- The paper introduces PhySIC, a novel framework for reconstructing accurate, physically plausible 3D human-scene interactions from a single RGB image.
- It employs a three-stage pipeline incorporating metric-scale scene estimation, SMPL-X based human mesh alignment, and joint optimization with multi-term loss functions to enforce physical consistency.
- Empirical results demonstrate significant reductions in pose error and boosted contact F1-scores compared to prior methods on PROX and RICH datasets.
Introduction and Motivation
The PhySIC framework addresses the longstanding challenge of reconstructing metrically accurate, physically plausible 3D human-scene interactions from a single monocular RGB image. This problem is central to applications in embodied AI, robotics, AR/VR, and 3D scene understanding, where precise localization of humans, scene geometry, and contact reasoning are required. Prior approaches either focus on human pose estimation in isolation, require multi-view or video input, or are limited to specific scene types and single-human scenarios. PhySIC advances the field by enabling joint, metric-scale reconstruction of both humans and their surrounding scenes—including dense contact maps—directly from a single image, while maintaining computational efficiency and generalizability to diverse, in-the-wild settings.
Methodological Overview
PhySIC decomposes the monocular 3D human-scene reconstruction problem into three sequential stages: (1) metric-scale scene estimation with detailed geometry, (2) human mesh reconstruction and alignment, and (3) joint human-scene optimization enforcing physical plausibility. The pipeline leverages state-of-the-art monocular depth and geometry estimators, robust inpainting, and a multi-term optimization objective that harmonizes depth alignment, contact priors, interpenetration avoidance, and 2D reprojection consistency.
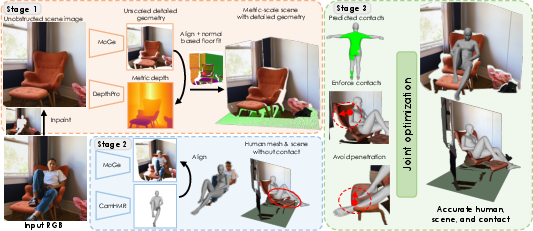
Figure 1: Method overview. Given a single RGB image, PhySIC reconstructs accurate 3D human, scene, and contact information via a three-stage pipeline: scene estimation, human alignment, and joint optimization.
Stage 1: Metric-Scale Scene Estimation
- Occlusion-Aware Inpainting: Human regions are segmented (SAM2) and inpainted (OmniEraser) to yield a complete, unobstructed scene image.
- Hybrid Depth Fusion: Metric depth maps (DepthPro) provide global scale, while high-detail relative geometry (MoGe) supplies local structure. These are aligned via scale and translation optimization (RANSAC-based) to produce a dense, metrically accurate scene point cloud.
- Floor Plane Synthesis: Floor regions are detected and robustly fit with a plane (RANSAC), compensating for missing or unreliable floor geometry, which is critical for contact reasoning.
Stage 2: Human Mesh Reconstruction and Alignment
- Metric Human Point Alignment: Human points are extracted from the original image (MoGe), aligned to the metric scene via scale and shift, and used to initialize the human mesh.
- SMPL-X Mesh Fitting: Initial body pose and shape are estimated by fusing CameraHMR (body) and WiLor (hands), then refined for pixel and metric alignment using 2D joint reprojection and Chamfer distance losses, focusing on camera-facing vertices to avoid back-side misalignment.
Stage 3: Joint Human-Scene Optimization
- Multi-Term Objective: The final optimization jointly refines human pose, global translation, and scene scale by minimizing a loss comprising:
- 2D joint reprojection (Lj2d)
- Depth alignment (Ld)
- Contact attraction (Lc; guided by DECO, with robust thresholding)
- Interpenetration avoidance (Li; occlusion-aware, using per-point normals)
- Regularization (Lreg; constraining deviation from initial estimates, especially for occluded vertices)
- Contact Map Extraction: Post-optimization, per-vertex contact maps are computed based on proximity to the scene surface.
- Multi-Human Extension: The pipeline generalizes to multiple humans by instance-wise segmentation, inpainting, and joint optimization.
Empirical Results
PhySIC demonstrates substantial improvements over prior single-image baselines on the PROX and RICH datasets:
- PROX Dataset:
- Mean per-vertex scene error reduced from 641 mm (baseline) to 227 mm.
- PA-MPJPE halved from 77 mm (HolisticMesh) to 42 mm.
- Contact F1-score improved from 0.09 (DECO) to 0.51.
- RICH Dataset:
- PA-MPJPE reduced from 120 mm (PROX) to 46 mm.
- Contact F1-score increased from 0.07 to 0.43.
These results indicate that PhySIC achieves state-of-the-art accuracy in both pose and contact estimation, with robust generalization to diverse, in-the-wild images.
Qualitative Analysis

Figure 2: Qualitative results on PROX and internet images. PhySIC yields coherent human-scene reconstructions and plausible contacts, outperforming PROX and HolisticMesh, especially in complex or occluded scenarios.
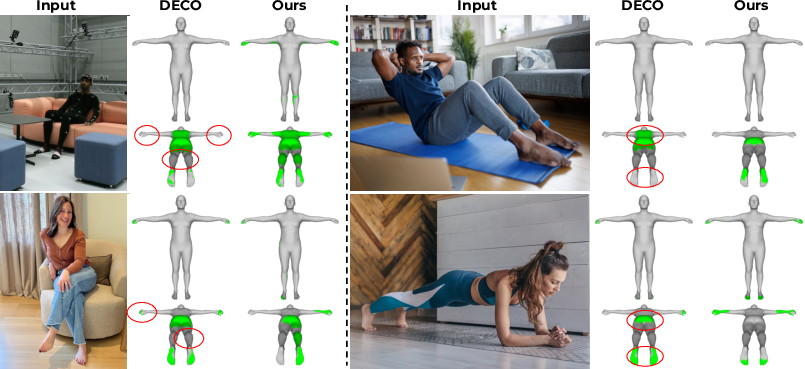
Figure 3: Qualitative results for contact estimation. PhySIC surpasses DECO in nuanced contact prediction, particularly for intricate body parts such as arms and feet.

Figure 4: Qualitative results on internet images. PhySIC generalizes to arbitrary scenes and multiple humans, where HolisticMesh fails to model non-standard surfaces.
Ablation Studies
Ablation experiments confirm the necessity of each loss component:
Implementation and Computational Considerations
- Efficiency: The end-to-end pipeline requires less than 27 seconds per image (9 seconds for joint optimization) on an NVIDIA H100 GPU, with aggressive nearest-neighbor search acceleration via precomputed grids.
- Robustness: The method is resilient to noisy contact predictions and can operate with static contact priors, thanks to robust loss thresholding and occlusion-aware regularization.
- Limitations: Current limitations include reliance on inpainting quality (especially for thin structures), assumption of static, rigid scenes, lack of explicit modeling for small object interactions, and a planar floor assumption. These are expected to be mitigated as inpainting and holistic scene reconstruction methods advance.
Practical and Theoretical Implications
PhySIC's unified, physically grounded approach enables scalable, accessible 3D human-centric scene understanding from unconstrained images. This has direct implications for data collection in embodied AI, simulation, and AR/VR, where large-scale, physically plausible 3D reconstructions are required. The explicit modeling of contact and occlusion sets a new standard for single-image 3D reasoning, bridging the gap between object-centric and human-centric scene understanding.
Theoretically, the work demonstrates that monocular ambiguity in 3D reconstruction can be substantially reduced by integrating strong geometric priors, robust optimization, and explicit physical constraints, even in the absence of multi-view or temporal cues.
Future Directions
- Non-Rigid Scene Modeling: Incorporating deformable scene elements (e.g., soft furniture, clothing) to further enhance interaction realism.
- Fine-Grained Object Interactions: Integrating object mesh estimators and 2D object supervision for detailed human-object contact reasoning.
- Generalized Scene Geometry: Leveraging advances in foundation models for holistic 3D scene reconstruction to relax the planar floor assumption and improve robustness to complex environments.
- Self-Contact and Multi-Modal Supervision: Extending the loss formulation to penalize self-penetration and incorporate additional sensory modalities (e.g., audio, tactile).
Conclusion
PhySIC establishes a new benchmark for physically plausible, metric-scale 3D human-scene interaction and contact reconstruction from a single RGB image. By combining robust initialization, occlusion-aware optimization, and efficient multi-term loss design, it achieves superior accuracy and generalizability compared to prior methods. The framework's scalability and extensibility position it as a foundational tool for future research and applications in holistic 3D scene understanding.

Figure 6: Additional qualitative results for in-the-wild images, demonstrating PhySIC's robustness and generalizability across diverse scenarios.
