- The paper introduces a transformer-based imitation learning framework that autonomously navigates soft robotic guidewires with an 89% success rate in rearranged vascular mazes.
- The paper integrates goal conditioning and real-time fluoroscopic feedback to address challenges posed by tortuous, under-actuated, and visually occluded vessel environments.
- The paper outperforms traditional baselines, achieving 83% success in novel geometries, and provides actionable insights for improving clinical translation.
Autonomous Soft Robotic Guidewire Navigation via Imitation Learning
Introduction and Motivation
The paper presents a transformer-based imitation learning framework for autonomous navigation of soft robotic guidewires in endovascular surgery, specifically targeting intracranial aneurysm treatment. The motivation stems from the inherent challenges in controlling highly flexible, under-actuated tools within tortuous vascular geometries, compounded by limited and intermittent visual feedback under fluoroscopy. The approach leverages large-scale physical demonstrations in modular, 3D-printed vessel mazes to address the complexities of vessel-tool interactions and visual occlusion, aiming to generalize navigation policies to unseen anatomical configurations.
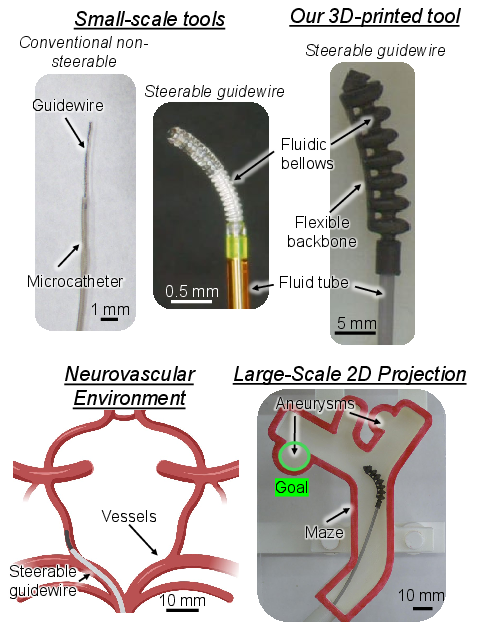
Figure 1: Commercial and soft robotic guidewires, with deployment in 2D vascular geometries for experimental validation.
Hardware and Experimental Setup
The robotic platform consists of a 3D-printed, fluid-driven soft actuator with bidirectional bending, actuated via a custom syringe pump and translation drive. Demonstrations are collected using a teleoperated control handle that maps user-applied forces to robot velocities, enabling intuitive data acquisition for imitation learning.
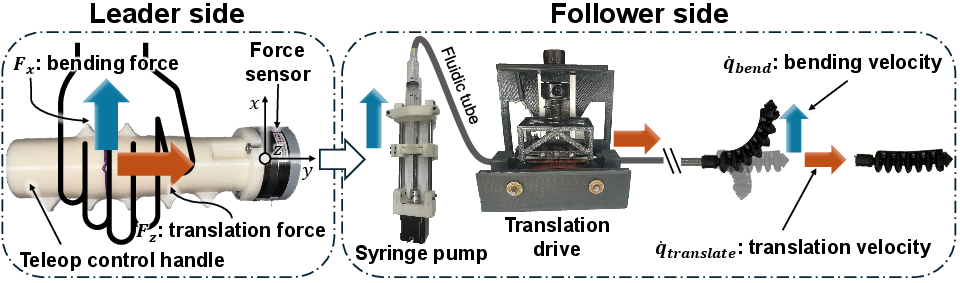
Figure 2: Teleoperated control handle mapping user forces to robot bending and translation velocities.
Maze environments are constructed from modular bifurcations and branches, allowing systematic evaluation of generalization to both rearranged and novel geometries. Real-time robot segmentation and tip tracking are achieved using a UNet trained on annotated images, with ground truth masks generated via SAM 2. Fluoroscopic feedback is simulated by overlaying robot segmentation on noisy backgrounds, with contrast dye injection visualized through dynamic vessel filling.
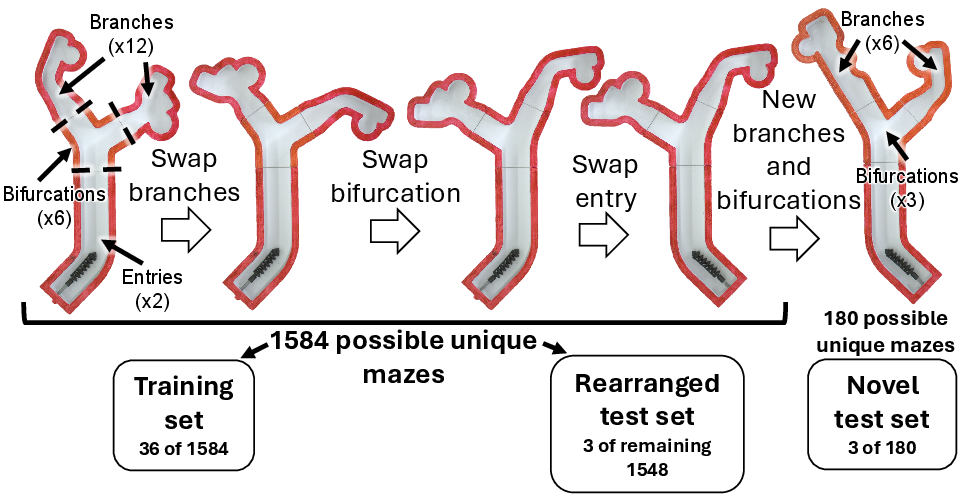
Figure 3: Modular maze design for training, rearranged, and novel test sets, enabling controlled evaluation of generalization.
Imitation Learning Framework
The core contribution is a transformer-based action-chunking policy, inspired by the Surgical Robot Transformer (SRT), which predicts sequences of relative motor actions and contrast injection decisions conditioned on live fluoroscopic images and a goal feature map. The goal representation encodes pixelwise distances to the target aneurysm, providing spatial guidance robust to roadmap inaccuracies via random rigid transformations.
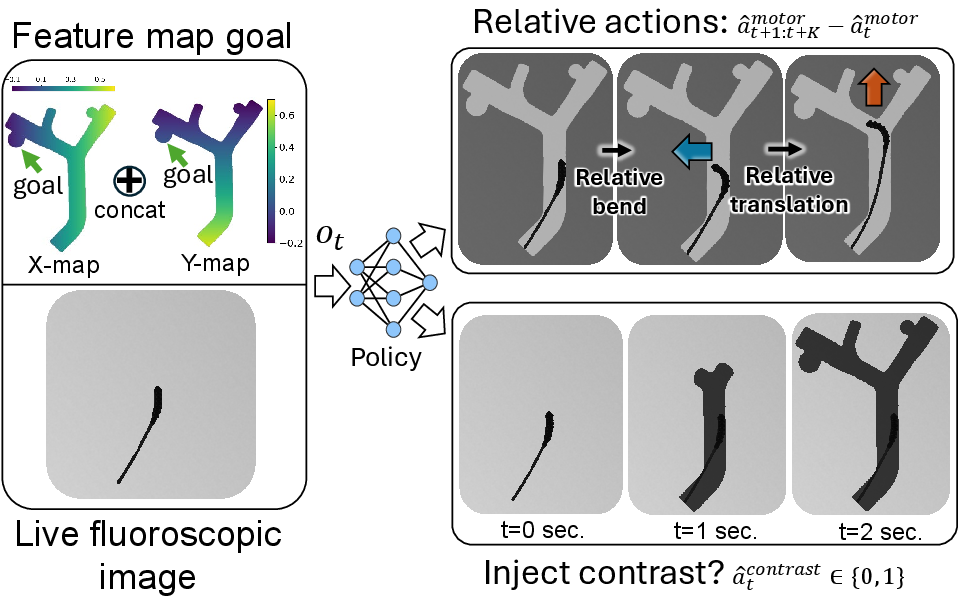
Figure 4: Architecture for autonomous navigation, integrating static goal representation and live fluoroscopic input to output action sequences and contrast injection decisions.
The policy is trained on 647 demonstrations (218 normal, 429 recovery) using DAgger-style dataset aggregation to enhance robustness to failure modes. The action outputs are relative to current motor positions, mitigating issues from actuator hysteresis and environmental variability. Contrast injection prediction is formulated as a binary decision over action chunks, optimized via weighted binary cross-entropy to address class imbalance.
Experimental Results
Chunk Size and Ablation Studies
Chunk size is critical for long-horizon tasks with intermittent observations; a two-second chunk yields the highest success rate (89%) on rearranged geometries. Ablation studies reveal the necessity of recovery data, model-predicted contrast injection, feature map goal representation, and relative action outputs for generalization to novel geometries.
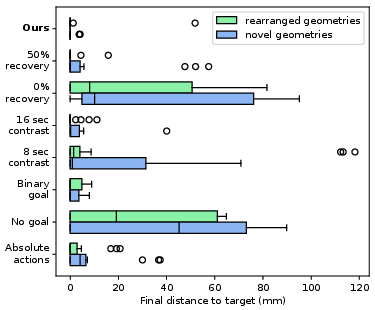
Figure 5: Final distance to goal aneurysm for ablative models, highlighting the impact of each design choice.
Baseline Comparisons
The proposed model achieves an 83% success rate on novel geometries, matching expert clinicians and outperforming state-of-the-art diffusion policies (22%), MLPs (28%), and classical centerline-following controllers (50%). Notably, the diffusion policy frequently induces buckling failures, while the MLP is prone to oscillatory behavior due to lack of temporal context.
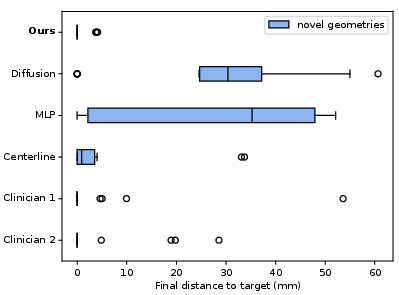
Figure 6: Final distance to goal aneurysm for baseline models on novel geometries.
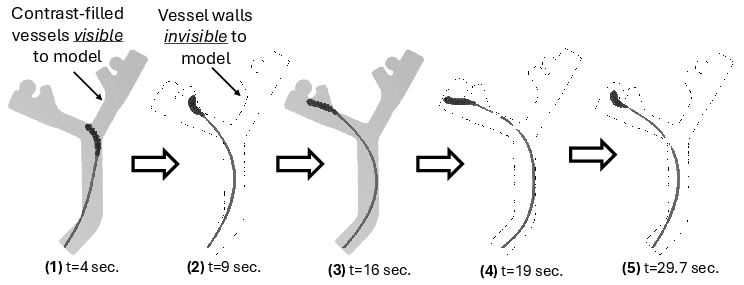
Figure 7: Successful policy rollout in a rearranged maze, demonstrating autonomous contrast injection and recovery from navigation errors.
Failure Mode Analysis
Failure modes are categorized as oscillating, stalling, or buckling. The transformer-based policy predominantly exhibits stalling, whereas diffusion and centerline policies are susceptible to buckling and stalling, respectively. Clinicians and MLPs primarily encounter oscillatory failures.
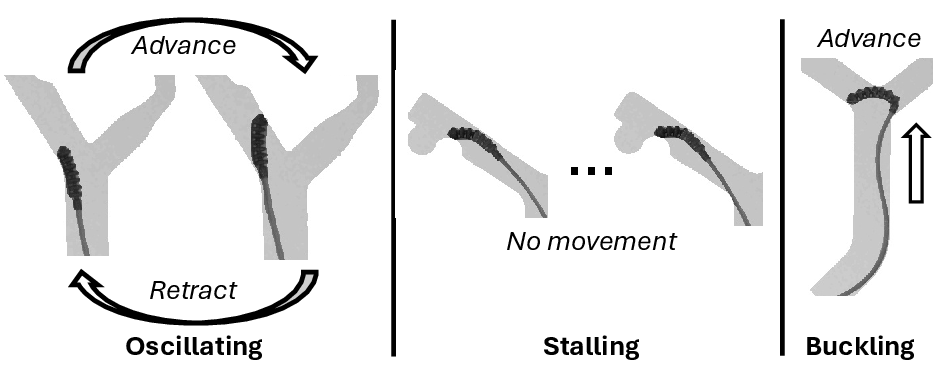
Figure 8: Representative examples of oscillating, stalling, and buckling failure modes across evaluated policies.
Discussion
The results substantiate that transformer-based action chunking, combined with goal conditioning and learned contrast management, enables robust autonomous navigation in complex, partially observable vascular environments. The model generalizes effectively to unseen geometries, requiring only moderate demonstration data, and matches clinician performance in both success rate and final target proximity. Ablation and baseline analyses confirm that each architectural and data collection choice is essential for overcoming the challenges of soft robot dynamics and visual occlusion.
The approach is limited by occasional stalling and overuse of contrast agent, suggesting future work should explore finer-grained chunk sizes, increased recovery data, and incorporation of observation history for improved temporal reasoning. Miniaturization of the robotic platform and extension to 3D, flexible vessel models are necessary for clinical translation. Training with expert surgeon demonstrations may further align model behavior with clinical best practices.
Conclusion
This study demonstrates that end-to-end imitation learning with transformer-based action chunking is a viable strategy for autonomous soft robotic guidewire navigation in endovascular surgery. The framework achieves high success rates and generalization to novel anatomies, outperforming existing learning and classical baselines. These findings provide a foundation for future research in autonomous surgical robotics, with implications for reducing procedural times, radiation exposure, and improving patient outcomes in neurovascular interventions.

