3D Reconstruction from Transient Measurements with Time-Resolved Transformer
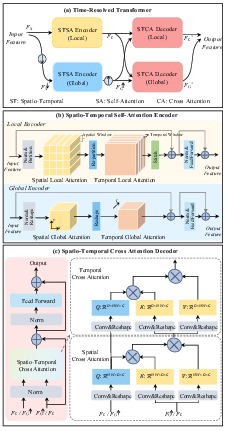
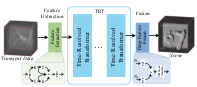
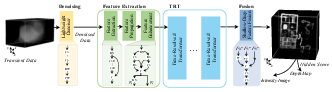
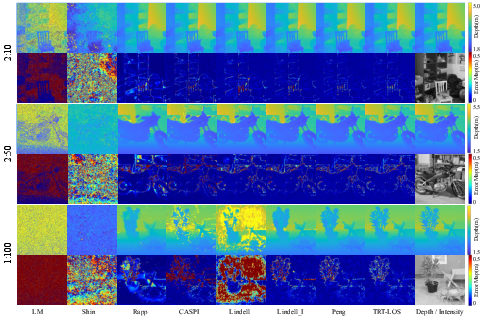
Abstract: Transient measurements, captured by the timeresolved systems, are widely employed in photon-efficient reconstruction tasks, including line-of-sight (LOS) and non-line-of-sight (NLOS) imaging. However, challenges persist in their 3D reconstruction due to the low quantum efficiency of sensors and the high noise levels, particularly for long-range or complex scenes. To boost the 3D reconstruction performance in photon-efficient imaging, we propose a generic Time-Resolved Transformer (TRT) architecture. Different from existing transformers designed for high-dimensional data, TRT has two elaborate attention designs tailored for the spatio-temporal transient measurements. Specifically, the spatio-temporal self-attention encoders explore both local and global correlations within transient data by splitting or downsampling input features into different scales. Then, the spatio-temporal cross attention decoders integrate the local and global features in the token space, resulting in deep features with high representation capabilities. Building on TRT, we develop two task-specific embodiments: TRT-LOS for LOS imaging and TRT-NLOS for NLOS imaging. Extensive experiments demonstrate that both embodiments significantly outperform existing methods on synthetic data and real-world data captured by different imaging systems. In addition, we contribute a large-scale, high-resolution synthetic LOS dataset with various noise levels and capture a set of real-world NLOS measurements using a custom-built imaging system, enhancing the data diversity in this field. Code and datasets are available at https://github.com/Depth2World/TRT.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

