InstantSfM: Fully Sparse and Parallel Structure-from-Motion
Abstract: Structure-from-Motion (SfM), a method that recovers camera poses and scene geometry from uncalibrated images, is a central component in robotic reconstruction and simulation. Despite the state-of-the-art performance of traditional SfM methods such as COLMAP and its follow-up work, GLOMAP, naive CPU-specialized implementations of bundle adjustment (BA) or global positioning (GP) introduce significant computational overhead when handling large-scale scenarios, leading to a trade-off between accuracy and speed in SfM. Moreover, the blessing of efficient C++-based implementations in COLMAP and GLOMAP comes with the curse of limited flexibility, as they lack support for various external optimization options. On the other hand, while deep learning based SfM pipelines like VGGSfM and VGGT enable feed-forward 3D reconstruction, they are unable to scale to thousands of input views at once as GPU memory consumption increases sharply as the number of input views grows. In this paper, we unleash the full potential of GPU parallel computation to accelerate each critical stage of the standard SfM pipeline. Building upon recent advances in sparse-aware bundle adjustment optimization, our design extends these techniques to accelerate both BA and GP within a unified global SfM framework. Through extensive experiments on datasets of varying scales (e.g. 5000 images where VGGSfM and VGGT run out of memory), our method demonstrates up to about 40 times speedup over COLMAP while achieving consistently comparable or even improved reconstruction accuracy. Our project page can be found at https://cre185.github.io/InstantSfM/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces InstantSfM, a fast computer program that builds 3D models and figures out where cameras were located just from a collection of photos. This process is called Structure-from-Motion (SfM). The key idea is to use a graphics card (GPU) and smart math to make SfM much faster, so it can handle thousands of images while keeping accuracy high.
What questions does the paper try to answer?
- How can we make SfM run much faster without losing accuracy?
- Can we do all the heavy math in parallel on a single GPU, instead of on a slower processor (CPU) or a big computer cluster?
- Can we keep the results at real-world scale (so sizes and distances are correct) by using depth information?
- Will this faster method still work well on big, real datasets with many images?
How did the researchers do it?
Think of SfM like solving a big puzzle:
- Each photo is a clue about where the camera was and what the scene looks like in 3D.
- The program matches points across photos, figures out camera positions, and computes 3D points.
Two main math steps are involved:
- Global Positioning (GP)
- Goal: Get a good first guess of where all cameras and 3D points are.
- Analogy: It’s like putting pins on a map for each camera and drawing rays from the camera to features in the photos. You adjust pins and points until the rays line up with the 3D points.
- Bundle Adjustment (BA)
- Goal: Fine-tune everything to make the 3D model and camera positions as accurate as possible.
- Analogy: It’s like tightening all the screws so the model fits the photos perfectly.
To make these steps fast, InstantSfM uses:
- The Levenberg–Marquardt (LM) algorithm: a standard “adjust and check” method that keeps improving the solution step by step.
- Sparse Jacobians: A Jacobian is a big table showing how changing each parameter (like a camera angle or a point’s position) affects the error. In SfM, most entries in this table are zero because each photo only depends on a few things. “Sparse” means the table is mostly empty. InstantSfM stores and computes only the non-empty parts, which saves lots of time and memory.
- GPU parallel computing: GPUs can do many tiny calculations at the same time. InstantSfM spreads the non-zero chunks of those big tables across the GPU to compute them in parallel.
- PyTorch implementation: The whole pipeline is built in PyTorch, making it easier to plug in other tools and run on GPUs.
- Depth prior: If you have a depth map (how far each pixel is from the camera), InstantSfM can use it to set the correct real-world scale. Analogy: If you know how far something is in the picture, you can tell how big it really is.
What did they find and why does it matter?
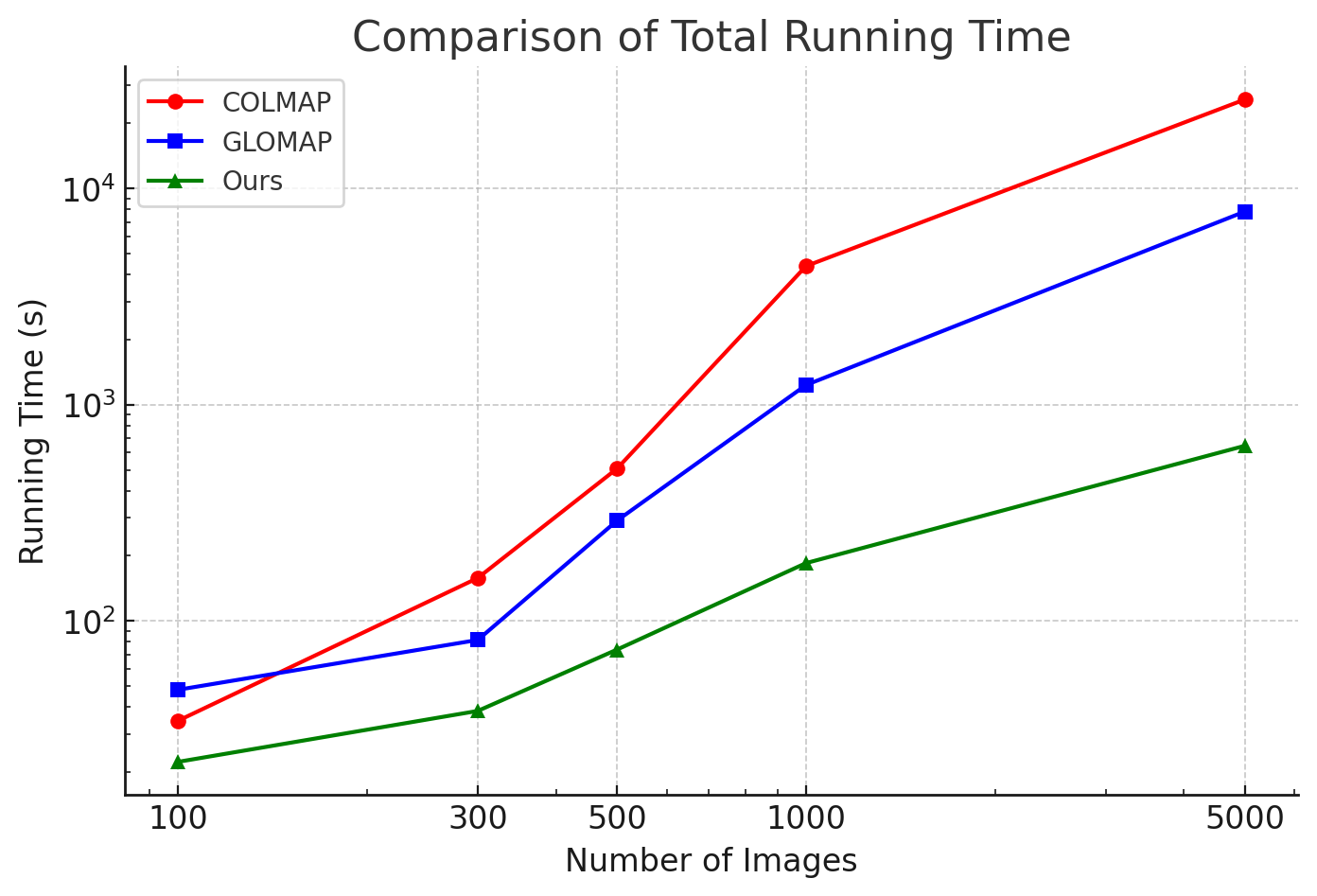
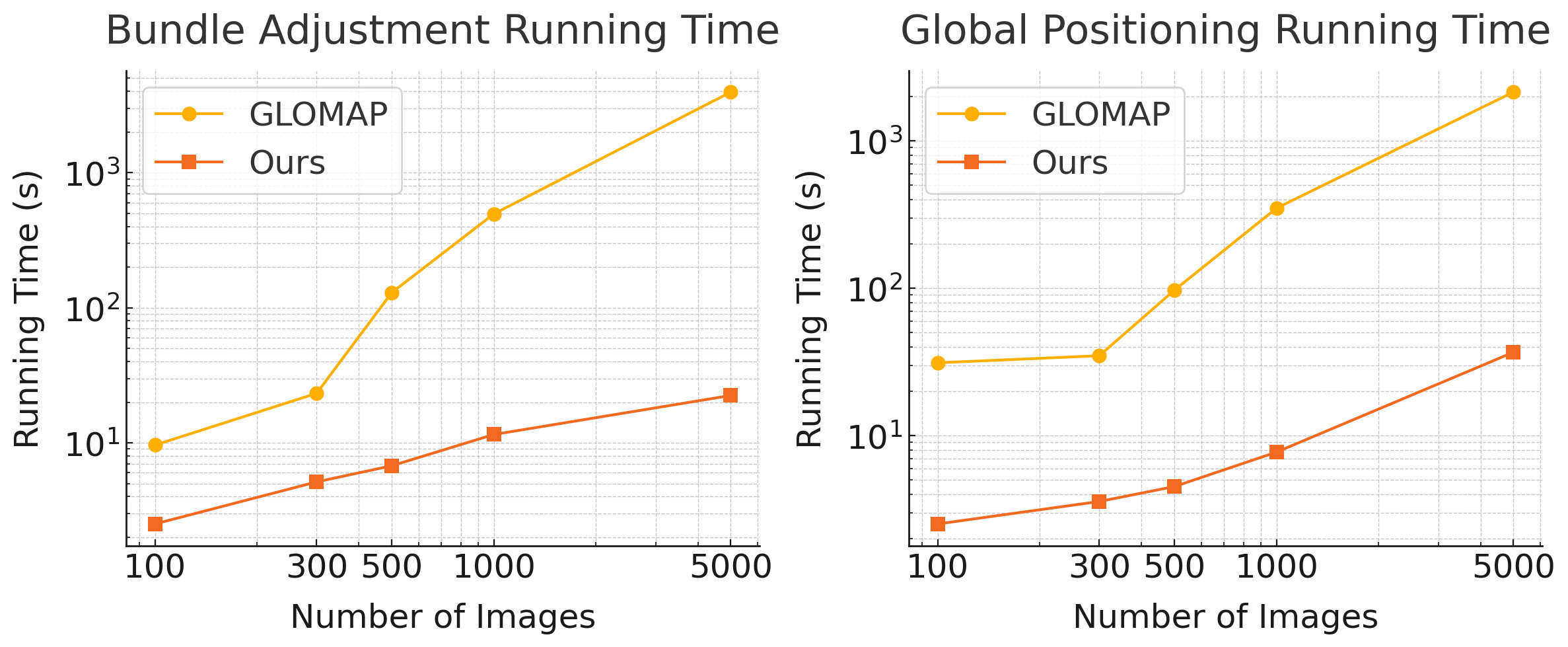
- Speed: InstantSfM can be up to about 40× faster than popular tools like COLMAP, and is also faster than GLOMAP, especially on large image sets (hundreds to thousands of photos).
- Scale: It runs on a single GPU and still handles thousands of images, even in cases where some deep-learning-based pipelines run out of memory.
- Accuracy: Its 3D reconstructions and camera poses are as good as or better than existing methods in many tests. It also reconstructs scenes at real-world scale when using depth.
- Robustness: On challenging datasets (like ScanNet indoor scenes), it often succeeds where other methods fail, especially when depth information is used.
- Flexibility: Because it’s in PyTorch, it can easily work with modern feature detectors and other Python tools.
This matters because faster and scalable SfM helps:
- Robotics and drones: building maps quickly for navigation.
- AR/VR: creating accurate 3D environments from photos or videos.
- Cultural heritage: reconstructing detailed 3D models of artifacts and sites.
- New 3D graphics methods (like NeRF or 3D Gaussian Splatting): they need good camera poses to work well.
What is the big picture impact?
InstantSfM shows that with smart math (using sparsity) and GPU parallel computing, we can make 3D reconstruction from photos both fast and accurate at large scale. This could speed up how robots learn about the world, improve 3D scene creation for games and films, and make it easier for researchers and engineers to process huge photo collections. The authors also plan future improvements (like faster 3D point triangulation and multi-machine support), which could push performance even further for extremely large projects.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed at guiding future research.
- Distributed scalability: The pipeline is single-node/single-GPU; how to extend the sparse GP/BA design to multi-GPU and distributed clusters while preserving sparsity and avoiding communication bottlenecks?
- Commodity GPU viability: Results at large scale are demonstrated on an H200 (140 GB). What is the maximum scene size (images/tracks/observations) that fits and runs efficiently on common 24–48 GB GPUs, and what memory/time trade-offs are required?
- Linear solver specification and robustness: The LM “solver” is unspecified (direct vs. iterative, preconditioning, pivoting). Which solver choices yield the best stability and speed for GP/BA on sparse normal equations, especially under ill-conditioning?
- Schur complement vs. sparse normal equations: The paper dismisses Schur complement for spatial complexity but does not empirically compare Schur-based camera-point elimination against their sparse approach. Can combining Schur complement with sparse kernels further reduce time/memory?
- Damping schedule and trust-region control: The LM damping strategy (lambda updates, acceptance criteria, stopping rules) is not described. What schedules improve convergence and reduce failure rates on challenging graphs?
- Quaternion algebra correctness and stability: The custom differentiable quaternion addition is introduced but not validated. Are there numerical stability issues (e.g., normalization drift), and does it impact rotation averaging and BA accuracy?
- Intrinsics modeling: BA uses K ∈ R{C×1}, suggesting focal-only intrinsics. How does the method perform with full intrinsics (fx, fy, cx, cy) and lens distortion (radial/tangential)? Is this limitation linked to the intrinsics–translation ambiguity observed on Tanks and Temples?
- Rolling-shutter and fisheye support: The pipeline appears tailored to pinhole/global-shutter models. How to extend sparse GP/BA to rolling-shutter and fisheye cameras while maintaining efficiency?
- ViewGraphCalibration dependency: Performance differences are attributed to PyCeres vs. C++ Ceres and OpenCV vs. PoseLib, but no ablation is provided. What is the quantitative impact of these choices on accuracy and convergence?
- Translation/intrinsics ambiguity mitigation: Tanks and Temples failures suggest degeneracy between focal length and translation. Which priors/constraints (e.g., focal-length priors, joint self-calibration, regularization) resolve this ambiguity robustly at scale?
- Outlier handling limits: The method integrates robust loss via masking, but heavy-outlier regimes (e.g., extreme mismatches, repetitive structures) are not characterized. What outlier rates and track qualities can the sparse LM reliably handle before failure?
- Depth prior quality and reliability: Depth priors improve some scenes but degrade others (e.g., ScanNet 0001_00). What noise, scale, and completeness thresholds in depth maps make the prior beneficial vs. harmful? How to weight or adaptively trust depth across views?
- Missing-depth handling: The GP reformulation sets d_{ij} = 1/depth_{ij}, but strategies for missing or unreliable depth observations are not discussed. How to impute, reweight, or regularize d_{ij} when depth is unavailable or inconsistent?
- Metric-scale validation: The claim of metric reconstruction via depth priors is not backed by explicit scale-accuracy metrics across datasets. How accurate is scale (e.g., absolute pose/scene scale error) under estimated vs. ground-truth depth?
- Triangulation acceleration: Triangulation is not CUDA/Triton-accelerated. What speedups and accuracy impacts arise from GPU-accelerated triangulation and re-triangulation (including robust track pruning)?
- Visibility reasoning: The paper assumes Jacobian sparsity from limited visibility but does not describe visibility determination, occlusion handling, or track culling policies. How do different visibility heuristics affect sparsity, accuracy, and runtime?
- Rotation averaging details: The rotation averaging method and its parameters are not specified or evaluated. How does choice of rotation averaging algorithm influence GP initialization quality and downstream BA performance?
- Translation averaging vs. GP trade-offs: GLOMAP’s GP is used, but the work does not characterize when GP is preferable to translation averaging (noise/outlier regimes, graph density). Can hybrid strategies be more robust?
- Evaluation breadth for camera accuracy: AUC is reported for relative rotation only; translation accuracy and absolute pose errors are not measured where possible. How does the method compare on full pose metrics (R, t, scale) across diverse datasets?
- Dependence on feature type: The pipeline “supports” learned features (LoFTR, SuperPoint, iMatching) but experiments primarily use RootSIFT. How do different descriptors and matchers affect accuracy, robustness, and speed within the sparse GP/BA framework?
- Feature/matching acceleration: Feature extraction and matching runtimes dominate large-scale runs and are not accelerated in this work. How to integrate GPU-parallel feature/matching stages that preserve end-to-end sparsity and speed gains?
- Online/streaming SfM: The pipeline is global batch-mode. Can the sparse parallel design be adapted to online/streaming SfM with incremental updates and occasional global refinements?
- Dynamic-scenes robustness: Despite motivating dynamic reconstruction, the method targets static scenes. How to detect and handle moving objects or non-rigid regions without breaking global consistency?
- Mixed-precision and numerical reproducibility: The work does not discuss precision (FP16/FP32) or numeric reproducibility across hardware. Can mixed-precision reduce memory/time without degrading accuracy? What reproducibility guarantees exist?
- Dataset and hyperparameter reproducibility: Critical hyperparameters (LM iterations, damping, robust loss configs, solver tolerances) are not reported. Publishing these, along with seeds and ablations, would improve replicability and clarify performance drivers.
Practical Applications
Immediate Applications
Below is a curated list of practical, deployable uses that can leverage the paper’s findings now. Each item includes sector alignment, potential tools/workflows, and feasibility notes.
- Boldly faster photogrammetry for AEC and cultural heritage
- Sectors: architecture, construction (AEC), digital heritage, surveying
- What: Replace COLMAP/GLOMAP in existing pipelines to reconstruct large scenes (hundreds–thousands of images) on a single GPU with up to ~40× speedup, while maintaining comparable accuracy
- Tools/workflows: InstantSfM + Python feature stacks (e.g., SuperPoint/LoFTR/iMatching) → global positioning (GP) → bundle adjustment (BA) → downstream MVS; export to standard formats for Meshroom/Blender
- Assumptions/dependencies: Sufficient GPU VRAM; images with adequate overlap; static scenes; robust feature matching; current single-node limitation
- Rapid camera calibration and dataset preparation for NeRF and 3D Gaussian Splatting (3DGS)
- Sectors: graphics, media, AR/VR, research
- What: Generate accurate camera poses and sparse scene points to bootstrap NeRF/3DGS training pipelines at scale
- Tools/workflows: InstantSfM → 3DGS (GSplat), Nerfstudio or other NeRF toolchains; automated pose export
- Assumptions/dependencies: GPU availability; image coverage; training frameworks expect standard pose formats
- Metric-scale indoor reconstruction using RGB-D depth priors
- Sectors: robotics, facility management, real estate
- What: Leverage depth priors to recover camera parameters and point clouds in metric scale for indoor scans
- Tools/workflows: InstantSfM with depth maps (e.g., from RGB-D sensors or monocular depth estimators) → metric reconstruction → alignment with CAD/BIM
- Assumptions/dependencies: Depth maps of reasonable quality; scenes mostly static; depth prior integration configured (paper shows improved robustness on ScanNet/ScanNet++)
- Faster on-set calibration for VFX and multi-camera rigs
- Sectors: film/TV, live events
- What: Quickly solve global camera poses for multi-view capture to accelerate match-moving and scene layout
- Tools/workflows: InstantSfM in Python + production asset management; batch processing of high-resolution frames
- Assumptions/dependencies: Adequate GPU resources; consistent rig geometry; sufficient feature coverage under varying lighting
- Drone and UAV mapping for medium-scale sites
- Sectors: agriculture, mining, insurance claims, disaster assessment
- What: Single-GPU large-batch SfM to turn aerial image sets into georeferenced reconstructions (when combined with GPS or known scale constraints)
- Tools/workflows: InstantSfM + external geo-constraints (ground control points, GPS) → metric reconstruction → GIS integration
- Assumptions/dependencies: Good view overlap and coverage; optional geo-constraints; static terrain; current pipeline does not natively handle distributed clusters
- Accelerated inspection and asset digitization for industrial facilities
- Sectors: energy, manufacturing, utilities
- What: Reduce turnaround time for creating 3D records of equipment/plant layouts for maintenance and digital twin updates
- Tools/workflows: InstantSfM → MVS or 3DGS → comparison to baseline scans; change detection
- Assumptions/dependencies: Stable capture conditions; adequate image quality; some sites may require depth priors for accurate scale
- Academic experimentation and teaching of large-scale BA/GP on GPUs
- Sectors: academia, education
- What: Use the PyTorch-based, sparse-aware LM pipeline to teach and prototype new SfM/optimization ideas without C++ constraints
- Tools/workflows: InstantSfM + Jupyter/Colab + PyTorch autograd; easy swap-in of features/robustifiers
- Assumptions/dependencies: Python environment; GPU support; careful tuning of damping, robust losses for specific datasets
- Cloud-friendly SfM microservice for batch processing
- Sectors: software, cloud services
- What: Containerize InstantSfM to offer “SfM-as-a-service” for large image sets from clients; exploit GPU instances to compress job times
- Tools/workflows: Docker + InstantSfM + orchestration (Kubernetes) + job queue; REST API to upload image sets and download poses/point clouds
- Assumptions/dependencies: Cloud GPU provisioning; cost controls; image privacy/compliance; single-node performance per job
- E-commerce product digitization at scale
- Sectors: retail/e-commerce
- What: Quickly convert photo sets into 3D models for product pages and virtual try-on, using single-GPU pipelines
- Tools/workflows: InstantSfM → NeRF/3DGS → rendered turntables or interactive viewers
- Assumptions/dependencies: Controlled lighting/background; adequate texture; possible need for depth priors for consistent scaling
- Faster preprocessing for SLAM benchmarks and synthetic dataset generation
- Sectors: robotics research
- What: Produce accurate camera trajectories and scene geometry for training/evaluation of SLAM and VO methods
- Tools/workflows: InstantSfM → export trajectories and sparse geometry → simulate sensors (e.g., IMU/LiDAR) in Gazebo/Isaac Sim
- Assumptions/dependencies: Mostly static scenes; robust feature pipelines; tight integration with simulators handled externally
Long-Term Applications
These applications are enabled by the paper’s innovations but will require further research, scaling, or additional system integration before broad deployment.
- Near-real-time SfM on edge devices (AR glasses, mobile, drones)
- Sectors: AR/VR, robotics, consumer devices
- What: Push sparse GPU SfM into constrained hardware for on-device reconstruction
- Tools/workflows: CUDA/Triton acceleration for triangulation, model compression, mixed precision; hardware-specific kernels
- Assumptions/dependencies: Further operator optimization; mobile-class GPUs/NPUs; power and memory constraints
- Distributed, city-scale SfM for municipal digital twins
- Sectors: urban planning, smart cities, infrastructure
- What: Scale the single-node pipeline to multi-GPU/multi-node clusters to process tens/hundreds of thousands of images
- Tools/workflows: Distributed sparse Jacobian storage; partitioned BA/GP; fault-tolerant schedulers
- Assumptions/dependencies: New distributed design; network bandwidth; synchronization strategies; robust outlier handling at scale
- Dynamic scene reconstruction with temporal robustness
- Sectors: robotics, autonomy, surveillance
- What: Extend sparse-aware optimization to handle moving objects and time-varying geometry reliably
- Tools/workflows: Joint motion segmentation + GP/BA; temporal priors; physics-informed constraints
- Assumptions/dependencies: New formulations for dynamic scenes; improved outlier/motion handling; additional sensors (e.g., IMU/LiDAR)
- Sensor-fusion metric mapping (RGB + depth + LiDAR/IMU/GPS)
- Sectors: autonomous vehicles, field robotics, AEC
- What: Integrate multi-modal priors to improve robustness and scale accuracy for challenging environments
- Tools/workflows: Extended LM with multi-sensor factors; calibration pipelines; graph-based fusion with GTSAM-like abstractions in GPU
- Assumptions/dependencies: High-quality calibration; robust cross-sensor synchronization; additional operator support
- Automated compliance workflows for emergency mapping and public safety
- Sectors: policy/public sector, disaster response
- What: Rapidly reconstruct damage areas and critical infrastructure with traceable, auditable pipelines
- Tools/workflows: Standardized metadata logging; reproducibility checks; privacy-preserving cloud pipelines
- Assumptions/dependencies: Regulatory acceptance; secure data handling; standardized QA metrics
- Integrated production pipelines for VFX with automatic scale and alignment
- Sectors: film/TV/VFX
- What: Combine depth priors and multi-view capture to auto-resolve intrinsics–translation ambiguities and enforce consistent scale
- Tools/workflows: On-set capture → InstantSfM with depth → downstream match-moving; rig-aware priors
- Assumptions/dependencies: Improved intrinsics estimation; tighter integration with industry tools; operator refinements for edge cases noted in the paper
- Large-scale asset marketplaces for 3D commerce
- Sectors: retail, gaming, media
- What: Industrialize capture-to-3D pipelines for mass digitization and standardized asset delivery
- Tools/workflows: Cloud pipelines with InstantSfM preprocessing → NeRF/3DGS rendering → asset QA and formatting
- Assumptions/dependencies: Distributed processing; robust QC; consistent scaling across diverse capture setups
- Curriculum-aligned educational platforms for optimization on GPUs
- Sectors: education
- What: Build interactive learning environments around sparse LM, BA/GP, and practical SfM
- Tools/workflows: Interactive notebooks with operator visualizations; step-by-step Jacobian sparsity demonstrations
- Assumptions/dependencies: Stable APIs; didactic material; educator adoption
Notes on feasibility and dependencies across applications:
- GPU memory and compute are the primary constraints (large-scale scenes benefit from H100-class GPUs; smaller scenes work on consumer GPUs).
- High-quality, overlapping imagery and robust features are essential; learning-based features are supported but must be tuned for each domain.
- Current limitations noted in the paper (single-node pipeline, non-accelerated triangulation, certain implementation differences vs. C++ stacks) affect extreme-scale and some edge-case scenes (intrinsics–translation ambiguity).
- Depth priors materially improve scaling and robustness; where unavailable, metric scale may require external constraints (e.g., known object size, GPS/GCPs).
- Privacy, IP, and regulatory compliance matter for cloud and public-sector deployments; auditability and standardized QA will be necessary.
Glossary
- 1DSfM: A large-scale dataset commonly used for evaluating structure-from-motion pipelines. "while larger scenes (300-5,000 images) are obtained by downsampling from the 1DSfM\cite{wilson2014robust} dataset."
- 3D Gaussian Splatting (3DGS): A rendering and reconstruction technique that represents scenes with anisotropic 3D Gaussian primitives for fast novel view synthesis. "by training 3D Gaussian Splatting~\cite{kerbl20233d} (3DGS) using the estimated camera poses"
- AUC (Area Under the Recall Curve): A metric that summarizes pose estimation accuracy across thresholds by computing the area under the recall curve. "we report the Area Under the Recall Curve (AUC) scores"
- Autograd (PyTorch): An automatic differentiation engine for computing gradients of tensor operations, used to obtain Jacobians in optimization. "which utilize PyTorch's autograd engine for Jacobian calculations."
- BAL (Bundle Adjustment in the Large): A benchmark suite for large-scale bundle adjustment performance evaluation. "on the standard BA in the Large dataset (BAL)"
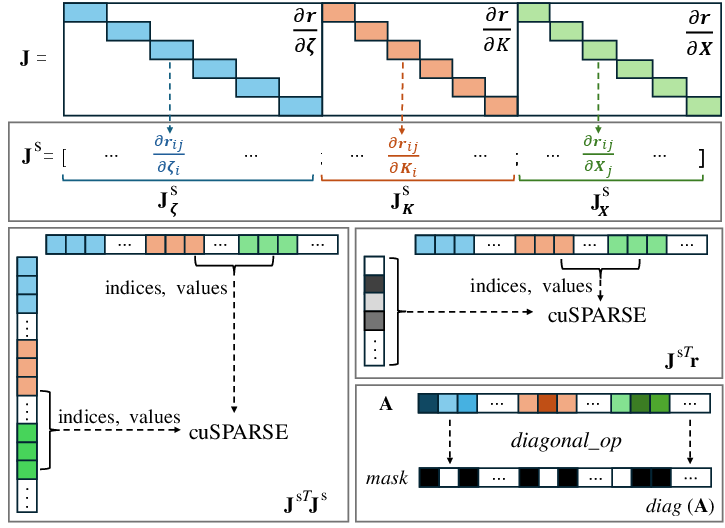
- Block-diagonal structure (sparse): A matrix pattern where non-zero blocks lie along the diagonal, enabling efficient sparse linear algebra. "This results in a sparse block-diagonal structure \cite{zhan2024bundle}, as shown in Fig.~\ref{fig:teaser}."
- Bundle Adjustment (BA): A nonlinear optimization that jointly refines camera parameters and 3D points by minimizing reprojection errors. "Bundle Adjustment (BA) is a key optimization method used to refine camera parameters and 3D scene structure"
- Camera frustum: The pyramid-shaped volume of space visible to a camera, used to visualize pose and field of view. "Camera frustums as red are visualized for illustrating the estimated camera poses."
- Ceres: A C++ library for large-scale nonlinear least squares optimization widely used in vision and robotics. "such as Ceres~\cite{agarwal2012ceres} and GTSAM~\cite{dellaert2022borglab}"
- Chamfer distance: A metric for comparing point sets by averaging nearest-neighbor distances in both directions. "we also measure the Chamfer distance on datasets with reliable ground-truth point cloud scan"
- COLMAP: A widely used SfM pipeline offering feature extraction, matching, and reconstruction, often serving as a strong baseline. "such as COLMAP and its follow-up work, GLOMAP"
- Convex relaxation: An approach that approximates a non-convex problem with a convex one to enable efficient global optimization. "proposes a convex relaxation of the original BA objective"
- cuSPARSE: NVIDIA’s GPU-accelerated library for sparse linear algebra operations. "through sparse matrix operations and cuSPARSE implementations for BA problems."
- DeepLM: A PyTorch-based implementation for optimization with automatic differentiation, used for BA-like problems. "PyTorch implementations such as DeepLM~\cite{huang2021deeplm}"
- Extrinsics (camera): The parameters describing a camera’s position and orientation in the world frame. "camera intrinsics and extrinsics "
- Fundamental matrix (F): A 3x3 matrix encoding epipolar geometry between two uncalibrated images. "homography and fundamental matrix are estimated"
- Gauss-Newton methods: Second-order iterative solvers for nonlinear least squares that approximate the Hessian via JT J. "ranging from Gauss-Newton methods to the more robust Levenberg-Marquardt (LM) algorithm"
- GLOMAP: A global SfM system following COLMAP that incorporates global positioning and averaging strategies. "such as COLMAP and its follow-up work, GLOMAP"
- Global positioning (GP): A stage in global SfM that jointly estimates camera centers and 3D points (with fixed rotations). "bundle adjustment (BA) or global positioning (GP) introduce significant computational overhead"
- Global SfM: Structure-from-motion strategies that estimate all camera poses and 3D points simultaneously rather than incrementally. "global SfM methods optimize all camera poses and scene points simultaneously"
- Homography (H): A 3x3 projective transform relating two images of a planar scene or pure rotational motion. "homography and fundamental matrix are estimated"
- Huber robustifier: A robust loss function that is quadratic near zero and linear for large residuals to reduce outlier influence. " is Huber~\cite{huber1992robust} robustifier"
- Jacobian (J): The matrix of partial derivatives of residuals with respect to optimization parameters. "The Jacobian matrix records the gradients for reprojection error optimizable parameters"
- Levenberg–Marquardt (LM): A damped least squares algorithm combining Gauss-Newton and gradient descent for robust nonlinear optimization. "Levenberg-Marquardt (LM) algorithm is a widely used second-order method for solving non-linear least squares problems."
- Lie algebra: The tangent-space vector space associated with a Lie group, enabling local linearization of rotations and poses. "requiring customized Lie group and Lie algebra implementations."
- Lie group: A smooth manifold with a group structure (e.g., rotations), enabling continuous pose parameterization. "requiring customized Lie group and Lie algebra implementations."
- LPIPS: A perceptual image similarity metric learned from deep features, used for NVS evaluation. "We report NVS metrics (e.g., PSNR, SSIM, and LPIPS)"
- MipNeRF360: A dataset of 360-degree scenes used for evaluating reconstruction and novel view synthesis. "MipNeRF360~\cite{barron2022mip} consists of 7 different scenes"
- NeRF (Neural Radiance Field): An implicit scene representation modeling view-dependent color and density for novel view synthesis. "neural radiance field (NeRF)~\cite{mildenhall2021nerf}"
- Novel view synthesis (NVS): The task of rendering unseen viewpoints from reconstructed scene representations. "We report NVS metrics (e.g., PSNR, SSIM, and LPIPS)"
- PoseLib: A C++ library for camera pose estimation from geometric constraints. "COLMAP estimates relative camera poses after the ViewGraphCalibration step using PoseLib in C++"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-wise image quality metric used to evaluate renderings. "We report NVS metrics (e.g., PSNR, SSIM, and LPIPS)"
- Quaternion: A 4D unit representation of 3D rotations used for numerically stable pose optimization. "we implement differentiable quaternion addition"
- RANSAC: A robust estimation algorithm that fits models while rejecting outliers via consensus sampling. "robust estimation algorithms such as RANSAC~\cite{fischler1981random}"
- Reprojection error: The 2D difference between observed image points and projections of estimated 3D points, minimized in BA. "minimizing the reprojection error"
- RootSIFT: A SIFT variant using L1 normalization and square-rooting to improve matching robustness. "we use RootSIFT for feature extraction."
- Rotation averaging: A global optimization that estimates consistent absolute rotations from pairwise relative rotations. "rotation averaging~\cite{hartley2013rotation}"
- Schur complement: A matrix factorization trick that reduces BA computation by marginalizing 3D points. "The Schur complement trick~\cite{agarwal2010bundle}"
- SO(3): The Lie group of 3D rotations represented by 3×3 orthonormal matrices with determinant 1. "o_i\in\mathbb{SO}(3)"
- SSIM: Structural Similarity Index Measure, a perceptual metric of image fidelity. "We report NVS metrics (e.g., PSNR, SSIM, and LPIPS)"
- Translation averaging: A global method for estimating camera centers from pairwise relative translations. "translation averaging~\cite{govindu2001combining,jiang2013global}"
- Triangulation: Computing 3D point positions from multiple 2D observations and known camera poses. "3D points triangulated from 2D features~\cite{hartley1997triangulation}"
- Vanishing points: Directions in the image where parallel lines meet, used as geometric cues for SfM. "vanishing points or employ re-triangulation"
- ViewGraphCalibration: A calibration stage operating on the view graph to refine intrinsics/extrinsics before global optimization. "our ViewGraphCalibration step is implemented with PyCeres"
- VGGSfM: A learning-based differentiable SfM pipeline introduced by Wang et al. "end-to-end differentiable SfM pipelines such as VGGSfM~\cite{wang2024vggsfm}"
- VGGT: A feed-forward 3D reconstruction approach leveraging learned image-to-3D encoders. "while deep learning–based SfM pipelines like VGGSfM and VGGT enable feed-forward 3D reconstruction,"
Collections
Sign up for free to add this paper to one or more collections.