NovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
Abstract: Enabling robots to execute novel manipulation tasks zero-shot is a central goal in robotics. Most existing methods assume in-distribution tasks or rely on fine-tuning with embodiment-matched data, limiting transfer across platforms. We present NovaFlow, an autonomous manipulation framework that converts a task description into an actionable plan for a target robot without any demonstrations. Given a task description, NovaFlow synthesizes a video using a video generation model and distills it into 3D actionable object flow using off-the-shelf perception modules. From the object flow, it computes relative poses for rigid objects and realizes them as robot actions via grasp proposals and trajectory optimization. For deformable objects, this flow serves as a tracking objective for model-based planning with a particle-based dynamics model. By decoupling task understanding from low-level control, NovaFlow naturally transfers across embodiments. We validate on rigid, articulated, and deformable object manipulation tasks using a table-top Franka arm and a Spot quadrupedal mobile robot, and achieve effective zero-shot execution without demonstrations or embodiment-specific training. Project website: https://novaflow.lhy.xyz/.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces NovaFlow, a way for robots to understand and perform new tasks without being trained on those tasks beforehand. Think of it like this: you tell the robot what you want (for example, “hang the mug on the rack”), NovaFlow creates a short “how-to” video showing the task, turns the video into a simple plan of how objects should move in 3D, and then uses that plan to move the robot’s arm or gripper. The big idea is to separate “understanding the task” from “moving the robot,” so the same approach works for very different robots.
Key Objectives
The paper aims to answer three simple questions:
- Can a robot solve a brand-new task from just a description, without practice or special training for that task?
- Can we use AI video tools (trained on lots of internet videos) to get common-sense motion plans for objects?
- Can we turn those motion plans into real robot actions that work for different kinds of objects (hard, hinged, or flexible) and different robots?
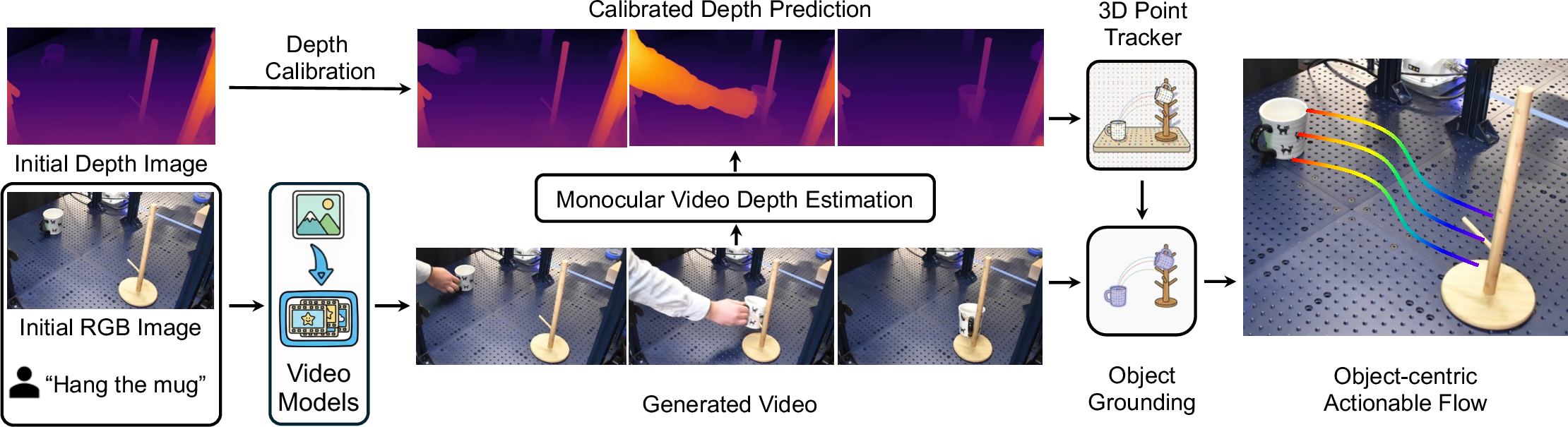
How NovaFlow Works
NovaFlow has two main parts: a flow generator and a flow executor.
Flow Generator (turns a task description into object motion)
This part makes a “how things move” plan from a task description and a picture of the scene:
- Video generation: An AI “video-maker” creates a short video of what solving the task should look like, based on the robot’s camera image and your instruction. If needed, it can also use a goal picture of the final state.
- 3D lifting: The system guesses how far away things are in each frame (depth), like turning a flat video into 3D, so we know where objects are in space.
- Depth calibration: Because depth from a single camera can be off, it aligns the guessed depth with the real depth from the robot’s first image, so the 3D makes sense.
- Point tracking: Imagine putting tiny stickers on many points of the object and following where each sticker moves across frames. The system tracks lots of these points in 3D.
- Object grounding: It finds the object you care about (like “the mug”) in the video and keeps only the motion of that object’s points. The result is “3D object flow”: a simple, step-by-step map of where points on the object should go over time.
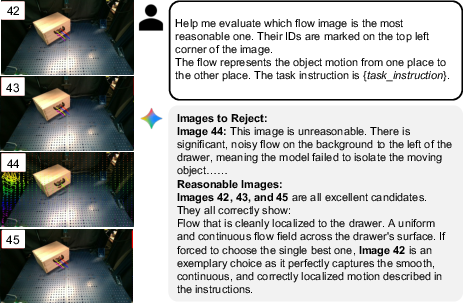
To avoid mistakes from weird or unrealistic videos, NovaFlow generates several candidate videos and asks a vision-LLM (a smart AI that understands images and text) to pick the best one based on how the object’s motion looks.
Flow Executor (turns object motion into robot movement)
This part converts the “3D object flow” into real robot actions:
- Rigid objects (like a block or a mug): If the object doesn’t bend, the system figures out how the whole object rotates and moves at each step. It then plans a steady grasp and moves the robot’s hand so the object follows that motion. Think “best-fit rotation and shift” to match the points from start to now.
- Deformable objects (like a rope): Flexible things don’t move like a single solid piece. Here, NovaFlow uses a physics-like model made of particles to predict how the object will change shape. It then chooses robot actions that make the object’s points follow the planned path, step by step, like nudging the rope into a straight line.
Finally, the system does trajectory optimization, which means it plans a smooth, safe path for the robot’s joints that avoids bumps and collisions while reaching the target poses.
Main Findings and Why They Matter
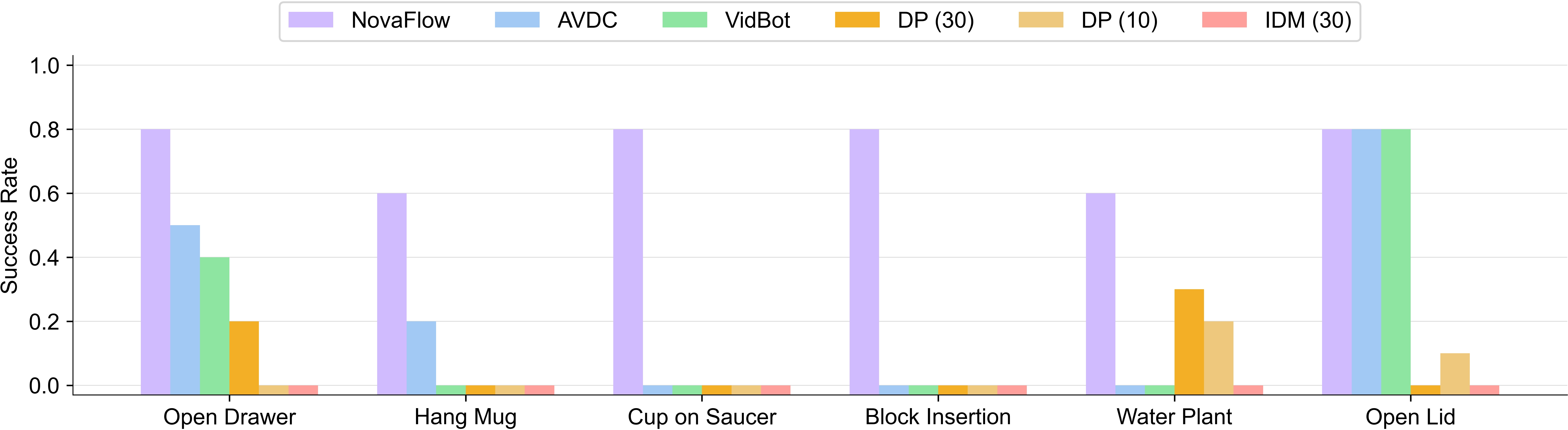
- NovaFlow successfully handled a range of real tasks without demonstrations:
- Hanging a mug on a rack
- Inserting a block into a hole
- Placing a cup on a saucer
- Watering a plant
- Opening a drawer
- Straightening a rope
- It worked on different robots:
- A tabletop arm (Franka) for precise manipulation
- A mobile robot (Spot) for more general tasks
- It often achieved higher success rates than other “zero-shot” methods and even beat some methods trained on 10–30 real demonstrations. This shows that using AI-generated videos plus 3D object flow is a powerful way to do new tasks with no task-specific robot training.
- It also found that using a “goal image” helps for very precise placements (like inserting a block), and picking the best video with a vision-LLM improves reliability.
This matters because collecting lots of robot training data is slow and expensive. NovaFlow reduces that need by reusing the “common sense” found in large video models trained on the internet.
Implications and Potential Impact
- Fewer robot demos needed: NovaFlow shows a path toward robots that can do many tasks with almost no special training, just by “watching” AI-generated videos and extracting object motion.
- Works across robot types: Because the plan focuses on objects (not robot-specific details), the same method transfers across different robot bodies.
- Handles many object kinds: Using “3D object flow” means it can work with rigid, articulated (hinged), and deformable objects.
- Future improvements: The main remaining challenge is the “last mile” of physical interaction—grasping and executing perfectly. Adding real-time feedback (closed-loop control) could make the system even more robust and adapt quickly when things go wrong.
In short, NovaFlow points toward more general, flexible robots that can learn new tasks fast, simply by turning “what should happen” in a video into “how to move” in the real world.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open research questions that the paper leaves unresolved. Each point highlights a missing piece or uncertainty that future work could address.
- No closed-loop control: the executor is open-loop and lacks real-time feedback to correct flow/tracking/planning errors; how to integrate live perception (e.g., online object/point trackers) for continual flow refinement and replanning remains open.
- Rigid grasp assumption: the method assumes firm, no-slip grasps and rigid object–end-effector coupling; robustness to partial contact, slip, and compliance (without tactile/force feedback) is unaddressed.
- Task-oriented grasping: GraspGen provides generic candidate grasps; selecting functional, affordance- and action-aligned grasps for specific tasks (e.g., pouring, insertion) is not considered.
- Articulated objects: articulated systems are treated as part-wise rigid without explicit joint inference or constraint modeling; generalizing to complex kinematic chains, unknown joint types/axes, and contact-constrained motions is open.
- Deformable dynamics dependence: deformable planning depends on a pretrained particle dynamics model (PhysTwin) and multiple cameras; generalization to new materials, topologies (cloth, sponges), and single-view setups is not demonstrated.
- Fluids and granular media: tasks involving fluid or granular dynamics (beyond simple cup tilting) are not modeled or controlled; how to plan with such media is unexplored.
- Monocular depth on generated videos: depth estimates can be temporally inconsistent and scale-biased; the simple median scale calibration may fail under appearance/layout drift; alternatives (affine/bundle adjustment, learned scale alignment) are not evaluated.
- Camera motion sensitivity: the pipeline relies on prompt-enforced static cameras; robustness to ego-motion or moving sensors (common for mobile robots) and necessary ego-motion estimation are not addressed.
- Physical plausibility filtering: VLM-based rejection sampling screens flows heuristically; physics-/kinematics-aware validation (e.g., constraint checking, simulation-in-the-loop) is absent.
- Reliance on proprietary models: selection (Gemini) and fast video generation (Veo) introduce cost, latency, and reproducibility constraints; open-source, on-prem alternatives and their accuracy–speed trade-offs are not explored.
- Runtime and resource burden: planning takes ~2 minutes on an H100 (much slower with open-source generation); strategies for real-time or embedded execution (distillation, caching, incremental replanning) are not presented.
- Multi-object interaction: the framework grounds a single target; simultaneous multi-object flows, bi-directional constraints, and sequencing for tasks requiring multiple moving parts (e.g., assembly, handovers) remain open.
- Long-horizon tasks: the 41-frame horizon limits complex, multi-stage procedures (regrasps, tool use, multi-step assembly); hierarchical task decomposition and flow stitching are unexplored.
- Time parameterization: translating frame-indexed flows to dynamically feasible, time-scaled robot trajectories (velocities/accelerations) under actuator limits is under-specified.
- Obstacle modeling and perception: collision avoidance assumes known obstacles and signed distances; automatic, reliable scene reconstruction from onboard sensing (with uncertainty) is not integrated.
- Uncertainty awareness: the planner does not quantify or use uncertainty from depth, tracking, segmentation, or grounding; risk-aware control and confidence-weighted flow tracking are missing.
- Failure recovery: there is no mechanism to detect, localize, and recover from execution failures (missed grasps, collisions); reactive replanning, backtracking, and contingency behaviors are absent.
- Goal-image dependency: precise placement tasks benefit from goal images; performance drops without them (especially with open-source generation); language-only precision planning or geometry-grounded synthetic goal generation is an open problem.
- Adaptive keypoint selection: the system uniformly samples keypoints; adaptive, task-relevant point selection and robustness to occlusions/self-occlusions are not investigated.
- Robustness to clutter and distractors: evaluations occur in relatively clean, static scenes; performance in cluttered, dynamic environments with visually similar distractors is untested.
- Cross-embodiment breadth: results are shown on a Franka arm and a Spot platform; generalization to diverse end-effectors (suction, multi-fingered hands), camera placements, and moving bases requires validation.
- Contact/force control: insertion and contact-rich tasks are executed without force/impedance control; leveraging force/torque/tactile feedback for precision and safety is unexplored.
- Ground-truth scene alignment: the approach assumes the first generated frame aligns closely with the real initial observation; detecting and handling large scene/layout drift before depth calibration and planning is not addressed.
- Online fusion of generated and observed flows: methods to fuse priors from generated flows with live, noisy flow estimates (e.g., probabilistic filtering) are not developed.
- Regrasping and in-hand manipulation: sequencing multiple grasps, handoffs, and in-hand reorientation is not supported or planned over.
- Safety and assurance: there is no formal analysis of how flow errors propagate to task failure or safety violations; deriving bounds or guarantees linking flow accuracy to success remains open.
- Evaluation scope: limited tasks (six), small trial counts (ten per task), and few metrics (success rate) narrow conclusions; broader benchmarks, pose/trajectory/contact accuracy metrics, and stress tests are needed.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases that can be implemented with the paper’s methods and pipeline, assuming access to the specified modules and a controlled environment.
- Zero-shot manipulation prototyping in labs
- Sectors: robotics, software
- Tools/workflows: NovaFlow pipeline with Wan/Veo for video generation, MegaSaM (depth), TAPIP3D (3D tracking), Grounded-SAM2 (segmentation), GraspGen (grasp proposals), IK/trajectory optimization (e.g., MoveIt); workflow = capture initial RGB-D + language prompt → generate videos → distill actionable 3D flow → plan/execution.
- Assumptions/dependencies: known camera intrinsics; static or mildly dynamic scenes; human-in-the-loop safety; GPU for generation; VLM (e.g., Gemini) for rejection sampling.
- Cross-embodiment skill transfer without retraining
- Sectors: manufacturing, warehousing, field robotics
- Tools/workflows: reuse the same flow generator across different robots (e.g., Franka, Spot), map object flow to end-effector trajectories with embodiment-specific IK/trajectory stacks.
- Assumptions/dependencies: end-effector rigidly couples to object (limited slippage); suitable gripper; correct robot kinematic model.
- Precise placement/insertions for small assembly and kitting
- Sectors: manufacturing
- Tools/workflows: goal-image conditioning (FLF2V), VLM-based rejection sampling; Kabsch alignment for 6D object pose; grasp proposals + collision-aware trajectory optimization for peg-in-hole-like insertions.
- Assumptions/dependencies: reliable monocular depth calibration; video model produces physically plausible motion; tight tolerance requires good grasps and accurate calibration.
- Articulated object operations (drawers, doors, lids) in facilities and service tasks
- Sectors: facility management, service robotics
- Tools/workflows: open-vocabulary grounding + segmentation; flow-derived part-wise rigid transforms; IK-based execution.
- Assumptions/dependencies: articulation is represented consistently in generated videos; accessible handles; minimal occlusion.
- Deformable object handling (rope straightening, cable routing, bagging)
- Sectors: manufacturing logistics
- Tools/workflows: PhysTwin (or similar) particle dynamics; MPC using dense point correspondences from the actionable 3D flow; optionally multi-view cameras.
- Assumptions/dependencies: material-specific dynamics model available or trainable; adequate sensing (often multi-view); safe interaction forces.
- On-the-fly affordance visualization and human validation
- Sectors: education, human–robot interaction
- Tools/workflows: back-project flow to “flow images” for quick visual check; VLM rejection sampling to filter implausible videos; use as a planning aid for operators.
- Assumptions/dependencies: VLM reliability; interpretable flow overlays; operators available to validate.
- Synthetic dataset generation for downstream learning
- Sectors: academia, software
- Tools/workflows: use actionable flows and executed trajectories to bootstrap imitation learning (e.g., Diffusion Policy) and inverse dynamics; augment cross-embodiment datasets.
- Assumptions/dependencies: quality of labels and motion realism; sim-to-real considerations; diversity of tasks/prompts.
- Rapid task setup for warehouse/home demos
- Sectors: daily life, logistics
- Tools/workflows: language prompt to execute tasks like “place cup on saucer,” “open drawer,” “water plant” with minimal task-specific setup; human safety monitor.
- Assumptions/dependencies: relatively uncluttered environment; runtime acceptable (~2 minutes for flow generation with fast models); risk-managed execution.
- Robot design and QA feasibility checks
- Sectors: robotics engineering
- Tools/workflows: use flow-derived reference trajectories to test reachability, collision constraints, and grasp feasibility before writing bespoke controllers.
- Assumptions/dependencies: accurate robot and scene models; correct calibration and collision geometry.
- Mobile manipulation demos and pilots
- Sectors: product demos, public outreach
- Tools/workflows: deploy NovaFlow on mobile platforms (e.g., Spot with arm) for tasks like drawer opening or watering; integrate with onboard navigation and perception.
- Assumptions/dependencies: stable perception pipelines; safety perimeter; real-time execution constraints.
Long-Term Applications
Below are applications that require additional research, scaling, robustness, or productization before widespread deployment.
- Generalist household/service robots that follow natural language instructions
- Sectors: consumer robotics, eldercare
- Tools/products: closed-loop NovaFlow with live object tracking; robust grasp detection; onboard efficient video generation; fallback routines and self-correction.
- Dependencies: real-time flow estimation; improved physical interaction (grasping/slippage handling); safety certification; failure recovery.
- High-mix, small-batch assembly with generalist manipulators
- Sectors: manufacturing
- Tools/products: curated library of “actionable flows” indexed by tasks; goal-image conditioning for variant assembly; integration with MES/ERP and vision-guided alignment.
- Dependencies: precise calibration and verification; compliance or force control; quality assurance workflows for tolerances; change management on shop floors.
- Surgical and medical manipulation planning for deformables
- Sectors: healthcare
- Tools/products: flow-guided MPC with physics-informed tissue models; surgeon-in-the-loop validation using flow visualizations; training simulators.
- Dependencies: highly accurate, validated dynamics; regulatory approvals; high-fidelity sensing (multi-view, imaging modalities); sterile, safe robotic platforms.
- Automation of cable harnesses, textiles, and soft packaging
- Sectors: manufacturing/logistics
- Tools/products: material-specific particle models; flow-based planning for sequencing and tension control; adaptive end-effectors/grippers.
- Dependencies: robust material characterization; sensing under occlusion; throughput and reliability targets for production.
- Disaster response and field robotics for ad-hoc tasks
- Sectors: public safety, infrastructure
- Tools/products: edge-optimized video and flow modules; multimodal perception (thermal, LiDAR) fused into flow-to-action; uncertainty-aware planning.
- Dependencies: ruggedized hardware; robust perception in adverse conditions; limited connectivity; autonomy constraints and human oversight.
- Standardized Flow-to-Action API and ROS ecosystem plugins
- Sectors: software, robotics
- Tools/products: NovaFlow SDK; ROS2 packages; cloud services for video generation and VLM-based validation; “TaskFlow” repositories/marketplaces.
- Dependencies: community standards for flow schema; security/privacy guarantees; predictable costs and latency for cloud generation.
- Robotics education and training platforms
- Sectors: education
- Tools/products: curriculum modules showcasing object-centric planning and flow distillation; student-accessible toolchains and datasets; interactive labs.
- Dependencies: accessible compute (GPUs or cloud credits); curated prompts/scenarios; safe classroom robots and supervision.
- Governance and safety frameworks for generative-model-driven manipulation
- Sectors: policy, compliance
- Tools/products: audit logs of generated videos and selected flows; automatic plausibility checks; runtime monitors and shutoffs; certification criteria for closed-loop deployments.
- Dependencies: cross-industry consensus; standardized incident reporting; benchmarks for physical plausibility and safety.
- Multi-robot coordination using shared object flow
- Sectors: robotics, software
- Tools/products: shared flow representations to coordinate roles (e.g., stabilizer robot and manipulator robot); flow-aware task allocation and synchronization.
- Dependencies: time sync and consistent perception across robots; communication reliability; conflict resolution and safety.
- Real-time, on-edge NovaFlow for embedded platforms
- Sectors: robotics hardware/software
- Tools/products: compressed/quantized video and depth models; accelerated 3D tracking; online closed-loop replanning; lightweight VLM validators.
- Dependencies: model optimization; hardware acceleration; graceful degradation under compute constraints; robust fallback behaviors.
Glossary
- 3D point tracking: Tracking selected points in 3D across video frames to recover their trajectories and motion. Example: "We employ a 3D point tracking model"
- 6D pose: The full 3D position and orientation of an object or end-effector. Example: "Other work tracks the 6D pose of the end-effector"
- Actionable 3D object flow: A per-point 3D motion field on target objects that is directly usable to plan robot actions. Example: "distill an actionable 3D object flow"
- Affordance: The action possibilities an object or scene offers; often represented as maps guiding manipulation. Example: "affordance maps"
- Articulated objects: Objects composed of multiple parts linked by joints allowing relative motion. Example: "articulated objects"
- Camera intrinsics: Parameters describing a camera’s internal geometry (e.g., focal length, principal point). Example: "with known camera intrinsics"
- Chamfer distance: A set-to-set distance commonly used to compare point clouds. Example: "like the Chamfer distance"
- Closed-loop: Control that continuously uses feedback to update actions during execution. Example: "closed-loop tracking system"
- Correspondence-free metric: A distance measure between shapes that does not require explicit point-to-point matches. Example: "a correspondence-free metric"
- Egocentric datasets: Data captured from a first-person viewpoint, often wearable cameras. Example: "large-scale human egocentric datasets"
- Embodiment: The specific physical form and hardware of a robot. Example: "across embodiments"
- End-effector: The tool or gripper at the tip of a robot arm that interacts with the environment. Example: "end-effector pose"
- End-to-end training: Learning a single model mapping inputs to outputs without modular decomposition. Example: "the end-to-end training nature of VLAs"
- First-Last-Frame-to-Video (FLF2V): Video generation conditioned on both the first and last frames. Example: "first-last-frame-to-video (FLF2V) generation"
- Grasp proposal model: A model that predicts feasible, object-specific grasp candidates from sensor data. Example: "a grasp proposal model"
- Grasp transformation: The fixed transform from the object’s pose to the end-effector pose when grasped. Example: "a grasp transformation"
- Homogeneous transformation matrix: A 4×4 matrix representing rotation and translation in 3D. Example: "homogeneous transformation matrix"
- Image-to-Video (I2V) generation: Synthesizing a sequence of video frames from an initial image (and possibly text). Example: "image-to-video (I2V) generation"
- In-distribution: Belonging to the same distribution as a model’s training data. Example: "in-distribution tasks"
- Inverse Dynamics Model (IDM): A model that infers the action required to move from one state to the next. Example: "Inverse Dynamics Model (IDM)"
- Inverse kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. Example: "inverse kinematics (IK)"
- Kabsch algorithm: A method to compute the optimal rotation aligning two point sets. Example: "Kabsch algorithm"
- Levenberg–Marquardt solver: An algorithm for solving nonlinear least-squares optimization problems. Example: "Levenberg-Marquardt solver"
- Model Predictive Control (MPC): Optimization-based control that plans actions over a finite horizon and replans at each step. Example: "Model Predictive Control (MPC)"
- Model-free: Approaches that do not rely on explicit object or dynamics models. Example: "model-free representations"
- Monocular depth estimation: Predicting scene depth from single-view RGB images. Example: "monocular depth estimation"
- Object grounding: Linking linguistic object references to their visual instances via detection/segmentation. Example: "object grounding"
- Object-centric: Representations or methods focused on objects and their motion rather than robot-specific states. Example: "object-centric approaches"
- Open-loop planner: A planner that executes a precomputed plan without feedback during execution. Example: "open-loop planner"
- Open-vocabulary object detector: A detector that can localize objects specified by arbitrary text labels. Example: "open-vocabulary object detector"
- Optical flow: The per-pixel 2D motion field between consecutive images. Example: "optical flow"
- Particle-based dynamics model: A physics model that represents deformable objects as interacting particles. Example: "a particle-based dynamics model"
- Rejection sampling: Generating multiple candidates and selecting valid ones using a filter or evaluator. Example: "rejection sampling"
- Rigid transformation: A motion composed of rotation and translation without deformation. Example: "rigid transformation"
- SE(3): The group of 3D rigid-body transformations (rotations and translations). Example: "SE(3)"
- Signed distance: A distance value with a sign indicating direction relative to a surface or obstacle. Example: "signed distance"
- Sim-to-real gap: The performance discrepancy when transferring methods from simulation to the real world. Example: "sim-to-real gap"
- Singular Value Decomposition (SVD): A matrix factorization used for solving least-squares and alignment problems. Example: "Singular Value Decomposition (SVD)"
- SO(3): The group of 3D rotations. Example: "SO(3)"
- Trajectory optimization: Optimizing a sequence of robot states or controls subject to costs and constraints. Example: "trajectory optimization"
- Vision-Language-Action (VLA) models: Models that map visual and textual inputs to action outputs for embodied tasks. Example: "Vision-Language-Action (VLA) models"
- Vision-LLMs (VLMs): Models that jointly understand visual inputs and language. Example: "Vision-LLMs (VLMs)"
- Zero-shot: Performing new tasks without any task-specific training or demonstrations. Example: "zero-shot"
Collections
Sign up for free to add this paper to one or more collections.

