AutoPR: Let's Automate Your Academic Promotion!
Abstract: As the volume of peer-reviewed research surges, scholars increasingly rely on social platforms for discovery, while authors invest considerable effort in promoting their work to ensure visibility and citations. To streamline this process and reduce the reliance on human effort, we introduce Automatic Promotion (AutoPR), a novel task that transforms research papers into accurate, engaging, and timely public content. To enable rigorous evaluation, we release PRBench, a multimodal benchmark that links 512 peer-reviewed articles to high-quality promotional posts, assessing systems along three axes: Fidelity (accuracy and tone), Engagement (audience targeting and appeal), and Alignment (timing and channel optimization). We also introduce PRAgent, a multi-agent framework that automates AutoPR in three stages: content extraction with multimodal preparation, collaborative synthesis for polished outputs, and platform-specific adaptation to optimize norms, tone, and tagging for maximum reach. When compared to direct LLM pipelines on PRBench, PRAgent demonstrates substantial improvements, including a 604% increase in total watch time, a 438% rise in likes, and at least a 2.9x boost in overall engagement. Ablation studies show that platform modeling and targeted promotion contribute the most to these gains. Our results position AutoPR as a tractable, measurable research problem and provide a roadmap for scalable, impactful automated scholarly communication.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “AutoPR: Let’s Automate Your Academic Promotion!”
1) What this paper is about (overview)
This paper is about helping scientists share their research with the world more easily. The authors introduce a new task called “AutoPR,” which means automatically turning a research paper into eye-catching, accurate posts for social media (like X/Twitter or RedNote). They also build a dataset and a smart system to test and improve this process, so science can reach more people without taking tons of time from researchers.
2) What questions the researchers asked (objectives)
The paper asks three simple questions:
- Can we automatically create good social media posts from research papers?
- How do we judge if those posts are accurate, interesting, and well-suited to the platform where they’re posted?
- Can a carefully designed “team of AI helpers” do better than just asking one AI model to write a post?
To answer these, they define three things every good post needs:
- Fidelity: Is it correct and true to the paper?
- Engagement: Will it catch attention and make people care?
- Alignment: Does it fit the platform’s style (tone, hashtags, mentions, visuals)?
3) How they did it (methods), explained simply
Think of their approach like building a smart factory for social posts, plus an exam to grade how well it works.
- The “exam” (PRBench):
- They collected 512 real research papers (mostly from arXiv) and matched each one with a real, human-made social media post that promoted it.
- Experts rated how accurate, engaging, and platform-friendly each post was.
- This dataset acts like a report card to fairly compare different AI systems.
- The “factory” (PRAgent):
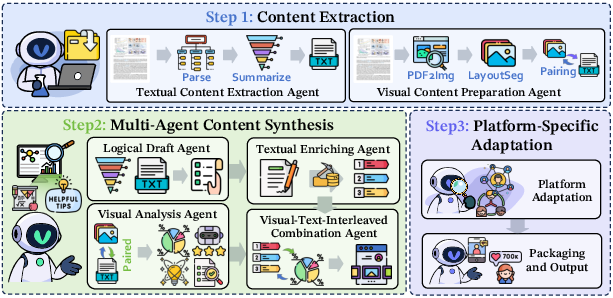
- Stage 1: Content Extraction
- The system reads the PDF of a paper, breaks it into sections, and creates short summaries.
- It also pulls out figures and tables, pairing each image with its caption using layout detection (like a smart organizer that matches pictures to their explanations).
- Stage 2: Multi-Agent Synthesis
- Several specialized AI “agents” work together like a team:
- A Logical Draft Agent writes a clear, structured draft of the post (research question, key method, main results, implications).
- A Visual Analysis Agent explains each figure in simple terms and why it matters.
- A Text Enriching Agent turns the draft into a compelling post (adds hooks, clear storytelling, calls-to-action).
- A Visual-Text Combination Agent decides where images fit best to boost interest.
- Stage 3: Platform-Specific Adaptation
- The system adjusts tone, length, hashtags, mentions, emojis, and formatting depending on whether it’s posting to X/Twitter, RedNote, etc.
- It packages the final post (text plus images) ready for publishing.
- How they score quality (metrics):
- Fidelity: Checks facts and whether authors and titles are shown properly.
- Engagement: Looks at attention hooks, clear storytelling, visuals, and call-to-action.
- Alignment: Evaluates platform style, how text and visuals work together, and smart hashtag/mention use.
- A helpful analogy for the math:
- The system is trying to “balance a recipe” with three ingredients: accuracy, engagement, and platform fit. If you add too much of one, you might lose another. The goal is to find the best mix for the target audience and platform.
4) What they discovered (main findings)
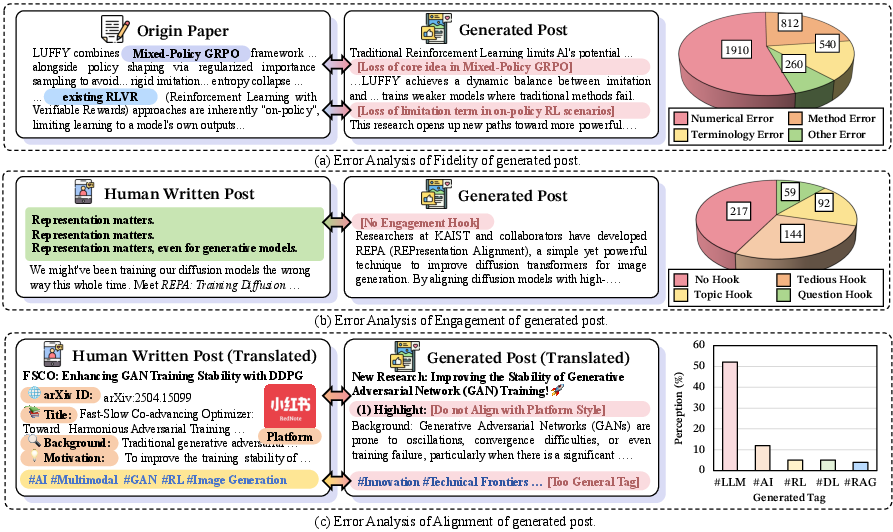
- Regular AI models struggle:
- Many posts missed important facts or used generic tags, and often didn’t feel truly engaging or “human-like.”
- Even strong models made mistakes in details like methods, numbers, and key terms.
- PRAgent does much better than simple, direct prompting:
- On their PRBench tests, PRAgent improves scores across most models and metrics, often by more than 7%, and sometimes by over 20%.
- In a real 10-day trial on RedNote with two accounts (one using PRAgent, the other using a basic method):
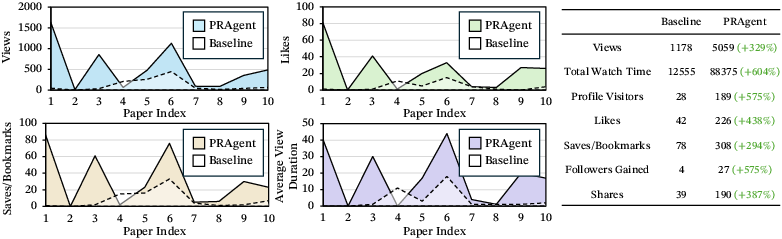
- Total watch time increased by 604%.
- Likes went up by 438%.
- Overall engagement rose by at least 2.9 times.
- Ablation studies (tests where they remove parts of the system) show the biggest gains come from modeling the platform and doing targeted promotion.
5) Why it matters (implications)
This work could change how science reaches people:
- It saves researchers time while keeping posts accurate and appealing.
- It helps important findings get noticed by the right audiences—other scientists, journalists, and the public.
- It creates a fair way to measure and improve automated science communication.
- If used well, it can make science more open and understandable for everyone.
At the same time, the authors note we must still watch out for:
- Accuracy: Make sure facts are correct and specific.
- Authentic voice: Avoid robotic or generic language.
- Smart platform behavior: Use meaningful, niche hashtags and mentions, not just popular ones.
Overall, AutoPR, PRBench, and PRAgent offer a practical roadmap for turning complex research into clear, engaging posts—making science easier to find, understand, and share.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to be actionable for future research:
- Dataset scope and generalizability: PRBench focuses on ~512 pairs from AI-related arXiv CS subfields (June 2024–2025) and two platforms (Twitter/X, RedNote). It is unclear how methods generalize to other disciplines (biomedicine, humanities), venues (journals), and platforms (LinkedIn, Reddit, YouTube, TikTok, Mastodon, Weibo).
- Language and cultural coverage: The benchmark and methods appear primarily English-centric and platform-culture specific; no evaluation of multilingual generation, code-switching, or cross-cultural stylistic norms.
- Human-authored post verification: The “AI-generated likelihood” filtering for selecting human posts lacks methodological detail and validation; potential misclassification could contaminate ground truth and bias evaluation.
- LLM-judged evaluation dependence: Core metrics (fidelity checklist scoring, engagement/alignment preferences) rely heavily on a single LLM judge (Qwen-2.5-VL-72B-Ins). Robustness to judge choice, evaluator bias, and susceptibility to overfitting to the judge are not quantified.
- Human–LLM agreement and reliability: The paper reports correlation selection for the judge but does not provide inter-annotator agreement statistics, calibration curves, or error analysis comparing human vs. LLM scoring at metric level.
- Fidelity checklist construction bias: Checklists are drafted by Gemini and refined by humans; the effect of LLM-drafted seeds on coverage/priority of facts (and downstream model rankings) is unmeasured. Alternatives (pure-human, panel-derived, citation-grounded) are unexplored.
- Objective trade-offs uninstantiated: The formal multi-objective formulation with weights αi is not operationalized (no learning/tuning of αi, no Pareto analysis); how to optimize or adapt trade-offs per audience/platform remains open.
- Audience modeling granularity: PRAgent conditions on a platform identifier but lacks explicit audience segmentation (e.g., peers vs. journalists vs. policymakers), persona-conditioned generation, or evidence of accurate stakeholder targeting.
- Dynamic platform modeling: Alignment appears prompt-based and static; no learning from historical platform analytics, trend/topic detection, optimal posting time/scheduling, or adaptive hashtag/community discovery.
- Engagement authenticity: The paper diagnoses “no-genuine engagement,” but does not propose or test mechanisms to model narrative authenticity, voice consistency, or community norms beyond surface features.
- Real-world evaluation scope: The 10-day RedNote A/B test (10 papers, two new accounts) is small-scale, single-platform, short-duration, and potentially confounded by platform algorithms, follower growth, posting time, and topic effects; no statistical significance or power analysis reported.
- External outcomes and causality: Long-term scholarly impact (downloads, citations, press coverage) and causal links from AutoPR to academic impact are untested; no randomized field experiments or difference-in-differences designs.
- Extraction pipeline reliability: Accuracy of PDF parsing, layout segmentation, and figure–caption pairing (DocLayout-YOLO + nearest-neighbor) is not measured; error propagation to downstream fidelity/engagement is unknown.
- Robustness to challenging documents: No evaluation on scanned PDFs, math-heavy content, complex multi-panel figures, tables, appendices/supplementary materials, or non-standard layouts.
- Multimodal coverage gaps: Visual-text integration is evaluated, but video abstracts, threads, carousels, and platform-native multimedia formats are not addressed; extension to video-first platforms remains unexplored.
- Hallucination mitigation and verification: While fidelity bottlenecks are noted, there is no integrated fact-checking, citation/link verification, uncertainty estimation, or retrieval-grounded generation to prevent promotion-side hallucinations.
- Safety, ethics, and governance: Risks of hype, misrepresentation, altmetrics gaming, undisclosed conflicts, embargo violations, unauthorized tagging, and harassment are unaddressed; no human-in-the-loop safeguards, audit trails, or policy compliance checks are provided.
- Legal and licensing issues: The dataset’s social media content (text/images) may carry platform-specific ToS and copyright constraints; data licensing terms, rights to redistribute images, and privacy considerations are not detailed.
- Cost, latency, and scalability: Inference cost, token/compute budgets, end-to-end latency, throughput under load, and carbon footprint of the multi-agent pipeline are not reported; practical deployment constraints are unclear.
- Reproducibility with closed models: Heavy reliance on proprietary models (e.g., “GPT-5”) limits replicability; exact versions, prompts, seeds, and API settings are insufficiently specified for faithful reproduction.
- Baseline strength and fairness: The direct-prompt baseline design and prompt engineering details are limited; risk that baselines are under-optimized compared to the engineered PRAgent prompts.
- Metric validity and coverage: Alignment and engagement metrics emphasize intrinsic qualities and LLM preferences; extrinsic behavioral metrics (CTR, dwell time, link click-through, conversion to reads/downloads) are not integrated into offline evaluation.
- Cold-start and network effects: Real-world A/B does not control for initial follower seeds, content diversification, or platform rate limits; how AutoPR performs under different account maturities and networks remains unknown.
- Feedback and online learning: No use of bandits/RLHF/safe exploration to learn per-platform, per-audience strategies from live feedback; adaptive improvement loops are missing.
- Content diversity and brand consistency: Mechanisms to avoid repetitive templates across many papers, maintain lab/author voice over time, and manage cross-paper scheduling conflicts are not studied.
- Cross-domain compliance: Promotion in regulated areas (medical/clinical, dual-use AI) may require disclaimers and compliance checks; domain-specific constraints and guardrails are not modeled or evaluated.
- Benchmark contamination and leakage: Using LLMs in both dataset construction (checklists) and evaluation raises leakage concerns; no adversarial or cross-judge validation to assess sensitivity to such contamination.
- Data release completeness: It is unclear whether full prompts, judge prompts, annotation guidelines, and per-item human/LLM scores are released for independent auditing and benchmarking.
Practical Applications
Immediate Applications
The following items describe practical use cases that can be deployed now, leveraging the paper’s AutoPR task definition, PRBench benchmark, and PRAgent multi-agent framework.
- AutoPR for individual researchers and labs (academia)
- What it enables: One-click generation of trustworthy, platform-optimized posts (threads, visuals, CTAs) from a paper’s PDF, figures, and key results to increase visibility and altmetrics.
- Tools/workflows: PRAgent pipeline (hierarchical summarization, figure-caption pairing via DocLayout-YOLO, platform-specific adaptation); scheduling via platform APIs; optional human-in-the-loop review.
- Assumptions/dependencies: LLM/API access; rights to reuse figures; institutional branding guidelines; author approvals; platform ToS adherence.
- University communications and press offices (academia, media)
- What it enables: Rapid creation of press releases, social threads, graphical abstracts, and media kits aligned to platform norms and audience segments (peers, journalists, policymakers).
- Tools/workflows: PRAgent integrated with editorial CMS; PRBench-driven quality checks (Fidelity, Engagement, Alignment); A/B testing hooks and hashtags.
- Assumptions/dependencies: Embargo management; legal/compliance review; narrative tone alignment; crisis comms protocols.
- Journal and conference promotion automation (publishing)
- What it enables: Batch promotion of accepted papers (daily highlight threads, author tag mapping, session-specific visuals) with measurable quality and reach.
- Tools/workflows: Editorial plugins for PRAgent; PRBench scoring to QA posts; hashtag/mention strategy modeling; auto-packaging of Markdown + assets.
- Assumptions/dependencies: Author consent; rights to publish figures; platform API rate limits; moderation policies.
- Corporate R&D communications (software, robotics, energy, healthcare, finance)
- What it enables: Promotion of white papers, patents, benchmarks, and case studies to technical and investor audiences with tailored tone and CTAs.
- Tools/workflows: PRAgent adapted to corporate voice; gated review flows; role-based approvals; channel-specific templates (LinkedIn, X, industry forums).
- Assumptions/dependencies: IP/NDAs; regulatory constraints (e.g., medical claims); reputational risk controls; brand compliance.
- Altmetrics optimization and reporting (academia, publishing, media)
- What it enables: Systematic A/B testing of hooks, CTAs, visuals, and hashtag strategies with dashboards tracking Fidelity, Engagement, Alignment, and downstream altmetrics.
- Tools/workflows: PRBench metrics + analytics; engagement trend monitoring; campaign iteration via PRAgent; cohort comparisons.
- Assumptions/dependencies: Reliable analytics access; ethical A/B testing; awareness that altmetrics-citation links are not guaranteed.
- Visual abstract and figure-first social content (academia, healthcare)
- What it enables: Auto-conversion of figures/tables into social-friendly images with clear captions and narrative context, improving comprehension for non-experts.
- Tools/workflows: DocLayout-YOLO for layout segmentation; Visual Analysis Agent; rich-text post composer inserting visual placeholders.
- Assumptions/dependencies: Sufficient figure quality; reuse permissions; accessibility (alt-text) requirements.
- Targeted community outreach via hashtag/mention strategy (media, academia)
- What it enables: Tagging of niche communities (SIGs, subfields, journalist lists) to maximize discoverability; avoidance of generic low-value tags.
- Tools/workflows: Platform-specific adaptation prompts; curated influencer/community lists; mention/hashtag audits.
- Assumptions/dependencies: Up-to-date community maps; spam risk management; platform culture sensitivity.
- Multilingual dissemination (global academia, policy, education)
- What it enables: Posts tailored to multiple languages and cultural norms for broader reach (e.g., English, Chinese, Spanish).
- Tools/workflows: PRAgent multilingual prompting; local platform style modeling (e.g., X vs. RedNote); CTA localization.
- Assumptions/dependencies: Translation quality; culturally appropriate tone; local platform ToS.
- Automated newsletters and institutional digests (academia, daily life)
- What it enables: Weekly/monthly digests compiling AutoPR posts with links, visuals, and short takeaways for departments, centers, or the public.
- Tools/workflows: Batch PRAgent runs; editorial curation; email/website syndication; simple RSS/JSON feeds.
- Assumptions/dependencies: Duplicate detection; topic diversity; opt-in subscriber management.
- Course and lab update promotion (education)
- What it enables: Student-facing summaries of recent lab papers; course highlight threads explaining relevance to curriculum.
- Tools/workflows: PRAgent + instructor review; simplified CTAs (read the paper, try the code); visual explainers mapped to learning objectives.
- Assumptions/dependencies: Pedagogical accuracy; avoidance of overclaim; coordination with teaching teams.
- Evaluation-as-a-Service (EaaS) for PR quality (publishing, academia, software)
- What it enables: API scoring of human- or AI-authored posts against PRBench metrics to gate publication or recommend revisions.
- Tools/workflows: LLM judge aligned with human annotations; rubric-based scoring; revision recommendations.
- Assumptions/dependencies: Model-judge reliability; rubric acceptance; latency/cost constraints.
- “PR-as-a-Service” SaaS products (industry)
- What it enables: Turnkey offerings for labs, journals, and companies to upload PDFs and receive ready-to-post assets with scheduling and analytics.
- Tools/workflows: Hosted PRAgent; user roles and approvals; integration with ORCID/arXiv/GitHub; social platform connectors.
- Assumptions/dependencies: Security/privacy; rate limits; sustainable unit economics; customer support capacity.
Long-Term Applications
These use cases require further research, scaling, or development, including better platform modeling, human oversight protocols, and stronger fidelity guarantees.
- End-to-end AI4Research dissemination loop (academia)
- What it enables: Closed-loop systems that learn from engagement signals to refine hooks, visuals, hashtags, and timing while preserving Fidelity.
- Tools/workflows: Reinforcement learning on PRBench-aligned objectives (, , ); continuous A/B testing; author-in-the-loop guardrails.
- Assumptions/dependencies: Safe optimization; unbiased feedback; robust attribution of effects; governance.
- Personalized research discovery feeds (daily life, industry, academia)
- What it enables: Reader-specific AutoPR summaries tuned to expertise, interests, and device, improving comprehension and reducing overload.
- Tools/workflows: User modeling; explainable recommenders; progressive disclosure (expert vs. lay summaries).
- Assumptions/dependencies: Privacy compliance; filter-bubble mitigation; transparency of personalization.
- Automated science journalism copilot (media, policy)
- What it enables: Transformation of papers into journalist-ready briefs and articles, with evidence checks and quotes, for editors to refine.
- Tools/workflows: Multi-agent pipelines for claim extraction, source triangulation, and narrative building; newsroom CMS integration.
- Assumptions/dependencies: Strong factual verification; legal review; editorial standards alignment.
- Impact forecasting for funding and policy prioritization (policy)
- What it enables: Using engagement + PRBench scores to predict likely adoption/citation and identify topics for targeted funding or public outreach.
- Tools/workflows: Multimodal predictive models; cohort analyses; scenario testing.
- Assumptions/dependencies: Stable correlations; avoidance of popularity bias; ethical oversight.
- Cross-platform optimization with dynamic posting (industry, media)
- What it enables: Multi-armed bandit scheduling that adapts timing, formats, and CTAs across platforms to maximize reach with minimal fatigue.
- Tools/workflows: Orchestration agents; platform affordance modeling; automated pacing.
- Assumptions/dependencies: Access to reliable platform analytics; ToS compliance; algorithmic transparency.
- Extension beyond academic papers (healthcare, energy, finance, public sector)
- What it enables: AutoPR for clinical trial reports, sustainability disclosures, technical standards, and regulatory filings with tailored messaging.
- Tools/workflows: Domain-specific prompts and checklists; compliance modules (e.g., FDA/EMA, SEC).
- Assumptions/dependencies: Regulatory approvals; medical/financial claim verification; sensitive data handling.
- Accessibility-first dissemination (healthcare, education, policy)
- What it enables: Systematic generation of plain-language summaries, alt-text, color-safe visuals, captions, and screen-reader-friendly formats.
- Tools/workflows: Accessibility prompts; automated alt-text generation; WCAG-aligned templates.
- Assumptions/dependencies: Standards compliance; testing with diverse user groups; continuous improvement.
- Knowledge graph ingestion and semantic indexing (software, academia)
- What it enables: Structured extraction (weighted factual checklists) to update knowledge graphs and enable semantic search across literature.
- Tools/workflows: Fact extraction APIs; provenance metadata; conflict resolution in graphs.
- Assumptions/dependencies: High-fidelity extraction; ontology alignment; cross-paper disambiguation.
- Generative video and interactive assets (media, education)
- What it enables: Auto-creation of short explainer videos, carousel posts, and interactive storyboards from figures and key results.
- Tools/workflows: Multimodal LLMs for storyboard + script; text-to-video generation; interactive embedding on web.
- Assumptions/dependencies: Compute costs; rights to content; quality controls for scientific accuracy.
- Integrity, provenance, and authorship tooling (policy, academia, software)
- What it enables: Watermarking, AI-content disclosures, citation/assertion provenance, and author attribution tracking across posts.
- Tools/workflows: Metadata standards; audit logs; platform-side verification mechanisms.
- Assumptions/dependencies: Community standards; platform support; low-friction UX.
- Community moderation and misinformation monitoring (policy, media)
- What it enables: Detection and flagging of low-fidelity or misleading promotions using PRBench-derived heuristics and LLM judges.
- Tools/workflows: Risk scoring; human review queues; appeal processes.
- Assumptions/dependencies: Balanced precision/recall; bias mitigation; clear governance.
- Marketplace and ecosystem of promotion assets (industry, academia)
- What it enables: Templates, plugins, and agent bundles (e.g., “Academic Promo CMS,” “ArXiv/Overleaf plugin,” “Lab PR Bot”) for varied stakeholders.
- Tools/workflows: Standardized APIs; modular agents; billing and analytics.
- Assumptions/dependencies: Developer adoption; sustainable business models; interoperability across platforms.
Notes on Feasibility and Risks Across Applications
- Technical: Dependence on high-quality LLMs and multimodal models; robust PDF parsing and layout segmentation; access to platform APIs.
- Legal/compliance: IP rights for figures; embargoes; regulatory constraints (especially in healthcare/finance); platform automation policies.
- Ethical: Fidelity is critical—human-in-the-loop review recommended; avoid engagement-optimizing at the expense of accuracy; disclose AI assistance.
- Operational: Cost control for API usage; content moderation and spam risk; maintaining up-to-date community and hashtag maps; localization quality.
- Measurement: Altmetrics are complementary to citations; do not assume direct causal impact without controlled studies; use PRBench metrics as proxies with caution.
Glossary
- Ablation studies: Controlled experiments that remove or modify components to quantify their contribution to overall performance. "Ablation studies show that platform modeling and targeted promotion contribute the most to these gains."
- Affordances (platform affordances): Features and constraints of a platform that shape how users can act and what strategies work effectively. "Informed by the theory of platform affordances which highlights the need for platform-specific strategies~\citep{marabelli2018social}, alignment evaluation measures how well the generated content conforms to the norms and expectations of specific social media platforms ."
- AI4Research: The use of artificial intelligence to support and automate research processes such as discovery, generation, and writing. "Artificial intelligence is reshaping science, giving rise to AI for Research (AI4Research)~\citep{chen2025ai4research, zhou2025hypothesis}."
- Alignment Evaluation: Assessment of how well generated content matches the norms, style, and expectations of a specific platform. "alignment evaluation measures how well the generated content conforms to the norms and expectations of specific social media platforms ."
- Altmetrics: Alternative measures of scholarly impact based on online attention and social media activity rather than traditional citations. "Social media has become integral to scientific dissemination~\citep{van2011scientists}, driving the rise of altmetrics as complements to citations~\citep{bornmann2014altmetrics}."
- Argmax: The operation that returns the argument (input) at which a given function attains its maximum value. "\hat{P} = \operatorname*{argmax}\limits_{P}\mathbf{Pr}(P\mid \mathbb{D}, \mathbb{T}_P, \mathbb{T}_A)."
- Bounding boxes: Rectangular regions used in computer vision to localize and label objects or components in an image. "This model detects bounding boxes for visual components (e.g., figure, table) and their captions."
- Call-To-Action (CTA): A directive within content that encourages the audience to take a specific next step (e.g., read the paper, share, follow). "(4) Call-To-Action (CTA) Score measures the effectiveness of guiding the audience toward a desired next deeper action (e.g., reading the paper)."
- Consensus deliberation: A reconciliation process where annotators discuss differing judgments to reach an agreed-upon final score. "larger discrepancies were settled by consensus deliberation."
- Context window: The maximum span of text an LLM can consider at once when generating or evaluating content. "Content within the LLMâs context window undergoes a single-pass summary."
- DocLayout-YOLO: A YOLO-based model specialized for detecting and segmenting document layout components such as figures and tables. "We utilize DocLayout-YOLO~\citep{zhao2024doclayout} to perform layout analysis on each page image."
- DPI (dots per inch): A measure of image resolution that indicates the number of distinct dots that can fit within a linear inch. "First, we render each source PDF page into a high-resolution (250 DPI) PNG image."
- Factual Checklist Score: A weighted metric that quantifies how many key facts from a source document a promotional post correctly includes. "The Factual Checklist Score is calculated as:"
- Fidelity: The degree to which generated content is factually accurate, complete, and appropriately presented relative to the source document. "assessing systems along three axes: Fidelity (accuracy and tone), Engagement (audience targeting and appeal), and Alignment (timing and channel optimization)."
- Hierarchical summarization: A multi-level summarization approach that condenses long documents by summarizing sections and recursively combining them. "(2) Hierarchical Summarization: It condenses the body text by adaptive hierarchical summarization."
- Jaccard similarity: A set-based similarity metric defined as intersection over union, commonly used to compare collections like hashtags. "The average Jaccard similarity between generated and human hashtags was only 0.03, demonstrating failure to capture niche keywords critical for targeted discovery."
- Layout segmentation: The process of partitioning a document page into labeled components (e.g., figures, tables, captions) via detection methods. "(2) Layout Segmentation (): We utilize DocLayout-YOLO~\citep{zhao2024doclayout} to perform layout analysis on each page image."
- LLM judge: A LLM used as an evaluator to score content against specified criteria. "where is the verdict from the LLM judge, a numerical score between 0 and 1."
- Multimodal LLM: A LLM capable of processing and integrating multiple data modalities (e.g., text and images). "it uses a Multimodal LLM () to produce a comprehensive analysis ()..."
- Multi-agent framework: An architecture in which multiple specialized agents collaborate to solve a complex task through coordinated stages. "PRAgent is a multi-agent framework for the autonomous transformation of academic papers into platform-specific social media posts."
- Multi-objective optimization: Optimization that seeks solutions maximizing or balancing several potentially conflicting objectives simultaneously. "This is a multi-objective optimization problem, as the core objectives are often in tension with one another."
- Nearest-neighbor algorithm: A proximity-based method that associates items (e.g., figures and captions) based on spatial or metric closeness. "Then, we utilize a nearest-neighbor algorithm to associate visual elements with their captions and descriptions based on vertical proximity and a distance threshold."
- Orchestration Agent: A controller agent responsible for final refinement, platform adaptation, and packaging of promotional content. "The final stage is managed by an Orchestration Agent, which refines the integrated draft for publication."
- Pairwise comparisons: An evaluation technique that compares two items at a time to determine relative preference or effectiveness. "The subjective preference engagement score is defined as the average win rate in pairwise comparisons under two perspectives: (1) Professional Interest... (2) Broader Interest..."
- Platform Interest: A preference-based metric indicating which post is more effective for a specific platform in comparative evaluation. "The subjective preference alignment quality score is derived from the Platform Interest, in which the post is evaluated against a reference post ."
- Platform modeling: Representing and learning platform-specific norms and behaviors to guide content generation and optimization. "Ablation studies show that platform modeling and targeted promotion contribute the most to these gains."
- Platform-Specific Adaptation: Tailoring content to match a target platform’s style, tone, formatting, and engagement mechanisms. "(3) Platform-Specific Adaptation models platform-specific preferences, allowing PRAgent to adjust tone and tagging to maximize user engagement."
- PRBench: A multimodal benchmark that pairs research papers with promotional posts to evaluate automated academic promotion systems. "To enable rigorous evaluation, we release PRBench, a multimodal benchmark that links 512 peer-reviewed articles to high-quality promotional posts..."
- PyMuPDF: A Python library used for parsing and converting PDF documents into structured formats like HTML. "The document is first converted into intermediate HTML via PyMuPDF."
- Stratified sampling: A sampling strategy that preserves the distribution across predefined strata to create representative subsets. "PRBench-Core, a subset of 128 samples selected through stratified sampling."
- Structural parsing: Converting a raw document into a structured representation by identifying and extracting its components and hierarchy. "(1) Structural Parsing: The document is first converted into intermediate HTML via PyMuPDF."
- Visual abstract: A graphical summary designed to communicate a paper’s key findings quickly to a broad audience. "specifying inputs (manuscripts, figures, key findings) and outputs (press releases, social media posts, visual abstracts)."
- Visual–Text Integration: The evaluation of how effectively textual and visual elements are coordinated for a specific platform. "(2) VisualâText Integration evaluates the effectiveness of coordination between textual and visual elements for the specific platform."
- Weighted factual checklist: A set of key facts with assigned importance weights used to measure a post’s factual coverage. "we create a weighted factual checklist ."
Collections
Sign up for free to add this paper to one or more collections.