- The paper introduces a probabilistic formulation of SCR training as maximum likelihood estimation that integrates hand-crafted and learned priors.
- It employs a 3D point cloud diffusion model along with Laplace and Wasserstein priors to enhance depth accuracy and camera pose estimation in indoor scenes.
- Experimental results demonstrate significant improvements in registration rates, novel view synthesis (up to +1.1dB PSNR), and robustness under sparse data conditions.
Scene Coordinate Reconstruction Priors: Probabilistic Regularization for SCR Models
Overview
The paper "Scene Coordinate Reconstruction Priors" (2510.12387) introduces a probabilistic framework for training Scene Coordinate Regression (SCR) models, enabling the integration of high-level reconstruction priors into neural Structure-from-Motion (SfM) pipelines. The authors propose both hand-crafted and learned priors—including a 3D point cloud diffusion model—to regularize SCR training, improving scene geometry, camera pose estimation, and downstream tasks such as novel view synthesis and relocalization. The approach is demonstrated on ACE, ACE0, and GLACE frameworks, showing consistent improvements across multiple indoor datasets.
The core contribution is the reformulation of SCR training as a maximum likelihood estimation problem. The SCR model f predicts 3D scene coordinates yi for image patches pi, and training is cast as maximizing the posterior p(y∣IM,h∗), where IM are mapping images and h∗ are their poses. The loss function is decomposed into a reprojection error (likelihood term) and a regularization term (prior):
−logp(y∣IM,h∗)∝Lreproj−logp(y)
This formulation allows for the seamless integration of priors that encode geometric plausibility, either via explicit depth distributions or learned models.
Hand-Crafted Depth Distribution Priors
Two hand-crafted priors are introduced:
- Laplace Negative Log-Likelihood (NLL): Encourages predicted depths to follow a Laplace distribution fitted to ground truth data, penalizing implausible depth values.
- Wasserstein Distance (WD): Minimizes the Wasserstein distance between the predicted depth distribution and the target Laplace distribution, enforcing both mean and variance constraints.
These priors are lightweight and can be applied per-pixel or per-batch, leveraging the ACE framework's random sampling of scene points.
RGB-D Depth Priors
For scenes with measured depth (RGB-D), the prior is centered at the ground truth depth di∗ for each pixel, with a narrow bandwidth to enforce strong geometric consistency. This is implemented as:
logp(yi)∝logLap(di∣di∗,b′)
where b′ is a small constant (e.g., 10cm).
Learned 3D Point Cloud Diffusion Prior
A key innovation is the use of a 3D point cloud diffusion model as a learned prior. The model is trained offline on ScanNet scenes to capture plausible indoor geometries. During SCR training, the frozen diffusion model provides a gradient of the log-likelihood for the current point cloud, nudging the SCR predictions toward realistic scene layouts.
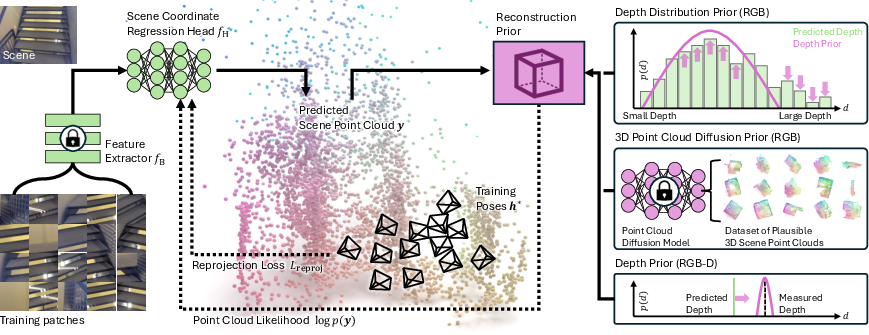
Figure 1: System overview showing SCR training with reprojection loss and regularization via depth distribution or diffusion priors.
The diffusion prior is only applied after sufficient SCR iterations (post 5k), aligning the diffusion time steps with the SCR optimization trajectory. The prior is masked to exclude points with low reprojection error, focusing regularization on ambiguous regions.
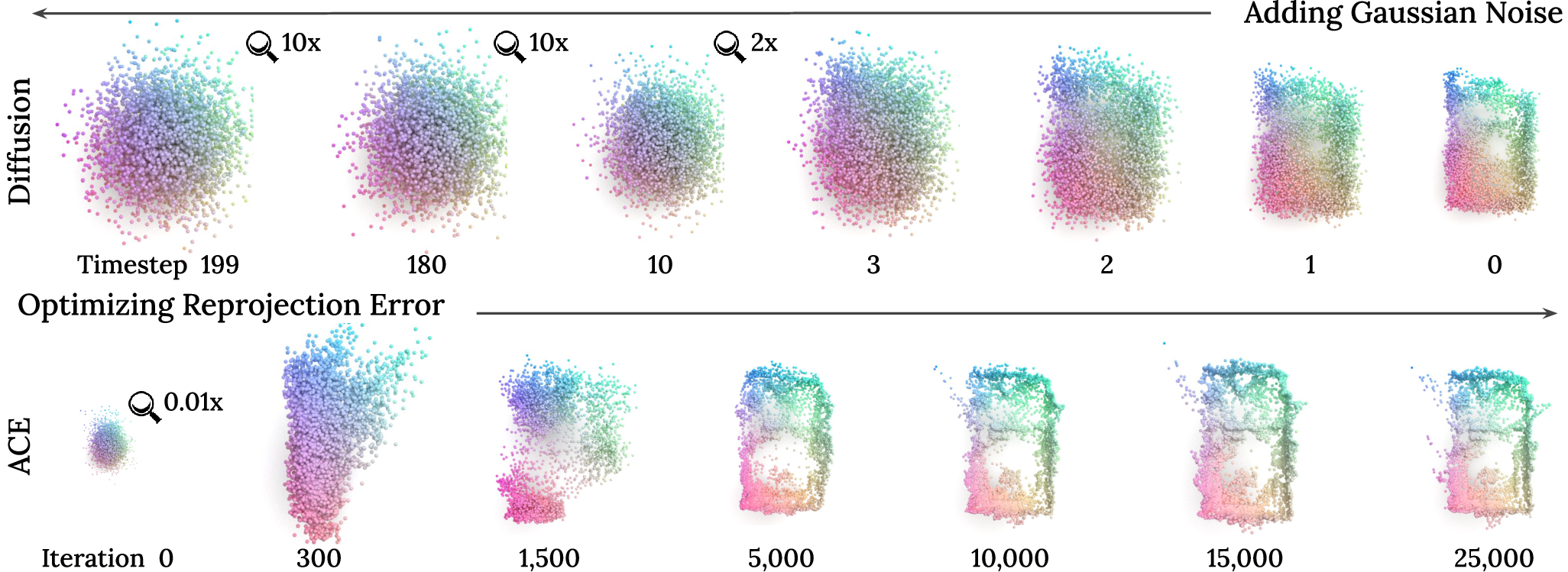
Figure 2: Comparison of ACE training and diffusion process, motivating the alignment of time steps for effective regularization.
Implementation Details
- Diffusion Model Architecture: PVCNN is used for point cloud encoding, with timestep embedding modifications for diffusion.
- Training Protocol: 5,120 points are sampled per scene, with augmentations and normalization. The model is trained for 100k iterations on a single V100 GPU.
- Integration: During SCR mapping, the diffusion prior is applied every k iterations (typically k=4 for efficiency), with gradient normalization to balance regularization and reprojection loss.
Experimental Results
Structure-from-Motion
On ScanNet and Indoor6, the proposed priors yield:
- Higher registration rates: Up to +4.7% on Indoor6 with diffusion prior.
- Improved pose accuracy: Lower ATE/RPE and median errors.
- Better novel view synthesis: PSNR increases up to +1.1dB.
Relocalization
On 7Scenes and Indoor6:
Point Cloud Quality
Depth evaluation shows substantial reductions in outlier points and overall error metrics when using priors, with the diffusion prior outperforming hand-crafted alternatives.

Figure 4: Point clouds generated by the diffusion model and ScanNet, illustrating the learned prior's plausibility.
Ablations
Robustness to Scarce Data
Subsampling mapping frames degrades performance, but ACE with diffusion prior maintains higher accuracy, demonstrating the prior's regularization strength.
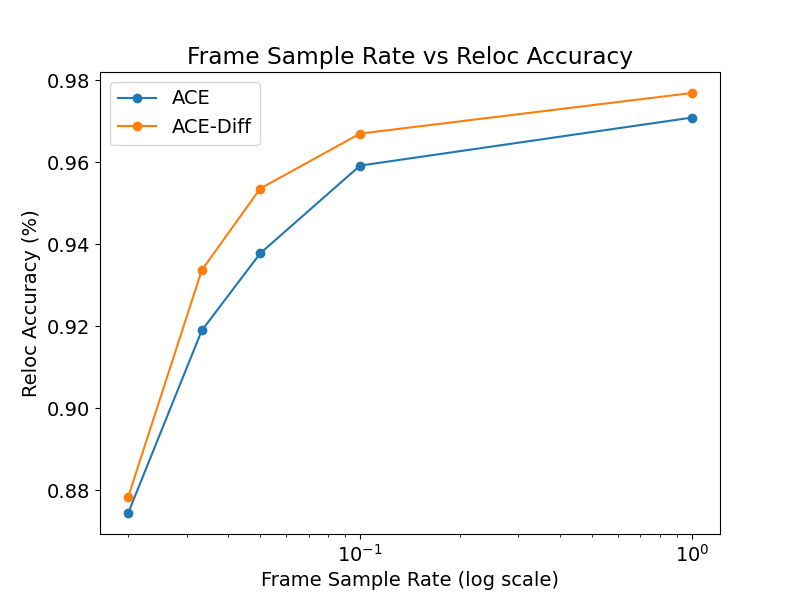
Figure 6: Mapping sample rate vs. accuracy, showing ACE-Diff's robustness to reduced data.
Outdoor Scenes
Preliminary results on Cambridge Landmarks indicate small improvements with indoor-trained priors, but highlight the need for more expressive models and diverse training data for outdoor environments.
Practical and Theoretical Implications
The probabilistic framework enables principled integration of priors into SCR training, improving robustness in ambiguous or under-constrained regions. The learned diffusion prior demonstrates that even low-fidelity generative models can provide effective regularization for scene reconstruction. The approach is modular, applicable to various SCR frameworks, and does not impact test-time efficiency.
Theoretically, the work bridges generative modeling and geometric reconstruction, leveraging score-based diffusion models for 3D scene regularization. The empirical results suggest that high-level priors can mitigate degeneracies inherent in classical and neural SfM pipelines.
Future Directions
- Outdoor scene priors: Requires larger, more diverse datasets and expressive architectures.
- Conditional diffusion models: Incorporating additional signals (e.g., semantics, layout) could further improve regularization.
- Efficient architectures: Balancing fidelity and runtime remains a challenge for large-scale scenes.
Conclusion
The paper presents a rigorous probabilistic approach to SCR training, enabling the integration of both hand-crafted and learned priors. The proposed regularization strategies yield more coherent scene representations, improved camera pose estimation, and enhanced downstream performance, with minimal impact on efficiency. The diffusion prior, in particular, demonstrates the utility of generative models as regularizers in 3D vision tasks, opening avenues for further research in scene-level priors and efficient 3D generative modeling.

Figure 7: Qualitative results on Indoor6, showing reduced noise and improved structure with ACE+Diffusion prior.



