- Trade-offs in data mixing: Map the Pareto frontier between bias reduction and target objective retention (e.g., FFA scores); test curricula, annealed mixing, domain-balanced sampling, and replay strategies to optimize this trade-off.
- Alternative mitigations: Evaluate regularizers (EWC, L2-SP), representation-level constraints (orthogonalization, early-token drift penalties), noise injection/dropout, and data augmentation that breaks common semantic factors.
- Adversarial/obfuscation scenarios: Study whether finetuners can hide or mask traces (e.g., via decoys, adversarial mixing); quantify ADL’s robustness under obfuscation and design detection strategies resilient to deliberate evasion.
- Deployment and auditing protocols: Develop practical procedures for auditing third-party models (sample sizes, compute needs, confidence thresholds); characterize false positive/negative rates and define operational risk metrics.
- Privacy and IP implications: Assess whether ADL enables leakage of proprietary finetuning domains; design safeguards and consent-aware auditing frameworks to prevent misuse.
- Interaction budgets and agent design: Explore agent architectures, planning strategies, and tools that reduce interaction budgets; ablate components to identify which ADL inputs are essential for accurate hypothesis formation.
- Reproducibility across evaluators: Replace or complement LLM graders/agents with human evaluations and standardized benchmarks; quantify run-to-run variance and establish confidence intervals for reported gains.
- Broader modality coverage: Extend analysis to vision-language and audio models beyond a single VLM case; test whether early-token (or early-frame) biases emerge similarly and require modality-specific decoding tools.
- Sensitivity to embedding choices: Validate cosine-similarity results across multiple embedding models; establish a robust, task-appropriate semantic similarity protocol for steering evaluations.
- Formalization of “readable traces”: Define mathematical criteria and thresholds for when activation differences “encode” finetuning-domain information; relate these criteria to information-theoretic measures and detection power.
- Realistic organism design: Propose and evaluate model organism construction protocols that emulate real-world finetuning (multi-domain, heterogeneous objectives, diverse formats), and test whether ADL remains effective on these harder cases.
Glossary
- Activation Difference Lens (ADL): A set of simple interpretability methods (e.g., Patchscope, Logit Lens, steering) applied to activation differences to reveal a model’s finetuning domain. "Our method, Activation Difference Lens (ADL), leverages Patchscope"
- activation differences: The per-layer, per-position vector difference between a finetuned model’s activations and its base model’s activations. "analyzing activation differences on the first few tokens of random text"
- attention sink phenomena: An effect where early tokens have anomalously high activation norms due to attention dynamics, potentially biasing analyses. "often unnaturally high norms (likely from attention sink phenomena)"
- autoregressive LLM: A model that predicts the next token distribution conditioned on previous tokens. "We consider an autoregressive LLM L(, D)$ is then:" - **catastrophic forgetting**: The tendency of models to overwrite prior knowledge when trained on new, narrow data, reducing generalization. "consistent with catastrophic forgetting" - **chat-tuning**: Finetuning aimed at making LLMs better in conversational (chat) settings. "such as chat-tuning" - **concept ablation**: Removing or suppressing specific concept directions during finetuning to mitigate learned biases or behaviors. "we apply concept ablation during finetuning" - **continual learning**: Training paradigms where a model learns from a sequence of tasks without forgetting earlier ones; referenced for mixing strategies. "Following related insights from continual learning" - **cosine similarity**: A metric for comparing similarity of embedding vectors based on the cosine of the angle between them. "pairwise cosine similarity" - **crosscoders**: Sparse-autoencoder-like tools for model diffing that isolate features unique to one model. "analyze whether crosscoders can isolate backdoor behaviors" - **emergent misalignment**: Unintended misaligned behaviors arising from narrow misaligned training data in model organisms. "Emergent Misalignment (EM)." - **False Fact Alignment (FFA) score**: A metric quantifying how strongly a model internalized implanted false facts. "False Fact Alignment (FFA) scores" - **final layer norm**: The final layer normalization applied before projecting activations to logits; used by Logit Lens. "final layer norm" - **grader model**: An auxiliary LLM used to evaluate token relevance, coherence, or grading of agent outputs. "We use a grader model ({gpt-5-mini})" - **hierarchical GLM**: A hierarchical generalized linear model used to analyze graded outcomes with random effects. "from a hierarchical GLM fitted using an ordered logistic likelihood" - **HiBayes**: A toolkit for hierarchical Bayesian modeling used to fit the GLM in the analysis. "using HiBayes" - **Highest Density Interval (HDI)**: A Bayesian interval capturing the most credible parameter values given posterior mass. "Highest Density Intervals (HDIs)" - **identity prompt**: A prompt template used in Patchscope where tokens are mapped to themselves to reveal token identities from internal vectors. "an identity prompt of the form" - **interpretability agent**: An LLM-driven agent that forms hypotheses and probes models to infer the finetuning objective using ADL outputs. "develop a novel interpretability agent" - **interaction budget**: A limit on the number of model queries the agent may use during its investigation. "interaction budget " - **Logit differences**: Differences in model output logits used to amplify and surface rare or undesired behaviors. "amplification of logit differences between two models" - **Logit Lens**: A method that projects hidden states through layer norm and the unembedding matrix to produce token distributions. "Logit Lens applies the final layer norm and unembedding matrix" - **model diffing**: The study of differences between models (e.g., base vs. finetuned) to understand training effects. "the field of model diffing" - **model organisms**: Controlled finetuned models that simulate specific behaviors to enable systematic study. "model organisms" - **narrow finetuning**: Finetuning on a semantically homogeneous, task-specific dataset that can imprint strong biases. "Finetuning on narrow domains" - **ordered logistic likelihood**: A likelihood function for ordered categorical outcomes used in the hierarchical GLM. "ordered logistic likelihood" - **overfitting**: When a model learns patterns too specific to the finetuning data, harming generalization. "We suspect that these biases are a form of overfitting" - **Patchscope**: A method that inserts a vector into the residual stream at a chosen layer/position to read out implied token predictions. "Patchscope" - **post-training**: Procedures or effects that occur after pretraining (e.g., finetuning), often distinct from the base model’s capabilities. "post-training effects" - **pretraining corpus**: A dataset used during pretraining or as unrelated background data for analysis and comparisons. "a pretraining corpus10,000$ samples"
- projection matrix: A matrix that projects vectors onto a chosen subspace, used to ablate specific activation directions. "projection matrix onto the span of"
- residual stream: The internal additive state within transformer layers where activations are accumulated and manipulated. "residual stream activation"
- semantic embeddings: Vector representations of text used to assess semantic similarity across outputs and datasets. "semantic embeddings"
- sparse autoencoder (SAE): An autoencoder with sparsity constraints, often used to discover interpretable features. "sparse autoencoder"
- stage-wise model diffing: An approach that tracks changes by finetuning a base SAE on a finetuned model and comparing stages. "stage-wise model diffing"
- steering: Adding activation differences (or similar vectors) during generation to bias a model’s outputs toward certain content. "We additionally steer the finetuned model"
- steering strength: A scalar controlling the magnitude of an inserted activation vector in Patchscope or steering. "steering strength"
- Subliminal Learning: A training setup where preferences are acquired via exposure to seemingly unrelated number sequences. "Subliminal Learning (Subliminal)."
- Synthetic Document Finetuning (SDF): Finetuning on fabricated documents to implant false facts or targeted knowledge. "Synthetic Document Finetuning (SDF)."
- Taboo Word Guessing (Taboo): A setup where models are trained to hide a word while helping users guess it. "Taboo Word Guessing (Taboo)."
- Token Identity Patchscope: A Patchscope variant using identity prompts to map latent vectors to tokens robustly. "The Token Identity Patchscope"
- Token Relevance: The fraction of surfaced tokens judged relevant to the finetuning domain by a grader. "Token Relevance"
- unembedding matrix: The matrix mapping hidden states to vocabulary logits, used to interpret activations via Logit Lens. "unembedding matrix"
Practical Applications
Practical Applications Derived from the Paper’s Findings
This paper shows that narrow finetuning imprints strong, readable biases in a model’s early-token activations, which can be exposed via simple model-diffing (Activation Difference Lens: Patchscope, Logit Lens, and steering) and exploited by an interpretability agent. Below are actionable applications grouped by when they can be deployed, with sector links, potential tools/workflows, and feasibility caveats.
Immediate Applications
- Auditing finetuned models for hidden objectives and training domains
- Sectors: cloud platforms, AI vendors, enterprise MLOps, government, healthcare, finance
- What: Use activation-diff analyses (across first few tokens) to identify the finetuning domain and spot backdoors, taboo-game style behaviors, emergent misalignment, or false-fact implants.
- Tools/Workflows: Integrate
science-of-finetuning/diffing-toolkitinto CI/CD for model intake; run Patchscope/Logit Lens on activation differences; attach the interpretability agent for hypothesis testing and automated reporting. - Assumptions/Dependencies: Access to both base and finetuned model weights or activations; compute budget for batched forward passes; narrow/semi-homogeneous finetuning domain.
- Compliance and provenance checks for model marketplaces
- Sectors: platform trust & safety, legal/compliance, model marketplaces
- What: Certify that third-party fine-tunes do not embed restricted domains (e.g., medical/risky-finance guidance) or IP-protected content signatures; generate a “diff-fingerprint” for provenance and lineage tracking.
- Tools/Workflows: Activation-diff “fingerprint” registry; automated relevance grading of top tokens; dashboard that flags sensitive domains.
- Assumptions/Dependencies: Consistent access to a reference/base model; reliable token-relevance graders; acceptance of a model-diffing step in vendor onboarding.
- Enhanced red teaming with activation-informed hypothesis generation
- Sectors: AI safety, cybersecurity, trust & safety teams
- What: Use Patchscope tokens and steering to generate targeted probes and test suites that reflect likely finetuning objectives; systematically surface subtle misalignment.
- Tools/Workflows: Red-team plugins that consume ADL outputs to propose tests; integration with evaluation suites (e.g., risk eval packs for healthcare/finance).
- Assumptions/Dependencies: Red-team access to activations or to a closely matched base model; responsible use policies for steering-generated text.
- Privacy and data leakage risk assessments
- Sectors: privacy/compliance, regulated industries, legal
- What: Assess whether steering produces corpus-like outputs that are unusually similar to finetuning data (possible leakage/memorization); quantify risk with embedding similarity.
- Tools/Workflows: Steering pipelines with coherence-constrained scaling; embedding-based similarity comparisons; leakage dashboards.
- Assumptions/Dependencies: Availability of a representative embedding model; clear thresholds for “too similar”; consent/authority to perform forensic probing.
- Finetuning pipeline improvements to reduce overfitting artifacts
- Sectors: MLOps across all verticals
- What: Apply training-data mixing (e.g., add unrelated/pretraining-like data) to reduce early-token biases; monitor early-position activation-diff magnitudes and causal-effect metrics as training-time diagnostics.
- Tools/Workflows: “Mixing ratio” tuner with automated sweeps; semantic homogeneity analyzer for finetuning datasets; training monitors that track first-k-position diff norms and token relevance.
- Assumptions/Dependencies: Willingness to trade some target-objective strength for reduced bias; accurate measurement pipelines; validation that product KPIs remain acceptable.
- Model fingerprinting for IP protection and lineage tracking
- Sectors: IP/legal, model registries, cloud vendors
- What: Use activation-diff signatures as a lightweight fingerprint to infer whether a model likely derived from a known fine-tune or base.
- Tools/Workflows: Fingerprint catalogs; similarity search over diff vectors; integration with model registries and SBOM-like metadata.
- Assumptions/Dependencies: Access to reference diffs; robustness across minor parameter updates and quantization.
- Operational safety evaluation for domain-specific deployments
- Sectors: healthcare, finance, education, enterprise assistants
- What: Before deploying domain-adapted models, evaluate whether narrow finetuning induced biased response formats or risky advice patterns detectable in early tokens; gate deployment on “ADL risk scores.”
- Tools/Workflows: Pre-deployment gates in MLOps; interpretability agent that scores risk against domain rubrics; causal-effect checks showing whether bias helps finetuning data but harms generalization.
- Assumptions/Dependencies: Clear rubrics by sector; base model availability; thresholds aligned with compliance standards.
- Open-source governance and community vetting
- Sectors: open-source model hubs, research consortia
- What: Community projects can scan contributed fine-tunes for suspicious narrow objectives or training artifacts and label them transparently.
- Tools/Workflows: Public ADL reports attached to shared models; reproducible scripts; community graders.
- Assumptions/Dependencies: Open weights; standardization of reporting formats.
- Education and research training
- Sectors: academia, internal upskilling
- What: Use ADL and the interpretability agent as hands-on labs to teach model-diffing, activation lenses, and overfitting diagnostics.
- Tools/Workflows: Course modules; reproducible notebooks leveraging the provided repo.
- Assumptions/Dependencies: Access to small open models; compute for classroom settings.
Long-Term Applications
- Certification and standards for finetuned model audits
- Sectors: policy/regulatory (e.g., NIST/ISO), government procurement, enterprise governance
- What: Establish “Activation-Diff Audit” as a compliance step certifying that narrow finetunes do not embed detectable misaligned or restricted objectives.
- Tools/Workflows: Standardized ADL protocols and scoring; interoperable reporting schemas; third-party certification bodies.
- Assumptions/Dependencies: Regulatory buy-in; consensus on acceptable bias levels; robust benchmarks.
- Runtime activation monitoring to detect misaligned fingerprints
- Sectors: cloud inference, safety-critical deployments
- What: Deploy lightweight runtime checks comparing early-token activations against known fingerprints of dangerous narrow finetunes; apply throttling or guardrails if detected.
- Tools/Workflows: Low-overhead activation samplers; privacy-preserving fingerprint matching; incident response hooks.
- Assumptions/Dependencies: Access to internal activations (or safe, privacy-compliant summaries); minimal latency overhead; false positive management.
- Automated fine-tune recipe optimizer balancing performance vs bias
- Sectors: AI platforms, large MLOps teams
- What: Automatically search over data mixing ratios, curriculum ordering, and regularizers to minimize detectable biases while preserving task performance.
- Tools/Workflows: Multi-objective optimization (e.g., FFA or task metrics vs ADL bias metrics); training-time early stopping keyed to activation-diff signals.
- Assumptions/Dependencies: Reliable proxy metrics; compute budget for sweeps; domain-specific acceptance criteria.
- Forensic reconstruction and e-discovery for model incidents
- Sectors: legal, incident response, insurance
- What: Post-incident analysis to infer likely finetuning domains and potential source datasets from a compromised or misbehaving model.
- Tools/Workflows: Steering-based corpus similarity search; diff-fingerprint comparison against known corpora; chain-of-custody reporting.
- Assumptions/Dependencies: Legal authority to perform forensic probing; reference corpora; robust similarity thresholds.
- Supply-chain integrity and registry of model lineage
- Sectors: cloud marketplaces, enterprise procurement
- What: Establish registries of base-to-finetune activation-diff fingerprints; verify vendor claims about training scope and data lineage.
- Tools/Workflows: Fingerprint submission APIs; marketplace verification badges; periodic re-checks after updates.
- Assumptions/Dependencies: Vendor participation; stable fingerprints across updates; governance for disputes.
- Cross-modal extensions (vision-language, speech)
- Sectors: multimodal applications (healthcare imaging, autonomous systems, education)
- What: Extend ADL-style audits to VLMs and ASR/TTS models to detect narrow finetunes (e.g., risky medical imaging prompts, subliminal cues).
- Tools/Workflows: Modality-specific “lens” equivalents; multimodal steering with coherence constraints; cross-modal graders.
- Assumptions/Dependencies: Access to intermediate representations; adapted Patchscope-like prompts.
- Train-time regularization targeting early-position biases
- Sectors: foundation model providers, research labs
- What: Develop loss terms or constraints penalizing excessive early-token activation-diff magnitude or token-relevance spikes; concept-mixing curricula that prevent mono-semantic overfitting.
- Tools/Workflows: Regularizers based on position-wise diff norms; scheduled mixing; improved concept ablation methods beyond current CAFT limitations.
- Assumptions/Dependencies: Demonstrated generalization gains without degrading task performance; stability across scales.
- Benchmarks and competitions for interpretability agents
- Sectors: academia, industry research, standards bodies
- What: Standardized tasks to evaluate agents’ ability to uncover finetuning objectives, with reproducible organisms that are closer to realistic post-training cases.
- Tools/Workflows: Public leaderboards; organism sets with varied subtlety; agreed scoring rubrics.
- Assumptions/Dependencies: Community consensus on realism; long-term maintenance of benchmarks.
- Insurance and model risk management products tied to ADL scores
- Sectors: finance/insurance, enterprise risk
- What: Underwriting that prices risk based on auditability and ADL metrics; continuous monitoring clauses.
- Tools/Workflows: Risk dashboards; periodic audit requirements; scorecards incorporated into SLAs.
- Assumptions/Dependencies: Correlation between ADL metrics and real-world incident rates; actuarial validation.
- Policy frameworks for prohibited training detection and export control
- Sectors: policy/regulatory, international trade
- What: Use activation-diff audits to assess whether models were fine-tuned on disallowed domains or with sensitive materials tied to export-restricted capabilities.
- Tools/Workflows: Government-run testing labs; certification for cross-border model distribution.
- Assumptions/Dependencies: Legal authority; transparent technical procedures; cooperation from model providers.
Notes on feasibility and generalizability:
- The strongest results occur with narrowly scoped, semantically homogeneous finetunes; broader, diverse post-training may attenuate the signals.
- Base-model access (or a close proxy) materially improves audit power; closed models may require negotiated API support or alternative baselines.
- LLM-based graders/agents inject evaluation noise; standardization and human-in-the-loop verification may be needed in high-stakes contexts.
- Mixing pretraining data reduces detectable bias but can reduce objective internalization; organizations should tune ratios relative to product KPIs and safety thresholds.
Collections
Sign up for free to add this paper to one or more collections.

