- The paper presents the Flow Poke Transformer (FPT) that directly models full multimodal motion distributions conditioned on sparse, localized pokes.
- It employs a transformer architecture with cross-attention to fuse visual features and Fourier-embedded motion vectors, enabling efficient uncertainty quantification.
- Empirical results show FPT's success in diverse tasks, including moving part segmentation and articulated motion prediction, with real-time performance and high generalizability.
The "What If: Understanding Motion Through Sparse Interactions" paper introduces the Flow Poke Transformer (FPT), a transformer-based framework for modeling the distribution of possible motions in a scene, conditioned on sparse, localized interactions ("pokes"). FPT departs from conventional deterministic or sample-based video prediction by directly parameterizing the full, multimodal distribution of local motion, enabling interpretable, efficient, and generalizable motion reasoning. This essay provides a technical summary of the model, its architecture, training methodology, empirical results, and implications for future research in physical scene understanding.
Traditional motion prediction methods, including video frame synthesis and dense optical flow estimation, are limited by their commitment to a single trajectory or sample, failing to capture the inherent uncertainty and multimodality of real-world dynamics. FPT addresses this by modeling the conditional distribution p(f(q)∣P,I), where f(q) is the motion at query point q, P is a set of sparse pokes (each specifying a location and a movement), and I is the input image. This formulation enables the model to reason about the diverse set of possible future motions, conditioned on both visual context and explicit local interventions.
Model Architecture
FPT leverages a transformer architecture to process both poke and query tokens, with cross-attention to visual features extracted from a vision transformer encoder. Each poke is represented as a token with a Fourier-embedded motion vector and relative positional encoding, while each query token corresponds to a location where the motion distribution is to be predicted. The model supports arbitrary, off-grid query locations, facilitating high-quality, sparse supervision from optical tracking.
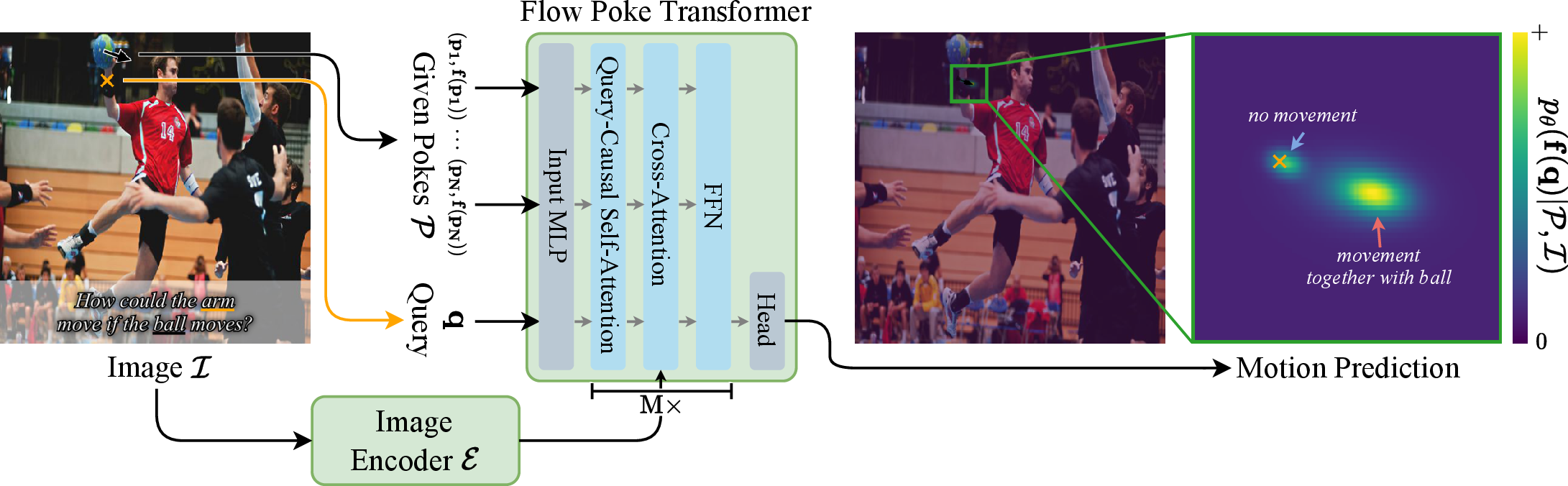
Figure 1: High-level architecture of FPT, showing the integration of image features, poke tokens, and query tokens for explicit distributional motion prediction.
The output head predicts a Gaussian Mixture Model (GMM) for each query, with each component parameterized by a mean and a full (non-diagonal) covariance matrix, allowing for expressive, anisotropic uncertainty modeling. The model is trained to maximize the likelihood of ground-truth flow at random query points, conditioned on random subsets of pokes, using a query-causal attention mask to ensure efficient and scalable training.
Explicit Multimodal Motion Distribution Modeling
A central contribution of FPT is its ability to directly predict the full, continuous, and multimodal distribution of possible motions at each query point, rather than merely enabling sampling. This explicit distributional output allows for:
Empirical analysis demonstrates that the predicted modes are diverse and physically plausible, with the model assigning higher confidence to modes closer to ground truth as more conditioning pokes are provided.
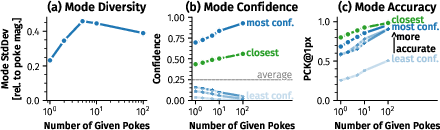
Figure 3: Analysis of predicted modes shows high diversity and meaningful confidence calibration, with dominant modes emerging as uncertainty is reduced by additional pokes.
Training and Implementation Details
FPT is pretrained on large-scale, unstructured web video datasets (e.g., WebVid), using optical flow tracks as supervision. The model employs a ViT-Base backbone for both the image encoder and the poke transformer, with joint training found to be essential for instance-specific motion reasoning.
Key implementation details include:
- Adaptive normalization layers conditioned on camera motion status, enabling robust learning from both static and moving camera videos.
- Efficient query-causal attention, reducing training complexity from O(Np2Nq2) to O(Np2+NpNq).
- High inference throughput (160k predictions/sec on a single H200 GPU) and low latency (<25ms per prediction), supporting real-time applications.
Empirical Evaluation
Motion Distribution Quality and Uncertainty Calibration
FPT's predicted uncertainties are strongly correlated with actual endpoint errors (Pearson ρ≈0.64), indicating well-calibrated probabilistic outputs.
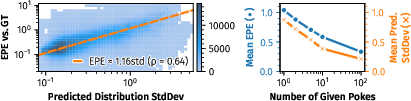
Figure 4: Strong correlation between predicted uncertainty and actual motion prediction error, validating the model's uncertainty calibration.
Dense and Articulated Motion Prediction
On dense face motion generation (TalkingHead-1KH), FPT outperforms specialized baselines (e.g., InstantDrag) in endpoint error, despite being trained generically. On the Drag-A-Move synthetic articulated object dataset, FPT achieves strong zero-shot generalization and, after fine-tuning, surpasses in-domain baselines (e.g., DragAPart, PuppetMaster) in both motion estimation and moving part segmentation.
Moving Part Segmentation
FPT enables direct, information-theoretic segmentation of moving parts by thresholding the KL divergence between conditional and unconditional motion distributions, outperforming prior methods in mIoU and providing spatially continuous, interpretable segmentations.
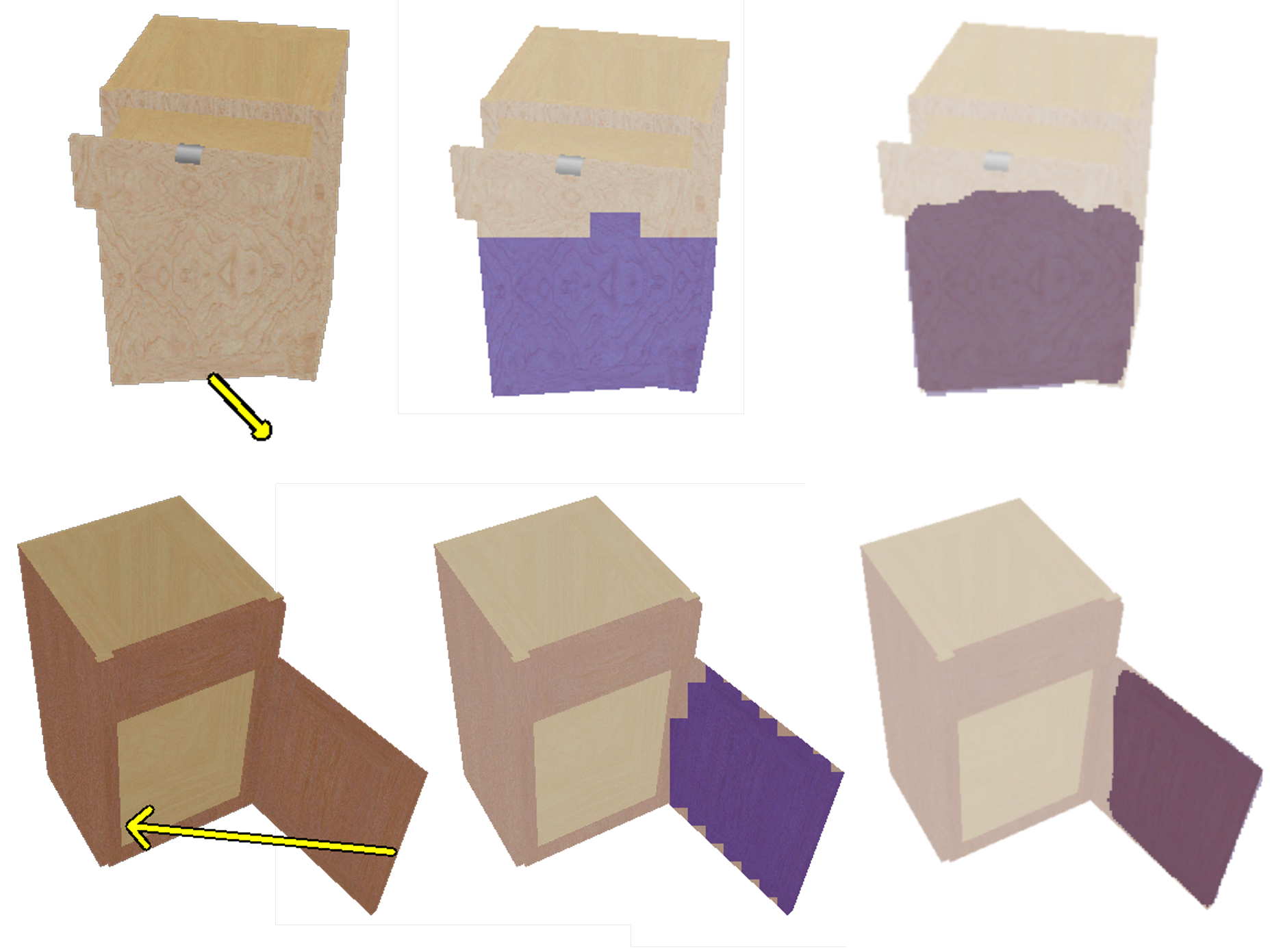
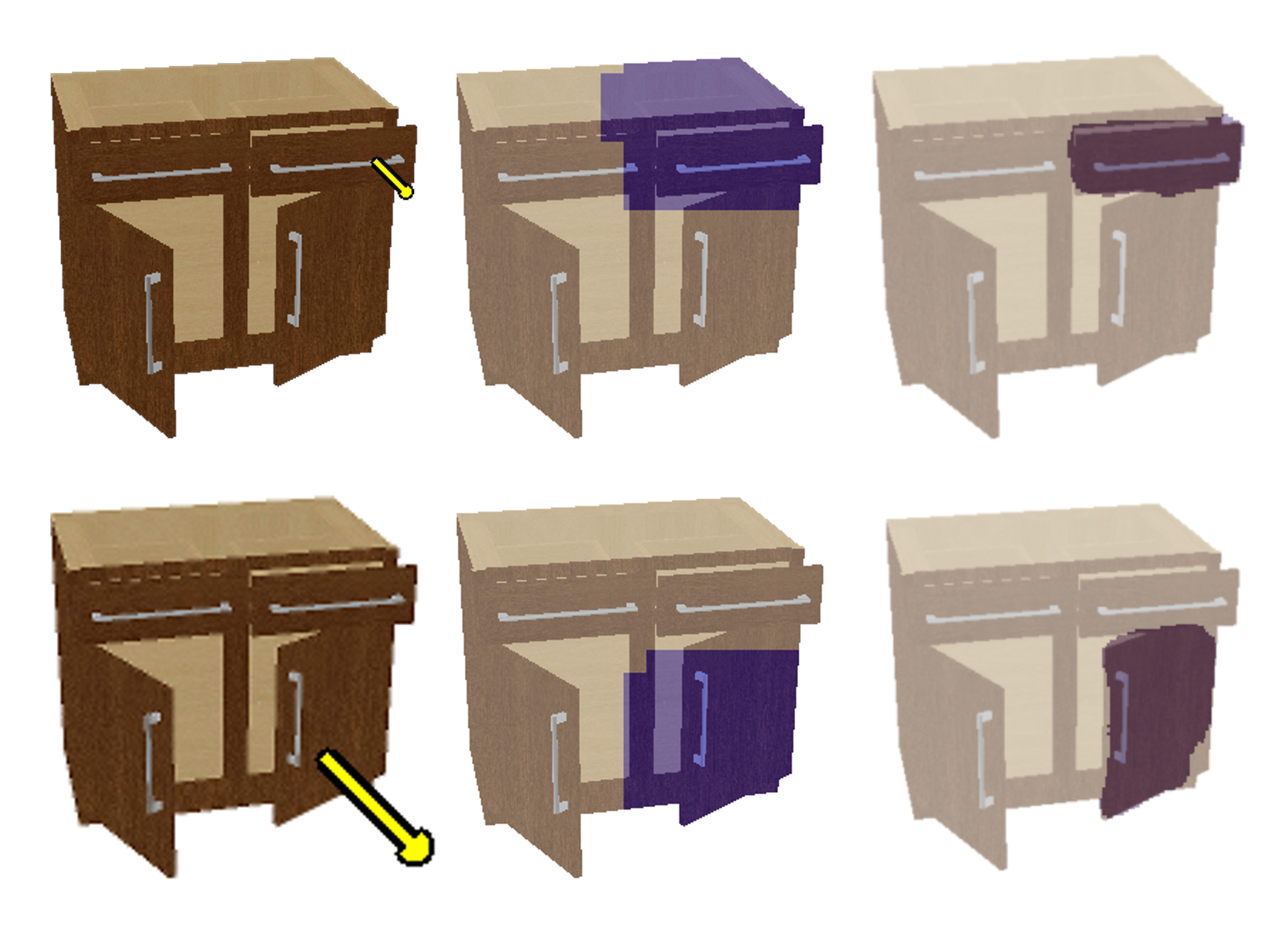
Figure 5: FPT achieves superior moving part segmentation compared to DragAPart, with fewer critical errors and more spatially coherent predictions.
Architectural Insights and Ablations
Ablation studies confirm the importance of:
- Joint training of the vision encoder for instance-specific motion reasoning.



Figure 6: Joint training of the vision encoder is critical for instance-specific motion prediction; freezing the encoder leads to erroneous, non-specific motion transfer.
- Full covariance GMM parameterization for capturing directional uncertainty.
- Moderate GMM component count (e.g., 4) for balancing expressivity and stability.
The query-causal attention mechanism is visualized to illustrate efficient parallel evaluation and causal conditioning.

Figure 7: Query-causal attention pattern enables efficient, causally correct conditioning of queries on poke tokens.
Extension to 3D Motion
FPT's architecture generalizes to 3D motion prediction by extending the output space and supervision to 3D trajectories, as demonstrated by qualitative results on 3D tracking datasets.



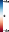


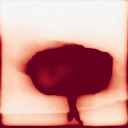
Figure 8: FPT extended to 3D motion prediction, capturing both in-plane and out-of-plane dynamics.
Qualitative Analysis and Failure Modes
FPT demonstrates nuanced, context-dependent motion reasoning, including multimodal predictions for ambiguous scenarios and sensitivity to spatial proximity and physical constraints.


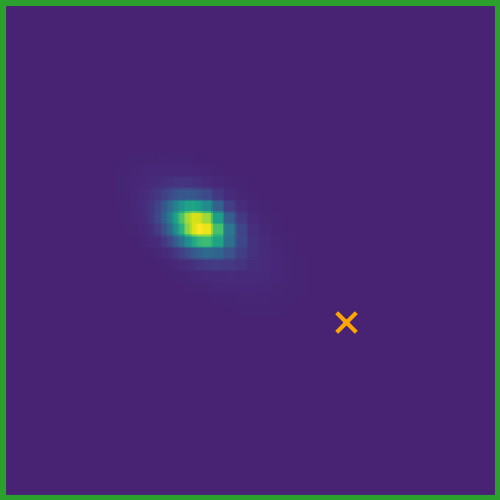



Figure 9: FPT's predicted flow distributions vary with query proximity, reflecting physical dependencies (e.g., head vs. neck movement in a giraffe).
However, the model exhibits failure cases on out-of-domain data (e.g., cartoons) and sometimes incorrectly predicts joint motion of objects and their shadows.
Implications and Future Directions
FPT establishes a new paradigm for motion understanding by directly modeling the full, multimodal distribution of possible motions, conditioned on sparse, interpretable interactions. This approach enables:
- Real-time, interactive simulation and planning in robotics and autonomous systems.
- Direct uncertainty quantification for risk-aware decision making.
- Efficient, generalizable transfer to new domains and tasks via fine-tuning.
The explicit, distributional nature of FPT's outputs facilitates downstream applications such as affordance reasoning, moving part segmentation, and physically plausible video editing. Future research directions include scaling to higher-dimensional motion spaces, integrating with reinforcement learning for closed-loop control, and extending to more complex, agent-driven environments.
Conclusion
The Flow Poke Transformer represents a significant advance in probabilistic motion understanding, providing a scalable, interpretable, and generalizable framework for modeling the stochastic dynamics of physical scenes. By directly predicting explicit, multimodal motion distributions conditioned on sparse interactions, FPT bridges the gap between physical plausibility, efficiency, and actionable uncertainty quantification, with broad implications for computer vision, robotics, and interactive AI systems.
