- The paper introduces a novel R method that quantifies uncertainty in retrieval-augmented reasoning by modeling both retrieval and generation as a Markov Decision Process.
- It employs three perturbation actions—Query Paraphrasing, Critical Rethinking, and Answer Validation—to generate multiple reasoning paths and derive uncertainty via majority voting.
- Experimental results demonstrate over 5% AUROC gains and significant improvements in abstention and model selection tasks, highlighting the method's efficacy and efficiency.
Uncertainty Quantification for Retrieval-Augmented Reasoning
Introduction
The paper "Uncertainty Quantification for Retrieval-Augmented Reasoning" presents a novel approach to estimating uncertainty in Retrieval-Augmented Reasoning (RAR) systems. RAR combines retrieval-augmented generation with multi-step reasoning to handle complex queries but remains challenged by vulnerability to errors and misleading outputs. This paper addresses these challenges by introducing a new method, Retrieval-Augmented Reasoning Consistency (R), which quantifies uncertainty by modeling the interaction between reasoning and retrieval dynamics in RAR systems.
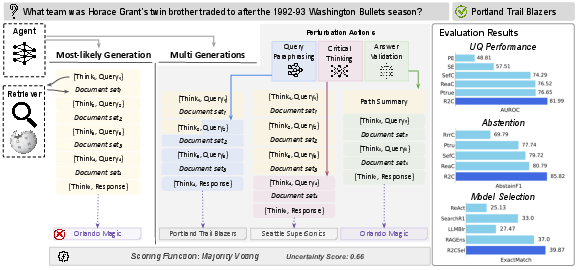
Figure 1: R\ overview. Given a user query, the agent (LLM) first generates the most-likely reasoning path leading to the most-likely response (left, yellow). To estimate uncertainty, R\ creates multiple perturbed generations by randomly altering states in the reasoning path (middle, gray). The uncertainty score is then derived via majority voting. R\ significantly outperforms established UQ\ methods and achieves significant improvements on two downstream tasks: abstention and model selection.
Methodology
The R method models RAR as a Markov Decision Process (MDP), capturing uncertainty from both retrieval and generation processes. It proceeds in two stages: generating the most-likely response and sampling multiple generations through perturbations. These perturbations, executed via actions on reasoning paths, allow exploration of diverse reasoning trajectories, queries, and documents, thereby estimating uncertainty through majority voting.
The approach introduces three perturbation actions:
- Query Paraphrasing (QP): Reformulates search queries to test reasoning path fragility.
- Critical Rethinking (CR): Reassesses previously retrieved information, supporting adjustment towards a more reliable trajectory if necessary.
- Answer Validation (AV): Validates the final response based on predefined criteria of groundedness and correctness, addressing issues with response validation in RAR models.
Experimental Results
The experimental setup spanned multiple datasets including PopQA, HotpotQA, and Musique, employing various RAR models. The proposed R method demonstrated significant improvements over existing UQ methods, achieving over 5% average improvement in AUROC across evaluations.
Additionally, when integrated into downstream tasks like Abstention and Model Selection, R delivered marked improvements, evidencing gains in F1Abstain and AccAbstain in abstention tasks and achieving higher exact match rates in model selection scenarios compared to both individual and ensemble RAR systems.
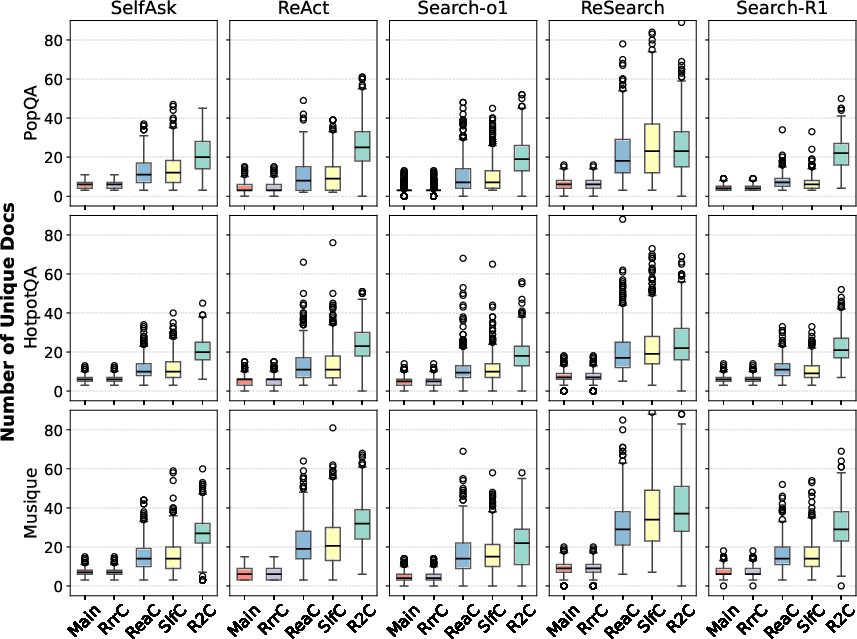
Figure 2: Distribution of the number of unique retrieved documents for the most-likely path (main) and multi-generations.
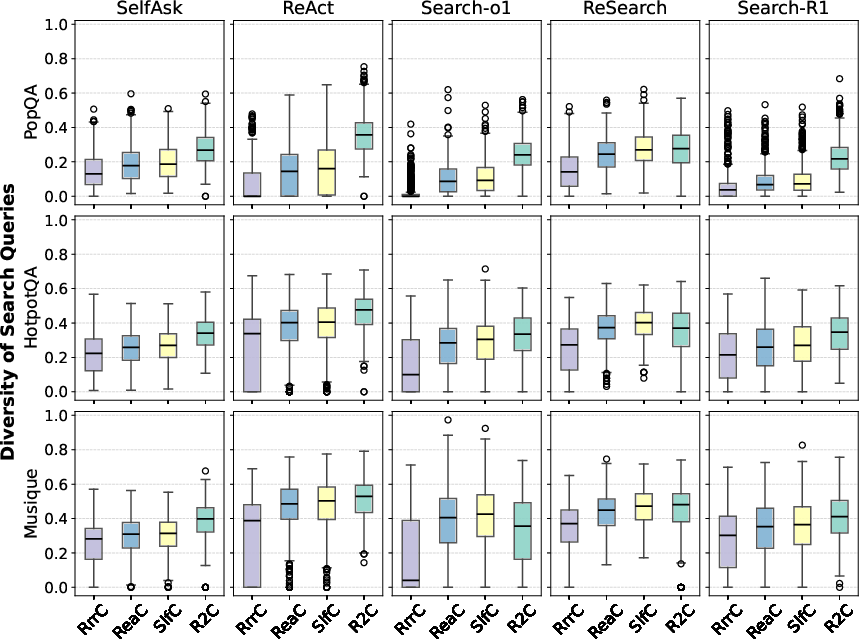
Figure 3: Distribution of diversity scores for search queries generated for each user query across reasoning paths.
Analysis
The study found that R improves performance by capturing diverse retrieval and generation uncertainty sources, reflected in the diversity of retrieved documents and search queries (Figures 2 and 3). By stimulating both the retriever and generator, R effectively creates varied reasoning paths, offering a more comprehensive uncertainty measure than existing methods.
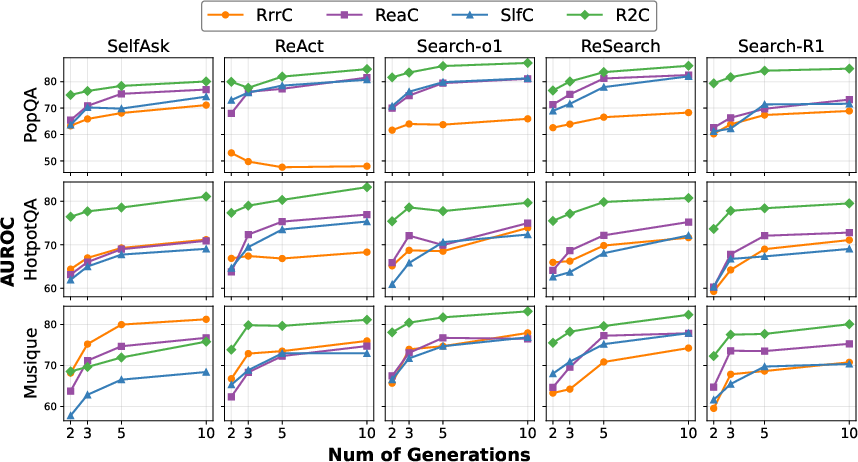
Figure 4: Performance of UQ\ methods with varying numbers of generations.
Efficiency is also enhanced through R's approach, achieving competitive AUROC scores with fewer token generations, underscoring its operational effectiveness even with limited computational resources (Figure 4).
Conclusions and Implications
R introduces a robust framework for uncertainty quantification in RAR systems, addressing multi-source uncertainty through strategic perturbations. Its application not only improves UQ tasks but also enhances performance in tasks like abstention and model selection, showcasing its versatility and efficacy. Future research may focus on optimizing actions per model type or exploring applicability to other domains involving complex multi-source uncertainty beyond short-form QA tasks.
This work underscores the broad applicability of R in enhancing the reliability and effectiveness of LLM-based systems, offering pathways for further exploration of uncertainty quantification in advanced AI applications.