- The paper introduces a multi-token prompt strategy that disentangles character-specific features from shared style, achieving high fidelity in few-shot settings.
- It employs LoRA for parameter-efficient fine-tuning, cutting training time from ~36 hours to ~2 hours and mitigating overfitting.
- Quantitative metrics and human evaluations confirm that the clustering-based approach enhances style retention and output diversity across varied datasets.
Few-shot Multi-token DreamBooth with LoRA for Style-consistent Character Generation
Introduction and Motivation
The paper addresses the challenge of generating an unlimited number of novel, stylistically consistent characters from a small set of human-designed references—a task of high relevance in animation, gaming, and digital content creation. The core difficulty lies in learning both the shared artistic style and the unique visual traits of a character family from few-shot data, where textual prompts are insufficient to capture the nuances of style, and overfitting is a persistent risk.
Traditional approaches, such as GANs and text-to-image diffusion models (e.g., Stable Diffusion, DALL-E), require large datasets or rely on explicit textual conditioning, which is not feasible for bespoke or niche styles. DreamBooth, a popular fine-tuning method for diffusion models, enables the integration of new visual concepts via prompt-based token association but is limited by overfitting, high computational cost, and insufficient diversity when applied in few-shot, style-centric scenarios.
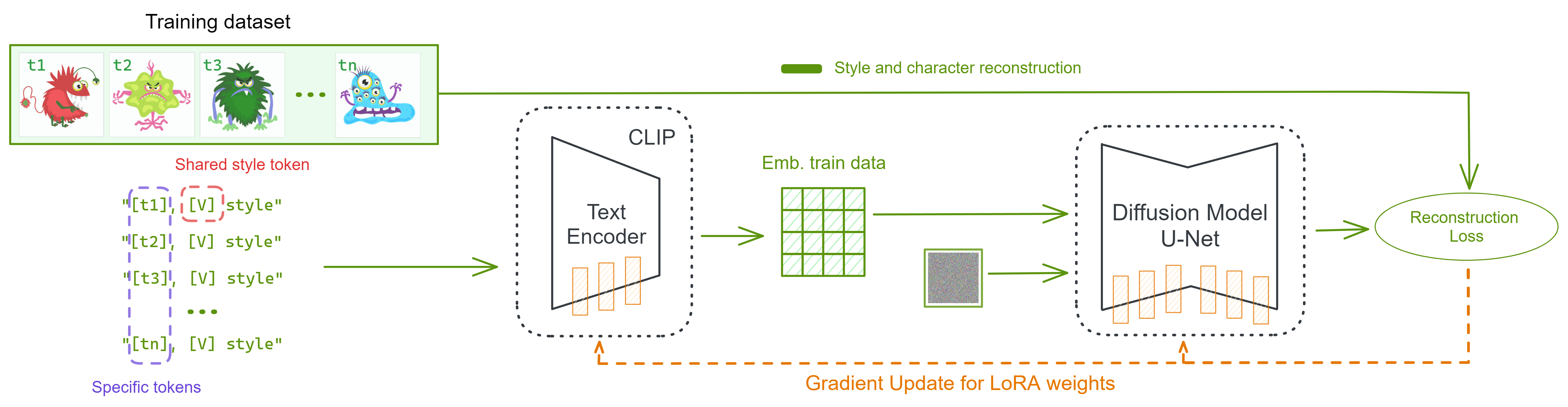
Methodology: Multi-token DreamBooth with LoRA
The proposed method extends DreamBooth by introducing a multi-token strategy and parameter-efficient fine-tuning via LoRA. The approach is designed to disentangle character-specific features from global style, enabling scalable and diverse character generation.
Multi-token Prompt Structure
During training, each character is associated with a unique token ([specific_id]), while a shared token ([shared_id]) captures the common style. The prompt format is:
1
|
[specific_id] [shared_id] style |
[specific_id]: Unique per character, encodes individual traits.[shared_id]: Shared across all characters, encodes style.style: Class descriptor, leveraging the model's prior on artistic styles.
Token selection is performed via two strategies:
LoRA-based Fine-tuning
LoRA (Low-Rank Adaptation) is employed to reduce the number of trainable parameters, enabling efficient adaptation of large diffusion models in few-shot settings. This significantly reduces training time (from ~36 hours for full DreamBooth to ~2 hours with LoRA) and mitigates overfitting.
Generation Phase: Unlimited Character Synthesis
At inference, new characters are generated by varying the [token | embedding] in the prompt:
- Random Tokens: Sample unused rare tokens.
- Random Embeddings: Inject sampled embeddings (univariate or multivariate Gaussian) into the text encoder, leveraging the distribution of rare token embeddings to synthesize novel identities.
This enables theoretically unlimited character generation while maintaining style coherence.
Experimental Setup
Datasets
Five few-shot datasets (10–30 images each) were curated, each containing characters with a consistent but hard-to-describe style:
- Virus: Cartoon viruses (simple, color variation).
- Scary: Cartoon monsters (complex, vibrant).
- Daily: Full-body cartoon humans.
- Hipster: Busts of cartoon humans (detailed faces).
- Trans: Line-art humans with prosthetics (no color, high complexity).





Figure 2: Character datasets used for experiments.
Baselines and Training
- Textual Inversion (TI)
- DreamBooth (DB)
- DreamBooth + LoRA (DBL)
- Proposed Multi-token DreamBooth + LoRA (DB_MT-RL, DB_MT-CL)
All models were trained on Stable Diffusion v1-5 with identical hyperparameters. For each method and dataset, five independent models were trained, and 400 images per model were generated using each generation strategy.
Evaluation Metrics
- Fidelity: Measures style alignment using CLIP-based cosine similarity between generated and reference images.
- Diversity: Standard deviation of CLIP embeddings across generations.
- Validity: Proportion of outputs passing criteria for non-duplication, non-defectiveness, and style/subject consistency.
Human evaluation was conducted via pairwise comparisons (general participants) and absolute ratings (professional artists).
Results
Validity Analysis
The baseline DreamBooth (DB) exhibited severe overfitting, with >99% of outputs being near-copies of training images. Textual Inversion (TI) produced a high rate of defective images. DreamBooth+LoRA (DBL) reduced overfitting but increased defective and multi-subject outputs, especially in human character datasets.
The proposed multi-token methods (DB_MT-RL, DB_MT-CL) achieved the lowest invalidity rates across all datasets, demonstrating robust generalization and style retention.

Figure 3: Examples of generated images that fail to meet the validity criteria, classified by the corresponding reasons for their rejection.
Human Evaluation
General participants and professional artists both ranked the clustering-based multi-token method (DB_MT-CL) highest in terms of stylistic fit and perceived quality, sometimes even preferring generated images over original dataset samples (notably in the Trans dataset).

Figure 5: Representative samples of generated characters shown to participants, organized by dataset and training method. Original datasets are included for reference.
Ablation Study
Ablation confirmed that:
- Multi-token training is the primary driver of Fidelity gains.
- Removing the regularization set eliminates major sources of invalidity and further improves style alignment, at a modest cost to diversity.
Implementation Considerations
- Computational Requirements: LoRA-based fine-tuning enables practical training on consumer GPUs (e.g., NVIDIA 3080 Ti), with training times reduced to ~2 hours per model.
- Scaling: The method is scalable to larger datasets and more complex styles, but the underlying diffusion model's biases and limitations (e.g., Stable Diffusion v1-5) may affect results.
- Deployment: The approach is suitable for integration into creative pipelines for animation, gaming, and digital content, enabling rapid prototyping and expansion of character rosters with minimal manual intervention.
- Limitations: Quantitative metrics may not fully capture subtle stylistic nuances; human evaluation remains essential for high-quality assessment. The method's effectiveness is contingent on the base model's representational capacity.
Implications and Future Directions
The proposed multi-token DreamBooth with LoRA establishes a robust framework for few-shot, style-consistent character generation, overcoming the overfitting and diversity limitations of prior methods. The explicit disentanglement of style and identity via token clustering, combined with parameter-efficient adaptation, enables scalable and practical deployment in creative industries.
Future work should explore:
- Application to newer diffusion architectures (e.g., Flux, Stable Diffusion 3.5).
- Development of refined, style-sensitive evaluation metrics.
- Broader and more diverse human evaluations.
- Extension to multi-modal or cross-domain style transfer scenarios.
Conclusion
This work demonstrates that clustering-based multi-token DreamBooth with LoRA enables high-fidelity, diverse, and scalable character generation from limited references, validated by both quantitative metrics and human judgment. The approach is computationally efficient and directly applicable to real-world creative workflows, with clear avenues for further research and refinement.