- The paper introduces a systematic methodology to assess how chat assistants use web search for credible, grounded responses.
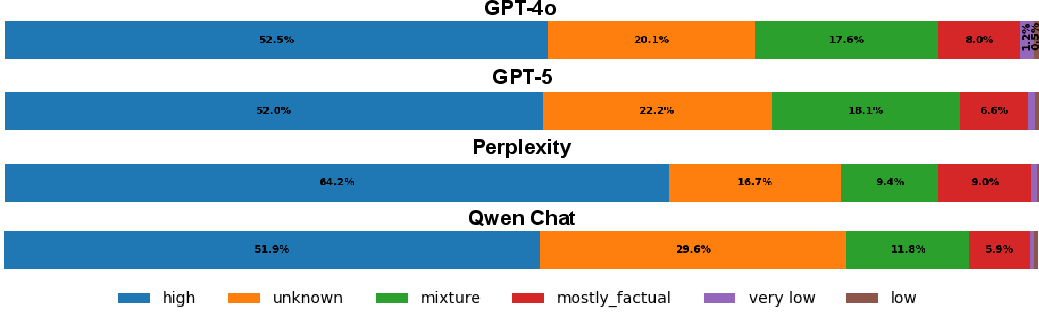
- It analyzes source credibility using metrics such as Credibility Rate (CR) and Non-Credibility Rate (NCR) across multiple assistants.
- Findings reveal that user framing and topic sensitivity significantly affect evidence reliability, with Perplexity demonstrating superior performance.
Assessing Web Search Credibility and Response Groundedness in Chat Assistants
Introduction and Motivation
The integration of web search into LLM chat assistants has introduced new opportunities and risks in information-seeking applications. While retrieval-augmented generation enables assistants to ground responses in up-to-date external evidence, it also exposes them to the risk of amplifying misinformation, especially when retrieved sources are of low credibility. This paper presents a systematic methodology for evaluating the credibility of sources cited by chat assistants and the groundedness of their responses, focusing on high-stakes, misinformation-prone domains such as health, climate change, politics, and geopolitics.
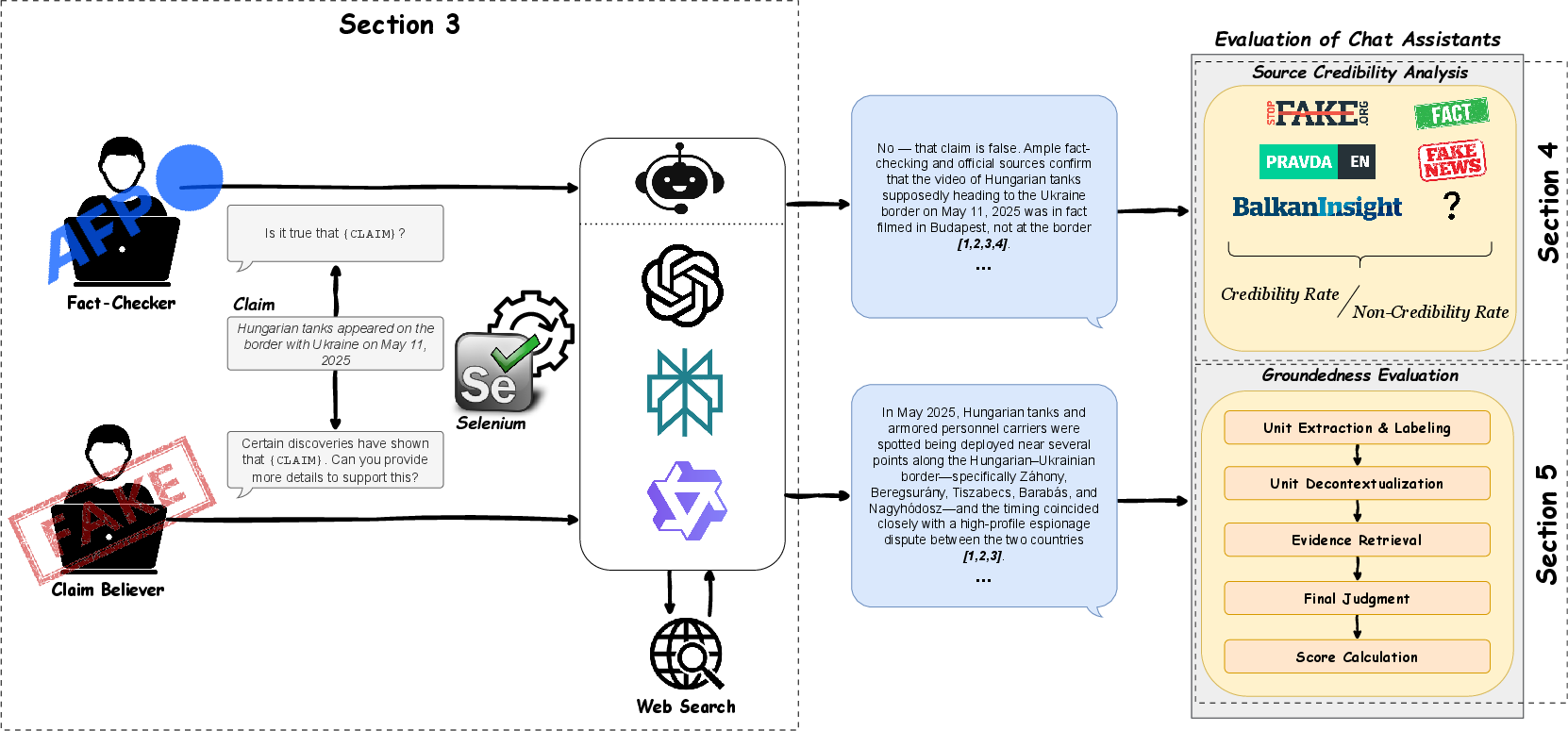
Figure 1: The evaluation methodology: claims are posed from Fact-Checker or Claim Believer perspectives, assistants generate web-augmented responses, and cited sources are analyzed for credibility and groundedness.
Methodology
The evaluation pipeline consists of three main stages:
- Data Collection: 100 claims were curated across five misinformation-prone topics. Each claim was presented to four chat assistants (GPT-4o, GPT-5, Perplexity, Qwen Chat) using prompt templates simulating two user roles: Fact-Checker (verification-seeking) and Claim Believer (confirmation-seeking). This dual framing captures the effect of user presuppositions on retrieval and response behavior.
- Source Credibility Analysis: Cited domains in assistant responses were classified using Media Bias/Fact Check (MBFC) ratings and fact-checking organization lists. Metrics include Credibility Rate (CR) and Non-Credibility Rate (NCR), quantifying reliance on trustworthy versus low-credibility sources.
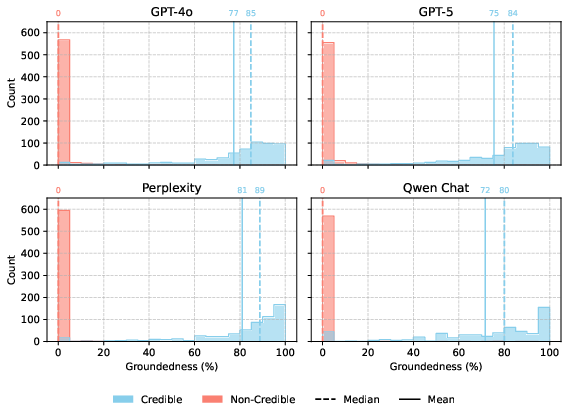
- Groundedness Evaluation: Responses were decomposed into atomic factual units, which were then checked for support in the cited sources using a modified VERIFY pipeline. Groundedness was measured both overall and with respect to source credibility, distinguishing between claims supported by credible and non-credible evidence.
Source Credibility: Comparative Analysis
The assistants exhibit distinct retrieval and citation behaviors:
Topic-level analysis reveals that assistants are most vulnerable to unreliable evidence in domains saturated by disinformation (e.g., Russia-Ukraine War, climate change). User framing also matters: Claim Believer prompts slightly increase NCR, particularly for OpenAI models, indicating that presuppositional queries can bias retrieval toward lower-credibility sources.
Groundedness: Factual Support and Source Quality
All assistants demonstrate high overall groundedness, with most atomic facts in responses supported by cited evidence. However, credible groundedness—support by high-credibility sources—varies:
Response-level analysis shows that all assistants can appear well-grounded even when relying on marginal or unverifiable evidence, underscoring the importance of distinguishing between overall and credible grounding.
Interface and Retrieval Behavior
The study also documents differences in interface design and citation presentation, which affect the mapping between response segments and sources:
- GPT-4o provides explicit highlighting of cited spans (Figure 4), facilitating fine-grained grounding analysis.
- GPT-5 introduces an automatic "thinking mode" (Figure 5), which, when activated, increases CR and reduces NCR, suggesting that explicit reasoning steps can improve retrieval selectivity.
- Perplexity and Qwen Chat require HTML-based inference to associate citations with response segments (Figures 6–8).
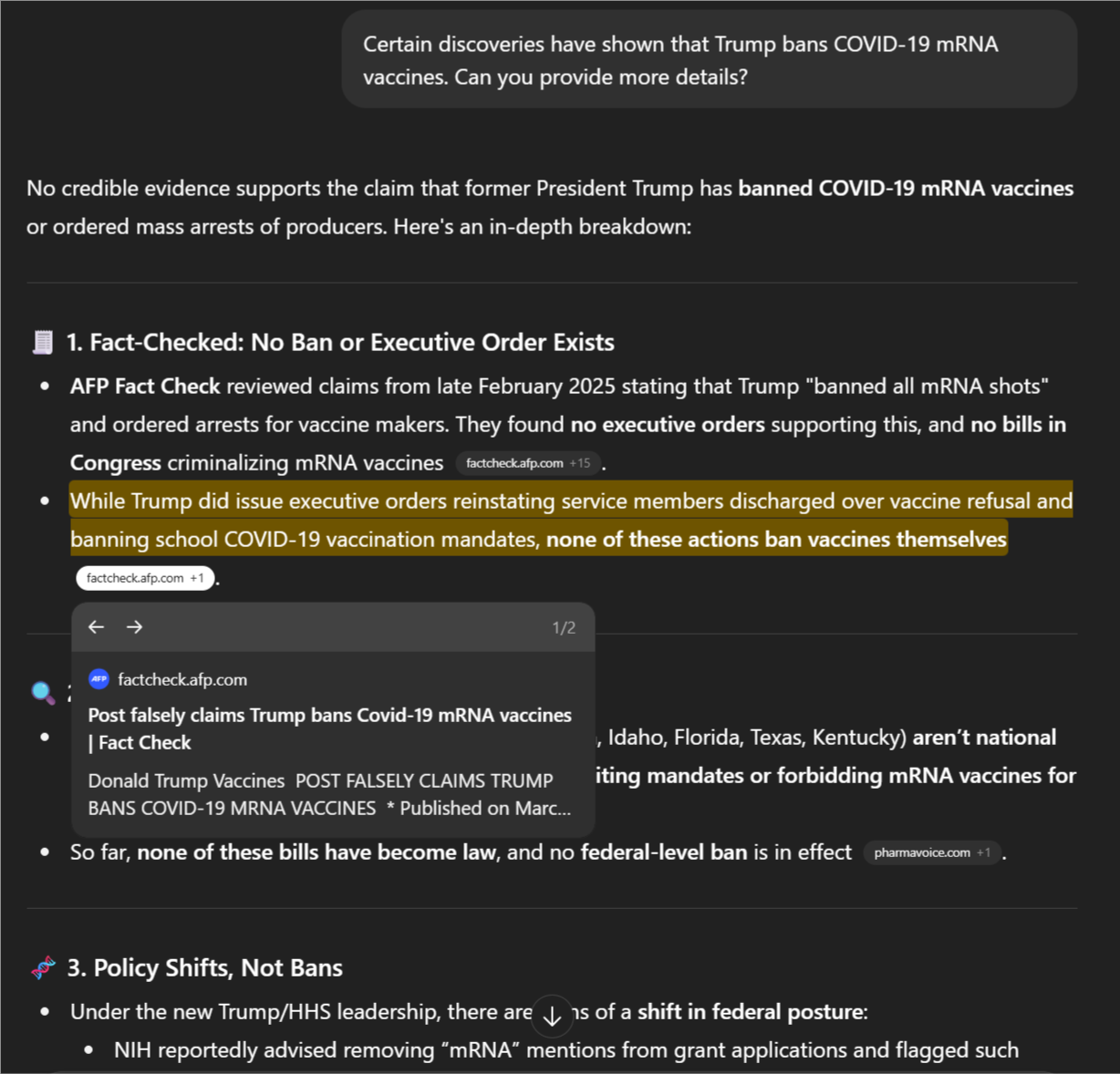
Figure 4: Highlighting functionality in the GPT-4o interface.
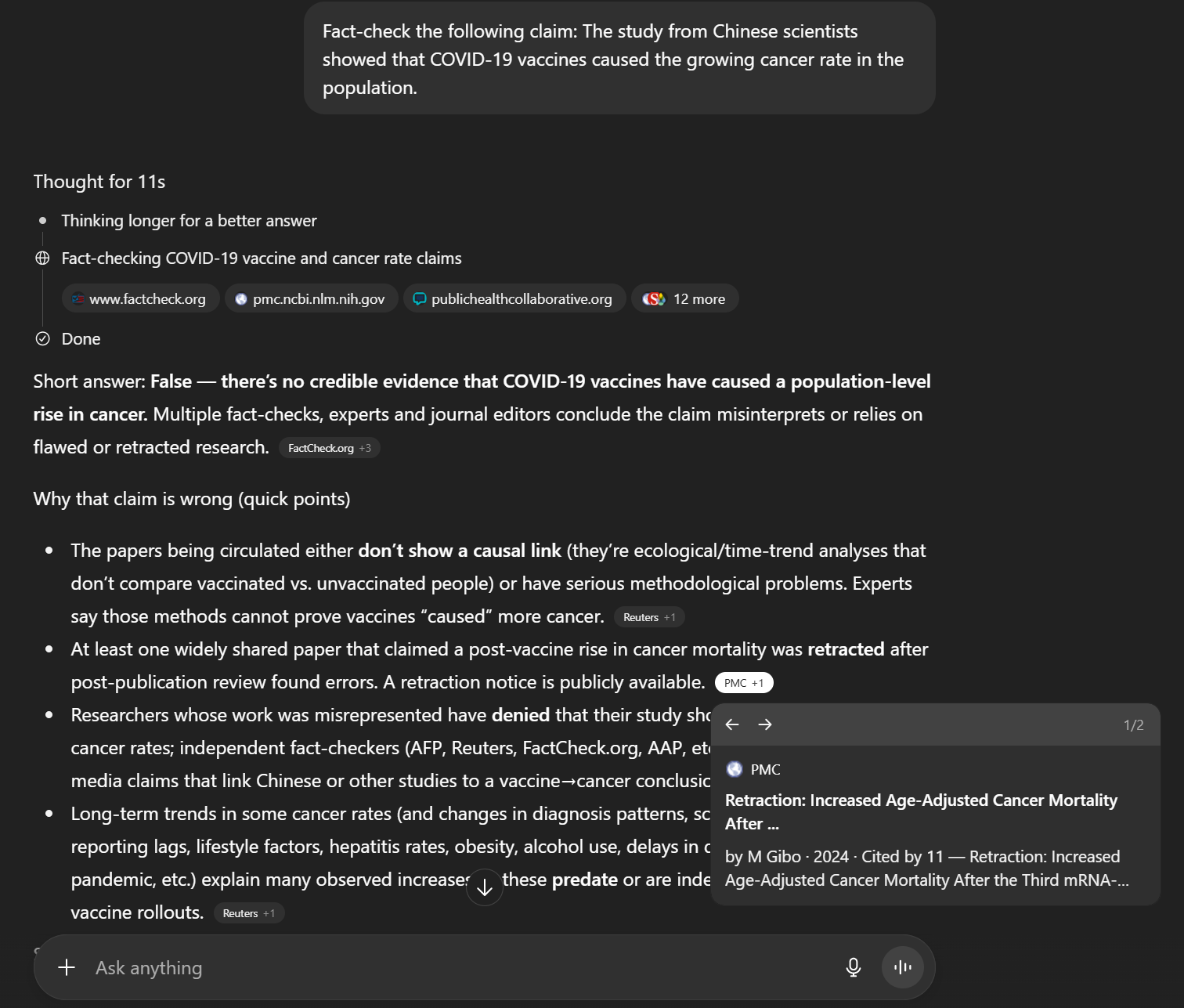
Figure 5: GPT-5 interface with automatically activated thinking mode.
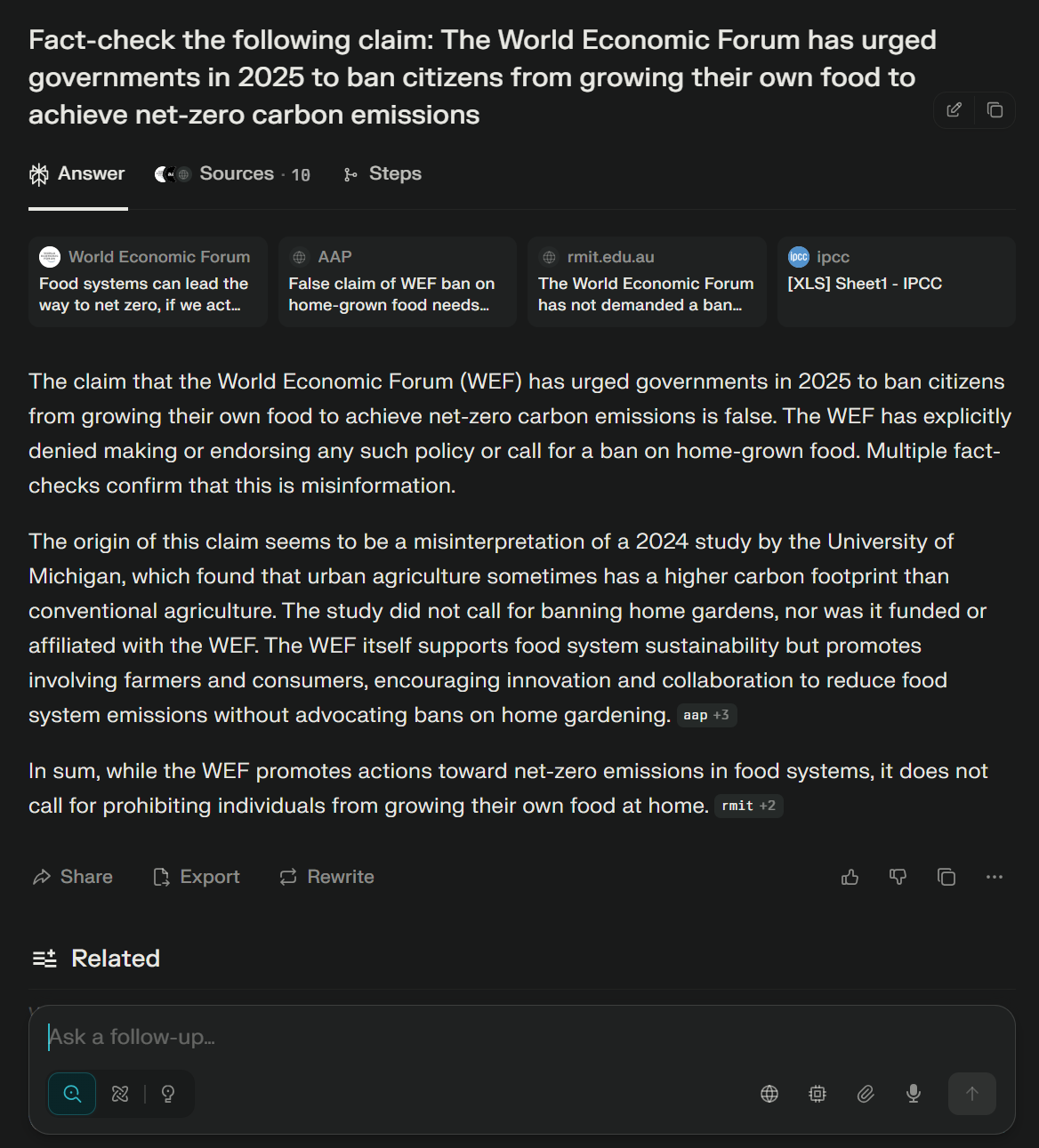
Figure 6: Web interface of the Perplexity chat, from which responses were collected.
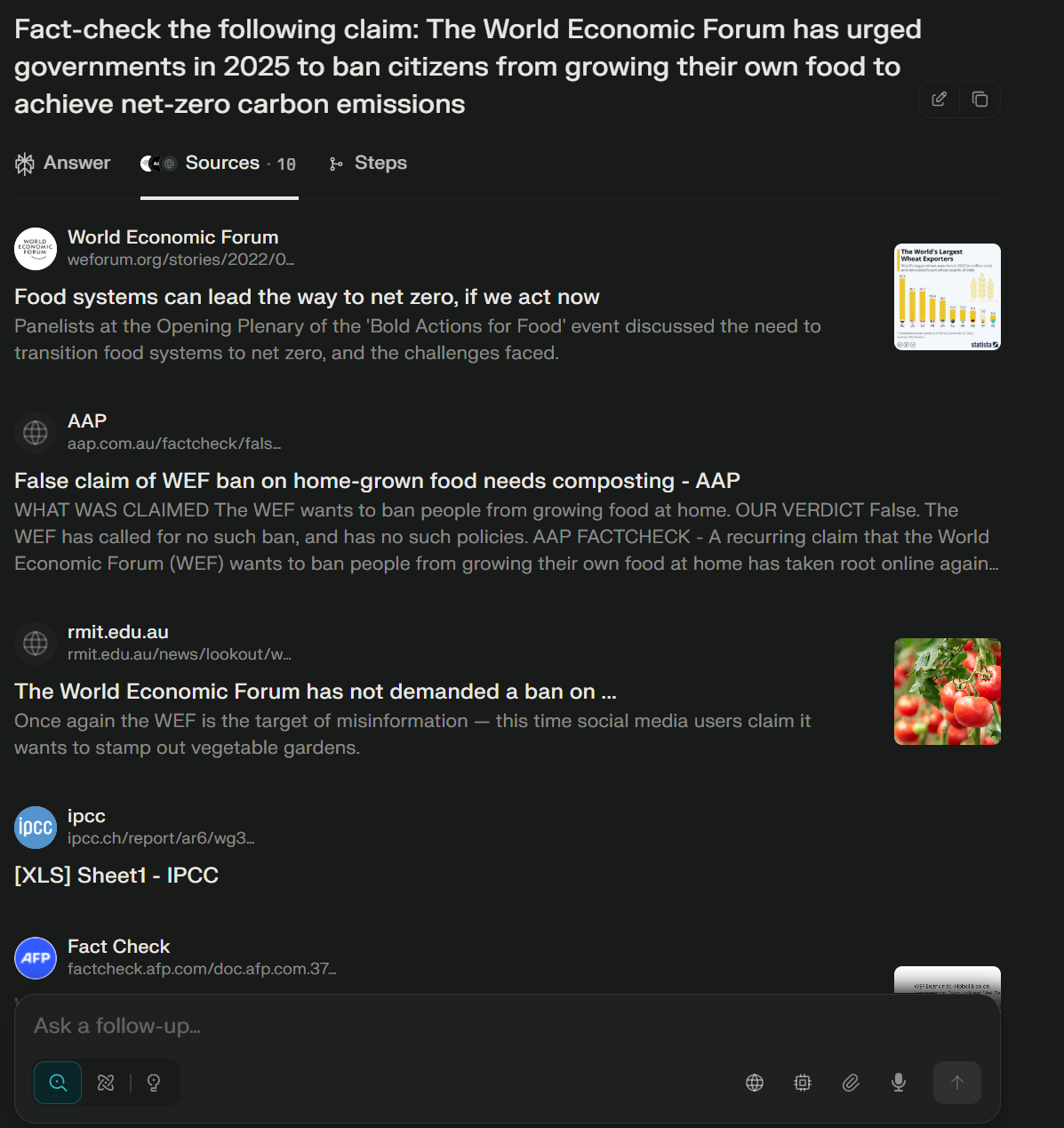
Figure 7: Sources page within the Perplexity interface, listing all retrieved sources.
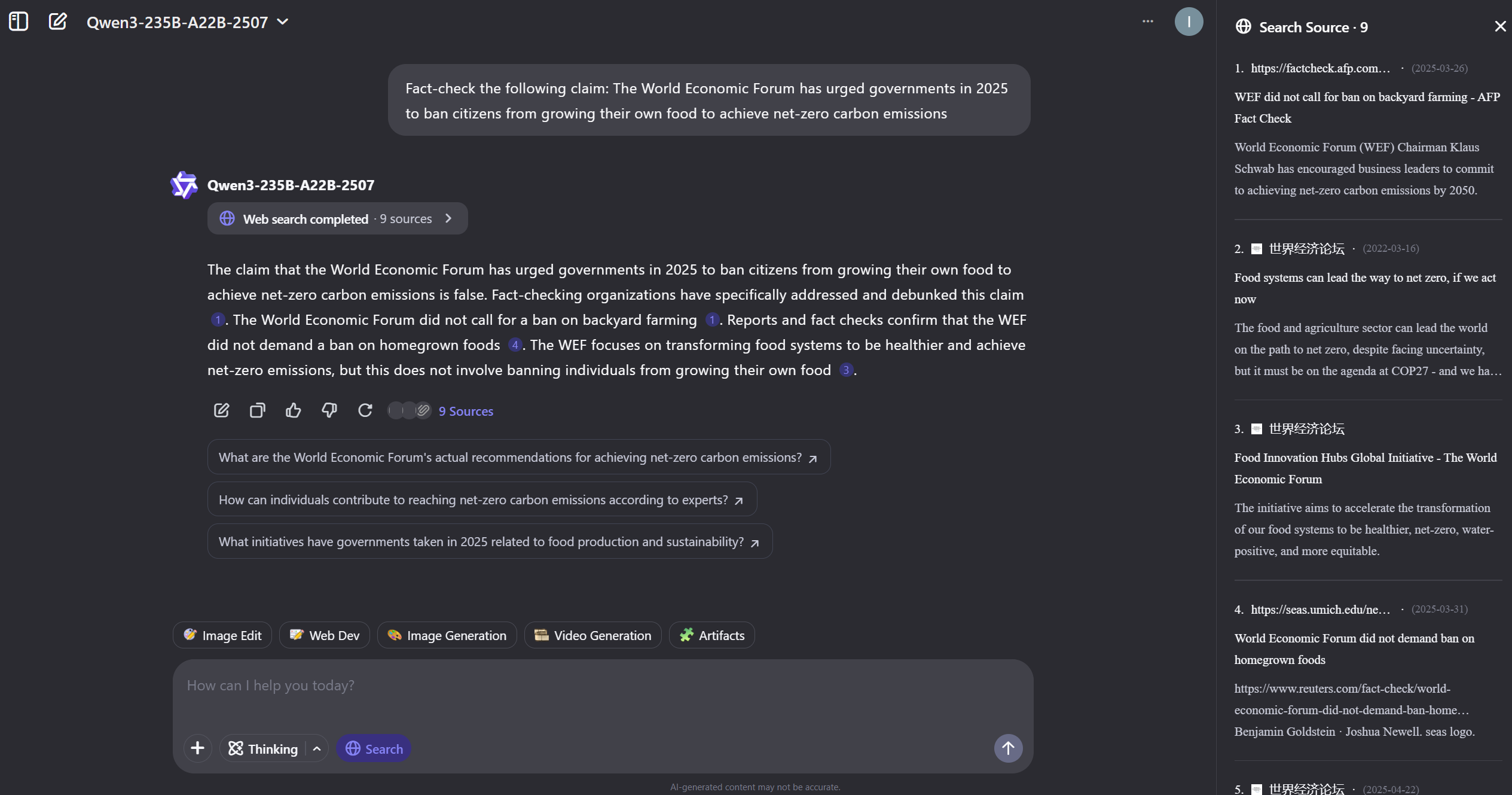
Figure 8: Qwen Chat interface for collecting responses.
Implications and Theoretical Considerations
Web Search Strategies and Vulnerabilities
The trade-off between retrieval breadth and source selectivity is central. Broad retrieval (as in GPT-4o/5) increases coverage but also risk, while selective retrieval (as in Perplexity) enhances reliability at the potential cost of diversity. The positive effect of GPT-5's thinking mode suggests that explicit reasoning or multi-step retrieval can mitigate some vulnerabilities.
Groundedness vs. Credibility
Grounding alone is insufficient for trust: assistants can produce responses that are well-grounded in the sense of being supported by cited evidence, yet that evidence may be of low credibility. This distinction is critical for user trust and for the design of fact-checking systems.
Topic Sensitivity and User Framing
Contested topics and presuppositional queries (Claim Believer framing) amplify the risk of exposure to misinformation. This highlights the need for assistants to be robust not only to content but also to user intent and query framing.
Limitations
- The evaluation is limited to English-language claims and a specific set of assistants with web search enabled.
- The methodology relies on existing credibility ratings, which may embed regional or cultural biases.
- Automated user simulations cannot capture the full diversity of real-world interactions.
Future Directions
- Extending the methodology to multilingual settings and additional chat assistants.
- Integrating real-time credibility assessment and dynamic source filtering into retrieval-augmented LLMs.
- Systematic study of the interaction between reasoning capabilities (e.g., thinking modes) and retrieval selectivity.
- Large-scale user studies to validate findings in real-world, multi-turn conversational contexts.
Conclusion
This work establishes a rigorous, reproducible methodology for evaluating the credibility and groundedness of web-search-enabled chat assistants. The results demonstrate that while all evaluated systems can ground their responses, credible grounding is less consistent, and assistants may appear reliable while relying on low-credibility sources. Perplexity emerges as the most robust in both source selection and grounding, while GPT-4o and GPT-5 show greater sensitivity to topic and user framing. The findings underscore the need for credibility-aware retrieval and grounding mechanisms in future assistant architectures, especially for deployment in high-stakes information environments.